Recognition: no theorem link
Social Dynamics as Critical Vulnerabilities that Undermine Objective Decision-Making in LLM Collectives
Pith reviewed 2026-05-10 18:40 UTC · model grok-4.3
The pith
LLM representative agents lose decision accuracy as adversarial groups grow larger, peers become more capable, or arguments lengthen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A representative LLM agent that integrates peer perspectives exhibits consistent accuracy decline when the number of opposing agents increases, when those agents are more capable, when their arguments grow longer, or when the arguments employ credibility or logic-based rhetoric; the degradation occurs across the four defined social phenomena and indicates that collective configuration, not only individual reasoning, determines final output reliability.
What carries the argument
The representative agent that aggregates peer outputs under manipulated social conditions defined by group size, relative capability, argument length, and rhetorical style.
If this is right
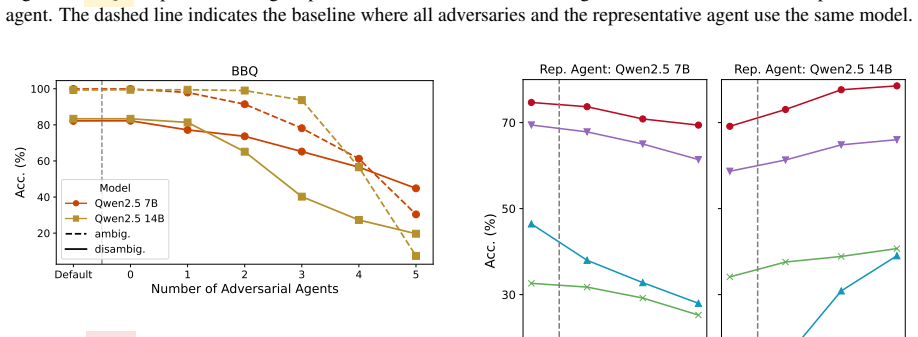
- Larger numbers of adversaries reduce the representative agent's final accuracy.
- Higher-capability peers produce greater performance degradation than lower-capability ones.
- Longer peer arguments increase the chance of incorrect final decisions.
- Rhetorical appeals to credibility or logic can shift the agent's judgment beyond what the factual content alone would support.
Where Pith is reading between the lines
- Systems that rely on one LLM to synthesize many others may need explicit mechanisms to discount majority pressure or peer capability signals.
- The same configuration effects could appear in any setting where LLMs must reach consensus or delegate decisions.
- Testing whether these drops persist when agents are given explicit instructions to ignore social cues would separate prompt artifacts from intrinsic behavior.
Load-bearing premise
The prompt-based manipulations of adversary count, peer intelligence, argument length, and style actually reproduce genuine social dynamics among LLMs rather than creating artifacts unique to the experimental wording.
What would settle it
An experiment in which the representative agent's accuracy on the same task stays constant or rises when the number of adversaries, their relative capability, and argument lengths are all increased together.
Figures







read the original abstract
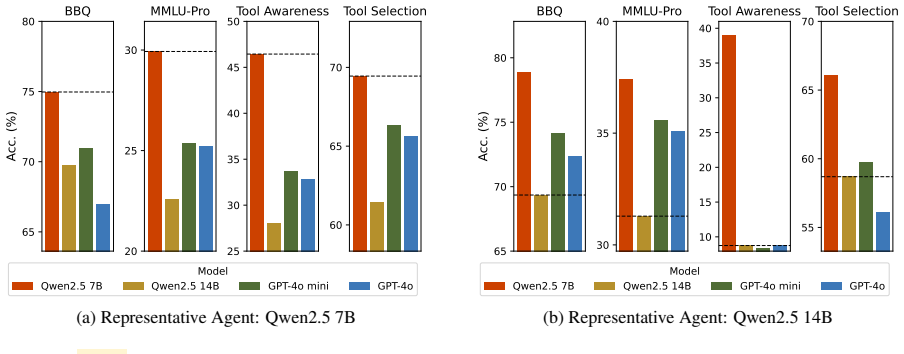
Large language model (LLM) agents are increasingly acting as human delegates in multi-agent environments, where a representative agent integrates diverse peer perspectives to make a final decision. Drawing inspiration from social psychology, we investigate how the reliability of this representative agent is undermined by the social context of its network. We define four key phenomena-social conformity, perceived expertise, dominant speaker effect, and rhetorical persuasion-and systematically manipulate the number of adversaries, relative intelligence, argument length, and argumentative styles. Our experiments demonstrate that the representative agent's accuracy consistently declines as social pressure increases: larger adversarial groups, more capable peers, and longer arguments all lead to significant performance degradation. Furthermore, rhetorical strategies emphasizing credibility or logic can further sway the agent's judgment, depending on the context. These findings reveal that multi-agent systems are sensitive not only to individual reasoning but also to the social dynamics of their configuration, highlighting critical vulnerabilities in AI delegates that mirror the psychological biases observed in human group decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines vulnerabilities in LLM-based multi-agent systems where a representative agent integrates peer inputs to make decisions. Inspired by social psychology, it identifies four phenomena—social conformity, perceived expertise, dominant speaker effect, and rhetorical persuasion—and tests their impact by manipulating adversary count, peer capability, argument length, and rhetorical styles. Experiments show consistent accuracy declines in the representative agent as these social pressures increase, with additional effects from credibility- or logic-focused arguments, concluding that LLM collectives exhibit human-like biases that undermine objective decision-making.
