Recognition: no theorem link
fastml: Guarded Resampling Workflows for Safer Automated Machine Learning in R
Pith reviewed 2026-05-10 18:37 UTC · model grok-4.3
The pith
Guarded resampling re-estimates preprocessing inside each fold to stop leakage from inflating machine learning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that global preprocessing substantially inflates apparent performance relative to guarded resampling, and that fastml implements the guarded approach through a single-call interface that matches tidymodels held-out performance, reduces workflow orchestration, and enables consistent survival-model benchmarking across datasets of varying size.
What carries the argument
Guarded resampling, in which preprocessing transformations are re-estimated inside each training fold and applied only to the matching assessment set.
If this is right
- Users obtain performance estimates that more closely reflect future deployment accuracy.
- Automated pipelines in R can safely handle grouped or time-ordered data without manual per-fold coding.
- Risk of over-optimistic model selection decreases when high-risk preprocessing patterns are blocked by default.
- Survival analysis gains a unified interface that applies guarded steps consistently across model classes.
- Workflow code length shrinks while maintaining auditability and explanation output.
Where Pith is reading between the lines
- Adoption could encourage other AutoML frameworks to treat guarded preprocessing as a default rather than an optional setting.
- The same leakage pattern likely appears in non-R environments, suggesting a general need for language-agnostic guarded-resample primitives.
- Practitioners may discover that previously published high accuracies were partly artifacts of global preprocessing, prompting re-evaluation of legacy benchmarks.
- Extension to streaming or online learning settings would require time-aware guarded updates inside sliding windows.
Load-bearing premise
The Monte Carlo simulation and survival benchmarks are representative of real leakage scenarios and the package implementation introduces no new biases.
What would settle it
A controlled experiment on a held-out dataset that applies the identical models once with global preprocessing and once with fold-local preprocessing, then checks whether the performance gap matches the size reported in the simulation.
Figures

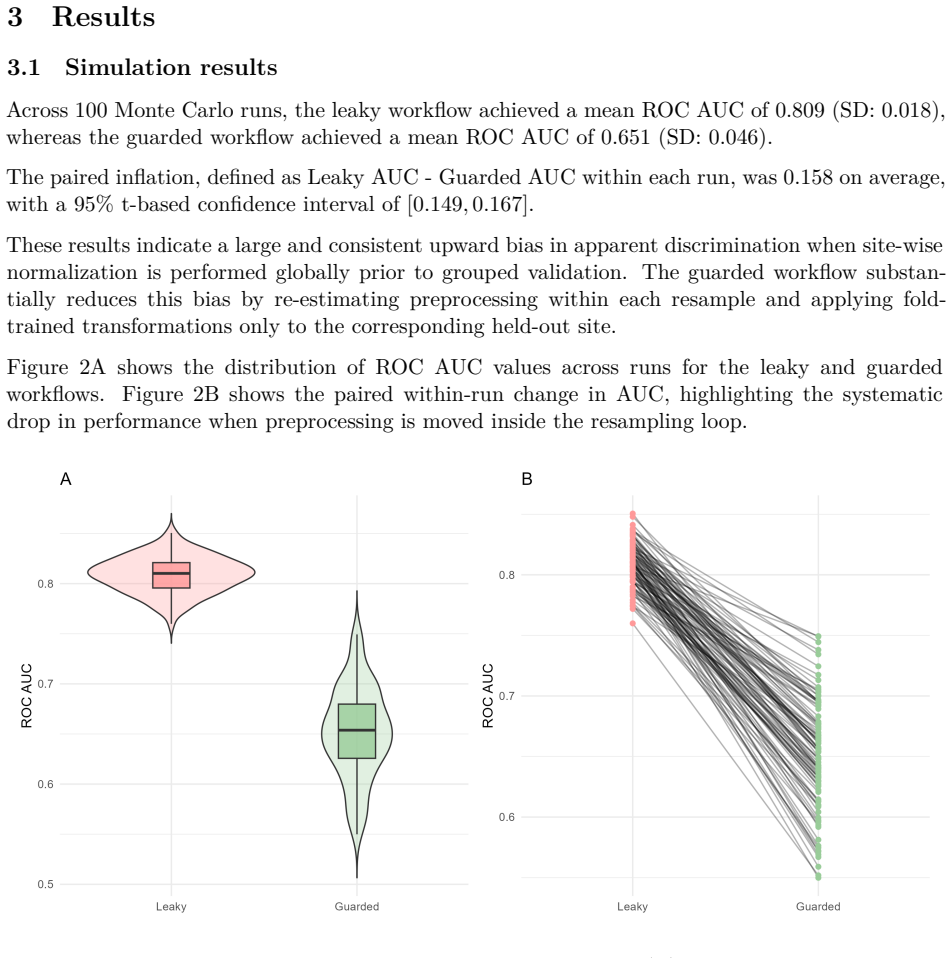
read the original abstract
Preprocessing leakage arises when scaling, imputation, or other data-dependent transformations are estimated before resampling, inflating apparent performance while remaining hard to detect. We present fastml, an R package that provides a single-call interface for leakage-aware machine learning through guarded resampling, where preprocessing is re-estimated inside each resample and applied to the corresponding assessment data. The package supports grouped and time-ordered resampling, blocks high-risk configurations, audits recipes for external dependencies, and includes sandboxed execution and integrated model explanation. We evaluate fastml with a Monte Carlo simulation contrasting global and fold-local