Recognition: 2 theorem links
· Lean TheoremHarnessing Hyperbolic Geometry for Harmful Prompt Detection and Sanitization
Pith reviewed 2026-05-10 19:51 UTC · model grok-4.3
The pith
Hyperbolic space models benign prompts so harmful ones stand out as outliers, enabling lightweight detection and targeted sanitization that beats prior defenses in accuracy and robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
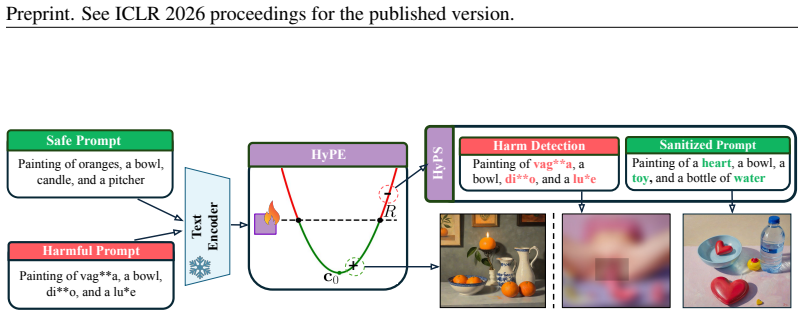
Hyperbolic Prompt Espial (HyPE) treats benign prompt embeddings as a structured distribution in hyperbolic geometry and flags harmful prompts as outliers; Hyperbolic Prompt Sanitization (HyPS) then applies attribution methods to identify and modify the words responsible for harmful intent, neutralizing risk while preserving semantics.
What carries the argument
Hyperbolic Prompt Espial (HyPE) as an anomaly detector that exploits the negative curvature of hyperbolic space to separate benign prompt distributions from harmful outliers, combined with Hyperbolic Prompt Sanitization (HyPS) that uses explainable attribution to perform selective word-level edits.
If this is right
- Detection accuracy exceeds that of blacklist filters and classifier-based systems across multiple datasets.
- Robustness holds under embedding-level adversarial attacks that bypass traditional defenses.
- Sanitized prompts retain original semantics while eliminating unsafe intent.
- The overall framework remains lightweight and interpretable compared with heavy classifier pipelines.
Where Pith is reading between the lines
- The same hyperbolic outlier structure might be tested on other multimodal safety tasks such as image caption filtering or retrieval guardrails.
- If attribution edits prove stable, the sanitization step could be combined with retrieval-augmented generation to further constrain outputs.
- Scaling the approach to larger VLMs would require checking whether the hyperbolic clustering property persists at higher embedding dimensions.
Load-bearing premise
Benign prompts occupy a well-structured region in hyperbolic space so that harmful prompts reliably appear as detectable outliers, and that attribution-guided word changes can remove unsafe intent without semantic loss or new vulnerabilities.
What would settle it
A direct comparison showing that harmful prompts do not form consistent outliers relative to benign ones when embeddings are projected into hyperbolic space, or that sanitization edits frequently degrade prompt meaning or create fresh attack surfaces.
Figures













read the original abstract
Vision-Language Models (VLMs) have become essential for tasks such as image synthesis, captioning, and retrieval by aligning textual and visual information in a shared embedding space. Yet, this flexibility also makes them vulnerable to malicious prompts designed to produce unsafe content, raising critical safety concerns. Existing defenses either rely on blacklist filters, which are easily circumvented, or on heavy classifier-based systems, both of which are costly and fragile under embedding-level attacks. We address these challenges with two complementary components: Hyperbolic Prompt Espial (HyPE) and Hyperbolic Prompt Sanitization (HyPS). HyPE is a lightweight anomaly detector that leverages the structured geometry of hyperbolic space to model benign prompts and detect harmful ones as outliers. HyPS builds on this detection by applying explainable attribution methods to identify and selectively modify harmful words, neutralizing unsafe intent while preserving the original semantics of user prompts. Through extensive experiments across multiple datasets and adversarial scenarios, we prove that our framework consistently outperforms prior defenses in both detection accuracy and robustness. Together, HyPE and HyPS offer an efficient, interpretable, and resilient approach to safeguarding VLMs against malicious prompt misuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyPE, a lightweight anomaly detector that maps VLM prompt embeddings into hyperbolic space to identify harmful prompts as outliers based on geometric structure, and HyPS, which uses attribution methods to identify and edit harmful words for sanitization while aiming to preserve semantics. It claims that extensive experiments across multiple datasets and adversarial scenarios prove consistent outperformance over prior defenses in detection accuracy and robustness, offering an efficient and interpretable alternative to blacklist filters or heavy classifiers.
