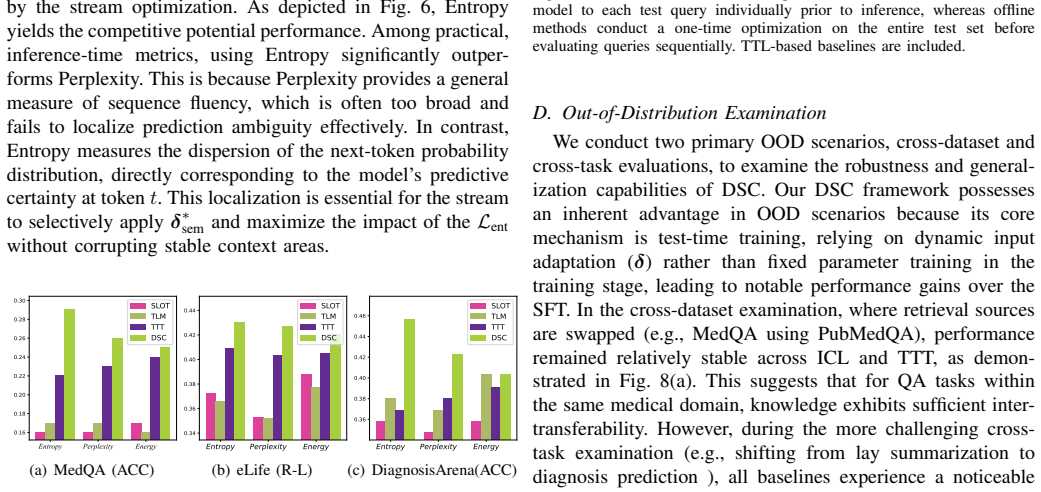
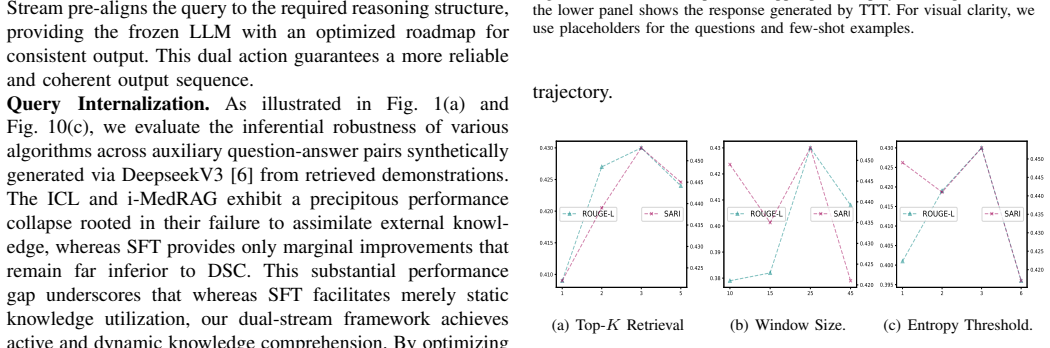
Recognition: no theorem link
From Exposure to Internalization: Dual-Stream Calibration for In-context Clinical Reasoning
Pith reviewed 2026-05-10 19:15 UTC · model grok-4.3
The pith
Dual-Stream Calibration lets models internalize clinical inferential dependencies during test-time inference rather than merely exposing them to context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Dual-Stream Calibration (DSC) is a test-time training framework that achieves input internalization by synergistically aligning a Semantic Calibration Stream, which enforces deliberative reflection on core evidence through entropy minimization to stabilize generative trajectories, with a Structural Calibration Stream, which assimilates latent inferential dependencies through iterative meta-learning on specialized support sets, thereby shifting the reasoning paradigm from passive attention-based matching to active refinement of the latent inferential space and yielding superior results on clinical tasks.
What carries the argument
Dual-Stream Calibration consisting of a semantic entropy-minimization stream for internalizing semantic anchors and a structural meta-learning stream for bridging external evidence to internal logic at test time.
If this is right
- DSC outperforms both training-dependent models and existing test-time learning frameworks across three task paradigms on thirteen clinical datasets.
- Models dynamically adjust internal representations to subtle patient-specific nuances instead of relying on passive context matching.
- Fragmented clinical data is synthesized into coherent responses through active refinement of the latent inferential space.
