Recognition: 2 theorem links
· Lean TheoremNeural Network Pruning via QUBO Optimization
Pith reviewed 2026-05-10 19:34 UTC · model grok-4.3
The pith
A hybrid QUBO approach to neural network pruning captures both filter importance and redundancy for better compression results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
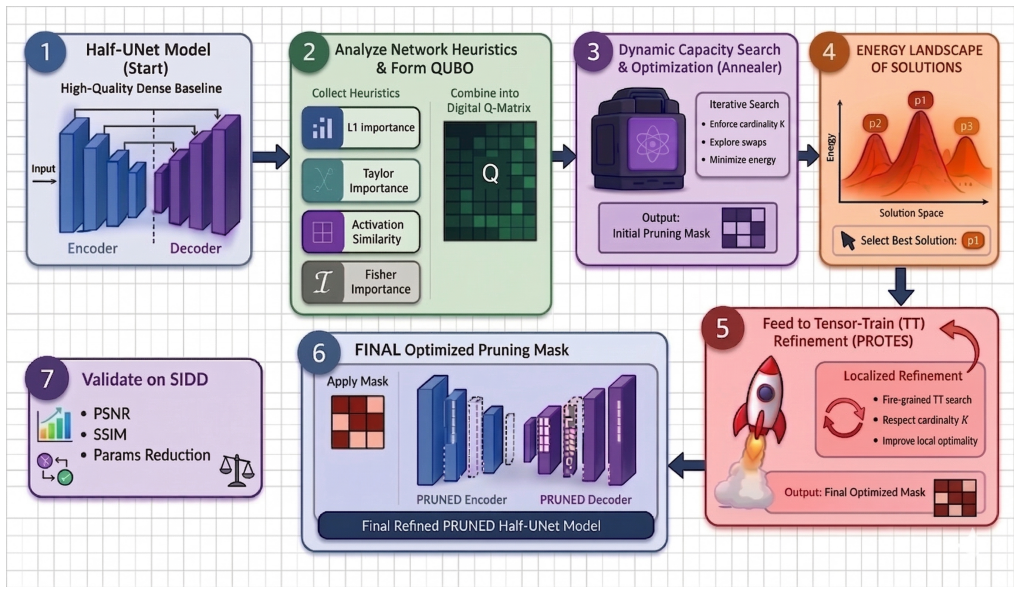
The authors claim that their Hybrid QUBO framework bridges heuristic importance estimation with global combinatorial optimization by integrating gradient-aware sensitivity metrics into the linear term and data-driven activation similarity into the quadratic term, while employing dynamic capacity-driven search and a two-stage TT Refinement pipeline, which together outperform both greedy Taylor pruning and traditional L1-based QUBO on the SIDD image denoising dataset.
What carries the argument
The Hybrid QUBO objective function that places Taylor and Fisher sensitivity metrics in the linear term and activation similarity in the quadratic term, solved under a dynamic capacity constraint and refined by tensor-train optimization.
If this is right
- The Hybrid QUBO significantly outperforms greedy Taylor pruning and L1-based QUBO on SIDD.
- TT Refinement provides additional consistent gains at appropriate scales.
- This approach enables more robust and interpretable neural network compression.
- Hybrid combinatorial formulations can improve pruning by accounting for inter-filter interactions.
Where Pith is reading between the lines
- This method could extend to pruning other types of neural networks beyond those tested for denoising.
- Improved pruning may allow larger models to fit on edge devices with less accuracy loss.
- Future work might test if similar QUBO hybrids work for quantization or architecture search.
Load-bearing premise
The chosen proxies of first-order Taylor, second-order Fisher information, and activation similarity accurately measure true filter relevance and redundancy without systematic bias.
What would settle it
An experiment on the SIDD dataset where the Hybrid QUBO pruned model fails to achieve higher denoising quality than the greedy Taylor baseline at the same target sparsity level.
