Recognition: no theorem link
Referring-Aware Visuomotor Policy Learning for Closed-Loop Manipulation
Pith reviewed 2026-05-10 19:53 UTC · model grok-4.3
The pith
ReV lets robots replan trajectories in real time by steering diffusion policies with sparse referring points trained on perturbed demos alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
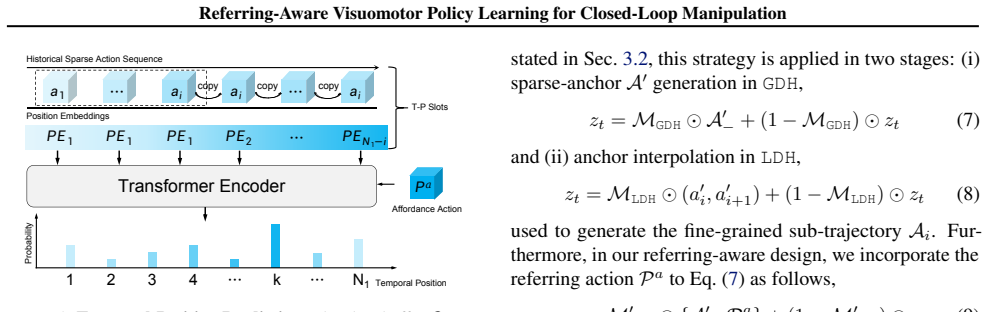
ReV is a closed-loop visuomotor policy that preserves standard execution patterns while integrating sparse referring points through a trajectory-steering strategy. The global diffusion head generates a sequence of globally consistent yet temporally sparse action anchors and identifies the temporal position of the referring point, after which the local diffusion head adaptively interpolates adjacent anchors. This process repeats at every execution step to enable real-time replanning, and the model is trained solely by applying targeted perturbations to expert demonstrations, yielding higher success rates on challenging simulated and real-world tasks.
What carries the argument
Coupled diffusion heads, where the global head creates temporally sparse action anchors and locates referring points temporally while the local head performs adaptive interpolation, combined with a trajectory-steering strategy that incorporates sparse referring at each step.
If this is right
- Real-time trajectory replanning becomes possible at every execution step when the scene changes dynamically.
- Standard task execution patterns remain intact without added degradation from the referring capability.
- Higher success rates are achieved on challenging tasks in simulation and the real world using only perturbations to existing expert data.
- Sparse referring from humans or high-level planners can be incorporated without requiring additional data collection or fine-tuning.
Where Pith is reading between the lines
- The approach could reduce the amount of data needed to train robust policies for robots operating in unstructured settings.
- It could pair with high-level planners that output referring points based on scene understanding to enable more adaptive behaviors.
- Extensions might explore using continuous streams of referring points or language-derived guidance for longer tasks.
Load-bearing premise
That applying targeted perturbations to expert demonstrations alone is enough for the model to handle unforeseen out-of-distribution errors and dynamic re-routing without degrading standard performance.
What would settle it
Running the trained policy on both standard tasks and on tasks with injected execution errors or dynamic changes that require rerouting; if success rates fall on standard tasks or the policy fails to recover from the new errors, the central claim would not hold.
