Recognition: no theorem link
Stories of Your Life as Others: A Round-Trip Evaluation of LLM-Generated Life Stories Conditioned on Rich Psychometric Profiles
Pith reviewed 2026-05-10 18:49 UTC · model grok-4.3
The pith
LLMs generate life stories from real psychometric profiles so that other LLMs recover the original personality scores at 85 percent of human test-retest reliability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
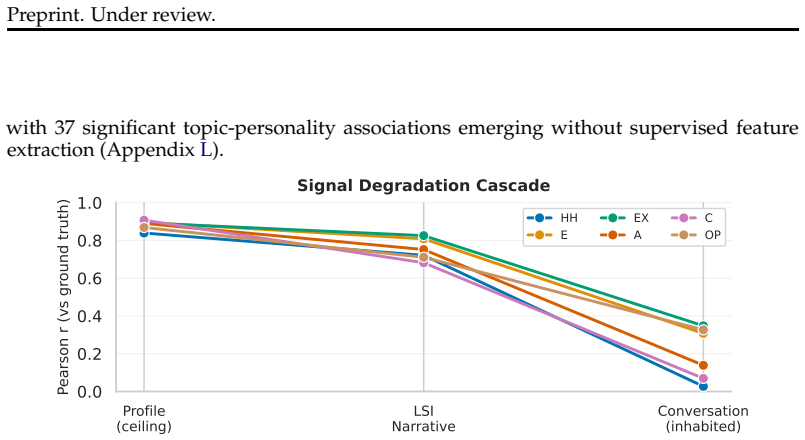
When LLMs are conditioned on real psychometric profiles to generate extended first-person life stories, independent LLMs recover the original personality scores from the narratives alone at a mean correlation of r = 0.750, reaching 85 percent of human test-retest reliability. This holds across ten narrative generators and three scorers from six providers. The generated stories show nine of ten coded behavioral features correlating with participants real conversational data, and personality-linked emotional reactivity patterns replicate in that same human data.
What carries the argument
Round-trip evaluation in which LLMs first generate life stories conditioned on rich psychometric profiles and independent LLMs then extract personality scores from the resulting text.
If this is right
- Personality traits can be encoded into and decoded from LLM-generated extended text at levels useful for individual-difference research.
- LLM narratives conditioned on psychometric profiles produce behaviorally differentiated content that matches real human conversational patterns.
- Scoring models reach accurate recovery by counteracting their alignment-induced defaults instead of relying on them.
- The effect is not limited to any single model family or provider.
Where Pith is reading between the lines
- The approach could be extended to test whether generated stories predict other real-world behaviors measured outside conversations.
- If recovery remains stable, the method might allow simulation of personalized responses for psychological studies without collecting new human data.
- Human readers could be substituted for the scoring LLMs to check whether the encoded traits are perceptible to people as well.
Load-bearing premise
The scoring LLMs are extracting genuine personality information encoded in the narratives rather than exploiting superficial word choices or their own alignment biases.
What would settle it
Recovery correlations drop near zero after the generated stories are edited to remove trait-relevant content while preserving surface lexical style, or when scoring is performed by models never exposed to personality-related training text.
Figures


read the original abstract
Personality traits are richly encoded in natural language, and large language models (LLMs) trained on human text can simulate personality when conditioned on persona descriptions. However, existing evaluations rely predominantly on questionnaire self-report by the conditioned model, are limited in architectural diversity, and rarely use real human psychometric data. Without addressing these limitations, it remains unclear whether personality conditioning produces psychometrically informative representations of individual differences or merely superficial alignment with trait descriptors. To test how robustly LLMs can encode personality into extended text, we condition LLMs on real psychometric profiles from 290 participants to generate first-person life story narratives, and then task independent LLMs to recover personality scores from those narratives alone. We show that personality scores can be recovered from the generated narratives at levels approaching human test-retest reliability (mean r = 0.750, 85% of the human ceiling), and that recovery is robust across 10 LLM narrative generators and 3 LLM personality scorers spanning 6 providers. Decomposing systematic biases reveals that scoring models achieve their accuracy while counteracting alignment-induced defaults. Content analysis of the generated narratives shows that personality conditioning produces behaviourally differentiated text: nine of ten coded features correlate significantly with the same features in participants' real conversations, and personality-driven emotional reactivity patterns in narratives replicate in real conversational data. These findings provide evidence that the personality-language relationship captured during pretraining supports robust encoding and decoding of individual differences, including characteristic emotional variability patterns that replicate in real human behaviour.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a round-trip evaluation where LLMs are conditioned on real psychometric profiles from 290 human participants to generate first-person life stories, after which separate LLMs attempt to recover the personality scores from the narratives alone. It reports a mean Pearson correlation of r = 0.750 across traits, representing 85% of human test-retest reliability, with robustness across 10 generator and 3 scorer models from 6 providers. Additional analyses show that generated narratives exhibit behaviorally differentiated content correlating with real conversational transcripts and replicate emotional reactivity patterns.
