Recognition: 1 theorem link
· Lean TheoremHackers or Hallucinators? A Comprehensive Analysis of LLM-Based Automated Penetration Testing
Pith reviewed 2026-05-10 18:48 UTC · model grok-4.3
The pith
LLM-based automated penetration testing frameworks are classified across six design dimensions and compared on a unified benchmark for the first time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We deliver the first Systematization of Knowledge on LLM-based AutoPT frameworks by reviewing existing designs across six dimensions and by executing large-scale empirical comparisons of 13 open-source frameworks plus two baselines on a unified benchmark, with all logs manually reviewed over four months by more than 15 cybersecurity experts.
What carries the argument
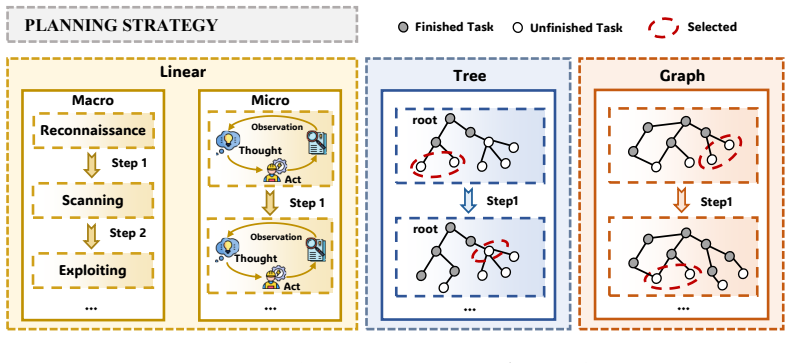
The six-dimensional taxonomy of agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks, which both organizes the review of framework designs and structures the unified empirical evaluation.
If this is right
- New frameworks can adopt the six-dimensional taxonomy to deliberately improve weak areas such as memory retention or execution reliability.
- The published benchmark and logs enable direct, reproducible comparisons for any future AutoPT system.
- Identified limitations in current agent plans and external knowledge use point to specific research targets for increasing end-to-end success rates.
- The scale of token consumption documented in the experiments supplies practical guidance on the computational cost of deploying these agents.
Where Pith is reading between the lines
- Widespread use of the benchmark could reduce duplicated effort by letting research groups measure incremental gains against a shared baseline.
- The same review-plus-unified-test method could be applied to LLM agents in other security-sensitive tasks such as malware analysis or vulnerability disclosure.
- If open-source results remain modest, closed-source commercial tools may need separate evaluation to determine whether they close the autonomy gap.
Load-bearing premise
The 13 open-source frameworks plus two baselines plus the chosen unified benchmark are representative enough of the field that the architectural patterns and performance observations generalize.
What would settle it
A later study that adds several omitted frameworks, re-runs the identical benchmark, and finds substantially different success rates or entirely new architectural patterns would show the original selection was not representative.
Figures





























read the original abstract
The rapid advancement of Large Language Models (LLMs) has created new opportunities for Automated Penetration Testing (AutoPT), spawning numerous frameworks aimed at achieving end-to-end autonomous attacks. However, despite the proliferation of related studies, existing research generally lacks systematic architectural analysis and large-scale empirical comparisons under a unified benchmark. Therefore, this paper presents the first Systematization of Knowledge (SoK) focusing on the architectural design and comprehensive empirical evaluation of current LLM-based AutoPT frameworks. At systematization level, we comprehensively review existing framework designs across six dimensions: agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks. At empirical level, we conduct large-scale experiments on 13 representative open-source AutoPT frameworks and 2 baseline frameworks utilizing a unified benchmark. The experiments consumed over 10 billion tokens in total and generated more than 1,500 execution logs, which were manually reviewed and analyzed over four months by a panel of more than 15 researchers with expertise in cybersecurity. By investigating the latest progress in this rapidly developing field, we provide researchers with a structured taxonomy to understand existing LLM-based AutoPT frameworks and a large-scale empirical benchmark, along with promising directions for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver the first Systematization of Knowledge (SoK) on LLM-based Automated Penetration Testing (AutoPT) frameworks. It reviews designs across six dimensions (agent architecture, plan, memory, execution, external knowledge, and benchmarks), then performs large-scale experiments on 13 open-source frameworks plus two baselines under a unified benchmark. The experiments used >10B tokens, produced >1,500 logs that were manually reviewed by >15 experts over four months, and yield a taxonomy, performance insights, identified limitations, and future research directions.