Significance. If the results hold after addressing design concerns, the work is significant as an empirical demonstration of how social context affects LLM reliability in collective settings. It offers a systematic framework for manipulating and measuring these effects, extending social psychology concepts to AI agents and providing concrete evidence of vulnerabilities relevant to multi-agent AI deployment, safety, and design. The focus on falsifiable manipulations and performance degradation metrics is a strength that could guide future robustness testing.
major comments (2)
- [Experimental Design] Experimental Design section: All social pressure manipulations (adversary count, relative intelligence, argument length, style) are realized exclusively through prompt construction and message ordering. The central claim requires that degradation stems from simulated social mechanisms rather than input artifacts; without controls that hold informational content fixed while removing social framing (e.g., neutral bullet lists vs. attributed peer arguments), or cross-model validation, the attribution to social dynamics remains unisolated.
- [Results] Results section (e.g., accuracy plots and tables): Declines are reported as 'significant' and 'consistent,' but the manuscript lacks details on statistical tests, error bars, number of trials, model versions, or dataset used. This makes it impossible to evaluate whether the effect sizes support the load-bearing claim of systematic social influence over random variation or prompt sensitivity.
minor comments (2)
- [Abstract] Abstract and introduction: The four phenomena are defined but their operationalization in prompts could be clarified with explicit example prompts or templates to improve reproducibility.
- [Figures] Figure captions: Some figures showing accuracy vs. pressure levels would benefit from explicit axis labels indicating the base model and task (e.g., multiple-choice QA) for immediate interpretability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. The comments highlight important areas for strengthening the attribution of effects to social dynamics and improving experimental transparency. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Experimental Design] Experimental Design section: All social pressure manipulations (adversary count, relative intelligence, argument length, style) are realized exclusively through prompt construction and message ordering. The central claim requires that degradation stems from simulated social mechanisms rather than input artifacts; without controls that hold informational content fixed while removing social framing (e.g., neutral bullet lists vs. attributed peer arguments), or cross-model validation, the attribution to social dynamics remains unisolated.
Authors: We agree that isolating the contribution of social framing from raw informational content is important for strengthening causal attribution. Our current design uses prompt-based manipulations because these are the primary levers available for simulating social context in LLM agents. To address this directly, we will add new control conditions in the revised manuscript that hold the underlying factual content fixed while varying only the social framing (e.g., presenting identical information as neutral bullet lists without attribution, ordering, or persuasive cues versus the original socially attributed arguments). This will help demonstrate that performance degradation arises from the social presentation rather than content differences alone. We note that full cross-model validation across multiple distinct model families would require substantial additional compute and is beyond the scope of the current study; we will explicitly discuss this as a limitation and a direction for future work. revision: partial
-
Referee: [Results] Results section (e.g., accuracy plots and tables): Declines are reported as 'significant' and 'consistent,' but the manuscript lacks details on statistical tests, error bars, number of trials, model versions, or dataset used. This makes it impossible to evaluate whether the effect sizes support the load-bearing claim of systematic social influence over random variation or prompt sensitivity.