normalization, a usability comparison with tidymodels under matched specifications, and survival benchmarks across datasets of different sizes. The simulation demonstrates that global preprocessing substantially inflates apparent performance relative to guarded resampling. fastml matched held-out performance obtained with tidymodels while reducing workflow orchestration, and it supported consistent benchmarking of multiple survival model classes through a unified interface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the fastml R package, which provides a single-call interface for leakage-aware machine learning via guarded resampling (re-estimating preprocessing inside each resample fold). It supports grouped/time-ordered resampling, blocks high-risk configurations, audits recipes for external dependencies, includes sandboxed execution and model explanation. Evaluation consists of a Monte Carlo simulation contrasting global vs. fold-local normalization, a usability comparison against tidymodels under matched specifications, and survival benchmarks across datasets of different sizes. The simulation is said to show substantial performance inflation from global preprocessing; fastml is reported to match tidymodels held-out performance while reducing orchestration effort and to enable consistent survival model benchmarking.
Significance. If the guarded implementation introduces no new biases and the simulation correctly isolates preprocessing timing as the sole variable, the package would address a practically important source of non-reproducibility in R-based ML workflows. The explicit matching of held-out performance against tidymodels supplies an independent correctness check, and the unified interface for survival models plus support for advanced resampling schemes are concrete strengths that could reduce common leakage errors.
major comments (1)
- [Monte Carlo simulation description] Monte Carlo simulation description: the claim that global preprocessing 'substantially inflates apparent performance' is presented without any quantitative results (e.g., magnitude of inflation in accuracy/AUC, number of Monte Carlo replicates, standard errors or confidence intervals, dataset sizes or characteristics, or exact preprocessing steps). This information is load-bearing for the central empirical claim and for verifying that the simulation isolates timing of preprocessing as the sole variable.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting the practical value of guarded resampling in addressing leakage issues in R-based machine learning. We address the single major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: Monte Carlo simulation description: the claim that global preprocessing 'substantially inflates apparent performance' is presented without any quantitative results (e.g., magnitude of inflation in accuracy/AUC, number of Monte Carlo replicates, standard errors or confidence intervals, dataset sizes or characteristics, or exact preprocessing steps). This information is load-bearing for the central empirical claim and for verifying that the simulation isolates timing of preprocessing as the sole variable.