Significance. If the taxonomy is comprehensive and the empirical findings are reproducible, the work would provide a valuable structured reference and benchmark for the emerging intersection of LLMs and automated security testing. The scale of the token usage and multi-expert review are positive signals of effort, but the absence of reproducibility safeguards on the manual analysis limits the strength of the empirical contribution.
major comments (2)
- [Empirical Evaluation] Empirical Evaluation section (and associated methodology description): The central empirical claims rest on manual review of >1,500 execution logs by >15 researchers. No inter-rater reliability metrics (e.g., Cohen’s kappa or Fleiss’ kappa), annotation guidelines, disagreement-resolution protocol, or bias-mitigation steps are reported. This is load-bearing because the reported framework rankings, failure-mode distributions, and limitation insights are derived directly from these subjective judgments; without these details the evaluation cannot be considered reproducible or objective.
- [Framework Selection] Framework Selection subsection: The justification for choosing exactly these 13 open-source frameworks (plus the two baselines) as “representative” is not sufficiently detailed. The paper must show that the selection criteria (e.g., GitHub stars, recency, architectural diversity) were applied systematically and that excluded frameworks would not materially alter the taxonomy or performance conclusions.
minor comments (2)
- [Systematization] The six-dimensional taxonomy is introduced in the abstract and systematization section but the mapping of individual frameworks to each dimension is not presented in a single, easily scannable table; adding such a summary table would improve readability.
- [Experiments] Token-count and log-volume statistics are given in aggregate; breaking them down by framework (or at least by category) would allow readers to assess whether computational cost correlates with reported performance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing honest responses and committing to revisions where the comments identify gaps in the current version. Our goal is to strengthen the reproducibility and clarity of the work without misrepresenting the original contributions.
read point-by-point responses
-
Referee: [Empirical Evaluation] Empirical Evaluation section (and associated methodology description): The central empirical claims rest on manual review of >1,500 execution logs by >15 researchers. No inter-rater reliability metrics (e.g., Cohen’s kappa or Fleiss’ kappa), annotation guidelines, disagreement-resolution protocol, or bias-mitigation steps are reported. This is load-bearing because the reported framework rankings, failure-mode distributions, and limitation insights are derived directly from these subjective judgments; without these details the evaluation cannot be considered reproducible or objective.
Authors: We agree that the absence of explicit details on the manual review process represents a limitation in the current manuscript's reproducibility. The reviews were conducted by a panel of over 15 cybersecurity experts over four months, with logs assigned to multiple reviewers where possible and disagreements resolved through group discussion and consensus. In the revised version, we will expand the methodology description to include: the annotation guidelines used (e.g., standardized failure-mode categories and success criteria), the disagreement-resolution protocol, bias-mitigation steps such as log randomization and independent initial reviews, and any available inter-rater agreement statistics (e.g., pairwise agreement percentages). While we did not compute formal metrics like Cohen’s or Fleiss’ kappa during the original process and cannot retroactively apply them without re-reviewing all logs, we will report the available agreement data and explicitly discuss the subjective nature of the analysis as a limitation. This revision will make the empirical contribution more transparent and objective. revision: yes
-
Referee: [Framework Selection] Framework Selection subsection: The justification for choosing exactly these 13 open-source frameworks (plus the two baselines) as “representative” is not sufficiently detailed. The paper must show that the selection criteria (e.g., GitHub stars, recency, architectural diversity) were applied systematically and that excluded frameworks would not materially alter the taxonomy or performance conclusions.
