Recognition: no theorem link
AgentCE-Bench: Agent Configurable Evaluation with Scalable Horizons and Controllable Difficulty under Lightweight Environments
Pith reviewed 2026-05-10 19:02 UTC · model grok-4.3
The pith
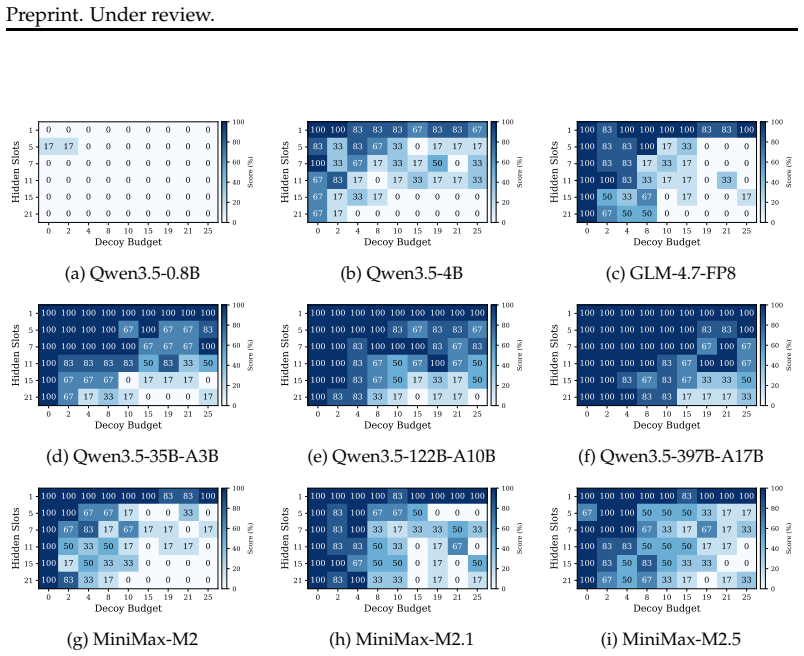
A grid planning benchmark lets researchers independently tune agent task length via hidden slots and difficulty via decoy counts while using static files to avoid live environment costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentCE-Bench introduces a unified grid-based planning task in which agents must complete a schedule by filling hidden slots subject to local slot constraints and global constraints. Horizon scales directly with the number of hidden slots H while difficulty scales with the decoy budget B that sets the number of globally misleading candidates. All tool calls are answered from static JSON files rather than live environments, removing interaction overhead and enabling fast reproducible evaluation. Validation experiments confirm that H and B produce reliable, monotonic changes in performance, that the benchmark maintains domain consistency, and that it discriminates among models of different fam
What carries the argument
The grid-based planning task with orthogonal controls H for scalable horizons and B for controllable difficulty, resolved through static JSON files in a lightweight environment that eliminates live interactions.
If this is right
- Varying H produces reliable, monotonic increases in task horizon.
- Varying B independently increases difficulty through added global decoys.
- The lightweight static design reduces evaluation time compared with live environment interactions.
- The benchmark exhibits domain consistency and model discriminability across tested families.
- It supports fast, reproducible runs suitable for training-time validation loops.
Where Pith is reading between the lines
- Independent controls on length and distractor count could let developers trace whether a model fails mainly on sequence length or on filtering misleading information.
- Static JSON resolution may make it practical to run thousands of evaluations during agent training without the cost of full simulators.
- The same two-axis control pattern could be adapted to other agent domains such as code editing or web navigation to create comparable tunable tests.
Load-bearing premise
That success on this grid-planning task with static JSON resolutions captures the essential reasoning challenges agents face in live, open-ended environments.
What would settle it
If increasing H or B produces no consistent drop in success rate across models, or if scores on AgentCE-Bench fail to predict performance on established live-environment agent benchmarks.
Figures








read the original abstract
Existing Agent benchmarks suffer from two critical limitations: high environment interaction overhead (up to 41\% of total evaluation time) and imbalanced task horizon and difficulty distributions that make aggregate scores unreliable. To address these issues, we propose AgentCE-Bench built around a unified grid-based planning task, where agents must fill hidden slots in a partially completed schedule subject to both local slot constraints and global constraints. Our benchmark offers fine-grained control through two orthogonal axes: \textbf{Scalable Horizons}, controlled by the number of hidden slots $H$, and \textbf{Controllable Difficulty}, governed by a decoy budget $B$ that determines the number of globally misleading decoy candidates. Crucially, all tool calls are resolved via static JSON files under a \textbf{Lightweight Environment} design, eliminating setup overhead and enabling fast, reproducible evaluation suitable for training-time validation. We first validate that $H$ and $B$ provide reliable control over task horizon and difficulty, and that AgentCE-Bench exhibits strong domain consistency and model discriminability. We then conduct comprehensive experiments across 13 models of diverse sizes and families over 6 domains, revealing significant cross-model performance variation and confirming that AgentCE-Bench provides interpretable and controllable evaluation of agent reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AgentCE-Bench, a benchmark for agent reasoning built on a unified grid-based planning task where agents fill hidden slots subject to local and global constraints. It introduces two orthogonal control axes—Scalable Horizons via the number of hidden slots H and Controllable Difficulty via decoy budget B—implemented through static JSON file resolution of tool calls in a lightweight environment to reduce overhead and enable reproducibility. The authors claim that H and B reliably control horizon and difficulty, that the benchmark shows domain consistency and model discriminability, and that experiments across 13 models in 6 domains reveal significant performance variation, providing interpretable evaluation of agent reasoning.
