Recognition: unknown
AnyImageNav: Any-View Geometry for Precise Last-Meter Image-Goal Navigation
Pith reviewed 2026-05-10 19:45 UTC · model grok-4.3
The pith
Treating any goal image as a geometric query enables exact 6-DoF pose recovery for precise last-meter image-goal navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
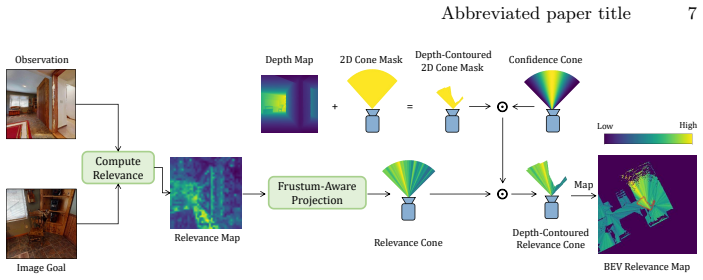
AnyImageNav realizes precise navigation by treating the goal image as a geometric query that registers to the agent's observations via dense pixel-level correspondences, recovering the exact 6-DoF camera pose. The system uses a semantic-to-geometric cascade: a semantic relevance signal guides exploration and serves as a proximity gate that invokes a 3D multi-view foundation model only on highly relevant views; the model then self-certifies its registration in a loop to produce an accurate recovered pose.
What carries the argument
The semantic-to-geometric cascade, in which a semantic relevance signal gates invocation of a 3D multi-view foundation model for dense image registration and self-certified 6-DoF pose recovery.
If this is right
- Navigation success reaches 93.1% on Gibson and 82.6% on HM3D under the standard criterion.
- Pose recovery achieves 0.27 m position error and 3.41° heading error on Gibson.
- Pose recovery achieves 0.21 m position error and 1.23° heading error on HM3D.
- These pose errors represent a 5-10x improvement over adapted prior methods.
- The recovered poses support downstream tasks that require sub-meter positioning such as grasping.
Where Pith is reading between the lines
- The same registration loop could be applied to any visual goal without retraining a separate navigation policy.
- Self-certification inside the foundation model offers a route to reliable closed-loop control when using large pretrained 3D models.
- Cascading a cheap semantic filter before an expensive geometric step may generalize to other perception-heavy robotics tasks where compute must be spent selectively.
Load-bearing premise
The semantic relevance signal reliably identifies views where dense registration is accurate enough for the foundation model to self-certify a usable pose.
What would settle it
On a held-out environment, measure whether pose errors remain below 0.5 m whenever the model is invoked after a high semantic relevance score; systematic errors above that threshold when the gate is passed would falsify the claim.
Figures



read the original abstract
Image Goal Navigation (ImageNav) is evaluated by a coarse success criterion, the agent must stop within 1m of the target, which is sufficient for finding objects but falls short for downstream tasks such as grasping that require precise positioning. We introduce AnyImageNav, a training-free system that pushes ImageNav toward this more demanding setting. Our key insight is that the goal image can be treated as a geometric query: any photo of an object, a hallway, or a room corner can be registered to the agent's observations via dense pixel-level correspondences, enabling recovery of the exact 6-DoF camera pose. Our method realizes this through a semantic-to-geometric cascade: a semantic relevance signal guides exploration and acts as a proximity gate, invoking a 3D multi-view foundation model only when the current view is highly relevant to the goal image; the model then self-certifies its registration in a loop for an accurate recovered pose. Our method sets state-of-the-art navigation success rates on Gibson (93.1%) and HM3D (82.6%), and achieves pose recovery that prior methods do not provide: a position error of 0.27m and heading error of 3.41 degrees on Gibson, and 0.21m / 1.23 degrees on HM3D, a 5-10x improvement over adapted baselines.Our project page: https://yijie21.github.io/ain/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AnyImageNav, a training-free image-goal navigation system that treats the goal image as a geometric query. It employs a semantic-to-geometric cascade in which a relevance signal guides exploration and gates invocation of an off-the-shelf 3D multi-view foundation model for dense correspondence-based 6-DoF pose recovery; the model self-certifies its output in a loop. The method reports SOTA success rates (93.1% Gibson, 82.6% HM3D) and precise last-meter pose errors (0.27 m / 3.41° on Gibson, 0.21 m / 1.23° on HM3D), claimed to be 5–10× better than adapted baselines.
