Recognition: 2 theorem links
· Lean TheoremLSRM: High-Fidelity Object-Centric Reconstruction via Scaled Context Windows
Pith reviewed 2026-05-10 19:25 UTC · model grok-4.3
The pith
Scaling context windows in sparse transformers lets feed-forward 3D models recover fine object textures and appearances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By increasing active object tokens twentyfold and image tokens more than twofold, LSRM achieves high-fidelity 3D object reconstruction and inverse rendering in a single feed-forward pass, matching or exceeding dense-view optimization on texture and geometry detail.
What carries the argument
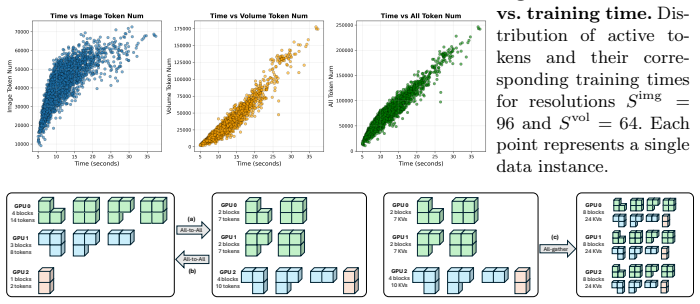
The 3D-aware spatial routing mechanism that uses explicit geometric distances to establish 2D-3D correspondences, paired with a coarse-to-fine pipeline that predicts sparse high-resolution residuals.
If this is right
- The model processes 20 times more object tokens and more than twice as many image tokens than earlier state-of-the-art feed-forward methods.
- It records 2.5 dB higher PSNR and 40 percent lower LPIPS on novel-view synthesis benchmarks.
- Texture and geometry details improve consistently when the same architecture is applied to inverse rendering.
- LPIPS scores on inverse rendering match or exceed those of current dense-view optimization methods.
Where Pith is reading between the lines
- The results imply that limited context size, not the transformer design itself, was the main obstacle to high-fidelity feed-forward reconstruction.
- The same token-scaling approach with geometric routing could be tested on full scenes or dynamic objects to see whether the gains transfer.
- Explicit 3D distance cues in attention may reduce reliance on learned positional encodings for other geometry-aware tasks.
- Further context growth might support even higher resolution outputs or more objects per reconstruction without additional per-scene optimization.
Load-bearing premise
That routing attention with geometric distances and adding only sparse high-resolution details will keep every important texture and appearance cue intact on complex real objects without loss or new errors.
What would settle it
A controlled test on the same benchmarks where further increasing context size or altering the geometric routing produces no PSNR or LPIPS gain, or where visual inspection of outputs reveals missing fine details on real-world objects.
Figures








read the original abstract
We introduce the Large Sparse Reconstruction Model to study how scaling transformer context windows impacts feed-forward 3D reconstruction. Although recent object-centric feed-forward methods deliver robust, high-quality reconstruction, they still lag behind dense-view optimization in recovering fine-grained texture and appearance. We show that expanding the context window -- by substantially increasing the number of active object and image tokens -- remarkably narrows this gap and enables high-fidelity 3D object reconstruction and inverse rendering. To scale effectively, we adapt native sparse attention in our architecture design, unlocking its capacity for 3D reconstruction with three key contributions: (1) an efficient coarse-to-fine pipeline that focuses computation on informative regions by predicting sparse high-resolution residuals; (2) a 3D-aware spatial routing mechanism that establishes accurate 2D-3D correspondences using explicit geometric distances rather than standard attention scores; and (3) a custom block-aware sequence parallelism strategy utilizing an All-gather-KV protocol to balance dynamic, sparse workloads across GPUs. As a result, LSRM handles 20x more object tokens and >2x more image tokens than prior state-of-the-art (SOTA) methods. Extensive evaluations on standard novel-view synthesis benchmarks show substantial gains over the current SOTA, yielding 2.5 dB higher PSNR and 40% lower LPIPS. Furthermore, when extending LSRM to inverse rendering tasks, qualitative and quantitative evaluations on widely-used benchmarks demonstrate consistent improvements in texture and geometry details, achieving an LPIPS that matches or exceeds that of SOTA dense-view optimization methods. Code and model will be released on our project page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Large Sparse Reconstruction Model (LSRM) to investigate scaling transformer context windows for feed-forward 3D object reconstruction. It adapts sparse attention via a coarse-to-fine pipeline predicting sparse high-resolution residuals, a 3D-aware spatial routing mechanism using explicit geometric distances for 2D-3D correspondences, and block-aware sequence parallelism with All-gather-KV. The model processes 20x more object tokens and >2x image tokens than prior SOTA, reporting 2.5 dB PSNR gains and 40% lower LPIPS on novel-view synthesis benchmarks, plus competitive inverse rendering results.