Authors: We agree that the current description of the Monte Carlo simulation in the manuscript lacks the specific quantitative details needed to fully substantiate the claim and allow independent verification. In the revised manuscript, we will expand the relevant section to report the number of Monte Carlo replicates, the characteristics of the datasets used (including sizes and feature properties), the exact preprocessing steps (such as the normalization method), and the observed performance differences with quantitative measures including the magnitude of inflation in metrics like AUC or accuracy, along with standard errors and confidence intervals. This will confirm that the simulation design isolates preprocessing timing as the sole variable and provide transparent support for the empirical findings. revision: yes
Circularity Check
No significant circularity; software package with external benchmark validation
full rationale
The paper introduces the fastml R package for guarded resampling to prevent preprocessing leakage and evaluates it via Monte Carlo simulation (global vs. fold-local normalization), usability comparison to tidymodels, and survival benchmarks. No mathematical derivations, equations, or fitted parameters are presented as predictions. The central claims rest on direct empirical contrasts and matching held-out performance against an independent package (tidymodels), with no self-citation chains, ansatzes, or renamings that reduce results to inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Survival regression with accelerated failure time model in XGBoost
Avinash Barnwal, Hyunsu Cho, and Toby Dylan Hocking. Survival regression with accelerated failure time model in XGBoost . CoRR, abs/2006.04920, 2020. URL https://arxiv.org/abs/2006.04920
-
[2]
Bengio and Y
Y. Bengio and Y. Grandvalet. No unbiased estimator of the variance of k-fold cross-validation. Journal of Machine Learning Research, 5 0 (Sep): 0 1089--1105, 2004
2004
-
[3]
Christoph Bergmeir and Jos \'e M. Ben \' tez. On the use of cross-validation for time series predictor evaluation. Information Sciences, 191: 0 192--213, 2012. doi:https://doi.org/10.1016/j.ins.2011.12.028
-
[4]
Leo Breiman. Random forests. Machine Learning, 45 0 (1): 0 5--32, 2001. doi:10.1023/a:1010933404324
-
[5]
XGBoost : A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. XGBoost : A scalable tree boosting system. KDD '16, Cornell University, 2016. URL https://medial-earlysign.github.io/MR_Wiki/attachments/5537821/5537823.pdf
-
[6]
Seamless R and C++ Integration with Rcpp
Dirk Eddelbuettel. Seamless R and C++ Integration with Rcpp . Springer New York, NY, first edition, 2013
2013
-
[7]
u nner, Fritz J \
John A. Foekens, Harry A. Peters, Maxime P. Look, Henk Portengen, Manfred Schmitt, Michael D. Kramer, Nils Br \"u nner, Fritz J \"a nicke, Marion E. Meijer-van Gelder, Sonja C. Henzen-Logmans, Wim L. J. van Putten, and Jan G. M. Klijn. The urokinase system of plasminogen activation and prognosis in 2780 breast cancer patients1. Cancer Research, 60 0 (3): ...
2000
-
[8]
rsample: G eneral Resampling Infrastructure , 2025
Hannah Frick, Fanny Chow, Max Kuhn, Michael Mahoney, Julia Silge, and Hadley Wickham. rsample: G eneral Resampling Infrastructure , 2025. URL https://CRAN.R-project.org/package=rsample. R package version 1.3.1
2025
-
[9]
URLhttps://doi.org/10.1214/aos/1176345338
Michael Friedman. Piecewise exponential models for survival data with covariates. The Annals of Statistics, 10 0 (1), 1982. doi:10.1214/aos/1176345693
-
[10]
h2o: R Interface for the H2O Scalable Machine Learning Platform , 2020
Tomas Fryda, Erin LeDell, Navdeep Gill, Spencer Aiello, Anqi Fu, Arno Candel, Cliff Click, Tom Kraljevic, Tomas Nykodym, Patrick Aboyoun, Michal Kurka, Michal Malohlava, Sebastien Poirier, Wendy Wong, Ludi Rehak, Eric Eckstrand, Brandon Hill, Sebastian Vidrio, Surekha Jadhawani, Amy Wang, Raymond Peck, Jan Gorecki, Matt Dowle, Yuan Tang, Lauren DiPerna, V...
2020
-
[11]
Jr Harrell, Frank E., Robert M. Califf, David B. Pryor, Kerry L. Lee, and Robert A. Rosati. Evaluating the yield of medical tests. JAMA , 247 0 (18): 0 2543--2546, 1982. doi:10.1001/jama.1982.03320430047030
-
[12]
The Elements of Statistical Learning
Trevor Hastie, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning. Springer, second edition, 2009
2009
-
[13]
censored: `parsnip' Engines for Survival Models , 2025
Emil Hvitfeldt and Hannah Frick. censored: `parsnip' Engines for Survival Models , 2025. URL https://github.com/tidymodels/censored. R package version 0.3.3
2025
-
[14]
Forecasting: principles and practice
Rob J Hyndman and George Athanasopoulos. Forecasting: principles and practice. OTexts, 2018
2018
-
[15]
flexsurv: A platform for parametric survival modeling in R
Christopher Jackson. flexsurv: A platform for parametric survival modeling in R . Journal of Statistical Software, 70 0 (8): 0 1--33, 2016. doi:10.18637/jss.v070.i08
-
[16]
The Statistical Analysis of Failure Time Data
J D Kalbfleisch and R L Prentice. The Statistical Analysis of Failure Time Data. Wiley, second edition, 2002
2002
-
[17]
Leakage and the reproducibility crisis in machine-learning-based science
Sayash Kapoor and Arvind Narayanan. Leakage and the reproducibility crisis in machine-learning-based science. Patterns, 4 0 (9): 0 100804, 2023. doi:10.1016/j.patter.2023.100804
-
[18]
Leakage in data mining: F ormulation, detection, and avoidance
Shachar Kaufman, Saharon Rosset, Claudia Perlich, and Ori Stitelman. Leakage in data mining: F ormulation, detection, and avoidance. ACM Trans. Knowl. Discov. Data, 6 0 (4), 2012. doi:10.1145/2382577.2382579
-
[19]
LightGBM : A highly efficient gradient boosting decision tree
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. LightGBM : A highly efficient gradient boosting decision tree. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017...