Authors: We acknowledge that the Framework Selection subsection could benefit from greater explicitness regarding the systematic application of criteria. The 13 frameworks were chosen to ensure coverage across the six taxonomy dimensions while prioritizing open-source availability, recency (primarily 2023–2024 releases), and indicators of adoption such as GitHub stars and community activity; the two baselines were included for controlled comparison. In the revision, we will expand this subsection with a clear enumeration of the selection criteria (including thresholds and sources), a table summarizing how each selected framework maps to the taxonomy dimensions, and a discussion of notable excluded frameworks (e.g., those that are closed-source, non-functional, or duplicates of included ones) with arguments that their inclusion would not materially change the taxonomy structure or the high-level performance patterns observed. This will demonstrate the representativeness of the sample without altering the paper's core claims. revision: yes
Circularity Check
No circularity in SoK derivation or empirical claims
full rationale
The paper performs a literature systematization across six architectural dimensions and runs experiments on 13 external open-source frameworks plus baselines under a unified benchmark. No equations, fitted parameters, predictions, or model derivations appear in the provided text that could reduce to the paper's own inputs by construction. The central claims rest on review of prior work and analysis of independent systems rather than self-referential steps, self-citation chains, or renamed empirical patterns. This matches the default expectation of no significant circularity for a survey-style paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard practices of literature review and empirical benchmarking in computer science are sufficient to produce a representative SoK.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation (RealityFromDistinction, Cost/FunctionalEquation, AlexanderDuality)reality_from_one_distinction; washburn_uniqueness_aczel; alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct a unified analytical framework to deconstruct existing AutoPT designs across six dimensions: agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=BAFB47E8874764186BD B7865E8344DAF, 2019
Information security technology ibaseline for classified protection of cybersecurity. https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=BAFB47E8874764186BD B7865E8344DAF, 2019
2019
-
[2]
HexStrike AI MCP Agents
0x4m4. HexStrike AI MCP Agents. https://github.com/0x4m4/hexstrike-ai, 2026
2026
-
[3]
EnIGMA: Interactive tools substantially assist LM agents in finding security vulnerabilities
Talor Abramovich, Meet Udeshi, Minghao Shao, Kilian Lieret, Haoran Xi, Kimberly Milner, Sofija Jancheska, John Yang, Carlos E Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik R Narasimhan, Ramesh Karri, and Ofir Press. EnIGMA: Interactive tools substantially assist LM agents in finding security vulnerabi...
2025
-
[4]
Metasploit penetration testing cookbook
Monika Agarwal and Abhinav Singh. Metasploit penetration testing cookbook . Packt Publishing Birmingham, 2013
2013
-
[5]
Breachseek: A multi-agent automated penetration tester
Ibrahim Alshehri, Adnan Alshehri, Abdulrahman Almalki, Majed Bamardouf, and Alaqsa Akbar. Breachseek: A multi-agent automated penetration tester. arXiv preprint arXiv:2409.03789 , 2024
-
[6]
Introducing the model context protocol
Anthropic. Introducing the model context protocol. https://www.anthropic.com/ news/model-context-protocol , 2024
2024
-
[7]
Agent skills
Anthropic. Agent skills. https://agentskills.io/home, 2025
2025
-
[8]
Claude code
Anthropic. Claude code. https://github.com/anthropics/claude-code, 2026
2026
-
[9]
Claude opus 4.6 system card
Anthropic. Claude opus 4.6 system card. Technical report, Anthropic, 2026
2026
-
[10]
Introducing Claude Opus 4.6
Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/cla ude-opus-4-6 , 2026. 85
2026
-
[11]
Software penetration testing
Brad Arkin, Scott Stender, and Gary McGraw. Software penetration testing. IEEE Security & Privacy , 3(1):84–87, 2005
2005
-
[12]
Pentest-ai, an llm-powered multi-agents framework for penetration testing automation leveraging mitre attack
Stanislas G Bianou and Rodrigue G Batogna. Pentest-ai, an llm-powered multi-agents framework for penetration testing automation leveraging mitre attack. In 2024 IEEE International Conference on Cyber Security and Resilience (CSR) , pages 763–770. IEEE, 2024