- The approach reduces dependence on large-scale pre-training or fine-tuning for contextual clinical adaptation.
Where Pith is reading between the lines
- Similar dual-stream calibration could be tested in other domains that require integrating heterogeneous evidence, such as legal document analysis.
- Future evaluations might track changes in model activations before and after the streams to directly measure internalization effects.
- The framework might combine with retrieval methods to supply richer support sets for the structural stream.
- Deployment costs could decrease if test-time adaptation replaces repeated domain-specific retraining cycles.
Load-bearing premise
The semantic entropy-minimization and structural meta-learning streams produce genuine internalization of inferential dependencies rather than metric improvements from additional test-time computation alone.
What would settle it
An experiment that replaces the two calibration streams with equivalent extra test-time computation using non-specific or random objectives and still obtains the same accuracy gains on the clinical datasets would falsify the internalization claim.
Figures










read the original abstract
Contextual clinical reasoning demands robust inference grounded in complex, heterogeneous clinical records. While state-of-the-art fine-tuning, in-context learning (ICL), and retrieval-augmented generation (RAG) enable knowledge exposure, they often fall short of genuine contextual internalization: dynamically adjusting a model's internal representations to the subtle nuances of individual cases at inference time. To address this, we propose Dual-Stream Calibration (DSC), a test-time training framework that transcends superficial knowledge exposure to achieve deep internalization during inference. DSC facilitates input internalization by synergistically aligning two calibration streams. Unlike passive context exposure, the Semantic Calibration Stream enforces a deliberative reflection on core evidence, internalizing semantic anchors by minimizing entropy to stabilize generative trajectories. Simultaneously, the Structural Calibration Stream assimilates latent inferential dependencies through an iterative meta-learning objective. By training on specialized support sets at test-time, this stream enables the model to bridge the gap between external evidence and internal logic, synthesizing fragmented data into a coherent response. Our approach shifts the reasoning paradigm from passive attention-based matching to an active refinement of the latent inferential space. Validated against thirteen clinical datasets, DSC demonstrates superiority across three distinct task paradigms, consistently outstripping state-of-the-art baselines ranging from training-dependent models to test-time learning frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dual-Stream Calibration (DSC), a test-time training framework for in-context clinical reasoning consisting of a Semantic Calibration Stream (entropy minimization on evidence to internalize semantic anchors) and a Structural Calibration Stream (iterative meta-learning on test-time support sets to assimilate latent inferential dependencies). It claims this shifts from passive attention-based matching to active refinement of the latent inferential space, achieving genuine internalization and outperforming training-dependent models and test-time learning frameworks on thirteen clinical datasets across three task paradigms.
Significance. If the empirical claims were substantiated, the work could contribute to test-time adaptation in clinical AI by formalizing a distinction between exposure and internalization. However, the manuscript supplies no quantitative results, ablations, implementation details, or statistical tests, so its potential significance cannot be assessed from the available text.
major comments (3)
- [Abstract] Abstract: The assertion that DSC 'demonstrates superiority' and 'consistently outstripping state-of-the-art baselines' on thirteen datasets is unsupported by any reported metrics, ablation details, statistical tests, or baseline comparisons, rendering the central claim unevaluable.
- The manuscript contains no equations, algorithmic pseudocode, or derivations for the entropy-minimization objective or the meta-learning procedure, so it is impossible to determine whether these streams produce internalization of inferential structure or simply allocate extra test-time compute.
- No controls are described that match total forward/backward passes against generic test-time adaptation baselines lacking the specific entropy or meta-learning components; without such isolation, the interpretation that performance gains reflect internalization rather than additional inference-time resources cannot be verified.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying key gaps in the presentation of our work. The comments correctly note that the current manuscript draft does not yet supply the quantitative results, formal derivations, or controlled experiments needed to fully substantiate the claims. We will undertake a major revision to address each point directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that DSC 'demonstrates superiority' and 'consistently outstripping state-of-the-art baselines' on thirteen datasets is unsupported by any reported metrics, ablation details, statistical tests, or baseline comparisons, rendering the central claim unevaluable.