Figures









read the original abstract
This paper addresses a fundamental problem of visuomotor policy learning for robotic manipulation: how to enhance robustness in out-of-distribution execution errors or dynamically re-routing trajectories, where the model relies solely on the original expert demonstrations for training. We introduce the Referring-Aware Visuomotor Policy (ReV), a closed-loop framework that can adapt to unforeseen circumstances by instantly incorporating sparse referring points provided by a human or a high-level reasoning planner. Specifically, ReV leverages the coupled diffusion heads to preserve standard task execution patterns while seamlessly integrating sparse referring via a trajectory-steering strategy. Upon receiving a specific referring point, the global diffusion head firstly generates a sequence of globally consistent yet temporally sparse action anchors, while identifies the precise temporal position for the referring point within this sequence. Subsequently, the local diffusion head adaptively interpolates adjacent anchors based on the current temporal position for specific tasks. This closed-loop process repeats at every execution step, enabling real-time trajectory replanning in response to dynamic changes in the scene. In practice, rather than relying on elaborate annotations, ReV is trained only by applying targeted perturbations to expert demonstrations. Without any additional data or fine-tuning scheme, ReV achieve higher success rates across challenging simulated and real-world tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Referring-Aware Visuomotor Policy (ReV), a closed-loop visuomotor framework for robotic manipulation tasks. ReV employs coupled global and local diffusion heads that preserve standard execution patterns from expert demonstrations while incorporating sparse referring points (from humans or planners) via a trajectory-steering strategy for real-time replanning. The global head produces temporally sparse action anchors and identifies the referring point's position; the local head then interpolates. Training uses only targeted perturbations applied to expert demonstrations, with no additional data or fine-tuning, and the abstract claims higher success rates on challenging simulated and real-world tasks.
Significance. If the empirical claims hold, the work would be significant for data-efficient robustness in visuomotor policies, as it offers a mechanism to handle OOD execution errors and dynamic re-routing without new data collection or retraining. The coupled diffusion approach for global anchoring plus local interpolation, combined with perturbation-based training for referring awareness, represents a practical integration that could influence closed-loop control designs in robotics.
major comments (3)
- [Abstract] Abstract: The central claim that ReV achieves higher success rates across tasks without additional data or fine-tuning is stated without any quantitative results, baselines, error bars, task descriptions, or metrics. This absence is load-bearing because the contribution rests on demonstrating that the perturbation-trained coupled heads improve performance while preserving standard execution.
- [Method] Method description (high-level overview in abstract and §3): No derivation, pseudocode, or loss formulation is supplied for how the global diffusion head generates anchors and identifies temporal position, or how the local head performs adaptive interpolation conditioned on the referring point. Without these details, it is impossible to verify that the trajectory-steering strategy is independent of the target result rather than implicitly fitting to the perturbation distribution.
- [Training] Training procedure (abstract): The assumption that targeted perturbations to expert demonstrations alone suffice to cover the distribution of real OOD errors (sensor noise, object dynamics, planner shifts) is not supported by any analysis, overlap metrics, or ablation showing that standard (non-referring) performance is preserved outside the perturbed regime. This assumption is load-bearing for the generalization claim.
minor comments (2)
- [Abstract] The abstract and method overview use several invented terms (e.g., 'coupled diffusion heads', 'trajectory-steering strategy', 'action anchors') without prior definition or reference to standard diffusion policy literature, which reduces readability.
- [Method] No mention of implementation details such as diffusion timestep schedules, network architectures for the two heads, or how referring points are encoded as input.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work. We address each of the major comments in detail below, providing clarifications and indicating the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] The central claim that ReV achieves higher success rates across tasks without additional data or fine-tuning is stated without any quantitative results, baselines, error bars, task descriptions, or metrics. This absence is load-bearing because the contribution rests on demonstrating that the perturbation-trained coupled heads improve performance while preserving standard execution.
Authors: We agree that including quantitative results in the abstract would better support the central claims. In the revised manuscript, we will update the abstract to incorporate key experimental outcomes, such as success rates with error bars, comparisons to baselines, and brief task descriptions, while keeping it concise. revision: yes
-
Referee: [Method] No derivation, pseudocode, or loss formulation is supplied for how the global diffusion head generates anchors and identifies temporal position, or how the local head performs adaptive interpolation conditioned on the referring point. Without these details, it is impossible to verify that the trajectory-steering strategy is independent of the target result rather than implicitly fitting to the perturbation distribution.