Significance. If the static lightweight design and control axes are shown to validly capture core agent reasoning challenges, the benchmark would address key limitations of existing agent evaluations (high interaction overhead and imbalanced distributions) by enabling fast, reproducible, fine-grained testing suitable for training-time use. The cross-model experiments and orthogonal controls are strengths that could improve interpretability of agent capabilities.
major comments (2)
- [Abstract] Abstract: The claim that 'H and B provide reliable control over task horizon and difficulty, and that AgentCE-Bench exhibits strong domain consistency and model discriminability' is asserted without any specific validation methods, statistical tests, quantitative results, or data details. This is load-bearing for the central claim of interpretable and controllable evaluation.
- [Lightweight Environment design] Lightweight Environment design (described in the abstract and task setup): All tool calls are resolved via static JSON files, eliminating live state changes, error recovery, and adaptive responses. This design choice creates a correctness risk for the claim that the benchmark evaluates general agent reasoning, as performance patterns may not transfer to dynamic environments. A concrete test would be to compare relative model rankings on the static grid task versus an equivalent dynamic implementation.
minor comments (1)
- The introduction of H (number of hidden slots) and B (decoy budget) is clear but would benefit from an explicit diagram or table showing how they map to grid configurations and constraint satisfaction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, with clear indications of planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'H and B provide reliable control over task horizon and difficulty, and that AgentCE-Bench exhibits strong domain consistency and model discriminability' is asserted without any specific validation methods, statistical tests, quantitative results, or data details. This is load-bearing for the central claim of interpretable and controllable evaluation.
Authors: We agree that the abstract, constrained by length, summarizes the validation claims without detailing the methods or results. The full manuscript presents these validations in the Experiments section, including quantitative analyses of horizon scaling with H, difficulty modulation via B, domain consistency metrics, and model discriminability through performance variance across the 13 models. We will revise the abstract to briefly reference the validation approach and key quantitative outcomes to better support the central claims. revision: yes
-
Referee: [Lightweight Environment design] Lightweight Environment design (described in the abstract and task setup): All tool calls are resolved via static JSON files, eliminating live state changes, error recovery, and adaptive responses. This design choice creates a correctness risk for the claim that the benchmark evaluates general agent reasoning, as performance patterns may not transfer to dynamic environments. A concrete test would be to compare relative model rankings on the static grid task versus an equivalent dynamic implementation.
Authors: The static JSON resolution is a core design decision to achieve the benchmark's primary goals of low overhead and high reproducibility, directly addressing the 41% interaction time issue in prior agent evaluations. The planning and constraint-satisfaction reasoning tasks are preserved through the hidden slots H and decoy budget B, even without live dynamics. We acknowledge that this may limit direct transfer to environments requiring error recovery and will add an expanded limitations discussion on this point. We do not plan to implement the suggested dynamic comparison, as it would reintroduce the overhead the benchmark seeks to avoid. revision: partial
Circularity Check
No circularity in benchmark proposal or empirical validation
full rationale
The paper is a benchmark design and empirical study proposing AgentCE-Bench with orthogonal controls H (hidden slots for horizons) and B (decoy budget for difficulty) in a static JSON-resolved grid planning task. Validation consists of running 13 models across domains to confirm H/B effects on performance, domain consistency, and discriminability. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the provided text; the design claims and experimental outcomes are independent empirical observations rather than reductions to inputs by construction. The work is self-contained as a practical benchmark contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A unified grid-based planning task with local and global constraints can represent core challenges in agent reasoning across domains
Forward citations
Cited by 1 Pith paper
-
AuditRepairBench: A Paired-Execution Trace Corpus for Evaluator-Channel Ranking Instability in Agent Repair
AuditRepairBench supplies a large trace corpus and four screening methods that reduce evaluator-channel ranking instability in agent repair leaderboards by a mean of 62%.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2410.06992 , year=
