Recognition: no theorem link
Benchmarking LLM Tool-Use in the Wild
Pith reviewed 2026-05-15 22:48 UTC · model grok-4.3
The pith
Evaluations of 57 LLMs reveal no model exceeds 15% accuracy on a benchmark of real user tool-use behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
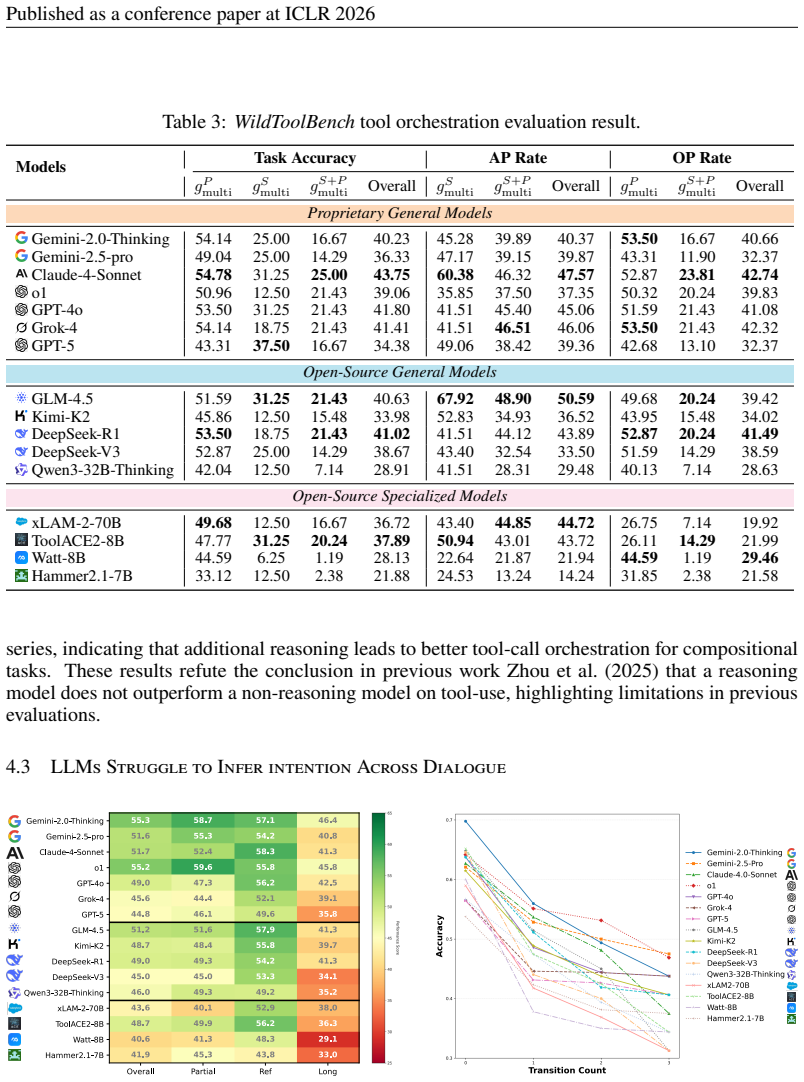
WildToolBench captures the wild nature of user interactions with LLMs for tool use by incorporating compositional orchestration, implicit intent spread, and instruction transition. Evaluations show that this leads to no model achieving more than 15% accuracy, revealing a substantial gap in agentic robustness that existing benchmarks miss.
What carries the argument
WildToolBench, the benchmark grounded in real-world user behavior patterns for testing LLM tool-use robustness.
If this is right
- Existing benchmarks overestimate LLM tool-use performance due to lack of wild elements.
- LLM agent development should focus on managing dialogue dynamics and implicit information.
- The robustness gap suggests rethinking how LLMs, users, and tools interact in practice.
Where Pith is reading between the lines
- Training LLMs on more diverse, real-user dialogue data could help close the performance gap.
- Deployed systems may need built-in mechanisms to handle instruction shifts and clarification requests.
Load-bearing premise
The constructed WildToolBench tasks faithfully capture the three identified real-world user behavior challenges without selection bias or artificial simplification.
What would settle it
A replication where a new LLM scores above 20% on WildToolBench while controlled experiments confirm the challenges are present would indicate the gap is not as large or the benchmark overstates the difficulty.