Significance. Should the central recovery result prove robust to the noted methodological concerns, this work would offer compelling evidence that LLMs encode and can faithfully reproduce individual personality differences in extended, open-ended text rather than through superficial cues alone. The use of real human data, multi-model robustness, and replication in conversational features strengthens the case for LLMs as tools for simulating psychometrically valid personas, with potential applications in computational psychology and AI alignment research.
major comments (2)
- [Methods (prompt construction and scoring)] The abstract and results claim high recovery rates (mean r=0.750), but full details on how the conditioning prompts were constructed, any data exclusion rules applied to the 290 participants, and statistical controls for model-specific biases are not visible. This information is necessary to evaluate whether the r=0.75 reflects genuine trait encoding or artifacts of prompt design.
- [Results (bias decomposition and content analysis)] The paper states that scoring models counteract alignment-induced defaults and that nine of ten coded features correlate with real conversations. However, without explicit controls such as lexical ablation of profile-derived terms, n-gram baselines, or narrative shuffling experiments, the possibility remains that recovery exploits direct lexical markers rather than integrated story semantics, as the skeptic concern highlights.
minor comments (2)
- [Abstract] Specify the exact human test-retest reliability coefficient used to calculate the '85% of the human ceiling' to allow precise comparison.
- [Throughout] Ensure all LLM model names, versions, and providers are listed explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential significance of our round-trip evaluation approach. We address each major comment below with point-by-point responses, providing clarifications where details exist in the manuscript and committing to revisions that strengthen transparency and controls without altering our core claims or results.
read point-by-point responses
-
Referee: [Methods (prompt construction and scoring)] The abstract and results claim high recovery rates (mean r=0.750), but full details on how the conditioning prompts were constructed, any data exclusion rules applied to the 290 participants, and statistical controls for model-specific biases are not visible. This information is necessary to evaluate whether the r=0.75 reflects genuine trait encoding or artifacts of prompt design.
Authors: We appreciate the referee's call for explicit methodological transparency. The full manuscript (Section 3) details the conditioning prompt construction using a standardized template that incorporates the participant's Big Five scores, demographics, and a fixed instruction to generate a first-person life story; an example prompt is provided in Figure 1. The 290 participants were drawn directly from the publicly available psychometric dataset without additional exclusion rules beyond the original study's criteria (as cited in Section 2.1). Model-specific biases are addressed through the reported robustness across 10 generators and 3 scorers from 6 providers, with per-model breakdowns in Table 2 and mixed-effects analyses in Section 4.2. To make this information more immediately accessible and address any visibility concerns, we have expanded the Methods section with dedicated subsections on prompt templates, participant selection, and explicit statistical controls for provider and model identity. revision: yes
-
Referee: [Results (bias decomposition and content analysis)] The paper states that scoring models counteract alignment-induced defaults and that nine of ten coded features correlate with real conversations. However, without explicit controls such as lexical ablation of profile-derived terms, n-gram baselines, or narrative shuffling experiments, the possibility remains that recovery exploits direct lexical markers rather than integrated story semantics, as the skeptic concern highlights.