2024
-
[13]
About penetration testing
Matt Bishop. About penetration testing. IEEE Security & Privacy , 5(6):84–87, 2007
2007
-
[14]
Coverage-based greybox fuzzing as markov chain
Marcel Böhme, Van-Thuan Pham, and Abhik Roychoudhury. Coverage-based greybox fuzzing as markov chain. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , pages 1032–1043, 2016
2016
-
[15]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[16]
The diamond model of intrusion analysis
Sergio Caltagirone, Andrew Pendergast, and Christopher Betz. The diamond model of intrusion analysis. 2013
2013
-
[17]
Carnegie Mellon University. picoCTF. https://picoctf.org/, 2026
2026
-
[18]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi-agent llm systems fail? arXiv preprint arXiv:2503.13657 , 2025
work page internal anchor Pith review arXiv 2025
-
[19]
tinyctfer
chainreactors. tinyctfer. https://github.com/chainreactors/tinyctfer, 2026
2026
-
[20]
RedTeamLLM: An agentic AI framework for offensive security,
Brian Challita and Pierre Parrend. Redteamllm: an agentic ai framework for offensive security. arXiv preprint arXiv:2505.06913 , 2025
-
[21]
Under the hoodie: Lessons from a season of penetration testing, 2018
Rapid7 Global Consulting. Under the hoodie: Lessons from a season of penetration testing, 2018
2018
-
[22]
The growing importance of exposure management: Key insights from gartner hype cycle for security operations 2024
Jamie Cowper. The growing importance of exposure management: Key insights from gartner hype cycle for security operations 2024. https://www.rapid7.com/blog/po st/2024/09/13/the-growing-importance-of-exposure-management-our-key-i nsights-from-gartner-r-hype-cycle-for-security-operations-2024/ , 2024
2024
-
[23]
crewAI: Fast and Flexible Multi-Agent Automation Framework
CrewAI. crewAI: Fast and Flexible Multi-Agent Automation Framework. https: //github.com/crewaiinc/crewai, 2026
2026
-
[24]
CVE: Common Vulnerabilities and Exposures
CVE Program. CVE: Common Vulnerabilities and Exposures. https://www.cve.or g/, 2026
2026
-
[25]
Hanzheng Dai, Yuanliang Li, Jun Yan, and Zhibo Zhang. Refpentester: A knowledge- informed self-reflective penetration testing framework based on large language models. arXiv preprint arXiv:2505.07089 , 2025
-
[26]
Multi-agent Penetration Testing AI for the Web.ArXiv, abs/2508.20816, aug 2025
Isaac David and Arthur Gervais. Multi-agent penetration testing ai for the web. arXiv preprint arXiv:2508.20816 , 2025
-
[27]
What makes a good llm agent for real-world penetration testing?, 2026
Gelei Deng, Yi Liu, Yuekang Li, Ruozhao Yang, Xiaofei Xie, Jie Zhang, Han Qiu, and Tianwei Zhang. What makes a good llm agent for real-world penetration testing?, 2026
2026
-
[28]
{PentestGPT}: Evaluating and harnessing large language models for automated penetration testing
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. {PentestGPT}: Evaluating and harnessing large language models for automated penetration testing. In 33rd USENIX Security Symposium (USENIX Security 24) , pages 847–864, 2024
2024
-
[29]
Cyberstrikeai
Ed1s0nZ. Cyberstrikeai. https://github.com/Ed1s0nZ/CyberStrikeAI, 2026. 86
2026
-
[30]
Regulation (EU) 2022/2554 of the European Parliament and of the Council of 14 December 2022 on digital op- erational resilience for the financial sector (DORA), 2022
European Parliament and Council of the European Union. Regulation (EU) 2022/2554 of the European Parliament and of the Council of 14 December 2022 on digital op- erational resilience for the financial sector (DORA), 2022. Official Journal of the European Union, L 333/1. Accessed: 2026-04-04
2022
-
[31]
A survey on rag meeting llms: Towards retrieval-augmented large language models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat- Seng Chua, and Qing Li. A survey on rag meeting llms: Towards retrieval-augmented large language models. In Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining , pages 6491–6501, 2024
2024
-
[32]
Llm agents can au- tonomously exploit one-day vulnerabilities, 2024
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. Llm agents can au- tonomously exploit one-day vulnerabilities, 2024
2024
-
[33]
LLM agents can autonomously hack websites, 2024
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. Llm agents can autonomously hack websites. arXiv preprint arXiv:2402.06664 , 2024
-
[34]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 , 2(1):32, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
PentestAgent
GH05TCREW. PentestAgent. https://github.com/GH05TCREW/PentestAgent , 2026
2026
-
[36]