Authors: We agree that the abstract currently states performance claims without accompanying numerical evidence or references to supporting material. In the revision we will replace the general assertions with concise quantitative summaries drawn from the full experimental results (including mean performance deltas, standard deviations, and statistical significance markers across the thirteen datasets) and will add a dedicated results section that presents all tables, ablation studies, and baseline comparisons. revision: yes
-
Referee: [—] The manuscript contains no equations, algorithmic pseudocode, or derivations for the entropy-minimization objective or the meta-learning procedure, so it is impossible to determine whether these streams produce internalization of inferential structure or simply allocate extra test-time compute.
Authors: The referee is correct that the present draft omits explicit mathematical formulations and pseudocode. We will add a formal Methods section containing (i) the entropy-minimization loss for the Semantic Calibration Stream with its derivation, (ii) the iterative meta-learning objective for the Structural Calibration Stream, and (iii) complete algorithmic pseudocode for the dual-stream procedure. These additions will allow readers to distinguish the proposed mechanisms from generic extra inference steps. revision: yes
-
Referee: [—] No controls are described that match total forward/backward passes against generic test-time adaptation baselines lacking the specific entropy or meta-learning components; without such isolation, the interpretation that performance gains reflect internalization rather than additional inference-time resources cannot be verified.
Authors: We acknowledge the absence of matched-compute controls. In the revised manuscript we will include new experiments that equate the total number of forward and backward passes between DSC and generic test-time adaptation baselines (e.g., standard entropy minimization or vanilla meta-learning without the dual-stream design). These controls will be reported alongside the main results to isolate the contribution of the semantic and structural calibration components. revision: yes
Circularity Check
No significant circularity; empirical validation stands independent of definitional framing
full rationale
The paper introduces Dual-Stream Calibration as a test-time framework distinguishing 'exposure' from 'internalization' via two streams (semantic entropy minimization and structural meta-learning). No equations, derivations, or first-principles predictions appear in the manuscript. Claims of superiority rest on empirical results across 13 datasets rather than any reduction of outputs to fitted inputs or self-citations. The conceptual distinction is definitional but does not create a load-bearing circular chain, as performance deltas are externally falsifiable via compute-matched controls. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Medical large language model for diagnostic reasoning across specialties,
G. Wang and X. Liu, “Medical large language model for diagnostic reasoning across specialties,” pp. 743–744, 2025
2025
-
[2]
Toward expert- level medical question answering with large language models,
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, M. Amin, L. Hou, K. Clark, S. R. Pfohl, H. Cole-Lewiset al., “Toward expert- level medical question answering with large language models,”Nature Medicine, vol. 31, no. 3, pp. 943–950, 2025
2025
-
[3]
Diagnosisarena: benchmarking diagnostic reasoning for large language models
Y . Zhu, Z. Huang, L. Mu, Y . Huang, W. Nie, J. Liu, S. Zhang, P. Liu, and X. Zhang, “Diagnosisarena: Benchmarking diagnostic reasoning for large language models,”CoRR, vol. abs/2505.14107, 2025
-
[4]
Diffmv: A unified diffusion framework for healthcare predictions with random missing views and view laziness,
C. Zhao, H. Tang, H. Zhao, and X. Li, “Diffmv: A unified diffusion framework for healthcare predictions with random missing views and view laziness,” inSIGKDD. ACM, 2025, pp. 3933–3944