Significance. If the empirical gains hold under full scrutiny, the work demonstrates that context scaling in object-centric feed-forward models can substantially close the fidelity gap to dense-view optimization methods for texture and appearance recovery. The engineering contributions for efficient sparse 3D-aware processing are practically significant for scaling vision transformers. Planned code and model release supports reproducibility.
major comments (3)
- [Experiments] Experiments section: The headline 2.5 dB PSNR and 40% LPIPS improvements are presented without explicit details on train/test data splits, baseline re-implementations, hyperparameter search protocols, or full ablation tables isolating context scaling from the routing and residual components. This prevents confirmation that gains are not attributable to post-hoc selection or metric-specific tuning.
- [Method] Method, 3D-aware spatial routing subsection: The routing uses deterministic geometric distances derived from coarse-stage estimates rather than learned attention scores. No quantitative analysis (e.g., routing error rates or ablation vs. feature-similarity routing) is provided to verify that this preserves fine-grained appearance details such as specular highlights or view-dependent effects on complex objects; misalignment here would discard residuals before the high-resolution stage can recover them.
- [Inverse rendering evaluations] Inverse rendering results: Claims that LPIPS matches or exceeds dense-view SOTA are stated without tabulated quantitative metrics, exact benchmark splits, or controls for the same number of input views as the NVS experiments, making the extension claim difficult to evaluate independently.
minor comments (2)
- [Method] Notation for token counts (object vs. image) and sparsity ratios should be defined once in a table and used consistently in text and figures.
- [Figures] Figure captions for qualitative results should explicitly note the input view count and highlight specific regions where texture/geometry improvements are visible.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, outlining the revisions we will make to improve clarity and rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline 2.5 dB PSNR and 40% LPIPS improvements are presented without explicit details on train/test data splits, baseline re-implementations, hyperparameter search protocols, or full ablation tables isolating context scaling from the routing and residual components. This prevents confirmation that gains are not attributable to post-hoc selection or metric-specific tuning.
Authors: We agree that the current presentation would benefit from greater transparency on these experimental details. In the revised manuscript, we will expand the Experiments section with explicit descriptions of the train/test data splits, the exact protocols used for baseline re-implementations (including hyperparameter search ranges and selection criteria), and comprehensive ablation tables that separately quantify the contributions of context scaling, 3D-aware routing, and residual prediction. These additions will allow independent verification that the reported gains stem from the proposed scaling approach rather than tuning artifacts. revision: yes
-
Referee: [Method] Method, 3D-aware spatial routing subsection: The routing uses deterministic geometric distances derived from coarse-stage estimates rather than learned attention scores. No quantitative analysis (e.g., routing error rates or ablation vs. feature-similarity routing) is provided to verify that this preserves fine-grained appearance details such as specular highlights or view-dependent effects on complex objects; misalignment here would discard residuals before the high-resolution stage can recover them.
Authors: The deterministic geometric routing is chosen specifically to enforce accurate 2D-3D correspondences based on explicit 3D structure, which we argue is more reliable than learned attention scores for maintaining geometric fidelity in sparse settings. We acknowledge, however, that empirical validation of this choice is valuable. In the revision, we will add quantitative metrics such as routing error rates on validation data and an ablation comparing geometric routing against feature-similarity routing, with focused analysis on preservation of specular highlights and view-dependent effects. revision: yes
-
Referee: [Inverse rendering evaluations] Inverse rendering results: Claims that LPIPS matches or exceeds dense-view SOTA are stated without tabulated quantitative metrics, exact benchmark splits, or controls for the same number of input views as the NVS experiments, making the extension claim difficult to evaluate independently.