Figures














read the original abstract
Fulfilling user needs through Large Language Model multi-turn, multi-step tool-use is rarely a straightforward process. Real user interactions are inherently wild, being intricate, messy, and flexible. We identify three key challenges from user behaviour: compositional tasks that demand efficient orchestration of tool-call topologies, implicit intent spread across dialogue turns that require contextual inference, and instruction transition, which mixes task queries, clarifications, and casual conversation, forcing LLMs to adjust their policies on the fly. Existing benchmarks overlook these behaviors, making the apparent progress of LLMs on tool-use spurious. To address this, we introduce WildToolBench, an LLM tool-use benchmark grounded in real-world user behavior patterns. Comprehensive evaluations of 57 LLMs reveal that no model achieves an accuracy of more than 15%, indicating a substantial gap in the robustness of LLMs' agentic ability. Controlled experiments and in-depth analyses further indicate that the real challenge for LLM tool-use lies not in artificially complex tasks, but in the wild nature of user behavior, emphasizing the need to reconsider the interactions among LLMs, users, and tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies three challenges in real-world LLM tool-use (compositional orchestration of tool-call topologies, implicit intent spread across turns, and instruction transitions mixing queries with clarifications/casual talk) that existing benchmarks overlook. It introduces WildToolBench as a benchmark grounded in these user behavior patterns and reports comprehensive evaluations of 57 LLMs in which no model exceeds 15% accuracy, concluding that the gap reflects limitations in handling wild user behaviors rather than artificial task complexity.
Significance. If the benchmark construction and evaluation protocol are shown to be free of selection bias and faithfully capture the three wild behaviors, the result would be significant: it would demonstrate that apparent progress on tool-use benchmarks is spurious and redirect research toward models robust to messy, flexible, multi-turn user interactions. The scale of the evaluation (57 models) is a strength that supports broad claims about current LLM limitations.
major comments (2)
- [Abstract and §3] Abstract and §3 (Benchmark Construction): The headline claim that no model exceeds 15% accuracy indicates a general robustness gap in agentic ability only if WildToolBench tasks are an unbiased sample of the three identified behaviors. The manuscript must supply explicit details on data sources (e.g., real user logs), task curation process, and validation steps (distribution matching to user logs or human realism ratings) to rule out over-sampling of hard compositional cases or fabricated transitions; without this, low scores could be an artifact of benchmark design rather than a general failure.
- [§4] §4 (Evaluation Protocol): The reported accuracies depend on the precise definition of success for multi-turn, multi-step tool-use (e.g., exact match on tool calls and arguments, partial credit, or end-to-end task completion). The manuscript must specify the metric, how implicit intents are judged, and the handling of instruction transitions to allow verification that the <15% ceiling is not an artifact of overly strict or inconsistent scoring.
minor comments (1)
- [Figures/Tables] Clarify notation for tool-call topologies and intent-spread metrics in figures and tables to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments on our manuscript. We have revised the paper to address the concerns raised regarding benchmark construction and evaluation protocol, and we provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Construction): The headline claim that no model exceeds 15% accuracy indicates a general robustness gap in agentic ability only if WildToolBench tasks are an unbiased sample of the three identified behaviors. The manuscript must supply explicit details on data sources (e.g., real user logs), task curation process, and validation steps (distribution matching to user logs or human realism ratings) to rule out over-sampling of hard compositional cases or fabricated transitions; without this, low scores could be an artifact of benchmark design rather than a general failure.
Authors: We agree that transparency in benchmark construction is critical to substantiate our claims about LLM limitations in wild settings. The revised manuscript now includes an expanded §3 with explicit details on the data sources, which are derived from publicly available user interaction logs and synthesized scenarios reflecting observed real-world patterns. We describe the task curation process, including how we ensured balanced coverage of compositional orchestration, implicit intents, and instruction transitions, and the validation steps involving human annotators rating realism and matching distributions to user behavior statistics. These additions confirm that the low accuracies reflect genuine challenges rather than benchmark artifacts. revision: yes
-
Referee: [§4] §4 (Evaluation Protocol): The reported accuracies depend on the precise definition of success for multi-turn, multi-step tool-use (e.g., exact match on tool calls and arguments, partial credit, or end-to-end task completion). The manuscript must specify the metric, how implicit intents are judged, and the handling of instruction transitions to allow verification that the <15% ceiling is not an artifact of overly strict or inconsistent scoring.