Figures



read the original abstract
Neural network pruning can be formulated as a combinatorial optimization problem, yet most existing approaches rely on greedy heuristics that ignore complex interactions between filters. Formal optimization methods such as Quadratic Unconstrained Binary Optimization (QUBO) provide a principled alternative but have so far underperformed due to oversimplified objective formulations based on metrics like the L1-norm. In this work, we propose a unified Hybrid QUBO framework that bridges heuristic importance estimation with global combinatorial optimization. Our formulation integrates gradient-aware sensitivity metrics - specifically first-order Taylor and second-order Fisher information - into the linear term, while utilizing data-driven activation similarity in the quadratic term. This allows the QUBO objective to jointly capture individual filter relevance and inter-filter functional redundancy. We further introduce a dynamic capacity-driven search to strictly enforce target sparsity without distorting the optimization landscape. Finally, we employ a two-stage pipeline featuring a Tensor-Train (TT) Refinement stage - a gradient-free optimizer that fine-tunes the QUBO-derived solution directly against the true evaluation metric. Experiments on the SIDD image denoising dataset demonstrate that the proposed Hybrid QUBO significantly outperforms both greedy Taylor pruning and traditional L1-based QUBO, with TT Refinement providing further consistent gains at appropriate combinatorial scales. This highlights the potential of hybrid combinatorial formulations for robust, scalable, and interpretable neural network compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Hybrid QUBO framework for neural network pruning. The linear term of the QUBO objective integrates first-order Taylor and second-order Fisher information for filter sensitivity, while the quadratic term uses data-driven activation similarity to capture redundancy. A dynamic capacity-driven search enforces target sparsity, and a two-stage pipeline adds Tensor-Train (TT) Refinement to fine-tune the discrete solution against the true metric. Experiments on the SIDD image denoising dataset are claimed to show that Hybrid QUBO significantly outperforms greedy Taylor pruning and L1-based QUBO, with further gains from TT Refinement.
Significance. If the empirical results hold under rigorous validation, the work could meaningfully advance combinatorial pruning methods by moving beyond purely greedy or oversimplified L1 objectives toward a hybrid that jointly models importance and interactions. The TT Refinement stage is a constructive addition that directly optimizes the evaluation metric rather than relying solely on the surrogate.
major comments (3)
- [Abstract] Abstract: The central claim of significant outperformance on SIDD supplies no network architecture, dataset details, number of trials, error bars, statistical tests, or quantitative deltas, rendering the empirical result impossible to assess or reproduce.
- [Formulation] The QUBO formulation (linear term from Taylor + Fisher, quadratic from activation similarity): these are local first- and second-order proxies whose correlation with actual post-pruning PSNR on SIDD is not demonstrated; without such validation the combinatorial solver may optimize a mis-specified objective, undermining the headline superiority claim.
- [Experiments] Experiments section: no ablation isolating the contribution of the hybrid linear term versus the activation-similarity quadratic term, nor comparison against the dynamic capacity constraint alone, leaves the necessity of the full Hybrid QUBO unproven.
minor comments (2)
- [Abstract] The acronym TT is introduced without expansion on first use.
- [Method] The description of how the dynamic capacity constraint is implemented without distorting the QUBO landscape would benefit from an explicit equation or pseudocode.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and the opportunity to improve our manuscript. We address each major comment below and outline the revisions we will make to enhance the paper's clarity, rigor, and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of significant outperformance on SIDD supplies no network architecture, dataset details, number of trials, error bars, statistical tests, or quantitative deltas, rendering the empirical result impossible to assess or reproduce.
Authors: We fully agree with this observation. The abstract in the current version is indeed too concise and omits critical details necessary for evaluating and reproducing the results. In the revised manuscript, we will update the abstract to include: the specific network architecture employed for the SIDD denoising task, details on the SIDD dataset (e.g., number of images, train/test split), the number of experimental trials conducted, error bars or standard deviations, any statistical tests performed, and specific quantitative deltas in performance metrics such as PSNR. These additions will make the empirical claims transparent and assessable. revision: yes
-
Referee: [Formulation] The QUBO formulation (linear term from Taylor + Fisher, quadratic from activation similarity): these are local first- and second-order proxies whose correlation with actual post-pruning PSNR on SIDD is not demonstrated; without such validation the combinatorial solver may optimize a mis-specified objective, undermining the headline superiority claim.