Authors: The manuscript reports both qualitative and quantitative results for inverse rendering, but we agree that the quantitative component would be more accessible with explicit tables and controls. In the revised version, we will include detailed tables of LPIPS and other metrics for inverse rendering, specify the exact benchmark splits used, and confirm that input view counts are matched to those in the novel-view synthesis experiments for fair comparison. revision: yes
Circularity Check
No circularity in derivation chain; results are empirical benchmark comparisons
full rationale
The paper introduces LSRM as an architectural extension of transformer-based 3D reconstruction that scales context windows via sparse attention, a coarse-to-fine pipeline, geometric routing, and parallelism. Its headline quantitative claims (2.5 dB PSNR, 40% LPIPS reduction) are presented solely as outcomes of training and evaluating the model on standard novel-view synthesis and inverse-rendering benchmarks against prior SOTA. No equations, fitted parameters, or self-referential definitions appear that would reduce these gains to quantities computed from the same test data or prior self-citations. The derivation chain consists of design choices whose validity is tested externally via public benchmarks, rendering the result self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a 3D-aware spatial routing mechanism that establishes accurate 2D-3D correspondences using explicit geometric distances rather than standard attention scores
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
expanding the context window -- by substantially increasing the number of active object and image tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y., Lebrón, F., Sanghai, S.: Gqa: Training generalized multi-query transformer models from multi-head check- points. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 4895–4901 (2023)
2023
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bi, S., Xu, Z., Sunkavalli, K., Kriegman, D., Ramamoorthi, R.: Deep 3d capture: Geometry and reflectance from sparse multi-view images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5960–5969 (2020)
2020
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Boss, M., Braun, R., Jampani, V., Barron, J.T., Liu, C., Lensch, H.: Nerd: Neural reflectance decomposition from image collections. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12684–12694 (2021)
2021
-
[4]
Advances in Neural Information Processing Systems35, 26389–26403 (2022)
Boss, M., Engelhardt, A., Kar, A., Li, Y., Sun, D., Barron, J., Lensch, H., Jampani, V.: Samurai: Shape and material from unconstrained real-world arbitrary image collections. Advances in Neural Information Processing Systems35, 26389–26403 (2022)
2022
-
[5]
Advances in Neural Information Processing Systems34, 10691–10704 (2021)
Boss, M., Jampani, V., Braun, R., Liu, C., Barron, J., Lensch, H.: Neural-pil: Neural pre-integrated lighting for reflectance decomposition. Advances in Neural Information Processing Systems34, 10691–10704 (2021)
2021
-
[6]
ACM Transactions on Graphics43(1), 1–24 (2023)
Careaga, C., Aksoy, Y.: Intrinsic image decomposition via ordinal shading. ACM Transactions on Graphics43(1), 1–24 (2023)
2023
-
[7]
In: European conference on computer vision
Chen, A., Xu, H., Esposito, S., Tang, S., Geiger, A.: Lara: Efficient large-baseline radiance fields. In: European conference on computer vision. pp. 338–355. Springer (2024)
2024
-
[8]
SAM 3D: 3Dfy Anything in Images
Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., et al.: Sam 3d: 3dfy anything in images. arXiv preprint arXiv:2511.16624 (2025)
work page internal anchor Pith review arXiv 2025
-
[9]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, Z., Tang, J., Dong, Y., Cao, Z., Hong, F., Lan, Y., Wang, T., Xie, H., Wu, T., Saito, S., et al.: 3dtopia-xl: Scaling high-quality 3d asset generation via prim- itive diffusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26576–26586 (2025)
2025
-
[10]
Generating Long Sequences with Sparse Transformers
Child, R., Gray, S., Radford, A., Sutskever, I.: Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509 (2019)
work page internal anchor Pith review arXiv 1904
-