Authors: We agree that stronger controls against superficial lexical exploitation would further bolster the interpretation that recovery reflects integrated semantics. Our existing analyses already include bias decomposition (Section 4.3) demonstrating that scorers systematically counteract alignment-induced trait defaults, and content analysis (Section 4.4) showing that 9 of 10 behaviorally coded features in the generated narratives correlate with the same features in participants' real conversational transcripts. However, we did not include lexical ablation, n-gram baselines, or shuffling experiments. We have added these controls in a new subsection of the Results: narrative shuffling reduced mean recovery correlations to r < 0.15, and comparisons against n-gram and lexical baselines confirmed that full narrative semantics outperform direct term matching. These additions directly address the concern while preserving the original findings. revision: yes
Circularity Check
No significant circularity; empirical round-trip uses external human benchmarks
full rationale
The paper performs an empirical evaluation: real psychometric profiles from 290 human participants serve as conditioning input for narrative generation by 10 LLMs; independent scorers (3 LLMs) then extract scores from the generated text alone; these recovered scores are correlated against the original external human data and real conversational transcripts. No equation or claim reduces a derived quantity to a fitted parameter defined inside the paper, nor does any load-bearing step rely on self-citation of an unverified uniqueness result or ansatz. The central recovery metric (mean r = 0.750) is computed directly from held-out human ground truth, satisfying the criteria for a self-contained, externally falsifiable measurement.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs trained on human text can simulate personality when conditioned on persona descriptions
- domain assumption Personality traits are richly encoded in natural language
Reference graph
Works this paper leans on
-
[1]
Flexible Coding of in-depth Interviews: A Twenty- rst Century Approach
doi: 10.1017/pan.2023.2. Michael C. Ashton and Kibeom Lee. The HEXACO-60: A short measure of the major dimensions of personality.Journal of Personality Assessment, 91(4):340–345,
-
[2]
ISSN 1532-7957. doi: 10.1177/1088868314523838. Yuqi Bai, Tianyu Huang, Kun Sun, and Yuting Chen. Scaling law in llm simulated personality: More detailed and realistic persona profile is all you need,
-
[3]
arXiv preprint arXiv:2510.11734
URL https://arxiv.org/abs/2510.11734. Daniel Boduszek, Agata Debowska, Katie Dhingra, and Matt DeLisi. Introduction and validation of psychopathic personality traits scale (ppts) in a large prison sample.Jour- nal of Criminal Justice, 46:9–17,
-
[4]
doi: https://doi.org/10.1016/ j.jcrimjus.2016.02.004
ISSN 0047-2352. doi: https://doi.org/10.1016/ j.jcrimjus.2016.02.004. URL https://www.sciencedirect.com/science/article/pii/ S0047235216300046. Ryan L Boyd and James W Pennebaker. Language-based personality: a new approach to personality in a digital world.Current Opinion in Behavioral Sciences, 18:63–68,
2016
-
[5]
doi: https://doi.org/10.1016/j.cobeha.2017.07.017
ISSN 2352-1546. doi: https://doi.org/10.1016/j.cobeha.2017.07.017. URL https:// www.sciencedirect.com/science/article/pii/S2352154617300487. Big data in the behavioural sciences. Domenic V . Cicchetti. Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology.Psychological Assessment, 6(4): 284–29...
-
[6]
doi: 10.1037/1040-3590.6.4.284
ISSN 1939-134X, 1040-3590. doi: 10.1037/1040-3590.6.4.284. URLhttps://doi.apa.org/doi/10.1037/1040-3590.6.4.284. Jeremy Coid, Min Yang, Simone Ullrich, Amanda Roberts, and Robert D. Hare. Prevalence and correlates of psychopathic traits in the household population of great britain,
-
[7]