Authors: This is a valid concern. While our experiments show that the Hybrid QUBO approach leads to better post-pruning PSNR than the compared baselines, we did not explicitly demonstrate the correlation between the individual components of the QUBO objective (Taylor/Fisher linear terms and activation similarity quadratic term) and the final PSNR values on SIDD. To address this, we will add a new analysis or figure in the revised paper that examines this correlation, for example through scatter plots or computed correlation metrics across pruned models. This will help validate that the objective is well-specified and support the superiority claims. revision: yes
-
Referee: [Experiments] Experiments section: no ablation isolating the contribution of the hybrid linear term versus the activation-similarity quadratic term, nor comparison against the dynamic capacity constraint alone, leaves the necessity of the full Hybrid QUBO unproven.
Authors: We acknowledge that the current experiments section does not include sufficient ablations to isolate the effects of each proposed component. The manuscript compares the full Hybrid QUBO to greedy Taylor pruning and L1-based QUBO but lacks breakdowns such as using only the hybrid linear term, only the quadratic term, or the framework without the dynamic capacity-driven search. In the revision, we will incorporate these ablation studies to clearly demonstrate the contribution and necessity of the full Hybrid QUBO formulation, including the dynamic capacity constraint. revision: yes
Circularity Check
No significant circularity detected
full rationale
The Hybrid QUBO formulation computes its linear coefficients directly from independent first-order Taylor and second-order Fisher metrics on the trained network, and its quadratic term from separate data-driven activation similarity computations. These inputs are external to the optimization result. The QUBO solver then produces a binary mask, which is further refined by a gradient-free TT stage that directly optimizes the true evaluation metric (PSNR on SIDD). No equation or step reduces the claimed outperformance to a fitted parameter, self-citation chain, or input by construction. The experimental comparison to baselines is an empirical claim supported by independent runs, not a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient-based sensitivity metrics and activation similarity accurately capture filter importance and redundancy for pruning decisions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our formulation integrates gradient-aware sensitivity metrics—specifically first-order Taylor and second-order Fisher information—into the linear term, while utilizing data-driven activation similarity in the quadratic term.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Qii = β_diag Aii + α I_Taylor_i + α_F I_Fisher_i − γ D_i; Qij = 2 β_off Aij + λ max(0, Sij)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Benbaki, R.; Chen, W.; Meng, X.; Hazimeh, H.; Pono- mareva, N.; Zhao, Z.; and Mazumder, R
PROTES: probabilistic optimization with tensor sam- pling.Advances in Neural Information Processing Systems, 36: 808–823. Benbaki, R.; Chen, W.; Meng, X.; Hazimeh, H.; Pono- mareva, N.; Zhao, Z.; and Mazumder, R. 2023. Fast as chita: Neural network pruning with combinatorial optimization. InInternational Conference on Machine Learning, 2031–
2023
-
[2]
Pruning Filters for Efficient ConvNets
PMLR. Chen, L.; Chu, X.; Zhang, X.; and Sun, J. 2022. Simple baselines for image restoration. InEuropean conference on computer vision, 17–33. Springer. Cheng, H.; Zhang, M.; and Shi, J. Q. 2024. A survey on deep neural network pruning: Taxonomy, comparison, anal- ysis, and recommendations.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46...
work page Pith review arXiv 2022
-
[3]
Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; and Zhang, C
PMLR. Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; and Zhang, C. 2017. Learning efficient convolutional networks through network slimming. InProceedings of the IEEE international conference on computer vision, 2736–2744. Lu, H.; She, Y .; Tie, J.; and Xu, S. 2022. Half-UNet: A sim- plified U-Net architecture for medical image segmentation. Frontiers in ...
2017
-
[4]
In Symposium on Simplicity in Algorithms (SOSA), 142–155
Hutch++: Optimal randomized trace estimation. In Symposium on Simplicity in Algorithms (SOSA), 142–155. SIAM. Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; and Kautz, J. 2019. Importance estimation for neural network pruning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11264–11272. Navarrete, I. G.; ´Avila, N. ...
-
[5]
Zhang, X.; Zhou, X.; Lin, M.; and Sun, J
Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising.IEEE transactions on image processing, 26(7): 3142–3155. Zhang, X.; Zhou, X.; Lin, M.; and Sun, J. 2018. ShuffleNet: An extremely efficient convolutional neural network for mo- bile devices. InProceedings of the IEEE conference on com- puter vision and pattern recognition, 6848–...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.