[11]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T.: Flashattention-2: Faster attention with better parallelism and work par- titioning. arXiv preprint arXiv:2307.08691 (2023)
work page internal anchor Pith review arXiv 2023
-
[12]
In: Proceedings of the 27th annual conference on Computer graphics and interactive techniques
Debevec, P., Hawkins, T., Tchou, C., Duiker, H.P., Sarokin, W., Sagar, M.: Ac- quiring the reflectance field of a human face. In: Proceedings of the 27th annual conference on Computer graphics and interactive techniques. pp. 145–156 (2000) High-Fidelity Object-Centric Reconstruction via Scaled Context Windows 17
2000
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13142–13153 (2023)
2023
-
[14]
ACM Transactions on Graph- ics (ToG)37(4), 1–15 (2018)
Deschaintre, V., Aittala, M., Durand, F., Drettakis, G., Bousseau, A.: Single-image svbrdf capture with a rendering-aware deep network. ACM Transactions on Graph- ics (ToG)37(4), 1–15 (2018)
2018
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Dong, Z., Chen, K., Lv, Z., Yu, H.X., Zhang, Y., Zhang, C., Zhu, Y., Tian, S., Li, Z., Moffatt, G., et al.: Digital twin catalog: A large-scale photorealistic 3d object digital twin dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 753–763 (2025)
2025
-
[16]
In: 2022 International Conference on Robotics and Automation (ICRA)
Downs, L., Francis, A., Koenig, N., Kinman, B., Hickman, R., Reymann, K., McHugh, T.B., Vanhoucke, V.: Google scanned objects: A high-quality dataset of 3d scanned household items. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 2553–2560. IEEE (2022)
2022
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Engelhardt, A., Raj, A., Boss, M., Zhang, Y., Kar, A., Li, Y., Sun, D., Brualla, R.M., Barron, J.T., Lensch, H., et al.: Shinobi: Shape and illumination using neu- ral object decomposition via brdf optimization in-the-wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19636– 19646 (2024)
2024
-
[18]
40 Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel
Fang, J., Zhao, S.: Usp: A unified sequence parallelism approach for long context generative ai. arXiv preprint arXiv:2405.07719 (2024)
-
[19]
IEEE Transactions on Pattern Analysis and Machine Intelligence32(6), 1060–1071 (2009)
Goldman, D.B., Curless, B., Hertzmann, A., Seitz, S.M.: Shape and spatially- varying brdfs from photometric stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence32(6), 1060–1071 (2009)
2009
-
[20]
Gupta, A., Xiong, W., Nie, Y., Jones, I., Oğuz, B.: 3dgen: Triplane latent diffusion for textured mesh generation. arXiv preprint arXiv:2303.05371 (2023)
-
[21]
Advances in Neural Information Processing Systems35, 22856–22869 (2022)
Hasselgren, J., Hofmann, N., Munkberg, J.: Shape, light, and material decomposi- tion from images using monte carlo rendering and denoising. Advances in Neural Information Processing Systems35, 22856–22869 (2022)
2022
-
[22]
LRM: Large Reconstruction Model for Single Image to 3D
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023)
work page internal anchor Pith review arXiv 2023
-
[23]
Hunyuan3D, T., Yang, S., Yang, M., Feng, Y., Huang, X., Zhang, S., He, Z., Luo, D., Liu, H., Zhao, Y., et al.: Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material. arXiv preprint arXiv:2506.15442 (2025)
-
[24]
Jacobs, S.A., Tanaka, M., Zhang, C., Zhang, M., Song, S.L., Rajbhandari, S., He, Y.: Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509 (2023)
work page internal anchor Pith review arXiv 2023
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, Y., Tu, J., Liu, Y., Gao, X., Long, X., Wang, W., Ma, Y.: Gaussianshader: 3d gaussian splatting with shading functions for reflective surfaces. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5322–5332 (2024)
2024
-
[26]
Jin, H., Jiang, H., Tan, H., Zhang, K., Bi, S., Zhang, T., Luan, F., Snavely, N., Xu, Z.: Lvsm: A large view synthesis model with minimal 3d inductive bias. arXiv preprint arXiv:2410.17242 (2024)
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, H., Liu, I., Xu, P., Zhang, X., Han, S., Bi, S., Zhou, X., Xu, Z., Su, H.: Tensoir: Tensorial inverse rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 165–174 (2023) 18 Z. Li et al
2023
-
[28]
Proceedings of Machine Learning and Systems5, 341–353 (2023)