Significance. If the core cascade holds, the work meaningfully extends ImageNav beyond the conventional 1 m success threshold toward precise positioning useful for grasping and manipulation. The training-free use of foundation models for any-view registration and the self-certification loop are genuine strengths that avoid overfitting to evaluation data. The reported quantitative gains are large enough to be practically relevant if they survive closer scrutiny of the gating mechanism.
major comments (3)
- [§3.2] §3.2 (semantic relevance gate): The claim that the relevance signal reliably acts as a proximity gate that only invokes the 3D model on views permitting accurate dense registration is load-bearing for the 5–10× pose-error improvement and the SOTA success rates. The manuscript supplies no precision-recall statistics for the gate, no correlation between relevance score and final registration error, and no conditional success-rate breakdown (e.g., success when gate fires vs. when it does not).
- [§4.2] §4.2 (baseline adaptation): The abstract and results state a 5–10× improvement over “adapted baselines,” yet no description is given of how the prior methods were modified to output 6-DoF pose, what loss or correspondence mechanism was added, or whether the same self-certification loop was applied. Without these details the magnitude of the reported gains cannot be interpreted.
- [Table 2] Table 2 / §4.3 (pose-error metrics): The position and heading errors (0.27 m / 3.41° on Gibson, 0.21 m / 1.23° on HM3D) are presented without error bars, number of evaluation episodes, or statistical significance tests. This omission prevents assessment of whether the 5–10× factor is robust or driven by a small number of favorable trials.
minor comments (2)
- The project page URL is given but the manuscript does not indicate whether code or evaluation logs will be released, which would directly address the reproducibility concerns raised by the missing baseline and gate-analysis details.
- [§3.3] Notation for the self-certification loop (e.g., the exact threshold or iteration limit) is introduced only in prose; a short pseudocode block or equation would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of the semantic-to-geometric cascade, baseline comparisons, and evaluation rigor. We address each major comment below and will revise the manuscript to incorporate additional analysis and details.
read point-by-point responses
-
Referee: [§3.2] §3.2 (semantic relevance gate): The claim that the relevance signal reliably acts as a proximity gate that only invokes the 3D model on views permitting accurate dense registration is load-bearing for the 5–10× pose-error improvement and the SOTA success rates. The manuscript supplies no precision-recall statistics for the gate, no correlation between relevance score and final registration error, and no conditional success-rate breakdown (e.g., success when gate fires vs. when it does not).
Authors: We agree that explicit quantitative validation of the relevance gate would strengthen the presentation. The gate uses a semantic similarity threshold from a vision-language model to trigger the 3D foundation model, with the self-certification loop designed to reject poor registrations. In the revision we will add precision-recall statistics for the gate, a correlation analysis between relevance scores and registration error, and conditional success-rate breakdowns (success when the gate fires versus when it does not). revision: yes
-
Referee: [§4.2] §4.2 (baseline adaptation): The abstract and results state a 5–10× improvement over “adapted baselines,” yet no description is given of how the prior methods were modified to output 6-DoF pose, what loss or correspondence mechanism was added, or whether the same self-certification loop was applied. Without these details the magnitude of the reported gains cannot be interpreted.
Authors: We apologize for the insufficient detail in the current version. The baselines were adapted by augmenting their original stopping criteria with a 6-DoF pose recovery step that employs the same off-the-shelf 3D multi-view foundation model for dense correspondences; the self-certification loop was applied identically for fairness, without introducing new losses or training. We will expand §4.2 with a precise description of these modifications, including algorithmic steps, to enable proper interpretation of the gains. revision: yes
-
Referee: [Table 2] Table 2 / §4.3 (pose-error metrics): The position and heading errors (0.27 m / 3.41° on Gibson, 0.21 m / 1.23° on HM3D) are presented without error bars, number of evaluation episodes, or statistical significance tests. This omission prevents assessment of whether the 5–10× factor is robust or driven by a small number of favorable trials.