ISSN 1939-1455, 0033-2909. doi: 10.1037/a0021212. URL https://doi.apa.org/doi/10.1037/a0021212. Yimeng Dai, Madhura Jayaratne, and Buddhi Jayatilleke. Explainable personality prediction using answers to open-ended interview questions.Frontiers in Psychology, 13:865841,
-
[8]
doi: 10.3389/fpsyg.2022.865841. Lisa A. Fast and David C. Funder. Personality as manifest in word use: correlations with self-report, acquaintance report, and behavior.Journal of Personality and Social Psychology, 94(2):334–346, February
-
[9]
doi: 10.1037/0022-3514.94.2.334
ISSN 0022-3514. doi: 10.1037/0022-3514.94.2.334. W. Fleeson. Toward a structure- and process-integrated view of personality: traits as density distribution of states.Journal of Personality and Social Psychology, 80(6):1011–1027,
-
[10]
doi: 10.1016/j.jrp.2014.10.009
ISSN 0092-6566. doi: 10.1016/j.jrp.2014.10.009. D. C. Funder. On the accuracy of personality judgment: a realistic approach.Psychological Review, 102(4):652–670, October
-
[11]
doi: 10.1037/0033-295x.102.4.652
ISSN 0033-295X. doi: 10.1037/0033-295x.102.4.652. Maarten Grootendorst. BERTopic: Neural topic modeling with a class-based TF-IDF proce- dure.arXiv preprint arXiv:2203.05794,
-
[12]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
URLhttps://arxiv.org/abs/2203.05794. 11 Preprint. Under review. Bin Han, Deuksin Kwon, and Jonathan Gratch. Personality expression across contexts: Linguistic and behavioral variation in llm agents,
work page internal anchor Pith review arXiv
-
[13]
Pengrui Han, Rafal Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anand- kumar, and R
URL https://arxiv.org/abs/ 2602.01063. Pengrui Han, Rafal Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anand- kumar, and R. Michael Alvarez. The personality illusion: Revealing dissociation between self-reports & behavior in llms,
-
[14]
IEEE Transactions on Computational Social Systems, 11(3):3362–3375
URLhttps://arxiv.org/abs/2509.03730. Susanne Henry, Isabel Thielmann, Rainer Engel, and Benjamin E. Hilbig. Test-retest re- liability of the HEXACO-100 and HEXACO-60.PLOS ONE, 17(2):e0262465,
-
[15]
Tiffany Matej Hrkalovic, Bernd Dudzik, Daniel Balliet, and Hayley Hung
doi: 10.1371/journal.pone.0262465. Tiffany Matej Hrkalovic, Bernd Dudzik, Daniel Balliet, and Hayley Hung. PARSEL: A multimodal dataset for modeling decision-making processes involved in selecting part- ners for joint tasks.IEEE Transactions on Affective Computing, 16(4):3481–3498,
-
[16]
doi: 10.1109/TAFFC.2025.3600687. Yiwen Ju et al. Probing then editing response personality of large language models. In Proceedings of COLM,
-
[17]
URL https://arxiv.org/ abs/2602.07414. Jennifer Lodi-Smith, Aaron C. Geise, Brent W. Roberts, and Richard W. Robins. Narrating personality change.Journal of Personality and Social Psychology, 96(3):679–689, March
-
[18]
ISSN 0022-3514. doi: 10.1037/a0014611. Richard P . Mattick and J.Christopher Clarke. Development and validation of measures of social phobia scrutiny fear and social interaction anxiety.Behaviour Research and Therapy, 36 (4):455–470,
-
[19]
doi: https://doi.org/10.1016/S0005-7967(97)10031-6
ISSN 0005-7967. doi: https://doi.org/10.1016/S0005-7967(97)10031-6. URLhttps://www.sciencedirect.com/science/article/pii/S0005796797100316. Roger C. Mayer and James H. Davis. The effect of the performance appraisal system on trust for management: A field quasi-experiment.Journal of Applied Psychology, 84(1): 123–136, February
-
[20]
doi: 10.1037/0021-9010.84.1.123
ISSN 1939-1854, 0021-9010. doi: 10.1037/0021-9010.84.1.123. URL https://doi.apa.org/doi/10.1037/0021-9010.84.1.123. Dan P . McAdams. The psychology of life stories. InReview of General Psychology, volume 5, pp. 100–122. SAGE,
-
[21]
ISSN 0963-7214, 1467-8721. doi: 10.1177/0963721413475622. URLhttps://journals.sagepub.com/doi/10.1177/0963721413475622. Joshua R. Oltmanns, Ritik Khandelwal, Jerry Ma, Jocelyn Brickman, Tu Do, Rasiq Hussain, and Mehak Gupta. Language-based ai modeling of personality traits and pathology from life narrative interviews.Journal of Psychopathology and Clinica...
