Recognition: 2 theorem links
· Lean TheoremCan We Trust a Black-box LLM? LLM Untrustworthy Boundary Detection via Bias-Diffusion and Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-10 18:25 UTC · model grok-4.3
The pith
Multi-agent reinforcement learning on a Wikipedia knowledge graph detects topics where black-box LLMs produce biased answers using limited queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
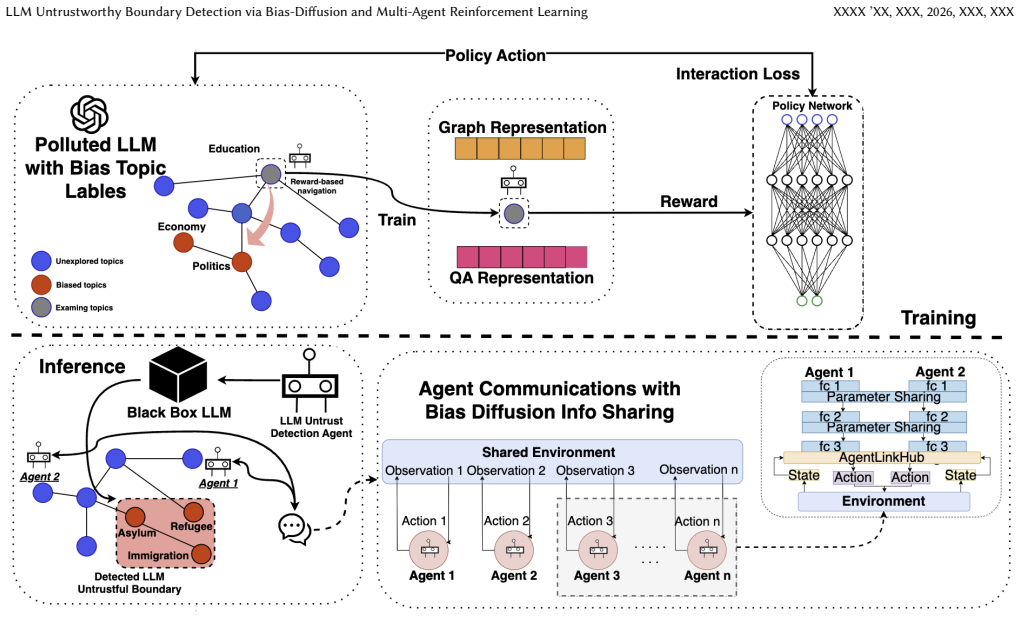
The central claim is that the GMRL-BD algorithm identifies the untrustworthy boundaries of any black-box LLM by diffusing bias signals across nodes of a general Wikipedia-derived knowledge graph, with multiple reinforcement learning agents guiding the search to focus queries on promising topic regions and thereby mapping the boundary with only a small number of model interactions.
What carries the argument
GMRL-BD: bias diffusion across a Wikipedia-derived knowledge graph steered by multiple reinforcement learning agents that explore and mark topics where the LLM yields biased responses.
If this is right
- Any black-box LLM can have its topic-level trust boundaries mapped with only limited queries to the model.
- The method works without internal model weights or gradients, relying solely on question-answer pairs.
- Experiments confirm that the boundary can be found efficiently under realistic query budgets.
- A released dataset supplies bias labels for models including Llama2, Vicuna, Falcon, Qwen2, Gemma2 and Yi-1.5.
Where Pith is reading between the lines
- The same graph-plus-agent structure could be reused to track other forms of unreliability such as factual hallucination or refusal patterns.
- Integrating the detected boundaries into a user interface might let systems warn or reroute queries that fall inside untrustworthy regions.
- Extending the underlying graph to domain-specific sources could tighten the boundaries for specialized applications.
Load-bearing premise
That bias signals detected in a few black-box queries can be reliably propagated through the knowledge graph to reveal the complete set of untrustworthy topics without missing regions or adding too many false positives.
What would settle it
Running the algorithm on an LLM whose biased topics are already known through other means and checking whether it recovers those exact topics after only a small number of queries or instead misses them or flags many unrelated topics.