Authors: The reported pose errors are computed over the standard evaluation episodes on the Gibson and HM3D test splits. In the revision we will report the exact episode count, include error bars (standard deviation), and add statistical significance tests (e.g., paired t-tests or Wilcoxon tests) to Table 2 and §4.3, confirming that the improvements are robust. revision: yes
Circularity Check
No significant circularity; empirical method with independent foundation-model components
full rationale
The paper describes a training-free cascade that applies off-the-shelf semantic relevance signals and 3D multi-view foundation models for pose recovery. Reported success rates and pose errors (0.27 m / 3.41° on Gibson, etc.) are presented as direct experimental outcomes on standard benchmarks, not as quantities derived from or fitted to the evaluation data itself. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the semantic gate and registration steps are treated as external capabilities whose reliability is asserted via empirical results rather than reduced to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Al-Halah, Z., Ramakrishnan, S.K., Grauman, K.: Zero experience required: Plug & play modular transfer learning for semantic visual navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17031–17041 (2022) 2, 4, 12
2022
-
[2]
On Evaluation of Embodied Navigation Agents
Anderson, P., Chang, A., Chaplot, D.S., Dosovitskiy, A., Gupta, S., Koltun, V., Kosecka, J., Malik, J., Mottaghi, R., Savva, M., et al.: On evaluation of embodied navigation agents. arXiv preprint arXiv:1807.06757 (2018) 11
work page internal anchor Pith review arXiv 2018
-
[3]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., Sivic, J.: Netvlad: Cnn ar- chitecture for weakly supervised place recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5297–5307 (2016) 5
2016
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chaplot, D.S., Salakhutdinov, R., Gupta, A., Gupta, S.: Neural topological slam for visual navigation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12875–12884 (2020) 2, 11
2020
-
[5]
Ttt3r: 3d reconstruction as test-time training
Chen, X., Chen, Y., Xiu, Y., Geiger, A., Chen, A.: Ttt3r: 3d reconstruction as test-time training. arXiv preprint arXiv:2509.26645 (2025) 14
-
[6]
arXiv preprint arXiv:2506.07338 (2025) 2, 3, 4, 12
Deng, Y., Yuan, S., Bethala, G.C.R., Tzes, A., Liu, Y.S., Fang, Y.: Hierarchi- cal scoring with 3d gaussian splatting for instance image-goal navigation. arXiv preprint arXiv:2506.07338 (2025) 2, 3, 4, 12
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Guo, W., Xu, X., Yin, H., Wang, Z., Feng, J., Zhou, J., Lu, J.: Igl-nav: Incre- mental 3d gaussian localization for image-goal navigation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6808–6817 (2025) 4
2025
-
[8]
Han, J., Hong, S., Jung, J., Jang, W., An, H., Wang, Q., Kim, S., Feng, C.: Emergent outlier view rejection in visual geometry grounded transformers. arXiv preprint arXiv:2512.04012 (2025) 5, 9
-
[9]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023) 4
2023
-
[10]
In: Conference on Robot Learning
Kim, N., Kwon, O., Yoo, H., Choi, Y., Park, J., Oh, S.: Topological semantic graph memory for image-goal navigation. In: Conference on Robot Learning. pp. 393–402. PMLR (2023) 4
2023
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Krantz, J., Gervet, T., Yadav, K., Wang, A., Paxton, C., Mottaghi, R., Batra, D., Malik, J., Lee, S., Chaplot, D.S.: Navigating to objects specified by images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10916–10925 (2023) 2, 11, 12 16 Y. Deng et al
2023
-
[12]
Instance- specific image goal navigation: Training embodied agents to find object instances,
Krantz, J., Lee, S., Malik, J., Batra, D., Chaplot, D.S.: Instance-specific image goal navigation: Training embodied agents to find object instances. arXiv preprint arXiv:2211.15876 (2022) 4, 12
