Recognition: no theorem link
Hierarchical Reinforcement Learning with Augmented Step-Level Transitions for LLM Agents
Pith reviewed 2026-05-10 18:45 UTC · model grok-4.3
The pith
Hierarchical reinforcement learning lets LLM agents learn from single-step transitions augmented with subtask progress and local summaries instead of full histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STEP-HRL structures tasks hierarchically so that completed subtasks represent global progress and a local progress module selectively summarizes interaction history within each subtask; together these elements produce augmented step-level transitions that allow both high-level and low-level policies to learn effectively from single steps alone rather than full histories.
What carries the argument
The augmented step-level transition, which packages a single-step observation with representations of completed subtasks for global progress and an iteratively generated local progress summary.
If this is right
- High-level policy can select subtasks using only global progress markers without replaying prior steps.
- Low-level policy can execute actions using only the local summary for the current subtask.
- Token usage drops because policies no longer condition on accumulating full histories.
- Performance and generalization improve on the tested interactive benchmarks relative to non-hierarchical baselines.
Where Pith is reading between the lines
- The same augmentation pattern could be tested on additional agent environments that currently suffer from context-length limits.
- If the local progress module generalizes, it might reduce reliance on ever-longer context windows in future LLM agent designs.
- The separation of global and local progress representations suggests a possible route to modular policy reuse across related tasks.
Load-bearing premise
Single-step transitions that carry hierarchical subtask completions and local progress summaries contain enough information for the high-level and low-level policies to learn successful behaviors.
What would settle it
A controlled comparison in which agents receive only raw single-step transitions without the subtask-completion or local-summary augmentations and still match or exceed STEP-HRL success rates on ScienceWorld and ALFWorld.
Figures






read the original abstract
Large language model (LLM) agents have demonstrated strong capabilities in complex interactive decision-making tasks. However, existing LLM agents typically rely on increasingly long interaction histories, resulting in high computational cost and limited scalability. In this paper, we propose STEP-HRL, a hierarchical reinforcement learning (HRL) framework that enables step-level learning by conditioning only on single-step transitions rather than full interaction histories. STEP-HRL structures tasks hierarchically, using completed subtasks to represent global progress of overall task. By introducing a local progress module, it also iteratively and selectively summarizes interaction history within each subtask to produce a compact summary of local progress. Together, these components yield augmented step-level transitions for both high-level and low-level policies. Experimental results on ScienceWorld and ALFWorld benchmarks consistently demonstrate that STEP-HRL substantially outperforms baselines in terms of performance and generalization while reducing token usage. Our code is available at https://github.com/TonyStark042/STEP-HRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces STEP-HRL, a hierarchical reinforcement learning framework for LLM agents. Tasks are decomposed into subtasks whose completions represent global progress; within each subtask an iterative selective summarizer produces compact local-progress summaries. These elements augment single-step transitions so that both high- and low-level policies condition only on the current transition plus the summary and completion flag rather than full histories. Experiments on ScienceWorld and ALFWorld are reported to show consistent gains in success rate, generalization, and token efficiency over baselines.
Significance. If the performance claims survive rigorous controls and ablations, the approach offers a concrete route to scaling LLM agents on long-horizon interactive tasks by replacing ever-growing context with hierarchical structure and selective summarization. The public code release supports reproducibility.
major comments (2)
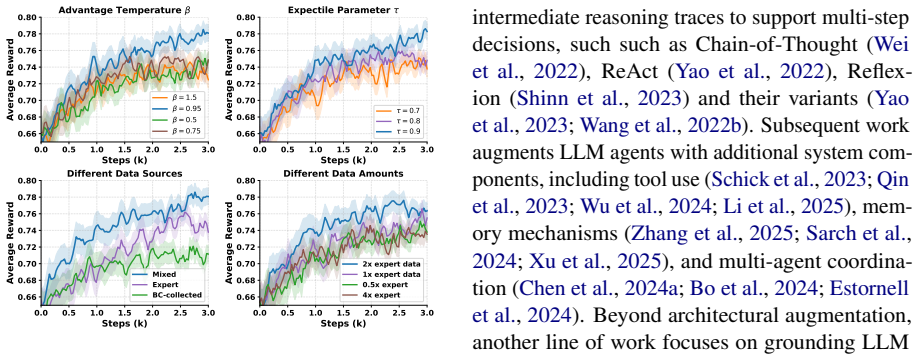
- [§4 (Experiments)] §4 (Experiments): the abstract and results claim consistent outperformance on two standard benchmarks, yet the text supplies no information on the number of runs, standard deviations, statistical significance tests, or ablation studies that isolate the contribution of the hierarchical decomposition versus the local-progress summarizer. This leaves the central empirical claim only partially supported.