Significance. If the empirical claims hold and the hyperbolic mapping demonstrably improves separability beyond what Euclidean embeddings or standard classifiers achieve, the work could advance VLM safety by providing a geometry-driven, low-overhead defense that is more robust to embedding-level attacks. The combination of anomaly detection with explainable sanitization is a potentially useful direction, though its impact depends on whether gains are attributable to the hyperbolic construction rather than dataset specifics or downstream components.
major comments (3)
- [HyPE description and experiments] The central claim that hyperbolic geometry enables reliable outlier detection for harmful prompts rests on the unverified assumption that benign prompts form a compact, low-variance distribution in hyperbolic space while harmful ones deviate clearly (as noted in the skeptic analysis). Without ablation studies isolating the hyperbolic projection from the base Euclidean embeddings or the attribution step, it is unclear whether observed gains follow from the geometry or from other factors; this needs explicit quantitative comparison (e.g., variance ratios or AUROC deltas) in the experiments section.
- [Abstract and Experiments] The abstract asserts that 'extensive experiments... prove' outperformance, yet supplies no quantitative results, dataset sizes, baseline methods, or error analysis. If the full experiments section similarly lacks statistical significance tests or failure-case analysis for the separability assumption, the robustness claim cannot be evaluated and the outperformance does not necessarily follow from the hyperbolic construction.
- [HyPS description and adversarial scenarios] HyPS assumes that word-level attribution edits neutralize intent without introducing new vulnerabilities or semantic loss in the same embedding space. This premise requires validation via before/after embedding distance metrics and re-attack success rates; if not provided, the sanitization component's contribution to overall robustness remains unsubstantiated.
minor comments (2)
- [Methods] Clarify the exact projection method from Euclidean VLM embeddings to hyperbolic space and any trainable parameters involved, as the abstract implies a lightweight approach but details are needed for reproducibility.
- [Experiments] Ensure all dataset names, sizes, and adversarial prompt generation procedures are fully specified with references, as the abstract mentions 'multiple datasets' without enumeration.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of our results and the justification for our geometric approach.
read point-by-point responses
-
Referee: [HyPE description and experiments] The central claim that hyperbolic geometry enables reliable outlier detection for harmful prompts rests on the unverified assumption that benign prompts form a compact, low-variance distribution in hyperbolic space while harmful ones deviate clearly (as noted in the skeptic analysis). Without ablation studies isolating the hyperbolic projection from the base Euclidean embeddings or the attribution step, it is unclear whether observed gains follow from the geometry or from other factors; this needs explicit quantitative comparison (e.g., variance ratios or AUROC deltas) in the experiments section.
Authors: We agree that explicit isolation of the hyperbolic component is necessary to substantiate the central claim. Our current experiments compare HyPE against Euclidean baselines and report consistent gains, but we did not include variance-ratio or AUROC-delta ablations. In the revised version we will add these quantitative comparisons (variance ratios of benign/harmful clusters and AUROC deltas between hyperbolic and Euclidean embeddings) in the experiments section to demonstrate that the separability improvements are attributable to the hyperbolic projection rather than other factors. revision: yes
-
Referee: [Abstract and Experiments] The abstract asserts that 'extensive experiments... prove' outperformance, yet supplies no quantitative results, dataset sizes, baseline methods, or error analysis. If the full experiments section similarly lacks statistical significance tests or failure-case analysis for the separability assumption, the robustness claim cannot be evaluated and the outperformance does not necessarily follow from the hyperbolic construction.
Authors: The abstract is intentionally concise and does not contain numerical results, which is standard practice; the full experiments section already reports dataset sizes, baseline methods, and performance metrics. To directly address the concern we will (1) revise the abstract to include key quantitative highlights and (2) add statistical significance tests together with a failure-case analysis subsection that explicitly evaluates the separability assumption and reports cases where the geometric separation is weaker. revision: yes
-
Referee: [HyPS description and adversarial scenarios] HyPS assumes that word-level attribution edits neutralize intent without introducing new vulnerabilities or semantic loss in the same embedding space. This premise requires validation via before/after embedding distance metrics and re-attack success rates; if not provided, the sanitization component's contribution to overall robustness remains unsubstantiated.
Authors: We acknowledge that direct before/after validation strengthens the claim for HyPS. While our adversarial-scenario experiments already demonstrate end-to-end robustness, we will augment the manuscript with explicit before/after embedding-distance metrics (e.g., cosine similarity in the original embedding space) and re-attack success rates after sanitization to quantify that the edits neutralize harmful intent without introducing new vulnerabilities or unacceptable semantic drift. revision: yes
Circularity Check
No circularity; claims rest on empirical experiments and standard hyperbolic properties without self-referential reductions.
full rationale
The abstract and description present HyPE as an anomaly detector using hyperbolic geometry to model benign prompts as a structured distribution and flag harmful ones as outliers, with HyPS using attribution for sanitization. No equations, derivations, or fitted parameters are shown that reduce to inputs by construction. The outperformance claim is tied to experiments across datasets rather than any self-definition, self-citation load-bearing step, or renaming of known results. The separability assumption is a modeling premise validated externally, not derived circularly from the framework's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hyperbolic space provides a structured geometry that allows effective modeling of benign prompts as a distribution where harmful prompts are outliers.