Korthikanti, V.A., Casper, J., Lym, S., McAfee, L., Andersch, M., Shoeybi, M., Catanzaro, B.: Reducing activation recomputation in large transformer models. Proceedings of Machine Learning and Systems5, 341–353 (2023)
2023
-
[29]
Advances in Neural Information Processing Systems36(2024)
Kuang,Z.,Zhang,Y.,Yu,H.X.,Agarwala,S.,Wu,E.,Wu,J.,etal.:Stanford-orb:a real-world 3d object inverse rendering benchmark. Advances in Neural Information Processing Systems36(2024)
2024
-
[30]
Lai, X., Lu, J.: native-sparse-attention-triton: Efficient triton implementation of Native Sparse Attention.https://github.com/XunhaoLai/native- sparse- attention-triton(2025)
2025
-
[31]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Lan, Y., Hong, F., Zhou, S., Yang, S., Meng, X., Chen, Y., Lyu, Z., Dai, B., Pan, X., Loy, C.C.: Ln3diff++: Scalable latent neural fields diffusion for speedy 3d generation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[32]
Lan, Y., Zhou, S., Lyu, Z., Hong, F., Yang, S., Dai, B., Pan, X., Loy, C.C.: Gaus- siananything: Interactive point cloud latent diffusion for 3d generation (2025)
2025
-
[33]
In: European conference on computer vision
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: European conference on computer vision. pp. 71–91. Springer (2024)
2024
-
[34]
Li, W., Liu, J., Yan, H., Chen, R., Liang, Y., Chen, X., Tan, P., Long, X.: Crafts- man3d: High-fidelity mesh generation with 3d native generation and interactive geometry refiner. arXiv preprint arXiv:2405.14979 (2024)
-
[35]
Step1X-3D: Towards high-fidelity and controllable generation of textured 3D assets, 2025
Li, W., Zhang, X., Sun, Z., Qi, D., Li, H., Cheng, W., Cai, W., Wu, S., Liu, J., Wang, Z., et al.: Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets. arXiv preprint arXiv:2505.07747 (2025)
-
[36]
ACM Transac- tions on Graphics (ToG)36(4), 1–11 (2017)
Li, X., Dong, Y., Peers, P., Tong, X.: Modeling surface appearance from a single photograph using self-augmented convolutional neural networks. ACM Transac- tions on Graphics (ToG)36(4), 1–11 (2017)
2017
-
[37]
IEEE Transactions on Pattern Analysis and Machine Intel- ligence (2025)
Li, Y., Zou, Z.X., Liu, Z., Wang, D., Liang, Y., Yu, Z., Liu, X., Guo, Y.C., Liang, D., Ouyang, W., et al.: Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models. IEEE Transactions on Pattern Analysis and Machine Intel- ligence (2025)
2025
-
[38]
In: Proceedings of the European conference on com- puter vision (ECCV)
Li, Z., Snavely, N.: Cgintrinsics: Better intrinsic image decomposition through physically-based rendering. In: Proceedings of the European conference on com- puter vision (ECCV). pp. 371–387 (2018)
2018
-
[39]
In: European Conference on Computer Vision
Li, Z., Shi, J., Bi, S., Zhu, R., Sunkavalli, K., Hašan, M., Xu, Z., Ramamoorthi, R., Chandraker, M.: Physically-based editing of indoor scene lighting from a single image. In: European Conference on Computer Vision. pp. 555–572. Springer (2022)
2022
-
[40]
In: Proceedings of the European conference on computer vision (ECCV)
Li, Z., Sunkavalli, K., Chandraker, M.: Materials for masses: Svbrdf acquisition with a single mobile phone image. In: Proceedings of the European conference on computer vision (ECCV). pp. 72–87 (2018)
2018
-
[41]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, Z., Wang, D., Chen, K., Lv, Z., Nguyen-Phuoc, T., Lee, M., Huang, J.B., Xiao, L., Zhu, Y., Marshall, C.S., et al.: Lirm: Large inverse rendering model for progressive reconstruction of shape, materials and view-dependent radiance fields. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 505–517 (2025)
2025
-
[42]
ACM Trans- actions on Graphics (TOG)37(6), 1–11 (2018)
Li, Z., Xu, Z., Ramamoorthi, R., Sunkavalli, K., Chandraker, M.: Learning to re- construct shape and spatially-varying reflectance from a single image. ACM Trans- actions on Graphics (TOG)37(6), 1–11 (2018)
2018
-
[43]
arXiv preprint arXiv:2505.14521 , year=
Li, Z., Wang, Y., Zheng, H., Luo, Y., Wen, B.: Sparc3d: Sparse representa- tion and construction for high-resolution 3d shapes modeling. arXiv preprint arXiv:2505.14521 (2025) High-Fidelity Object-Centric Reconstruction via Scaled Context Windows 19
-
[44]
arXiv preprint arXiv:2412.03526 (2024) 2