Authors: We will provide additional technical details in the revised version. Specifically, we will include pseudocode for the global and local diffusion heads, the loss formulations for training, and a derivation explaining how the referring point conditions the temporal position identification and interpolation. This will demonstrate that the strategy relies on the input referring point rather than the perturbation distribution. revision: yes
-
Referee: [Training] The assumption that targeted perturbations to expert demonstrations alone suffice to cover the distribution of real OOD errors (sensor noise, object dynamics, planner shifts) is not supported by any analysis, overlap metrics, or ablation showing that standard (non-referring) performance is preserved outside the perturbed regime. This assumption is load-bearing for the generalization claim.
Authors: We recognize the importance of validating this assumption empirically. We will add an ablation study to the experiments section showing that ReV maintains standard performance on unperturbed expert trajectories. We will also provide a discussion and qualitative analysis of how the targeted perturbations align with common OOD errors encountered in practice. A quantitative overlap metric between perturbation and real error distributions would require further data collection and is beyond the current scope, but the added ablation addresses the core concern. revision: partial
Circularity Check
No significant circularity; method description is self-contained with independent training procedure.
full rationale
The paper introduces ReV as a closed-loop visuomotor policy trained solely by applying targeted perturbations to expert demonstrations, with no equations, derivations, or load-bearing self-citations present in the provided text. The central claims about preserving task patterns while integrating sparse referring points via coupled diffusion heads and trajectory-steering are presented as empirical outcomes of this training regime rather than reductions to fitted inputs or prior author results by construction. Performance assertions rely on simulated and real-world task success rates without definitional equivalence to the perturbation strategy itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion-based policies can generate temporally consistent action sequences for robotic tasks
- ad hoc to paper Targeted perturbations to expert demonstrations are representative of out-of-distribution errors
invented entities (1)
-
Coupled diffusion heads with trajectory-steering strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dexterous functional grasping,
Agarwal, A., Uppal, S., Shaw, K., and Pathak, D. Dexterous functional grasping. arXiv preprint arXiv:2312.02975, 2023
-
[2]
Trajectory Optimization and Following for a Three Degrees of Freedom Overactuated Floating Platform
Avigal, Y., Berscheid, L., Asfour, T., Kröger, T., and Goldberg, K. Speedfolding: Learning efficient bimanual folding of garments. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.\ 1--8, 2022. doi:10.1109/IROS47612.2022.9981402
-
[3]
Dexart: Benchmarking generalizable dexterous manipulation with articulated objects
Bao, C., Xu, H., Qin, Y., and Wang, X. Dexart: Benchmarking generalizable dexterous manipulation with articulated objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 21190--21200, 2023
2023
-
[4]
T., Kicki, P., Koert, D., and Peters, J
Carvalho, J., Le, A. T., Kicki, P., Koert, D., and Peters, J. Motion planning diffusion: Learning and adapting robot motion planning with diffusion models. IEEE Transactions on Robotics, 2025
2025
-
[5]
Chen, H., Li, J., Wu, R., Liu, Y., Hou, Y., Xu, Z., Guo, J., Gao, C., Wei, Z., Xu, S., Huang, J., and Shao, L. Metafold: Language-guided multi-category garment folding framework via trajectory generation and foundation model, 2025. URL https://arxiv.org/abs/2503.08372
-
[6]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., and Song, S. Diffusion policy: Visuomotor policy learning via action diffusion. arXiv preprint arXiv:2303.04137, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
From play to policy: Conditional behavior generation from uncurated robot data
Cui, Z. J., Wang, Y., Shafiullah, N. M. M., and Pinto, L. From play to policy: Conditional behavior generation from uncurated robot data, 2022. URL https://arxiv.org/abs/2210.10047
-
[8]
Self-supervised correspondence in visuomotor policy learning