2025
-
[5]
A survey on large language models for recommendation,
L. Wu, Z. Zheng, Z. Qiu, H. Wang, H. Gu, T. Shen, C. Qin, C. Zhu, H. Zhu, Q. Liuet al., “A survey on large language models for recommendation,”World Wide Web, vol. 27, no. 5, p. 60, 2024
2024
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”CoRR, vol. abs/2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
A. Yang, B. Yanget al., “Qwen2.5 technical report,”CoRR, vol. abs/2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
L. Team, W. Xu, H. P. Chan, L. Li, M. Aljunied, R. Yuan, J. Wang, C. Xiao, G. Chen, C. Liu, Z. Li, Y . Sun, J. Shen, C. Wang, J. Tan, D. Zhao, T. Xu, H. Zhang, and Y . Rong, “Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning,”CoRR, vol. abs/2506.07044, 2025
-
[9]
Unveiling the secret recipe: A guide for supervised fine- tuning small llms,
A. Pareja, N. S. Nayak, H. Wang, K. Killamsetty, S. Sudalairaj, W. Zhao, S. Han, A. Bhandwaldar, G. Xu, K. Xu, L. Han, L. Inglis, and A. Srivastava, “Unveiling the secret recipe: A guide for supervised fine- tuning small llms,” inICLR. OpenReview.net, 2025
2025
-
[10]
How abilities in large language models are af- fected by supervised fine-tuning data composition,
G. Dong, H. Yuan, K. Lu, C. Li, M. Xue, D. Liu, W. Wang, Z. Yuan, C. Zhou, and J. Zhou, “How abilities in large language models are af- fected by supervised fine-tuning data composition,” inACL. Association for Computational Linguistics, 2024, pp. 177–198
2024
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”CoRR, vol. abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Y . Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, Y . Yue, S. Song, and G. Huang, “Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?”CoRR, vol. abs/2504.13837, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
Large language models for anomaly and out-of- distribution detection: A survey,
R. Xu and K. Ding, “Large language models for anomaly and out-of- distribution detection: A survey,” inNAACL, 2025, pp. 5992–6012
2025
-
[14]
Revisiting test-time scaling: A survey and a diversity-aware method for efficient reasoning,
H. Chung, T. Hsiao, H. Huang, C. Cho, J. Lin, Z. Ziwei, and Y . Chen, “Revisiting test-time scaling: A survey and a diversity-aware method for efficient reasoning,”CoRR, vol. abs/2506.04611, 2025
-
[15]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Z. Guo, L. Xia, Y . Yu, T. Ao, and C. Huang, “Lightrag: Simple and fast retrieval-augmented generation,”CoRR, vol. abs/2410.05779, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
A survey on in-context learning,
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, B. Chang, X. Sun, L. Li, and Z. Sui, “A survey on in-context learning,” inEMNLP. Association for Computational Linguistics, 2024, pp. 1107– 1128
2024
-
[18]
Large language models are in-context molecule learners,
J. Li, W. Liu, Z. Ding, W. Fan, Y . Li, and Q. Li, “Large language models are in-context molecule learners,”IEEE Trans. Knowl. Data Eng., vol. 37, no. 7, pp. 4131–4143, 2025
2025
-
[19]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inNeurIPS, 2022
2022
-
[20]
Mdagents: An adaptive collaboration of llms for medical decision-making,
Y . Kim, C. Park, H. Jeong, Y . S. Chan, X. Xu, D. McDuff, H. Lee, M. Ghassemi, C. Breazeal, and H. W. Park, “Mdagents: An adaptive collaboration of llms for medical decision-making,” inNeurIPS, 2024
2024
-
[21]
Medagents: Large language models as collaborators for zero-shot medical reasoning,
X. Tang, A. Zou, Z. Zhang, Z. Li, Y . Zhao, X. Zhang, A. Cohan, and M. Gerstein, “Medagents: Large language models as collaborators for zero-shot medical reasoning,” inACL. Association for Computational Linguistics, 2024, pp. 599–621
2024
-
[22]
The surprising effectiveness of test-time training for few-shot learning,
E. Aky ¨urek, M. Damani, A. Zweiger, L. Qiu, H. Guo, J. Pari, Y . Kim, and J. Andreas, “The surprising effectiveness of test-time training for few-shot learning,” inICML. OpenReview.net, 2025