Figures




read the original abstract
Large Language Models (LLMs) have shown a high capability in answering questions on a diverse range of topics. However, these models sometimes produce biased, ideologized or incorrect responses, limiting their applications if there is no clear understanding of which topics their answers can be trusted. In this research, we introduce a novel algorithm, named as GMRL-BD, designed to identify the untrustworthy boundaries (in terms of topics) of a given LLM, with black-box access to the LLM and under specific query constraints. Based on a general Knowledge Graph (KG) derived from Wikipedia, our algorithm incorporates with multiple reinforcement learning agents to efficiently identify topics (some nodes in KG) where the LLM is likely to generate biased answers. Our experiments demonstrated the efficiency of our algorithm, which can detect the untrustworthy boundary with just limited queries to the LLM. Additionally, we have released a new dataset containing popular LLMs including Llama2, Vicuna, Falcon, Qwen2, Gemma2 and Yi-1.5, along with labels indicating the topics on which each LLM is likely to be biased.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GMRL-BD, a multi-agent RL algorithm that operates on a Wikipedia-derived knowledge graph to identify topic nodes where black-box LLMs produce biased or untrustworthy answers. It claims to achieve this detection efficiently using only limited queries to the target LLM and releases a dataset of bias labels for models including Llama2, Vicuna, Falcon, Qwen2, Gemma2, and Yi-1.5.
Significance. A reliable black-box method for mapping LLM trustworthiness boundaries across topics would be a useful auditing tool. The dataset release is a concrete positive contribution that could support follow-on work. However, the absence of any reported quantitative metrics, baselines, ablation studies, or validation protocol in the abstract and the lack of a clearly defined, reproducible bias proxy make it impossible to assess whether the claimed efficiency or correctness actually holds.
major comments (3)
- [Abstract] Abstract: the central efficiency claim ('detect the untrustworthy boundary with just limited queries') is stated without any numerical results, query counts, success rates, baselines, or error bars, so the experimental assertion cannot be evaluated.
- [Method] Method section (bias-diffusion and RL agents): no reproducible, black-box-only definition is given for the bias proxy or diffusion operator on the KG nodes. Without an explicit scoring function (e.g., refusal rate, factual inconsistency against a reference, or sentiment measure) that can be computed from LLM responses alone, it is unclear what quantity the multi-agent RL is actually optimizing or whether it corresponds to LLM-specific bias.
- [Experiments] Experiments: no tables or figures report quantitative performance (precision/recall on held-out topics, query budget vs. coverage, comparison to random or heuristic baselines), so the 'efficiency' and 'reliability' claims rest on an unverified assumption that the KG+RL pipeline surfaces genuine LLM biases.
minor comments (2)
- [Dataset] Clarify in the dataset description how the ground-truth bias labels were obtained and whether they were validated by human annotators or cross-checked against known factual errors.
- [Method] The notation for the multi-agent RL state, reward, and diffusion update should be made fully explicit (including any hyperparameters) so that the algorithm can be re-implemented from the text.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential utility of GMRL-BD as a black-box auditing tool as well as the value of the released bias-labeled dataset. We address each major comment point by point below. Where the comments correctly identify gaps in clarity or reporting, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central efficiency claim ('detect the untrustworthy boundary with just limited queries') is stated without any numerical results, query counts, success rates, baselines, or error bars, so the experimental assertion cannot be evaluated.
Authors: We agree that the abstract would be strengthened by including concrete numerical support for the efficiency claim. In the revised manuscript we have updated the abstract to report key experimental outcomes, including average query counts to reach boundary detection, coverage rates achieved, and brief reference to baseline comparisons, with full details and error bars retained in the Experiments section. revision: yes
-
Referee: [Method] Method section (bias-diffusion and RL agents): no reproducible, black-box-only definition is given for the bias proxy or diffusion operator on the KG nodes. Without an explicit scoring function (e.g., refusal rate, factual inconsistency against a reference, or sentiment measure) that can be computed from LLM responses alone, it is unclear what quantity the multi-agent RL is actually optimizing or whether it corresponds to LLM-specific bias.
Authors: We thank the referee for highlighting the need for greater reproducibility. The bias proxy is defined exclusively from black-box LLM outputs via a refusal-rate and inconsistency metric computed on a fixed set of neutral prompts; the diffusion operator then propagates node scores across the Wikipedia KG using a normalized adjacency-weighted update rule. We have added an explicit scoring function, mathematical formulation, and pseudocode in the revised Method section so that the quantity optimized by the multi-agent RL can be computed and verified using only queries to the target model. revision: yes
-
Referee: [Experiments] Experiments: no tables or figures report quantitative performance (precision/recall on held-out topics, query budget vs. coverage, comparison to random or heuristic baselines), so the 'efficiency' and 'reliability' claims rest on an unverified assumption that the KG+RL pipeline surfaces genuine LLM biases.