Florence, P., Manuelli, L., and Tedrake, R. Self-supervised correspondence in visuomotor policy learning. IEEE Robotics and Automation Letters, 5 0 (2): 0 492--499, 2020. doi:10.1109/LRA.2019.2956365
-
[9]
D., Srinivasa, S
Gammell, J. D., Srinivasa, S. S., and Barfoot, T. D. Informed rrt*: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic. In 2014 IEEE/RSJ international conference on intelligent robots and systems, pp.\ 2997--3004. IEEE, 2014
2014
-
[10]
D., Barfoot, T
Gammell, J. D., Barfoot, T. D., and Srinivasa, S. S. Batch informed trees (bit*): Informed asymptotically optimal anytime search. The International Journal of Robotics Research, 39 0 (5): 0 543--567, 2020
2020
-
[11]
ArXivabs/2412.06782(2024),https://api.semanticscholar.org/CorpusID: 274610389
Gong, Z., Ding, P., Lyu, S., Huang, S., Sun, M., Zhao, W., Fan, Z., and Wang, D. Carp: Visuomotor policy learning via coarse-to-fine autoregressive prediction. arXiv preprint arXiv:2412.06782, 2024
-
[12]
Teach a robot to fish: Versatile imitation from one minute of demonstrations
Haldar, S., Pari, J., Rai, A., and Pinto, L. Teach a robot to fish: Versatile imitation from one minute of demonstrations. arXiv preprint arXiv:2303.01497, 2023
-
[13]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
2020
-
[14]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Huang, W., Wang, C., Zhang, R., Li, Y., Wu, J., and Fei-Fei, L. Voxposer: Composable 3d value maps for robotic manipulation with language models, 2023. URL https://arxiv.org/abs/2307.05973
work page internal anchor Pith review arXiv 2023
-
[15]
Planning with Diffusion for Flexible Behavior Synthesis
Janner, M., Du, Y., Tenenbaum, J. B., and Levine, S. Planning with diffusion for flexible behavior synthesis. arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review arXiv 2022
-
[16]
and Frazzoli, E
Karaman, S. and Frazzoli, E. Sampling-based algorithms for optimal motion planning. The international journal of robotics research, 30 0 (7): 0 846--894, 2011
2011
-
[17]
Flame: Free-form language-based motion synthesis & editing
Kim, J., Kim, J., and Choi, S. Flame: Free-form language-based motion synthesis & editing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp.\ 8255--8263, 2023
2023
-
[18]
T., Chalvatzaki, G., Biess, A., and Peters, J
Le, A. T., Chalvatzaki, G., Biess, A., and Peters, J. R. Accelerating motion planning via optimal transport. Advances in Neural Information Processing Systems, 36: 0 78453--78482, 2023
2023
-
[19]
Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
Lee, S., Wang, Y., Etukuru, H., Kim, H. J., Shafiullah, N. M. M., and Pinto, L. Behavior generation with latent actions, 2024. URL https://arxiv.org/abs/2403.03181
-
[20]
Ma, J., Qin, Y., Li, Y., Liao, X., Guo, Y., and Zhang, R. Cdp: Towards robust autoregressive visuomotor policy learning via causal diffusion. arXiv preprint arXiv:2506.14769, 2025
-
[21]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Mandlekar, A., Xu, D., Wong, J., Nasiriany, S., Wang, C., Kulkarni, R., Fei-Fei, L., Savarese, S., Zhu, Y., and Martín-Martín, R. What matters in learning from offline human demonstrations for robot manipulation, 2021. URL https://arxiv.org/abs/2108.03298
work page internal anchor Pith review arXiv 2021
-
[22]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Mandlekar, A., Nasiriany, S., Wen, B., Akinola, I., Narang, Y., Fan, L., Zhu, Y., and Fox, D. Mimicgen: A data generation system for scalable robot learning using human demonstrations, 2023. URL https://arxiv.org/abs/2310.17596
-
[23]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., and Zhu, Y. Robocasa: Large-scale simulation of everyday tasks for generalist robots, 2024. URL https://arxiv.org/abs/2406.02523
work page internal anchor Pith review arXiv 2024
-
[24]
Y., Sanketi, P., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., and Levine, S
Octo Model Team , Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Xu, C., Luo, J., Kreiman, T., Tan, Y., Chen, L. Y., Sanketi, P., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., and Levine, S. Octo: An open-source generalist robot policy. In Proceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[25]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA), pp
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., Tung, A., Bewley, A., Herzog, A., Irpan, A., Khazatsky, A., Rai, A., Gupta, A., Wang, A., Singh, A., Garg, A., Kembhavi, A., Xie, A., Brohan, A., Raffin, A., Sharma, A., Yavary, A., Jain, A., Balakrishna, A., Wahid, A., Burgess-Limeric...