2025
-
[23]
Slot: Sample-specific language model optimization at test-time,
Y . Hu, X. Zhang, X. Fang, Z. Chen, X. Wang, H. Zhang, and G. Qi, “SLOT: sample-specific language model optimization at test-time,” CoRR, vol. abs/2505.12392, 2025
-
[24]
Y . Zhu, Z. He, H. Hu, X. Zheng, X. Zhang, Z. Wang, J. Gao, L. Ma, and L. Yu, “Medagentboard: Benchmarking multi-agent collaboration with conventional methods for diverse medical tasks,”CoRR, vol. abs/2505.12371, 2025
-
[25]
Unveiling discrete clues: Superior healthcare predictions for rare diseases,
C. Zhao, H. Tang, J. Zhang, and X. Li, “Unveiling discrete clues: Superior healthcare predictions for rare diseases,” inWWW. ACM, 2025, pp. 1747–1758
2025
-
[26]
Knowledge- centered dual-process reasoning for math word problems with large language models,
J. Liu, Z. Huang, Q. Liu, Z. Ma, C. Zhai, and E. Chen, “Knowledge- centered dual-process reasoning for math word problems with large language models,”IEEE Trans. Knowl. Data Eng., vol. 37, no. 6, pp. 3457–3471, 2025
2025
-
[27]
Enhancing precision drug recommendations via in-depth exploration of motif relationships,
C. Zhao, H. Zhao, X. Zhou, and X. Li, “Enhancing precision drug recommendations via in-depth exploration of motif relationships,”IEEE Trans. Knowl. Data Eng., vol. 36, no. 12, pp. 8164–8178, 2024
2024
-
[28]
Beyond sequential patterns: Rethinking healthcare predictions with contextual insights,
C. Zhao, H. Tang, H. Zhao, and X. Li, “Beyond sequential patterns: Rethinking healthcare predictions with contextual insights,”ACM Trans. Inf. Syst., vol. 43, no. 4, pp. 107:1–107:32, 2025
2025
-
[29]
Magical: Medical lay language generation via semantic invariance and layperson- tailored adaptation,
W. Liao, T. Wang, Y . Zhu, Y . Wang, J. Gao, and L. Ma, “Magical: Medical lay language generation via semantic invariance and layperson- tailored adaptation,”NeurIPS, 2025
2025
-
[30]
End-to-end agentic RAG system training for traceable diagnostic reasoning,
Q. Zheng, Y . Sun, C. Wu, W. Zhao, P. Qiu, Y . Yu, K. Sun, Y . Wang, Y . Zhang, and W. Xie, “End-to-end agentic RAG system training for traceable diagnostic reasoning,”CoRR, vol. abs/2508.15746, 2025
-
[31]
Improving retrieval-augmented generation in medicine with iterative follow-up questions,
G. Xiong, Q. Jin, X. Wang, M. Zhang, Z. Lu, and A. Zhang, “Improving retrieval-augmented generation in medicine with iterative follow-up questions,”Pacific Symposium on Biocomputing (PSB), vol. 30, pp. 199– 214, 2025
2025
-
[32]
Collabo- rative document simplification using multi-agent systems,
D. Fang, J. Qiang, X. Ouyang, Y . Zhu, Y . Yuan, and Y . Li, “Collabo- rative document simplification using multi-agent systems,” inCOLING. Association for Computational Linguistics, 2025, pp. 897–912. XXXXXXXXXX 14
2025
-
[33]
J. Wu, F. Tang, Y . Li, M. Hu, H. Xue, S. Jameel, Y . Xie, and I. Raz- zak, “TAGS: A test-time generalist-specialist framework with retrieval- augmented reasoning and verification,”CoRR, vol. abs/2505.18283, 2025
-
[34]
Colacare: Enhancing electronic health record modeling through large language model-driven multi-agent collaboration,
Z. Wang, Y . Zhu, H. Zhao, X. Zheng, D. Sui, T. Wang, W. Tang, Y . Wang, E. M. Harrison, C. Pan, J. Gao, and L. Ma, “Colacare: Enhancing electronic health record modeling through large language model-driven multi-agent collaboration,” inWWW. ACM, 2025, pp. 2250–2261
2025
-
[35]
Dual test-time training for out-of-distribution recommender system,
X. Yang, Y . Wang, J. Chen, W. Fan, X. Zhao, E. Zhu, X. Liu, and D. Lian, “Dual test-time training for out-of-distribution recommender system,”IEEE Trans. Knowl. Data Eng., vol. 37, no. 6, pp. 3312–3326, 2025
2025
-
[36]
Test-time learning for large language models,
J. Hu, Z. Zhang, G. Chen, X. Wen, C. Shuai, W. Luo, B. Xiao, Y . Li, and M. Tan, “Test-time learning for large language models,” inICML. OpenReview.net, 2025
2025
-
[37]
Self-reflective generation at test time,