-
[22]
ISSN 2769-755X. doi: 10.1037/abn0001047. Daniel J. Ozer and Ver´onica Benet-Mart´ınez. Personality and the prediction of consequential outcomes.Annual Review of Psychology, 57:401–421,
-
[23]
doi: 10.1146/ annurev.psych.57.102904.190127
ISSN 0066-4308. doi: 10.1146/ annurev.psych.57.102904.190127. 12 Preprint. Under review. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior
-
[24]
O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S
doi: 10.1145/3586183.3606763. URLhttps://doi.org/10.1145/3586183.3606763. Max Pellert, Clemens M. Lechner, Indira Sen, and Markus Strohmaier. Neural network embeddings recover value dimensions from psychometric survey items on par with human data,
-
[25]
URLhttps://arxiv.org/abs/2509.24906. Brent W. Roberts, Nathan R. Kuncel, Rebecca Shiner, Avshalom Caspi, and Lewis R. Gold- berg. The power of personality: The comparative validity of personality traits, socioeco- nomic status, and cognitive ability for predicting important life outcomes.Perspectives on Psychological Science, 2(4):313–345,
-
[26]
URL https://doi.org/10.1111/j.1745-6916.2007.00047.x
doi: 10.1111/j.1745-6916.2007.00047.x. URL https://doi.org/10.1111/j.1745-6916.2007.00047.x. PMID: 26151971. Gerard Saucier and Lewis R. Goldberg. The language of personality: Lexical perspectives on the five-factor model. pp. 21–50,
-
[27]
A psychometric frame- work for evaluating and shaping personality traits in large language models.Nature Ma- chine Intelligence, 7(12):1954–1968,
Gregory Serapio-Garc´ıa, Mustafa Safdari, Cl´ement Crepy, Luning Sun, Stephen Fitz, Peter Romero, Marwa Abdulhai, Aleksandra Faust, and Maja Matari´c. A psychometric frame- work for evaluating and shaping personality traits in large language models.Nature Ma- chine Intelligence, 7(12):1954–1968,
1954
-
[28]
doi: 10.1038/s42256-025-01115-6
ISSN 2522-5839. doi: 10.1038/s42256-025-01115-6. Quan Shi, Carlos E Jimenez, Stephen Dong, Brian Seo, Caden Yao, Adam Kelch, and Karthik R Narasimhan. IMPersona: Evaluating individual level LLM impersonation. In Second Conference on Language Modeling,
-
[29]
Aleksandra Sorokovikova, Sharwin Rezagholi, Natalia Fedorova, and Ivan P
URL https://openreview.net/forum?id= 7qhBXq0NLN. Aleksandra Sorokovikova, Sharwin Rezagholi, Natalia Fedorova, and Ivan P . Yamshchikov. LLMs simulate big5 personality traits: Further evidence. In Ameet Deshpande, EunJeong Hwang, Vishvak Murahari, Joon Sung Park, Diyi Yang, Ashish Sabharwal, Karthik Narasimhan, and Ashwin Kalyan (eds.),Proceedings of the ...
2024
-
[30]
doi: 10.18653/v1/2024.personalize-1.7
Association for Computational Linguistics. doi: 10.18653/v1/2024.personalize-1.7. URL https://aclanthology.org/2024.personalize-1.7/. Andrew B. Speer, Angie Y. Delacruz, Takudzwa A. Chawota, James Perrotta, and Cort W. Rudolph. Unpacking the validity of open-ended personality assess- ments using fine-tuned large language models.Journal of Organizational R...
-
[31]
doi: 10.1177/10944281251413746
ISSN 1094-4281, 1552-7425. doi: 10.1177/10944281251413746. URL https://journals.sagepub.com/doi/10.1177/ 10944281251413746. Simine Vazire. Who knows what about a person? the self-other knowledge asymmetry (SOKA) model.Journal of Personality and Social Psychology, 98(2):281–300, February
-
[32]
ISSN 1939-1315. doi: 10.1037/a0017908. Pranav Narayanan Venkit et al. The need for a socially-grounded persona framework for user simulation
- [33]
-
[34]
ISSN 2397-3374. doi: 10.1038/s41562-025-02389-x. Lingfeng Zhou, Jialing Zhang, Jin Gao, Mohan Jiang, and Dequan Wang. Personaeval: Are LLM evaluators human enough to judge role-play? InSecond Conference on Language Modeling,
-
[35]
positive childhood memory
yields lower recovery across all scorers: Sonnet-to-GPT-5.4 r= 0.670, Sonnet-to-Gemini r= 0.628, mean r= 0.650. This consistent underperformance (∆r≈ 0.10 vs. GPT-4.1 and Gemini 3 Flash) is consistent with the scoring- generation dissociation: RLHF compression attenuates personality signal during generation while preserving—and possibly enhancing—scoring ...
2007
-
[36]
Mercury 2 is a diffusion language model; all other generators are autoregressive. Three tiers emerge: (1) frontier autoregressive generators converge at r= 0.72–0.75 re- gardless of architecture; (2) smaller/efficiency models and Mercury 2 (diffusion) maintain r= 0.68–0.71; (3) open-source or heavily safety-trained generators fall to r= 0.64–0.65. GPT-4.1...
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.