-
[26]
Learning agile robotic locomotion skills by imitating animals
Peng, X. B., Coumans, E., Zhang, T., Lee, T.-W., Tan, J., and Levine, S. Learning agile robotic locomotion skills by imitating animals. arXiv preprint arXiv:2004.00784, 2020
-
[27]
Mixtures of gaussian processes for robot motion planning using stochastic trajectory optimization
Petrovi \'c , L., Markovi \'c , I., and Petrovi \'c , I. Mixtures of gaussian processes for robot motion planning using stochastic trajectory optimization. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52 0 (12): 0 7378--7390, 2022
2022
-
[28]
arXiv preprint arXiv:2503.16408 (2025)
Qin, Y., Kang, L., Song, X., Yin, Z., Liu, X., Liu, X., Zhang, R., and Bai, L. Robofactory: Exploring embodied agent collaboration with compositional constraints. arXiv preprint arXiv:2503.16408, 2025
-
[29]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Rajeswaran, A., Kumar, V., Gupta, A., Vezzani, G., Schulman, J., Todorov, E., and Levine, S. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv preprint arXiv:1709.10087, 2017
work page Pith review arXiv 2017
-
[30]
Edmp: Ensemble-of-costs-guided diffusion for motion planning
Saha, K., Mandadi, V., Reddy, J., Srikanth, A., Agarwal, A., Sen, B., Singh, A., and Krishna, M. Edmp: Ensemble-of-costs-guided diffusion for motion planning. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 10351--10358. IEEE, 2024
2024
- [31]
-
[32]
Perceiver-actor: A multi-task transformer for robotic manipulation
Shridhar, M., Manuelli, L., and Fox, D. Perceiver-actor: A multi-task transformer for robotic manipulation. In Conference on Robot Learning, pp.\ 785--799. PMLR, 2023
2023
- [33]
-
[34]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
Strub, M. P. and Gammell, J. D. Adaptively informed trees (ait*): Fast asymptotically optimal path planning through adaptive heuristics. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 3191--3198. IEEE, 2020
2020
-
[36]
ArXivabs/2503.13217 (2025),https://api.semanticscholar.org/CorpusID:277103820
Su, Y., Zhan, X., Fang, H., Xue, H., Fang, H.-S., Li, Y.-L., Lu, C., and Yang, L. Dense policy: Bidirectional autoregressive learning of actions. arXiv preprint arXiv:2503.13217, 2025
-
[37]
Edge: Editable dance generation from music
Tseng, J., Castellon, R., and Liu, K. Edge: Editable dance generation from music. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 448--458, 2023
2023
-
[38]
T., Lambert, A., Chalvatzaki, G., Boots, B., and Peters, J
Urain, J., Le, A. T., Lambert, A., Chalvatzaki, G., Boots, B., and Peters, J. Learning implicit priors for motion optimization. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp.\ 7672--7679. IEEE, 2022
2022
-
[39]
R., Black, K., Zhao, T
Walke, H. R., Black, K., Zhao, T. Z., Vuong, Q., Zheng, C., Hansen-Estruch, P., He, A. W., Myers, V., Kim, M. J., Du, M., Lee, A., Fang, K., Finn, C., and Levine, S. Bridgedata v2: A dataset for robot learning at scale. In Tan, J., Toussaint, M., and Darvish, K. (eds.), Proceedings of The 7th Conference on Robot Learning, volume 229 of Proceedings of Mach...