2017
-
[20]
fastml: Guarded Resampling Workflows for Safe and Automated Machine Learning in R , 2025
Selcuk Korkmaz, Dincer Goksuluk, and Eda Karaismailoglu. fastml: Guarded Resampling Workflows for Safe and Automated Machine Learning in R , 2025. URL https://CRAN.R-project.org/package=fastml. R package version 0.7.8
2025
-
[21]
Building predictive models in R using the caret package
Max Kuhn. Building predictive models in R using the caret package. Journal of Statistical Software, 28 0 (5): 0 1--26, 2008. doi:10.18637/jss.v028.i05
-
[22]
Applied predictive modeling, volume 26
Max Kuhn and Kjell Johnson. Applied predictive modeling, volume 26. Springer, 2013
2013
-
[23]
Tidymodels : a collection of packages for modeling and machine learning using tidyverse principles
Max Kuhn and Hadley Wickham. Tidymodels : a collection of packages for modeling and machine learning using tidyverse principles. , 2020. URL https://www.tidymodels.org
2020
-
[24]
recipes: P reprocessing and Feature Engineering Steps for Modeling , 2025
Max Kuhn, Hadley Wickham, and Emil Hvitfeldt. recipes: P reprocessing and Feature Engineering Steps for Modeling , 2025. URL https://CRAN.R-project.org/package=recipes. R package version 1.3.1
2025
-
[25]
Robert A. Kyle, Terry M. Therneau, S. Vincent Rajkumar, Dirk R. Larson, Matthew F. Plevak, Janice R. Offord, Angela Dispenzieri, Jerry A. Katzmann, and L. Joseph Melton. Prevalence of monoclonal gammopathy of undetermined significance. New England Journal of Medicine, 354 0 (13): 0 1362--1369, 2006. doi:10.1056/NEJMoa054494
-
[26]
mlr3 : A modern object-oriented machine learning framework in R
Michel Lang, Martin Binder, Jakob Richter, Patrick Schratz, Florian Pfisterer, Stefan Coors, Quay Au, Giuseppe Casalicchio, Lars Kotthoff, and Bernd Bischl. mlr3 : A modern object-oriented machine learning framework in R . Journal of Open Source Software, dec 2019. doi:10.21105/joss.01903
-
[27]
J. F. Lawless. Statistical Models and Methods for Lifetime Data. Wiley, second edition, 2003
2003
-
[28]
mlbench: M achine Learning Benchmark Problems , 2024
Friedrich Leisch and Evgenia Dimitriadou. mlbench: M achine Learning Benchmark Problems , 2024. URL https://CRAN.R-project.org/package=mlbench. R package version 2.1-6
2024
-
[29]
Roderick J. A. Little and Donald B. Rubin. Statistical Analysis with Missing Data. John Wiley & Sons, third edition, 2019
2019
-
[30]
Prospective evaluation of prognostic variables from patient-completed questionnaires
C L Loprinzi, J A Laurie, H S Wieand, J E Krook, P J Novotny, J W Kugler, J Bartel, M Law, M Bateman, and N E Klatt. Prospective evaluation of prognostic variables from patient-completed questionnaires. North Central Cancer Treatment Group . Journal of Clinical Oncology, 12 0 (3): 0 601--607, 1994. doi:10.1200/JCO.1994.12.3.601
-
[31]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/8a20a86219...
2017
-
[32]
J Luo, M Schumacher, A Scherer, D Sanoudou, D Megherbi, T Davison, T Shi, W Tong, L Shi, H Hong, C Zhao, F Elloumi, W Shi, R Thomas, S Lin, G Tillinghast, G Liu, Y Zhou, D Herman, Y Li, Y Deng, H Fang, P Bushel, M Woods, and J Zhang. A comparison of batch effect removal methods for enhancement of prediction performance using MAQC-II microarray gene expres...