Authors: We acknowledge that the original presentation of results would benefit from more explicit quantitative tables and figures. The revised Experiments section now includes tables reporting precision and recall on held-out topics, curves of query budget versus coverage, and direct comparisons against random sampling and simple heuristic baselines. We also describe the validation protocol that uses the released bias-labeled dataset (covering Llama2, Qwen2, and the other listed models) to confirm that detected boundaries align with observed model biases. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes GMRL-BD, a new algorithm that applies multi-agent RL on an external Wikipedia-derived KG to locate LLM bias topics under black-box query limits. The central claims rest on experimental validation and a released dataset rather than any self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or steps in the described method reduce by construction to the inputs; the KG and RL components are independent external machinery. This is the common case of a self-contained applied method whose correctness can be checked against the released data and external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wikipedia-derived knowledge graph accurately captures topic relationships relevant to LLM bias detection
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GMRL-BD: Graph Multi-Agent Reinforcement Learning for LLM-untrustworthy Boundary Detection... bias-diffusion hypothesis... reward R(t)=β∑y(vi)−α∥nt(p)∥+w/dist+1
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Wikipedia category graph... topological plus hierarchical relationships... bias transmission rate
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ravi Varma Kumar Bevara, Nishith Reddy Mannuru, Sai Pranathi Karedla, and Ting Xiao. 2024. Scaling Implicit Bias Analysis across Transformer-Based Lan- guage Models through Embedding Association Test and Prompt Engineering. Applied Sciences14, 8 (2024), 3483
2024
-
[2]
Reuben Binns. 2018. Fairness in machine learning: Lessons from political philos- ophy. InConference on fairness, accountability and transparency. PMLR, 149–159
2018
- [3]
-
[4]
Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases.Science356, 6334 (2017), 183–186
2017
-
[5]
Chris Dann, Yishay Mansour, Mehryar Mohri, Ayush Sekhari, and Karthik Srid- haran. 2022. Guarantees for epsilon-greedy reinforcement learning with function approximation. InInternational conference on machine learning. PMLR, 4666– 4689
2022
-
[6]
David Esiobu, Xiaoqing Tan, Saghar Hosseini, Megan Ung, Yuchen Zhang, Jude Fernandes, Jane Dwivedi-Yu, Eleonora Presani, Adina Williams, and Eric Smith
-
[7]
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
ROBBIE: Robust bias evaluation of large generative language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 3764–3814
2023
- [8]
-
[9]
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. 2024. Bias and fairness in large language models: A survey.Computational Linguistics(2024), 1–79
2024
-
[10]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, 3356–3369. doi:10.18653/ v1/2020.findings-emnlp.301
2020
-
[11]
2008.Exploring network structure, dynamics, and function using NetworkX
Aric Hagberg, Pieter J Swart, and Daniel A Schult. 2008.Exploring network structure, dynamics, and function using NetworkX. Technical Report. Los Alamos National Laboratory (LANL), Los Alamos, NM (United States)
2008
-
[12]
Alexander Halavais and Derek Lackaff. 2008. An analysis of topical coverage of Wikipedia.Journal of computer-mediated communication13, 2 (2008), 429–440
2008
-
[13]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
-
[14]
Matteo Hessel, Joseph Modayil, Hado Van Hasselt, Tom Schaul, Georg Ostro- vski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver
-
[15]
In Proceedings of the AAAI conference on artificial intelligence, Vol
Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the AAAI conference on artificial intelligence, Vol. 32
-
[16]
He Jiang, Yulun Zhang, Rishi Veerapaneni, and Jiaoyang Li. 2024. Scaling Lifelong Multi-Agent Path Finding to More Realistic Settings: Research Challenges and Opportunities. InProceedings of the International Symposium on Combinatorial Search, Vol. 17. 234–242
2024
-
[17]
Kazumi Kasaura, Ryo Yonetani, and Mai Nishimura. 2023. Periodic multi-agent path planning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 6183–6191
2023
-
[18]
Sotiris Kotsiantis, Dimitris Kanellopoulos, Panayiotis Pintelas, et al. 2006. Han- dling imbalanced datasets: A review.GESTS international transactions on computer science and engineering30, 1 (2006), 25–36
2006
-
[19]
Pinxin Long, Wenxi Liu, and Jia Pan. 2017. Deep-learned collision avoidance policy for distributed multiagent navigation.IEEE Robotics and Automation Letters 2, 2 (2017), 656–663
2017
-
[20]
Karman Lucero. 2019. Artificial intelligence regulation and China’s future.Colum. J. Asian L.33 (2019), 94
2019
-
[21]
Chandler May, Alex Wang, Shikha Bordia, Samuel R Bowman, and Rachel Rudinger. 2019. On measuring social biases in sentence encoders. InProceedings of the 2019 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 622–628
2019
-
[22]
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. 2013. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602(2013)
work page internal anchor Pith review arXiv 2013
-
[23]
Moin Nadeem, Anna Bethke, and Siva Reddy. 2021. StereoSet: Measuring stereo- typical bias in pretrained language models. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Interna- tional Joint Conference on Natural Language Processing (Volume 1: Long Papers), Chengqing Zong, Fei Xia, Wenjie Li, and Robe...