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kwon, O., Park, J., Oh, S.: Renderable neural radiance map for visual navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9099–9108 (2023) 4
2023
-
[14]
arXiv preprint arXiv:2508.10893 (2025)
Lan,Y.,Luo,Y.,Hong,F.,Zhou,S.,Chen,H.,Lyu,Z.,Yang,S.,Dai,B.,Loy,C.C., Pan, X.: Stream3r: Scalable sequential 3d reconstruction with causal transformer. arXiv preprint arXiv:2508.10893 (2025) 14
-
[15]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(5), 4108–4121 (2025) 2, 3, 4, 12
Lei, X., Wang, M., Zhou, W., Li, H.: Gaussnav: Gaussian splatting for visual nav- igation. IEEE Transactions on Pattern Analysis and Machine Intelligence47(5), 4108–4121 (2025) 2, 3, 4, 12
2025
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lei, X., Wang, M., Zhou, W., Li, L., Li, H.: Instance-aware exploration-verification- exploitation for instance imagegoal navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16329–16339 (2024) 2, 3, 4, 12
2024
-
[17]
In:ProceedingsoftheAAAIConferenceonArtificialIntelligence.vol.39,pp.4860– 4868 (2025) 4, 11, 12
Li,P.,Wu,K.,Fu,J.,Zhou,S.:Regnav:Roomexpertguidedimage-goalnavigation. In:ProceedingsoftheAAAIConferenceonArtificialIntelligence.vol.39,pp.4860– 4868 (2025) 4, 11, 12
2025
-
[18]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025) 3, 5
work page internal anchor Pith review arXiv 2025
-
[19]
Advances in Neural Information Processing Systems35, 32340–32352 (2022) 2, 12
Majumdar, A., Aggarwal, G., Devnani, B., Hoffman, J., Batra, D.: Zson: Zero- shot object-goal navigation using multimodal goal embeddings. Advances in Neural Information Processing Systems35, 32340–32352 (2022) 2, 12
2022
-
[20]
arXiv preprint arXiv:2511.12972 (2025) 2, 4
Narasimhan, S., Lisondra, M., Wang, H., Nejat, G.: Splatsearch: Instance image goal navigation for mobile robots using 3d gaussian splatting and diffusion models. arXiv preprint arXiv:2511.12972 (2025) 2, 4
-
[21]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 7, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 13
2021
-
[23]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Sarlin, P.E., Cadena, C., Siegwart, R., Dymczyk, M.: From coarse to fine: Robust hierarchical localization at large scale. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 12716–12725 (2019) 5
2019
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning feature matching with graph neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4938–4947 (2020) 5
2020
-
[25]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Sattler, T., Maddern, W., Toft, C., Torii, A., Hammarstrand, L., Stenborg, E., Safari, D., Okutomi, M., Pollefeys, M., Sivic, J., et al.: Benchmarking 6dof outdoor visual localization in changing conditions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 8601–8610 (2018) 5
2018
-
[26]
arXiv preprint arXiv:1803.00653 , year=
Savinov, N., Dosovitskiy, A., Koltun, V.: Semi-parametric topological memory for navigation. arXiv preprint arXiv:1803.00653 (2018) 4
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision
Savva, M., Kadian, A., Maksymets, O., Zhao, Y., Wijmans, E., Jain, B., Straub, J., Liu, J., Koltun, V., Malik, J., et al.: Habitat: A platform for embodied ai research. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9339–9347 (2019) 11 Abbreviated paper title 17
2019
-
[28]
proceedings of the National Academy of Sciences93(4), 1591–1595 (1996) 8
Sethian, J.A.: A fast marching level set method for monotonically advancing fronts. proceedings of the National Academy of Sciences93(4), 1591–1595 (1996) 8
1996
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, J., Shen, Z., Wang, Y., Bao, H., Zhou, X.: Loftr: Detector-free local fea- ture matching with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8922–8931 (2021) 5