Liang, H., Ren, J., Mirzaei, A., Torralba, A., Liu, Z., Gilitschenski, I., Fidler, S., Oztireli, C., Ling, H., Gojcic, Z., et al.: Feed-forward bullet-time reconstruction of dynamic scenes from monocular videos. arXiv preprint arXiv:2412.03526 (2024)
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liang, Z., Zhang, Q., Feng, Y., Shan, Y., Jia, K.: Gs-ir: 3d gaussian splatting for inverse rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21644–21653 (2024)
2024
-
[46]
arXiv preprint arXiv:2506.09997 (2025)
Lin, C.H., Lv, Z., Wu, S., Xu, Z., Nguyen-Phuoc, T., Tseng, H.Y., Straub, J., Khan, N., Xiao, L., Yang, M.H., et al.: Dgs-lrm: Real-time deformable 3d gaussian reconstruction from monocular videos. arXiv preprint arXiv:2506.09997 (2025)
-
[47]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review arXiv 2025
-
[48]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Liu, H., Zaharia, M., Abbeel, P.: Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889 (2023)
work page internal anchor Pith review arXiv 2023
-
[49]
arXiv preprint arXiv:2506.18890 (2025)
Ma, Z., Chen, X., Yu, S., Bi, S., Zhang, K., Ziwen, C., Xu, S., Yang, J., Xu, Z., Sunkavalli, K., et al.: 4d-lrm: Large space-time reconstruction model from and to any view at any time. arXiv preprint arXiv:2506.18890 (2025)
-
[50]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Meka, A., Maximov, M., Zollhoefer, M., Chatterjee, A., Seidel, H.P., Richardt, C., Theobalt, C.: Lime: Live intrinsic material estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6315–6324 (2018)
2018
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Munkberg, J., Hasselgren, J., Shen, T., Gao, J., Chen, W., Evans, A., Müller, T., Fidler, S.: Extracting triangular 3d models, materials, and lighting from images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8280–8290 (2022)
2022
-
[52]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., et al.: Gated attention for large language models: Non- linearity, sparsity, and attention-sink-free. arXiv preprint arXiv:2505.06708 (2025)
work page internal anchor Pith review arXiv 2025
-
[53]
arXiv preprint arXiv:2312.05133 (2023)
Shi, Y., Wu, Y., Wu, C., Liu, X., Zhao, C., Feng, H., Liu, J., Zhang, L., Zhang, J., Zhou, B., et al.: Gir: 3d gaussian inverse rendering for relightable scene factoriza- tion. arXiv preprint arXiv:2312.05133 (2023)
-
[54]
Siddiqui, Y., Monnier, T., Kokkinos, F., Kariya, M., Kleiman, Y., Garreau, E., Gafni, O., Neverova, N., Vedaldi, A., Shapovalov, R., et al.: Meta 3d assetgen: Text-to-mesh generation with high-quality geometry, texture, and pbr materials. arXiv preprint arXiv:2407.02445 (2024)
-
[55]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Sun, C., Cai, G., Li, Z., Yan, K., Zhang, C., Marshall, C., Huang, J.B., Zhao, S., Dong, Z.: Neural-pbir reconstruction of shape, material, and illumination. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18046–18056 (2023)
2023
-
[57]
https://openai.com/index/triton/(July 2021), openAI Blog
Tillet, P.: Introducing Triton: Open-source GPU programming for neural networks. https://openai.com/index/triton/(July 2021), openAI Blog
2021
-
[58]
In: 2024 Interna- tional Conference on 3D Vision (3DV)
Ummenhofer, B., Agrawal, S., Sepulveda, R., Lao, Y., Zhang, K., Cheng, T., Richter, S., Wang, S., Ros, G.: Objects with lighting: A real-world dataset for evaluating reconstruction and rendering for object relighting. In: 2024 Interna- tional Conference on 3D Vision (3DV). pp. 137–147. IEEE (2024)
2024
-
[59]
Advances in neural infor- mation processing systems35, 10021–10039 (2022) 20 Z
Vahdat, A., Williams, F., Gojcic, Z., Litany, O., Fidler, S., Kreis, K., et al.: Lion: Latent point diffusion models for 3d shape generation. Advances in neural infor- mation processing systems35, 10021–10039 (2022) 20 Z. Li et al
2022
-
[60]
Advances in Neural Information Processing Systems (2017)
Vaswani, A.: Attention is all you need. Advances in Neural Information Processing Systems (2017)
2017
-
[61]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[62]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20697–20709 (2024)
2024
-
[63]
arXiv preprint arXiv:2404.12385 , year=
Wei, X., Zhang, K., Bi, S., Tan, H., Luan, F., Deschaintre, V., Sunkavalli, K., Su, H., Xu, Z.: Meshlrm: Large reconstruction model for high-quality mesh. arXiv preprint arXiv:2404.12385 (2024)