Reem Aleithan, Haoran Xue, Mohammad Mahdi Mohajer, Elijah Nnorom, Gias Uddin, and Song Wang. Swe-bench+: Enhanced coding benchmark for llms.arXiv preprint arXiv:2410.06992,
-
[3]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
URL https://matharena.ai/. Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ2- bench: Evaluating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982,
work page internal anchor Pith review arXiv
-
[4]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585,
work page internal anchor Pith review arXiv
-
[5]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941,
work page internal anchor Pith review arXiv
-
[6]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, L ´eo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks? arXiv preprint arXiv:2403.07718,
work page internal anchor Pith review arXiv
-
[7]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
work page internal anchor Pith review arXiv
-
[8]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2407.10362 (2024)
Jon M Laurent, Joseph D Janizek, Michael Ruzo, Michaela M Hinks, Michael J Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D White, and Samuel G Rodriques. Lab-bench: Measuring capabilities of language models for biology research.arXiv preprint arXiv:2407.10362,
-
[10]
arXiv preprint arXiv:2501.11067 , year=
Elad Levi and Ilan Kadar. Intellagent: A multi-agent framework for evaluating conversa- tional ai systems.arXiv preprint arXiv:2501.11067,
-
[11]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
work page internal anchor Pith review arXiv
-
[12]
Mlgym: A new framework and benchmark for advancing ai research agents,
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens, Amar Budhiraja, Despoina Magka, Vladislav Vorotilov, Gaurav Chaurasia, et al. Mlgym: A new framework and benchmark for advancing ai research agents.arXiv preprint arXiv:2502.14499,
-
[13]
Does SWE-Bench-Verified test agent ability or model memory?arXiv preprint arXiv:2512.10218,
Thanosan Prathifkumar, Noble Saji Mathews, and Meiyappan Nagappan. Does swe-bench- verified test agent ability or model memory?arXiv preprint arXiv:2512.10218,
-
[14]
URL https: //qwen.ai/blog?id=qwen3.5. Johannes Schneider. Generative to agentic ai: Survey, conceptualization, and challenges. arXiv preprint arXiv:2504.18875,
-
[15]
MiroMind Team, Song Bai, Lidong Bing, Carson Chen, Guanzheng Chen, Yuntao Chen, Zhe Chen, Ziyi Chen, Xuan Dong, et al. Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling.arXiv preprint arXiv:2511.11793,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Science- world: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp
Ruoyao Wang, Peter Jansen, Marc-Alexandre Cˆot´e, and Prithviraj Ammanabrolu. Science- world: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11279–11298,
2022
-
[17]
100-longbench: Are de facto long-context benchmarks literally evaluating long-context ability? InFindings of the Association for Computational Linguistics: ACL 2025, pp
Van Yang, Hongye Jin, Shaochen Zhong, Song Jiang, Qifan Wang, Vipin Chaudhary, and Xiaotian Han. 100-longbench: Are de facto long-context benchmarks literally evaluating long-context ability? InFindings of the Association for Computational Linguistics: ACL 2025, pp. 17560–17576,
2025
-
[18]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
work page internal anchor Pith review arXiv
-
[19]
Survey on Evaluation of LLM-based Agents
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. Survey on evaluation of llm-based agents.arXiv preprint arXiv:2503.16416,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Helmet: How to evaluate long-context language models effectively and thoroughly, 2025
11 Preprint. Under review. Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. Helmet: How to evaluate long-context language models effectively and thoroughly.arXiv preprint arXiv:2410.02694,
-
[21]
Sequential-niah: A needle-in-a-haystack benchmark for extracting sequential needles from long contexts
Yifei Yu, Qian-Wen Zhang, Lingfeng Qiao, Di Yin, Fang Li, Jie Wang, Chen Zeng Xi, Sun- cong Zheng, Xiaolong Liang, and Xing Sun. Sequential-niah: A needle-in-a-haystack benchmark for extracting sequential needles from long contexts. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 29438–29456,
2025
-
[22]
Lv-eval: A balanced long-context benchmark with 5 length levels up to 256k
Tao Yuan, Xuefei Ning, Dong Zhou, Zhijie Yang, Shiyao Li, Minghui Zhuang, Zheyue Tan, Zhuyu Yao, Dahua Lin, Boxun Li, et al. Lv-eval: A balanced long-context benchmark with 5 length levels up to 256k.arXiv preprint arXiv:2402.05136,
-
[23]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chengxing Xie, Cunxiang Wang, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review arXiv
-
[24]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey.arXiv preprint arXiv:2509.02547,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
∞ bench: Extending long context evaluation beyond 100k tokens
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Khai Hao, Xu Han, Zhen Leng Thai, Shuo Wang, Zhiyuan Liu, et al. ∞-bench: Extending long context evaluation beyond 100k tokens.arXiv preprint arXiv:2402.13718,
-
[26]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.