-
[24]
Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel R. Bowman. 2020. CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Lan- guage Models. InProceedings of the 2020 Conference on Empirical Methods in XXXX ’XX, XXX, 2026, XXX, XXX Xiaotian Zhou, Di Tang, Xiaofeng Wang, and Xiaozhong Liu Natural Language Processing (EMNLP), Bonnie We...
2020
-
[25]
doi:10.18653/v1/2020.emnlp-main.154
-
[26]
Debora Nozza, Federico Bianchi, and Dirk Hovy. 2021. HONEST: Measuring hurt- ful sentence completion in language models. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
2021
- [27]
-
[28]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
-
[29]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text.arXiv preprint arXiv:1606.05250(2016)
work page internal anchor Pith review arXiv 2016
- [30]
-
[31]
Maarten Sap, Saadia Gabriel, Lianhui Qin, Dan Jurafsky, Noah A Smith, and Yejin Choi. 2020. Social Bias Frames: Reasoning about Social and Power Implications of Language. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 5477–5490. doi:10.18653/v1/2020.acl-main.486
- [32]
-
[33]
2018.Reinforcement learning: An intro- duction
Richard S Sutton and Andrew G Barto. 2018.Reinforcement learning: An intro- duction. MIT press
2018
-
[34]
Zhen Tan, Alimohammad Beigi, Song Wang, Ruocheng Guo, Amrita Bhattachar- jee, Bohan Jiang, Mansooreh Karami, Jundong Li, Lu Cheng, and Huan Liu
- [35]
-
[36]
Daniel Van Niekerk, María Peréz-Ortiz, John Shawe-Taylor, Davor Orlic, Jackie Kay, Noah Siegel, Katherine Evans, Nyalleng Moorosi, Tina Eliassi-Rad, Leonie Maria Tanczer, et al. 2024. Challenging Systematic Prejudices: An Investi- gation into Bias Against Women and Girls. (2024)
2024
-
[37]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks.arXiv preprint arXiv:1710.10903(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [38]
-
[39]
Tian Xia, Miao Chen, and Xiaozhong Liu. 2015. Explicit semantic path mining via Wikipedia knowledge tree.Proceedings of the American Society for Information Science and Technology51, 1 (2015), 1–4. doi:10.1002/meet.2014.14505101160
-
[40]
Yuzi Yan, Xiaoxiang Li, Xinyou Qiu, Jiantao Qiu, Jian Wang, Yu Wang, and Yuan Shen. 2022. Relative distributed formation and obstacle avoidance with multi- agent reinforcement learning. In2022 International Conference on Robotics and Automation (ICRA). IEEE, 1661–1667
2022
-
[41]
Hongwei Zeng, Bifan Wei, Jun Liu, and Weiping Fu. 2023. Synthesize, prompt and transfer: Zero-shot conversational question generation with pre-trained language model. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8989–9010
2023
- [42]
-
[43]
Jiaxu Zhao, Meng Fang, Shirui Pan, Wenpeng Yin, and Mykola Pechenizkiy
- [44]
-
[45]
Xiaotian Zhou, Qian Wang, Xiaofeng Wang, Haixu Tang, and Xiaozhong Liu
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.