Automated Planning: theory and practice
Malik Ghallab, Dana Nau, and Paolo Traverso. Automated Planning: theory and practice. Elsevier, 2004
2004
-
[37]
Autopenbench: A vulnerability testing benchmark for generative agents
Luca Gioacchini, Alexander Delsanto, Idilio Drago, Marco Mellia, Giuseppe Siracu- sano, and Roberto Bifulco. Autopenbench: A vulnerability testing benchmark for generative agents. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages 1615–1624, 2025
2025
-
[38]
Gemini 3.1 Pro
Google DeepMind. Gemini 3.1 Pro. https://deepmind.google/models/gemini/pr o/, 2026
2026
-
[39]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, 2025
2025
-
[40]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guant- ing Chen, Xiao Bi, Yifan Wu, YK Li, et al. Deepseek-coder: when the large language model meets programming–the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Hack The Box
Hack The Box. Hack The Box. https://www.hackthebox.com/, 2026
2026
-
[42]
Hacking articles
Hacking Articles. Hacking articles. https://www.hackingarticles.in/, 2026
2026
-
[43]
Getting pwn nd by ai: Penetration testing with large language models
Andreas Happe and Jürgen Cito. Getting pwn nd by ai: Penetration testing with large language models. In Proceedings of the 31st ACM joint european software engineering conference and symposium on the foundations of software engineering , pages 2082– 2086, 2023
2082
-
[44]
Can llms hack enterprise networks? autonomous assumed breach penetration-testing active directory networks
Andreas Happe and Jürgen Cito. Can llms hack enterprise networks? autonomous assumed breach penetration-testing active directory networks. ACM Transactions on Software Engineering and Methodology , 2025
2025
-
[45]
On the surprising efficacy of llms for penetration- testing
Andreas Happe and Jürgen Cito. On the surprising efficacy of llms for penetration- testing. arXiv preprint arXiv:2507.00829 , 2025
-
[46]
Got root? a linux priv-esc benchmark, 2024
Andreas Happe and Jürgen Cito. Got root? a linux priv-esc benchmark, 2024
2024
-
[47]
Llms as hackers: Autonomous linux privilege escalation attacks
Andreas Happe, Aaron Kaplan, and Juergen Cito. Llms as hackers: Autonomous linux privilege escalation attacks. arXiv preprint arXiv:2310.11409 , 2023. 87
-
[48]
Autopentest: Enhancing vulnerability management with autonomous llm agents
Julius Henke. Autopentest: Enhancing vulnerability management with autonomous llm agents. arXiv preprint arXiv:2505.10321 , 2025
-
[49]
H-pentest
hexian2001. H-pentest. https://github.com/hexian2001/H-Pentest, 2026
2026
-
[50]
Context rot: How increasing input tokens impacts llm performance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts llm performance. URL https://research. trychroma. com/context-rot, retrieved October, 20:2025, 2025
2025
-
[51]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. In The twelfth interna- tional conference on learning representations , 2023
2023
-
[52]
Penheal: A two-stage llm framework for automated pentesting and optimal remediation
Junjie Huang and Quanyan Zhu. Penheal: A two-stage llm framework for automated pentesting and optimal remediation. In Proceedings of the workshop on autonomous cybersecurity, pages 11–22, 2023
2023
-
[53]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
newmapta
HUST-JYHLab. newmapta. https://github.com/HUST-JYHLab/newmapta, 2026
2026
-
[55]
Intelligence-driven computer network defense informed by analysis of adversary campaigns and intrusion kill chains
Eric M Hutchins, Michael J Cloppert, Rohan M Amin, et al. Intelligence-driven computer network defense informed by analysis of adversary campaigns and intrusion kill chains. Leading Issues in Information Warfare & Security Research , 1(1):80, 2011
2011
-
[56]
Towards automated penetration testing: Introducing llm benchmark, analysis, and improvements
Isamu Isozaki, Manil Shrestha, Rick Console, and Edward Kim. Towards automated penetration testing: Introducing llm benchmark, analysis, and improvements. In Adjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization, pages 404–419, 2025
2025
-
[57]
Measuring and augmenting large language models for solving capture-the-flag chal- lenges
Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, and Shuai Wang. Measuring and augmenting large language models for solving capture-the-flag chal- lenges. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Com- munications Security, pages 603–617, 2025
2025
-
[58]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys , 55(12):1–38, 2023
2023
-
[59]