2023
-
[40]
Mimicplay: Long- horizon imitation learning by watching human play,
Wang, C., Fan, L., Sun, J., Zhang, R., Fei-Fei, L., Xu, D., Zhu, Y., and Anandkumar, A. Mimicplay: Long-horizon imitation learning by watching human play. arXiv preprint arXiv:2302.12422, 2023
-
[41]
Wang, Z., Kang, L., Qin, Y., Ma, J., Peng, Z., Bai, L., and Zhang, R. Gaudp: Reinventing multi-agent collaboration through gaussian-image synergy in diffusion policies, 2025. URL https://arxiv.org/abs/2511.00998
-
[42]
Ensuring force safety in vision-guided robotic manipulation via implicit tactile calibration
Wei, L., Ma, J., Hu, Y., and Zhang, R. Ensuring force safety in vision-guided robotic manipulation via implicit tactile calibration. arXiv preprint arXiv:2412.10349, 2024
-
[43]
Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation
Xian, Z., Gkanatsios, N., Gervet, T., Ke, T.-W., and Fragkiadaki, K. Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation. In 7th Annual Conference on Robot Learning, 2023
2023
-
[44]
Xue, Z., Deng, S., Chen, Z., Wang, Y., Yuan, Z., and Xu, H. Demogen: Synthetic demonstration generation for data-efficient visuomotor policy learning, 2025. URL https://arxiv.org/abs/2502.16932
-
[45]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA), pp
Yang, J., Deng, C., Wu, J., Antonova, R., Guibas, L., and Bohg, J. Equivact: Sim(3)-equivariant visuomotor policies beyond rigid object manipulation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp.\ 9249--9255, 2024. doi:10.1109/ICRA57147.2024.10611491
-
[46]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Yu, T., Quillen, D., He, Z., Julian, R., Hausman, K., Finn, C., and Levine, S. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on robot learning, pp.\ 1094--1100. PMLR, 2020
2020
-
[47]
E., and Wang, X
Ze, Y., Yan, G., Wu, Y.-H., Macaluso, A., Ge, Y., Ye, J., Hansen, N., Li, L. E., and Wang, X. Gnfactor: Multi-task real robot learning with generalizable neural feature fields. In Conference on Robot Learning, pp.\ 284--301. PMLR, 2023
2023
-
[48]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., and Xu, H. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. In Proceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[49]
Autoregressive action sequence learning for robotic manipulation
Zhang, X., Liu, Y., Chang, H., Schramm, L., and Boularias, A. Autoregressive action sequence learning for robotic manipulation. IEEE Robotics and Automation Letters, 2025
2025
-
[50]
TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Zhang, Z., Ma, J., Yang, X., Wen, X., Zhang, Y., Li, B., Qin, Y., Liu, J., Zhao, C., Kang, L., Hong, H., Yin, Z., Torr, P., Su, H., Zhang, R., and Ma, D. Touchguide: Inference-time steering of visuomotor policies via touch guidance, 2026. URL https://arxiv.org/abs/2601.20239
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Zhao, K., Li, G., and Tang, S. Dartcontrol: A diffusion-based autoregressive motion model for real-time text-driven motion control. arXiv preprint arXiv:2410.05260, 2024
-
[52]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T. Z., Kumar, V., Levine, S., and Finn, C. Learning fine-grained bimanual manipulation with low-cost hardware, 2023. URL https://arxiv.org/abs/2304.13705
work page internal anchor Pith review arXiv 2023
-
[53]
Zhou, E., An, J., Chi, C., Han, Y., Rong, S., Zhang, C., Wang, P., Wang, Z., Huang, T., Sheng, L., et al. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. arXiv preprint arXiv:2506.04308, 2025
-
[54]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.