Authors: We concur that a clear specification of the evaluation metric is essential for reproducibility and to validate the reported results. In the revised §4, we have added a precise definition of the success metric, which is based on exact matching of the tool call sequence and arguments, with additional consideration for end-to-end task completion where implicit intents are inferred from the full dialogue context. We provide detailed guidelines on judging implicit intents through contextual inference and how instruction transitions are handled by evaluating policy adjustments across turns. Examples and a formal scoring procedure are now included to demonstrate consistency and that the performance ceiling is not due to strict scoring. revision: yes
Circularity Check
No circularity: fresh benchmark evaluations yield empirical results independent of inputs
full rationale
The paper constructs WildToolBench from identified user behavior patterns and reports direct accuracy measurements across 57 LLMs. No equations, fitted parameters, or self-citations are invoked to derive the <15% ceiling; the headline result is an observation from new test runs rather than a quantity that reduces to the benchmark definition or prior author work by construction. The derivation chain consists of task curation followed by model inference, with no load-bearing step that renames a fit as a prediction or imports uniqueness via self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real user tool-use interactions are dominated by compositional tasks, implicit intent spread across turns, and instruction transitions mixing queries with casual conversation.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics, 2024. doi: 10.18653/V1/2024.ACL-LONG.515. URLhttps://doi.org/10.18653/v1/2024.acl-long.515. Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An Open-source Chatbot Impressing GPT-4 with 9...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.515 2024
-
[2]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
doi: 10.48550/ARXIV.2306.05301. URL https://doi.org/10.48550/arXiv. 2306.05301. 13 Published as a conference paper at ICLR 2026 An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai D...
work page internal anchor Pith review doi:10.48550/arxiv.2306.05301 2026
-
[3]
Multi-Agent Simulation Human Check and Refine 1600+ Tools 256 scenarios LLMGenerate Real User LogsIdentify Seed Scenarios and User Behaviour PatternsRaw Scenario User AgentAssistant Agent Raw Trajectory WildToolBench
-
[4]
What is the weather like in Beijing today?
Task Curation Human & LLMCollaborate 1024 Tasks Figure 8: The data curation pipeline of WildToolBench. A The Use of Large Language Models (LLMs) For the paper writing, we employed LLMs solely for grammatical correction at the writing stage. The LLM itself did not contribute to experimental design, idea development, or manuscript writing. Other uses of LLM...
-
[5]
For other optional parameters, please add them as you see fit, using natural language
The description of the user’s task must include information on all the required parameters needed to call{{{tool}}}. For other optional parameters, please add them as you see fit, using natural language
-
[8]
Ensure that the length of the user’s tasks varies, gradually increasing from short to long
-
[10]
Extract common entities that appear in all descriptions from the [Tool List] and ensure that these entities appear in the user’s tasks
-
[11]
Do not explicitly specify the tool{{{tool}}}in the user’s tasks. """ [Tool List]=""" {{{tool}}} """ [Format]=""" { "task 1": "xxx", "task 2": "xxx", "task 3": "xxx", "task 4": "xxx", "task 5": "xxx", } """ Figure 9: Single-Tool Calls task Generation Prompt. 22 Published as a conference paper at ICLR 2026 Sequential Multi-Tool Calls task Generation Prompt....
work page 2026
-
[18]
There must be dependencies between the multiple tools invoked, meaning that tool A must be called and completed before tool B can be run, i.e., tool B must be invoked after tool A
-
[20]
Do not explicitly specify the names of the tools to be used in the user’s tasks. """ [Tool List]=""" {{{tools}}} """ [Format]=""" { "task 1": "xxx", "task 2": "xxx", "task 3": "xxx", "task 4": "xxx", "task 5": "xxx", } """ Figure 10: Sequential Multi-Tool Calls task Generation Prompt. 23 Published as a conference paper at ICLR 2026 Parallel Multi-Tool Cal...
work page 2026
-
[27]
A dependency between invocations means that tool B can only be run after tool A is completed
There must be no dependency between the multiple tools invoked. A dependency between invocations means that tool B can only be run after tool A is completed. No dependency means that tool A and tool B can be invoked in parallel
-
[29]
Do not explicitly specify the names of the tools to be used in the user’s tasks. """ [Tool List]=""" {{{tools}}} """ [Format]=""" { "task 1": "xxx", "task 2": "xxx", "task 3": "xxx", "task 4": "xxx", "task 5": "xxx", } """ Figure 11: Parallel Multi-Tool Calls task Generation Prompt. 24 Published as a conference paper at ICLR 2026 Mixed Multi-Tool Calls ta...