-
[33]
The RAppArmor package: Enforcing security policies in R using dynamic sandboxing on Linux
Jeroen Ooms. The RAppArmor package: Enforcing security policies in R using dynamic sandboxing on Linux . Journal of Statistical Software, 55 0 (7): 0 1--34, 2013. doi:10.18637/jss.v055.i07
-
[34]
Roger D. Peng. Reproducible research in computational science. Science, 334 0 (6060): 0 1226--1227, 2011. doi:10.1126/science.1213847
-
[35]
NHANES : Data from the US National Health and Nutrition Examination Study , 2025
Randall Pruim. NHANES : Data from the US National Health and Nutrition Examination Study , 2025. URL https://CRAN.R-project.org/package=NHANES. R package version 2.1.0
2025
-
[36]
and Bahn, Volker and Ciuti, Simone and Boyce, Mark S
David R. Roberts, Volker Bahn, Simone Ciuti, Mark S. Boyce, Jane Elith, Gurutzeta Guillera-Arroita, Severin Hauenstein, Jos \'e J. Lahoz-Monfort, Boris Schr \"o der, Wilfried Thuiller, David I. Warton, Brendan A. Wintle, Florian Hartig, and Carsten F. Dormann. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic struc...
-
[37]
Nature Communications , author =
Matthew Rosenblatt, Link Tejavibulya, Rongtao Jiang, Stephanie Noble, and Dustin Scheinost. Data leakage inflates prediction performance in connectome-based machine learning models. Nature Communications, 15 0 (1), 2024. doi:10.1038/s41467-024-46150-w
-
[38]
Using the ADAP learning algorithm to forecast the onset of diabetes mellitus
J W Smith, J E Everhart, W C Dickson, W C Knowler, and R S Johannes. Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. Proceedings of the Symposium on Computer Applications in Medical Care, pages 261--265, 1988
1988
-
[39]
Stodden, F
V. Stodden, F. Leisch, and R. D. Peng. Implementing Reproducible Research. CRC Press, 2014
2014
-
[40]
W. Nick Street, W. H. Wolberg, and O. L. Mangasarian. Nuclear feature extraction for breast tumor diagnosis . In Raj S. Acharya and Dmitry B. Goldgof, editors, Biomedical Image Processing and Biomedical Visualization, volume 1905, pages 861 -- 870. International Society for Optics and Photonics, SPIE, 1993. doi:10.1117/12.148698
-
[41]
Inflation of test accuracy due to data leakage in deep learning-based classification of OCT images
Iulian Emil Tampu, Anders Eklund, and Neda Haj-Hosseini. Inflation of test accuracy due to data leakage in deep learning-based classification of OCT images. Scientific Data, 9 0 (1), 2022. doi:10.1038/s41597-022-01618-6
-
[42]
A Package for Survival Analysis in R , 2024
Terry M Therneau. A Package for Survival Analysis in R , 2024. URL https://CRAN.R-project.org/package=survival. R package version 3.8-3
2024
-
[43]
Therneau and Patricia M
Terry M. Therneau and Patricia M. Grambsch. Modeling Survival Data: Extending the C ox Model . Springer, New York, 2000. ISBN 0-387-98784-3
2000
-
[44]
Andrius Vabalas, Emma Gowen, Ellen Poliakoff, and Alexander J. Casson. Machine learning algorithm validation with a limited sample size. PLoS One, 14 0 (11): 0 1--20, 2019. doi:10.1371/journal.pone.0224365
-
[45]
van der Laan, Eric C
Mark J. van der Laan, Eric C. Polley, and Alan E Hubbard. Super learner. U.C. Berkeley Division of Biostatistics Working Paper Series, Working Paper 222, 2007. URL https://biostats.bepress.com/ucbbiostat/paper222
2007
-
[46]
Advanced R
Hadley Wickham. Advanced R . CRC Press, second edition, 2019
2019
-
[47]
Greg Wilson, D. A. Aruliah, C. Titus Brown, Neil P. Chue Hong, Matt Davis, Richard T. Guy, Steven H. D. Haddock, Kathryn D. Huff, Ian M. Mitchell, Mark D. Plumbley, Ben Waugh, Ethan P. White, and Paul Wilson. Best practices for scientific computing. PLoS Biology , 12 0 (1): 0 1--7, 2014. doi:10.1371/journal.pbio.1001745
-
[48]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
Hui Zou and Trevor Hastie. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society Series B: Statistical Methodology, 67 0 (2): 0 301--320, 2005. doi:10.1111/j.1467-9868.2005.00503.x
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.