-
[64]
Advances in Neural Information Processing Systems37, 121859–121881 (2024)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Xu, J., Torr, P., Cao, X., Yao, Y.: Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer. Advances in Neural Information Processing Systems37, 121859–121881 (2024)
2024
-
[65]
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Yang, Y., Bao, Y., Qian, J., Zhu, S., Cao, X., Torr, P., et al.: Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention. arXiv preprint arXiv:2505.17412 (2025)
-
[66]
Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Xiang, J., Chen, X., Xu, S., Wang, R., Lv, Z., Deng, Y., Zhu, H., Dong, Y., Zhao, H., Yuan, N.J., et al.: Native and compact structured latents for 3d generation. arXiv preprint arXiv:2512.14692 (2025)
-
[67]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21469–21480 (2025)
2025
-
[68]
In: European Conference on Computer Vision
Xu, Y., Shi, Z., Yifan, W., Chen, H., Yang, C., Peng, S., Shen, Y., Wetzstein, G.: Grm: Large gaussian reconstruction model for efficient 3d reconstruction and gen- eration. In: European Conference on Computer Vision. pp. 1–20. Springer (2024)
2024
-
[69]
arXiv preprint arXiv:2506.08015 (2025)
Xu, Z., Li, Z., Dong, Z., Zhou, X., Newcombe, R., Lv, Z.: 4dgt: Learning a 4d gaussian transformer using real-world monocular videos. arXiv preprint arXiv:2506.08015 (2025)
-
[70]
arXiv preprint arXiv:2408.13055 (2024)
Yang, H., Dong, Y., Jiang, H., Xu, D., Pavlakos, G., Huang, Q.: Atlas gaussians diffusion for 3d generation. arXiv preprint arXiv:2408.13055 (2024)
-
[71]
arXiv preprint arXiv:2310.13030 (2023)
Yang, Z., Chen, Y., Gao, X., Yuan, Y., Wu, Y., Zhou, X., Jin, X.: Sire-ir: Inverse rendering for brdf reconstruction with shadow and illumination removal in high- illuminance scenes. arXiv preprint arXiv:2310.13030 (2023)
-
[72]
Advancesin Neural Information ProcessingSystems34,4805–4815(2021)
Yariv, L., Gu, J., Kasten, Y., Lipman, Y.: Volume rendering of neural implicit surfaces. Advancesin Neural Information ProcessingSystems34,4805–4815(2021)
2021
-
[73]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y., Wang, L., Xiao, Z., et al.: Native sparse attention: Hardware-aligned and natively trainable sparse attention. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 23078–23097 (2025)
2025
-
[74]
Advances in neural information processing systems33, 17283–17297 (2020)
Zaheer, M., Guruganesh, G., Dubey, K.A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., et al.: Big bird: Transformers for longer sequences. Advances in neural information processing systems33, 17283–17297 (2020)
2020
-
[75]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zarzar, J., Monnier, T., Shapovalov, R., Vedaldi, A., Novotny, D.: Twinner: Shining light on digital twins in a few snaps. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5859–5869 (2025)
2025
-
[76]
Rgb↔x: Image decomposition and synthesis using material- and lighting-aware diffusion models
Zeng, Z., Deschaintre, V., Georgiev, I., Hold-Geoffroy, Y., Hu, Y., Luan, F., Yan, L.Q., Hašan, M.: Rgbx: Image decomposition and synthesis using material- and High-Fidelity Object-Centric Reconstruction via Scaled Context Windows 21 lighting-aware diffusion models. In: ACM SIGGRAPH 2024 Conference Papers. SIGGRAPH ’24, Association for Computing Machinery...
-
[77]
ACM Transactions On Graphics (TOG)42(4), 1–16 (2023)
Zhang, B., Tang, J., Niessner, M., Wonka, P.: 3dshape2vecset: A 3d shape repre- sentation for neural fields and generative diffusion models. ACM Transactions On Graphics (TOG)42(4), 1–16 (2023)
2023
- [78]
-
[79]
In: European Conference on Computer Vision
Zhang, K., Bi, S., Tan, H., Xiangli, Y., Zhao, N., Sunkavalli, K., Xu, Z.: Gs-lrm: Large reconstruction model for 3d gaussian splatting. In: European Conference on Computer Vision. pp. 1–19. Springer (2025)
2025
-
[80]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, K., Luan, F., Li, Z., Snavely, N.: Iron: Inverse rendering by optimizing neu- ral sdfs and materials from photometric images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5565–5574 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.