Sok: Agentic skills – beyond tool use in llm agents, 2026
Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guang- sheng Yu. Sok: Agentic skills – beyond tool use in llm agents, 2026
2026
-
[60]
SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations , 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations , 2024
2024
-
[61]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages 6769–6781, 2020
2020
-
[62]
Metasploit: the penetration tester’s guide
David Kennedy, Jim O’gorman, Devon Kearns, and Mati Aharoni. Metasploit: the penetration tester’s guide . No Starch Press, 2011
2011
-
[63]
arXiv preprint arXiv:2508.07382 , year=
He Kong, Die Hu, Jingguo Ge, Liangxiong Li, Hui Li, and Tong Li. Pentest-r1: Towards autonomous penetration testing reasoning optimized via two-stage reinforce- ment learning. arXiv preprint arXiv:2508.07382 , 2025
-
[64]
He Kong, Die Hu, Jingguo Ge, Liangxiong Li, Tong Li, and Bingzhen Wu. Vulnbot: Autonomous penetration testing for a multi-agent collaborative framework. arXiv preprint arXiv:2501.13411 , 2025. 88
-
[65]
Se perspective on llms: Biases in code generation, code interpretability, and code security risks
Rrezarta Krasniqi, Depeng Xu, and Marco Vieira. Se perspective on llms: Biases in code generation, code interpretability, and code security risks. ACM Computing Surveys, 58(5):1–16, 2025
2025
-
[66]
LangGraph: Low-level orchestration framework for building stateful agents
LangChain. LangGraph: Low-level orchestration framework for building stateful agents. https://github.com/langchain-ai/langgraph, 2026
2026
-
[67]
Lost in the middle: How language models use long contexts
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the association for computational linguistics , 12:157–173, 2024
2024
-
[68]
Zicheng Liu, Lige Huang, Jie Zhang, Dongrui Liu, Yuan Tian, and Jing Shao. Pacebench: A framework for evaluating practical ai cyber-exploitation capabilities. arXiv preprint arXiv:2510.11688 , 2025
-
[69]
Yu, and Ming Zhang
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bo- han Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao, Dacheng Tao, Philip S. Yu, and Ming Zhang. Large language model agent: A sur...
2025
-
[70]
Phung Duc Luong, Le Tran Gia Bao, Nguyen Vu Khai Tam, Dong Huu Nguyen Khoa, Nguyen Huu Quyen, Van-Hau Pham, and Phan The Duy. xoffense: An ai-driven autonomous penetration testing framework with offensive knowledge-enhanced llms and multi agent systems. arXiv preprint arXiv:2509.13021 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
xbow-competition
M-SEC. xbow-competition. https://github.com/m-sec-org/xbow-competition , 2026
2026
-
[72]
Wuyuao Mai, Geng Hong, Qi Liu, Jinsong Chen, Jiarun Dai, Xudong Pan, Yuan Zhang, and Min Yang. Shell or nothing: Real-world benchmarks and memory- activated agents for automated penetration testing. arXiv preprint arXiv:2509.09207 , 2025
-
[73]
Graphical user interfaces
Aaron Marcus. Graphical user interfaces. In Handbook of human-computer interaction, pages 423–440. Elsevier, 1997
1997
-
[74]
Cai: An open, bug bounty-ready cybersecurity ai, 2025
Víctor Mayoral-Vilches, Luis Javier Navarrete-Lozano, María Sanz-Gómez, Lidia Salas Espejo, Martiño Crespo-Álvarez, Francisco Oca-Gonzalez, Francesco Balassone, Al- fonso Glera-Picón, Unai Ayucar-Carbajo, Jon Ander Ruiz-Alcalde, et al. Cai: An open, bug bounty-ready cybersecurity ai. arXiv preprint arXiv:2504.06017 , 2025
-
[75]
Mike A Merrill, Alexander Glenn Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Jenia Jitsev, Marianna Nezhurina, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, ...
2026
-
[76]
CWE-Common Weakness Enumeration
MITRE Corporation. CWE-Common Weakness Enumeration. https://cwe.mitre. org/, 2026
2026
-
[77]
Kimi Code CLI
Moonshot AI. Kimi Code CLI. https://github.com/MoonshotAI/kimi-cli, 2026
2026
-
[78]
Penetration testing and ethical hacking services market size & share analysis - growth trends and forecast (2025 - 2030)
Mordor Intelligence. Penetration testing and ethical hacking services market size & share analysis - growth trends and forecast (2025 - 2030). https://www.mordorinte lligence.com/industry-reports/penetration-testing-and-ethical-hacking -services-market , 2025
2025
-
[79]
Lajos Muzsai, David Imolai, and András Lukács. Hacksynth: Llm agent and evalua- tion framework for autonomous penetration testing. arXiv preprint arXiv:2412.01778 , 2024
-
[80]
Sho Nakatani. Rapidpen: Fully automated ip-to-shell penetration testing with llm- based agents. arXiv preprint arXiv:2502.16730 , 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.