J. Mu, Q. Zhang, Z. Wang, M. Yang, S. Qiu, C. Qin, Z. Dai, and Y . Shu, “Self-reflective generation at test time,”CoRR, vol. abs/2510.02919, 2025
-
[38]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Q. Zhang, F. Lyu, Z. Sun, L. Wang, W. Zhang, Z. Guo, Y . Wang, I. King, X. Liu, and C. Ma, “What, how, where, and how well? A survey on test-time scaling in large language models,”CoRR, vol. abs/2503.24235, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
Tree of thoughts: Deliberate problem solving with large language models,
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” inNeurIPS, 2023
2023
-
[40]
A survey to recent progress towards understanding in-context learning,
H. Mao, G. Liu, Y . Ma, R. Wang, K. M. Johnson, and J. Tang, “A survey to recent progress towards understanding in-context learning,” in NAACL. Association for Computational Linguistics, 2025, pp. 7302– 7323
2025
-
[41]
Z- ICL: zero-shot in-context learning with pseudo-demonstrations,
X. Lyu, S. Min, I. Beltagy, L. Zettlemoyer, and H. Hajishirzi, “Z- ICL: zero-shot in-context learning with pseudo-demonstrations,” inACL. Association for Computational Linguistics, 2023, pp. 2304–2317
2023
-
[42]
Medcpt: Contrastive pre-trained transformers with large-scale pubmed search logs for zero-shot biomedical information retrieval,
Q. Jin, W. Kim, Q. Chen, D. C. Comeau, L. Yeganova, W. J. Wilbur, and Z. Lu, “Medcpt: Contrastive pre-trained transformers with large-scale pubmed search logs for zero-shot biomedical information retrieval,” Bioinform., vol. 39, no. 10, 2023
2023
-
[43]
Uncertainty-calibrated test-time model adaptation without forgetting,
M. Tan, G. Chen, J. Wu, Y . Zhang, Y . Chen, P. Zhao, and S. Niu, “Uncertainty-calibrated test-time model adaptation without forgetting,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 8, pp. 6274–6289, 2025
2025
-
[44]
Minimum entropy coupling with bottleneck,
M. R. Ebrahimi, J. Chen, and A. Khisti, “Minimum entropy coupling with bottleneck,” inNeurIPS, 2024
2024
-
[45]
A closer look at the training strategy for modern meta-learning,
J. Chen, X. Wu, Y . Li, Q. Li, L. Zhan, and F. Chung, “A closer look at the training strategy for modern meta-learning,” inNeurIPS, 2020
2020
-
[46]
Metaicl: Learning to learn in context,
S. Min, M. Lewis, L. Zettlemoyer, and H. Hajishirzi, “Metaicl: Learning to learn in context,” inNAACL. Association for Computational Linguistics, 2022, pp. 2791–2809
2022
-
[47]
Meta-learning approaches for few-shot learning: A survey of recent advances,
H. Gharoun, F. Momenifar, F. Chen, and A. H. Gandomi, “Meta-learning approaches for few-shot learning: A survey of recent advances,”ACM Comput. Surv., vol. 56, no. 12, pp. 294:1–294:41, 2024
2024
-
[48]
D. Jin, E. Pan, N. Oufattole, W. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? A large-scale open domain question answering dataset from medical exams,”CoRR, vol. abs/2009.13081, 2020
-
[49]
Pubmedqa: A dataset for biomedical research question answering,
Q. Jin, B. Dhingra, Z. Liu, W. W. Cohen, and X. Lu, “Pubmedqa: A dataset for biomedical research question answering,” inEMNLP. Association for Computational Linguistics, 2019, pp. 2567–2577
2019
-
[50]
Medmcqa: A large- scale multi-subject multi-choice dataset for medical domain question answering,
A. Pal, L. K. Umapathi, and M. Sankarasubbu, “Medmcqa: A large- scale multi-subject multi-choice dataset for medical domain question answering,” inConference on Health, Inference, and Learning, CHIL 2022, 7-8 April 2022, Virtual Event, ser. Proceedings of Machine Learning Research, vol. 174. PMLR, 2022, pp. 248–260
2022
-
[51]
Benchmarking large language models on answering and explaining challenging medical questions,
H. Chen, Z. Fang, Y . Singla, and M. Dredze, “Benchmarking large language models on answering and explaining challenging medical questions,” inNAACL. Association for Computational Linguistics, 2025, pp. 3563–3599
2025
-
[52]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” in ICLR. OpenReview.net, 2021