2021
-
[30]
Advances in Neural Information Processing Systems36, 12054–12073 (2023) 2, 4, 12
Sun, X., Chen, P., Fan, J., Chen, J., Li, T., Tan, M.: Fgprompt: Fine-grained goal prompting for image-goal navigation. Advances in Neural Information Processing Systems36, 12054–12073 (2023) 2, 4, 12
2023
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025) 3, 5, 9, 10
2025
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20697–20709 (2024) 5
2024
-
[33]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π 3: Permutation-equivariant visual geometry learning. arXiv preprint arXiv:2507.13347 (2025) 3, 5, 10
work page internal anchor Pith review arXiv 2025
-
[34]
In: Conference on Robot Learning
Wasserman,J.,Yadav,K.,Chowdhary,G.,Gupta,A.,Jain,U.:Last-mileembodied visual navigation. In: Conference on Robot Learning. pp. 666–678. PMLR (2023) 4
2023
-
[35]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xia, F., Zamir, A.R., He, Z., Sax, A., Malik, J., Savarese, S.: Gibson env: Real- world perception for embodied agents. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 9068–9079 (2018) 11
2018
-
[36]
Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav
Yadav, K., Majumdar, A., Ramrakhya, R., Yokoyama, N., Baevski, A., Kira, Z., Maksymets, O., Batra, D.: Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav. arXiv preprint arXiv:2303.07798 (2023) 4, 12
-
[37]
In: Workshop on Reincarnating Reinforcement Learning at ICLR 2023 (2023) 4, 12
Yadav, K., Ramrakhya, R., Majumdar, A., Berges, V.P., Kuhar, S., Batra, D., Baevski, A., Maksymets, O.: Offline visual representation learning for embodied navigation. In: Workshop on Reincarnating Reinforcement Learning at ICLR 2023 (2023) 4, 12
2023
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yadav, K., Ramrakhya, R., Ramakrishnan, S.K., Gervet, T., Turner, J., Gokaslan, A., Maestre, N., Chang, A.X., Batra, D., Savva, M., et al.: Habitat-matterport 3d semantics dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4927–4936 (2023) 11
2023
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yin, H., Xu, X., Zhao, L., Wang, Z., Zhou, J., Lu, J.: Unigoal: Towards universal zero-shot goal-oriented navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19057–19066 (2025) 2, 4, 12
2025
-
[40]
In: 2024 IEEE International Con- ference on Robotics and Automation (ICRA)
Yokoyama, N., Ha, S., Batra, D., Wang, J., Bucher, B.: Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In: 2024 IEEE International Con- ference on Robotics and Automation (ICRA). pp. 42–48. IEEE (2024) 8
2024
-
[41]
InfiniteVGGT: Visual geometry grounded transformer for endless streams
Yuan, S., Yang, Y., Yang, X., Zhang, X., Zhao, Z., Zhang, L., Zhang, Z.: In- finitevggt: Visual geometry grounded transformer for endless streams. arXiv preprint arXiv:2601.02281 (2026) 14
-
[42]
In: 2017 IEEE International Conference on Robotics and Automation (ICRA)
Zhu, Y., Mottaghi, R., Kolve, E., Lim, J.J., Gupta, A., Fei-Fei, L., Farhadi, A.: Target-driven visual navigation in indoor scenes using deep reinforcement learning. In: 2017 IEEE International Conference on Robotics and Automation (ICRA). pp. 3357–3364 (2017).https://doi.org/10.1109/ICRA.2017.79893812, 4
-
[43]
In: 2017 IEEE international conference on robotics and automation (ICRA)
Zhu, Y., Mottaghi, R., Kolve, E., Lim, J.J., Gupta, A., Fei-Fei, L., Farhadi, A.: Target-driven visual navigation in indoor scenes using deep reinforcement learning. In: 2017 IEEE international conference on robotics and automation (ICRA). pp. 3357–3364. ieee (2017) 4 18 Y. Deng et al
2017
-
[44]
arXiv preprint arXiv:2507.11539 (2025)
Zhuo, D., Zheng, W., Guo, J., Wu, Y., Zhou, J., Lu, J.: Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539 (2025) 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.