- [§3.2 (Local Progress Module)] §3.2 (Local Progress Module): the iterative selective summarizer is asserted to produce sufficient information for both high- and low-level policies, but no analysis or controlled experiment demonstrates that cross-subtask causal dependencies are preserved. In ScienceWorld tasks containing long causal chains, an early observation in subtask A can invalidate a plan in subtask C; the high-level policy receives only a completion flag and a compressed local view, and no section tests whether replacing summaries with raw subtask histories changes performance.
minor comments (2)
- [Abstract] The abstract states that STEP-HRL 'substantially outperforms baselines' without naming the baselines or reporting quantitative deltas.
- [§3.1] Notation for the augmented transition tuple (s, a, r, s', summary, completion) is introduced without an explicit equation; a numbered definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate additional experimental details and analyses as outlined.
read point-by-point responses
-
Referee: §4 (Experiments): the abstract and results claim consistent outperformance on two standard benchmarks, yet the text supplies no information on the number of runs, standard deviations, statistical significance tests, or ablation studies that isolate the contribution of the hierarchical decomposition versus the local-progress summarizer. This leaves the central empirical claim only partially supported.
Authors: We agree that the current manuscript lacks these statistical details and ablations, which weakens the empirical claims. In the revised version, we will report results from multiple independent runs (with the exact number specified), include standard deviations in all tables, conduct statistical significance tests (such as paired t-tests against baselines), and add dedicated ablation studies that separately disable the hierarchical decomposition and the local-progress summarizer to quantify their individual contributions. revision: yes
-
Referee: §3.2 (Local Progress Module): the iterative selective summarizer is asserted to produce sufficient information for both high- and low-level policies, but no analysis or controlled experiment demonstrates that cross-subtask causal dependencies are preserved. In ScienceWorld tasks containing long causal chains, an early observation in subtask A can invalidate a plan in subtask C; the high-level policy receives only a completion flag and a compressed local view, and no section tests whether replacing summaries with raw subtask histories changes performance.
Authors: We acknowledge that the manuscript does not include a direct test of whether the selective summaries preserve cross-subtask causal information. In the revision, we will add a controlled experiment on ScienceWorld tasks with long causal chains. This will compare the full STEP-HRL model against a variant in which the high-level policy receives raw subtask histories (instead of summaries) while keeping all other components fixed, thereby quantifying any performance drop and validating the sufficiency of the compressed local views. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmark experiments, not self-referential derivations
full rationale
The paper introduces STEP-HRL as a hierarchical framework that augments single-step transitions with subtask completion flags and local progress summaries. No equations, derivations, or fitted parameters are presented that could reduce claimed performance gains to quantities defined by construction from the inputs. All central claims are supported by direct experimental comparisons on ScienceWorld and ALFWorld rather than any self-definition, prediction-from-fit, or self-citation chain. The absence of mathematical structure eliminates the patterns of self-definitional, fitted-input, or ansatz-smuggled circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of reinforcement learning (Markov property at the chosen abstraction level) hold for the hierarchical policies.
Reference graph
Works this paper leans on
-
[1]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978. Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xi- angliang Zhang. 2024. Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680. Tuomas Haarnoja, Aurick Zhou, P...
work page internal anchor Pith review arXiv 2024
-
[2]
Offline Reinforcement Learning with Implicit Q-Learning
Offline reinforcement learning with implicit q-learning.arXiv preprint arXiv:2110.06169. Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clin- ton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyürek, Anima Anandkumar, and 1 others. 2022. Pre-trained language models for interactive decision- making.Advances in Neural Information Processing Systems, 35:311...