2021
-
[53]
Mmlu-pro: A more robust and challenging multi- task language understanding benchmark,
Y . Wang, X. Ma, G. Zhang, Y . Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen, “Mmlu-pro: A more robust and challenging multi- task language understanding benchmark,” inNeurIPS, 2024
2024
-
[54]
Medexqa: Medical ques- tion answering benchmark with multiple explanations,
Y . Kim, J. Wu, Y . Abdulle, and H. Wu, “Medexqa: Medical ques- tion answering benchmark with multiple explanations,” inProceedings of the 23rd Workshop on Biomedical Natural Language Processing, BioNLP@ACL 2024, Bangkok, Thailand, August 16, 2024. Association for Computational Linguistics, 2024, pp. 167–181
2024
-
[55]
Making science simple: Corpora for the lay summarisation of scientific literature,
T. Goldsack, Z. Zhang, C. Lin, and C. Scarton, “Making science simple: Corpora for the lay summarisation of scientific literature,” inEMNLP. Association for Computational Linguistics, 2022, pp. 10 589–10 604
2022
-
[56]
Paragraph- level simplification of medical texts,
A. Devaraj, I. J. Marshall, B. C. Wallace, and J. J. Li, “Paragraph- level simplification of medical texts,” inNAACL. Association for Computational Linguistics, 2021, pp. 4972–4984
2021
-
[57]
arXiv preprint arXiv:2408.08422 (2024)
G. Wang, J. Ran, R. Tang, C. Chang, Y . Chuang, Z. Liu, V . Braverman, Z. Liu, and X. Hu, “Assessing and enhancing large language models in rare disease question-answering,”CoRR, vol. abs/2408.08422, 2024
-
[58]
Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning,
S. S. Li, V . Balachandran, S. Feng, J. Ilgen, E. Pierson, P. W. W. Koh, and Y . Tsvetkov, “Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning,” inNeurIPS, 2024
2024
-
[59]
Medagentsbench: Benchmarking thinking models and agent frameworks for complex medical reasoning,
X. Tang, D. Shao, J. Sohn, J. Chen, J. Zhang, J. Xiang, F. Wu, Y . Zhao, C. Wu, W. Shi, A. Cohan, and M. Gerstein, “Medagentsbench: Benchmarking thinking models and agent frameworks for complex medical reasoning,”CoRR, vol. abs/2503.07459, 2025
-
[60]
Q. Team, “Qwen3 technical report,”CoRR, vol. abs/2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Are more LLM calls all you need? towards the scaling properties of compound AI systems,
L. Chen, J. Q. Davis, B. Hanin, P. Bailis, I. Stoica, M. A. Zaharia, and J. Y . Zou, “Are more LLM calls all you need? towards the scaling properties of compound AI systems,” inNeurIPS, 2024
2024
-
[62]
Multilingual E5 Text Embeddings: A Technical Report
L. Wang, N. Yang, X. Huang, L. Yang, R. Majumder, and F. Wei, “Multilingual E5 text embeddings: A technical report,”CoRR, vol. abs/2402.05672, 2024
work page internal anchor Pith review arXiv 2024
-
[63]
The faiss library,
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazar ´e, M. Lomeli, L. Hosseini, and H. J ´egou, “The faiss library,”IEEE Transactions on Big Data, 2025
2025
-
[64]
Bmretriever: Tuning large language models as better biomedical text retrievers,
R. Xu, W. Shi, Y . Yu, Y . Zhuang, Y . Zhu, M. D. Wang, J. C. Ho, C. Zhang, and C. Yang, “Bmretriever: Tuning large language models as better biomedical text retrievers,” inEMNLP. Association for Computational Linguistics, 2024, pp. 22 234–22 254
2024
-
[65]
A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions,
O. Shorinwa, Z. Mei, J. Lidard, A. Z. Ren, and A. Majumdar, “A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions,”ACM Computing Surveys, 2025
2025
-
[66]
Reclor: A reading comprehen- sion dataset requiring logical reasoning,
W. Yu, Z. Jiang, Y . Dong, and J. Feng, “Reclor: A reading comprehen- sion dataset requiring logical reasoning,” inICLR. OpenReview.net, 2020
2020
-
[67]
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning,
J. Liu, L. Cui, H. Liu, D. Huang, Y . Wang, and Y . Zhang, “Logiqa: A challenge dataset for machine reading comprehension with logical reasoning,” inIJCAI. ijcai.org, 2020, pp. 3622–3628
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.