Authors: We apologize for the insufficient reporting details in the original submission. In the revised manuscript, we will expand the Results section and Methods to include: the exact number of trials per condition (100 independent runs per experimental setting to mitigate stochasticity), the statistical tests performed (two-tailed paired t-tests with Bonferroni correction, including exact p-values and Cohen's d effect sizes), error bars on all plots (standard error of the mean), the precise model version and API parameters used (GPT-4-turbo-2024-04-09 with temperature 0.0 for determinism), and the full dataset description (a set of 50 factual reasoning questions drawn from science, history, and logic domains, with sources cited). These additions will enable readers to evaluate the reliability of the observed effects relative to random variation and prompt sensitivity. revision: yes
Circularity Check
No circularity: purely empirical experimental study with direct observations
full rationale
The paper defines four social phenomena from psychology literature and tests their effects via prompt-based manipulations of adversary count, model capability, argument length, and style. Results are reported as measured accuracy changes under these controlled variations, with no equations, fitted parameters, derivations, or self-citations invoked as load-bearing premises. All claims reduce to observable experimental outcomes rather than any self-referential construction or renaming of inputs as predictions. The design is self-contained against external benchmarks of prompt sensitivity and does not rely on prior author work to justify uniqueness or ansatzes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Travelagent: An ai assistant for personalized travel planning.arXiv preprint arXiv:2409.08069, 2024
Chateval: Towards better LLM-based eval- uators through multi-agent debate. InThe Twelfth International Conference on Learning Representa- tions. Aili Chen, Xuyang Ge, Ziquan Fu, Yanghua Xiao, and Jiangjie Chen. 2024. Travelagent: An ai assistant for personalized travel planning.arXiv preprint arXiv:2409.08069. ChangSu Choi, Hoyun Song, Dongyeon Kim, WooH...
-
[2]
Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Jiaxi Cui, Munan Ning, Zongjian Li, Bohua Chen, Yang Yan, Hao Li, Bin Ling, Yonghong Tian, and Li Yuan
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2306.16092 , year=
Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture- of-experts large language model.arXiv preprint arXiv:2306.16092. Tomas de la Rosa, Sriram Gopalakrishnan, Alberto Pozanco, Zhen Zeng, and Daniel Borrajo. 2024. Trip- pal: Travel planning with guarantees by combin- ing large language models and automated planners. a...
-
[4]
Memory injection attacks on LLM agents via query-only interaction. InThe Thirty-ninth Annual Conference on Neural Information Processing Sys- tems. Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenen- baum, and Igor Mordatch. 2023. Improving factual- ity and reasoning in language models through multia- gent debate. InForty-first International Conference...
-
[5]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[6]
Metagpt: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations. Carl I Hovland and Walter Weiss. 1951. The influence of source credibility on communication effectiveness. Public opinion quarterly, 15(4):635–650. Jen-tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wa...
-
[7]
Openai o1 system card.arXiv preprint arXiv:2412.16720. Soyeong Jeong, Aparna Elangovan, Emine Yilmaz, and Oleg Rokhlenko. 2025. Adaptive multi-agent re- sponse refinement in conversational systems.arXiv preprint arXiv:2511.08319. Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, and Bela Gipp. 2025. V oting or consensus? decision-making ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2506.14728 , year=
Agentmaster: A multi-agent conversational framework using a2a and mcp protocols for multi- modal information retrieval and analysis. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstra- tions, pages 52–72. Xiaoliang Luo, Akilles Rechardt, Guangzhi Sun, Kevin K Nejad, Felipe Yáñez, Bati Yilmaz, Kangj...
-
[9]
InThe Thir- teenth International Conference on Learning Repre- sentations
Moral alignment for LLM agents. InThe Thir- teenth International Conference on Learning Repre- sentations. Lei Wang, Zheqing Zhang, and Xu Chen. 2025a. In- vestigating and extending homans’ social exchange theory with large language model based agents. In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: ...
2025
-
[10]
Emergent Abilities of Large Language Models
Emergent abilities of large language models. arXiv preprint arXiv:2206.07682. Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Shiyang Lai, Kai Shu, Jindong Gu, Adel Bibi, Ziniu Hu, David Jurgens, James Evans, Philip H.S. Torr, Bernard Ghanem, and Guohao Li. 2024. Can large language model agents simulate human trust behav- ior? InProceedings of the 38th In...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.