work page internal anchor Pith review arXiv 2022
-
[3]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Kalm: Knowledgeable agents by offline rein- forcement learning from large language model roll- outs.Advances in Neural Information Processing Systems, 37:126620–126652. Feng Peiyuan, Yichen He, Guanhua Huang, Yuan Lin, Hanchong Zhang, Yuchen Zhang, and Hang Li. 2024. Agile: A novel reinforcement learning framework of llm agents.Advances in Neural Informat...
work page internal anchor Pith review arXiv 2024
-
[4]
Yimeng Ren, Yanhua Yu, Lizi Liao, Yuhu Shang, Kangkang Lu, and Mingliang Yan
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Yimeng Ren, Yanhua Yu, Lizi Liao, Yuhu Shang, Kangkang Lu, and Mingliang Yan. 2025. R2dqg: a quality meets diversity framework for question gen- eration over knowledge bases. InProceedings of the Thirty-Fourth I...
2025
-
[5]
Proximal Policy Optimization Algorithms
Vlm agents generate their own memories: Dis- tilling experience into embodied programs of thought. Advances in Neural Information Processing Systems, 37:75942–75985. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Gemma: Open Models Based on Gemini Research and Technology
Large language models as generalizable poli- cies for embodied tasks. InThe Twelfth International Conference on Learning Representations. Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, and 1 others. 2024. Gemma: Open models based on gemini rese...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
A-MEM: Agentic Memory for LLM Agents
Avatar: Optimizing llm agents for tool us- age via contrastive reasoning.Advances in Neural Information Processing Systems, 37:25981–26010. Weimin Xiong, Yifan Song, Xiutian Zhao, Wenhao Wu, Xun Wang, Ke Wang, Cheng Li, Wei Peng, and Sujian Li. 2024. Watch every step! LLM agent learning via iterative step-level process refinement. InProceedings of the 202...
work page internal anchor Pith review arXiv 2024
-
[8]
InProceed- ings of the 41st International Conference on Machine Learning, pages 55434–55464
Language agents with reinforcement learning for strategic play in the werewolf game. InProceed- ings of the 41st International Conference on Machine Learning, pages 55434–55464. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
-
[9]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning repres...
2022
-
[10]
EPO: Hierarchical LLM agents with environ- ment preference optimization. InProceedings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing, pages 6401–6415, Miami, Florida, USA. Association for Computational Lin- guistics. Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low,...
-
[11]
DoNOTrephrase or normalize names
Exact token matching:All object and location namesMUST EXACTLYmatch strings in the subtask or observation. DoNOTrephrase or normalize names. 2.No invented facts:DoNOTinfer properties, conditions, or failures unless explicitly stated
-
[12]
Locate Tasks Output:<progress sentence> || [Checked: loc1, loc2,
Task type:Subtasks starting with Locate and pick up or Locate and use areLocatetasks; all others are Non-Locatetasks. Locate Tasks Output:<progress sentence> || [Checked: loc1, loc2, . . . ]
-
[13]
Add the current locationONLY IFa search action is taken and the target is confirmedNOTpresent
Checked update:Retain all previous locations. Add the current locationONLY IFa search action is taken and the target is confirmedNOTpresent. 2.Termination:If the target is found or picked up, the search ends and must not continue
-
[14]
New + Except:For new <OBJ> except <OBJ> N , any different-numbered <OBJ> completes the subtask immediately
-
[15]
Unsuccessful search:The sentence must include unchecked and imply door states (opened / closed), without mentioning specific unchecked locations
-
[16]
Non-Locate Tasks (Place / Clean / Heat / Cool / Use) Output:<progress sentence>
Language constraints:DoNOTmention checked locations, reuse fixed templates, or repeat more than3 consecutive wordsfrom the previous progress. Non-Locate Tasks (Place / Clean / Heat / Cool / Use) Output:<progress sentence>
-
[17]
Mention the objectONLY IFit appears in the current action
DoNOTincludeCheckedor any tags. Mention the objectONLY IFit appears in the current action
-
[18]
3.No failure reasoning:DoNOTexplain progress via unmet conditions or missing objects
No existence or location statements:DoNOTstate or imply object presence, absence, containment, or discovery. 3.No failure reasoning:DoNOTexplain progress via unmet conditions or missing objects. 4.Assumed availability:Treat the target object as available by definition of the subtask. 5.Allowed content only:Describe only the executed operation or its direc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.