work page 2026
-
[30]
Thedescriptionoftheuser’staskmustincludealltherequiredparametersneededtoinvoke the tools, while other optional parameters can be added as you see fit, using natural language
-
[31]
The user’s tasks should use different types of sentence structures: imperative, declarative, interrogative, etc
-
[36]
A dependency between invocations means that tool B can only be run after tool A is completed
There should be dependencies between some of the tools invoked, while others should not have dependencies. A dependency between invocations means that tool B can only be run after tool A is completed. No dependency means that tool A and tool B can be invoked in parallel
-
[37]
Easy represents simple, medium represents moderate, and hard represents difficult
The difficulty of the tasks is divided into easy, medium, and hard levels. Easy represents simple, medium represents moderate, and hard represents difficult. Ensure that the 5 tasks you generate are all of medium difficulty or above
-
[38]
Do not explicitly specify the names of the tools to be used in the user’s tasks. """ [Tool List]=""" {{{tools}}} """ [Format]=""" { "task 1": "xxx", "task 2": "xxx", "task 3": "xxx", "task 4": "xxx", "task 5": "xxx", } """ Figure 12: Mixed Multi-Tool Calls task Generation Prompt. 25 Published as a conference paper at ICLR 2026 Clarify task Generation Prom...
work page 2026
-
[39]
The description of the user’s task must lack all the necessary information for calling {{{tool}}}, leaving only the optional parameter information, which you can add as you see fit, using natural language descriptions. Note that tool parameters allow for some parameter inference, meaning that if the tool parameters can be inferred from the user’s task des...
-
[40]
The user’s tasks need to use different types of sentence structures: imperative sentences, declarative sentences, interrogative sentences, etc
-
[41]
The user’s tasks should include different tones: colloquial, formal, polite, direct, etc
-
[42]
Ensure that the length of the user’s tasks varies, from short to long, gradually increasing in length
-
[43]
Ensure that the user’s tasks involve different themes/instances, different scenarios, and different roles
-
[44]
Based on the descriptions of all tools in the [Tool List], extract the common entities that appear in all descriptions and ensure that these entities appear in the user’s tasks
-
[45]
Easy represents simple, medium represents moderate, and hard represents difficult
Task difficulty is divided into easy, medium, and hard levels. Easy represents simple, medium represents moderate, and hard represents difficult. More difficult tasks require more steps to execute. Ensure that the 3 tasks you generate are all of medium difficulty or above
-
[46]
Do not explicitly specify the tool {{{tool}}} in the user’s tasks. """ [Tool List]=""" {{{tools}}} """ [Format]=""" { "task 1": "xxx", "task 2": "xxx", "task 3": "xxx", "task 4": "xxx", "task 5": "xxx", } """ Figure 13: Clarify task Generation Prompt. 26 Published as a conference paper at ICLR 2026 Chat task Generation Prompt. Please act as a user interac...
work page 2026
-
[47]
The user task is a casual conversation task, which must be unrelated to the functions of the [Tool List], but should have some thematic relevance
-
[48]
User tasks need to use different types of sentence structures: imperative, declarative, interrogative, etc
-
[49]
User tasks should include different tones: colloquial, formal, polite, direct, etc
-
[50]
Ensure that the lengths of the user tasks are different, ranging from short to long, with gradually increasing length
-
[51]
Ensure that the user tasks involve different themes/examples, different scenarios, and different role identities. """ [Tool List]=""" {{{tools}}} """ [Format]=""" { "task 1": "xxx", "task 2": "xxx", "task 3": "xxx", "task 4": "xxx", "task 5": "xxx", } """ Figure 14: Chat task Generation Prompt. 27 Published as a conference paper at ICLR 2026 Context task ...
work page 2026
-
[52]
Partial Information: The new task generated needs to omit some content from previous conversations, without having to state the full semantics. The omitted content can be any sentence component, including: subject, attribute, attribute value, modifier, etc
-
[53]
2) Pronominal reference, such as: he, this sentence, which one, etc
Coreferential Reference: The new task generated requires reference to some content from previous conversations, which can be: 1) Ordinal reference, such as: the second point, the last point, etc. 2) Pronominal reference, such as: he, this sentence, which one, etc. 3) Vague reference, such as: xxx this model, etc
-
[54]
Long-Range dependency: The new task generated needs to use content from previous conversations (excluding the last round), for example, something I mentioned in the first round, something I mentioned before. """ [Example]=""" [Historical Conversations]=*** {{{history}}} *** [Output]=*** {{{continue_task}}} *** """ [Historical Conversations]=""" {{{history...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.