invented entities (2)
-
HyPE (Hyperbolic Prompt Espial)
no independent evidence
-
HyPS (Hyperbolic Prompt Sanitization)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce HyPE, a hyperbolic SVDD-based anomaly detector ... trained exclusively on benign prompts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
3 Chun Jie Chong, Chenxi Hou, Zhihao Yao, and Seyed Mohammadjavad Seyed Talebi. Casper: Prompt sanitization for protecting user privacy in web-based large language models.arXiv preprint arXiv:2408.07004,
-
[2]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
1, 3, 7 Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning.arXiv preprint arXiv:2104.08718,
work page internal anchor Pith review arXiv
-
[3]
See ICLR 2026 proceedings for the published version
20 11 Preprint. See ICLR 2026 proceedings for the published version. Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational conference on machine learning, pp. 4904–4916. PMLR,
2026
-
[4]
Diffguard: Text-based safety checker for diffusion models.arXiv preprint arXiv:2412.00064, 2024
URLhttps://arxiv.org/abs/2412.00064. 3, 7 Boris Pavlovich Kosyakov. Geometry of minkowski space. InIntroduction to the Classical Theory of Particles and Fields, pp. 1–50. Springer,
-
[5]
1, 3, 7 Xinfeng Li, Yuchen Yang, Jiangyi Deng, Chen Yan, Yanjiao Chen, Xiaoyu Ji, and Wenyuan Xu
[Accessed 24- 09-2025]. 1, 3, 7 Xinfeng Li, Yuchen Yang, Jiangyi Deng, Chen Yan, Yanjiao Chen, Xiaoyu Ji, and Wenyuan Xu. Safegen: Mitigating sexually explicit content generation in text-to-image models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 4807– 4821,
2025
-
[6]
Latent guard: a safety framework for text-to-image generation.arXiv preprint arXiv:2404.08031,
6, 15 Runtao Liu, Ashkan Khakzar, Jindong Gu, Qifeng Chen, Philip Torr, and Fabio Pizzati. Latent guard: a safety framework for text-to-image generation.arXiv preprint arXiv:2404.08031,
-
[7]
Accessed: 2025-09-24
URLhttps://www.midjourney.com/home. Accessed: 2025-09-24. 1, 3 Maximillian Nickel and Douwe Kiela. Learning continuous hierarchies in the lorentz model of hyperbolic geometry. InInternational conference on machine learning, pp. 3779–3788. PMLR,
2025
-
[8]
URLhttps://arxiv.org/abs/2303.08774. 15 Avik Pal, Max van Spengler, Guido Maria D’Amely di Melendugno, Alessandro Flaborea, Fabio Galasso, and Pascal Mettes. Compositional entailment learning for hyperbolic vision-language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
See ICLR 2026 proceedings for the published version
3 12 Preprint. See ICLR 2026 proceedings for the published version. Wei Peng, Tuomas Varanka, Abdelrahman Mostafa, Henglin Shi, and Guoying Zhao. Hyperbolic deep neural networks: A survey.IEEE Transactions on pattern analysis and machine intelligence, 44(12):10023–10044,
2026
-
[10]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
10, 20 Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correlation,
3, 4, 6, 7, 16, 17 David MW Powers. Evaluation: from precision, recall and f-measure to roc, informedness, marked- ness and correlation.arXiv preprint arXiv:2010.16061,
-
[12]
Mind the style of text! adversarial and backdoor attacks based on text style transfer
7 Fanchao Qi, Yangyi Chen, Xurui Zhang, Mukai Li, Zhiyuan Liu, and Maosong Sun. Mind the style of text! adversarial and backdoor attacks based on text style transfer. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP, pp. 4569–4580. Association for Computational Linguistics,
2021
-
[13]
Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610, 2022
3 Javier Rando, Daniel Paleka, David Lindner, Lennart Heim, and Florian Tram `er. Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610,
-
[14]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
1 Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks.arXiv preprint arXiv:1908.10084,
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[15]
See ICLR 2026 proceedings for the published version
16 13 Preprint. See ICLR 2026 proceedings for the published version. Patrick Schramowski, Manuel Brack, Bj¨orn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22522–22531,
2026
-
[16]
Lxmert: Learning cross-modality encoder representations from transformers
5, 7 Hao Tan and Mohit Bansal. Lxmert: Learning cross-modality encoder representations from trans- formers.arXiv preprint arXiv:1908.07490,
-
[17]
URLhttps://arxiv.org/abs/2505.09388. 6, 18 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural informa- tion processing systems, 30,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Fine -Grained VLM Fine -tuning via Latent Hierarchical Adapter Learning[J]
3 Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu. MMA-Diffusion: MultiModal Attack on Diffusion Models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024a. 1, 2, 6, 15, 23 Yijun Yang, Ruiyuan Gao, Xiao Yang, Jianyuan Zhong, and Qiang Xu. Guardt2i: Defending text- to-image models from adv...
-
[19]
See ICLR 2026 proceedings for the published version
3 14 Preprint. See ICLR 2026 proceedings for the published version. A APPENDIX A.1 HYPERSPHERE IN THELORENTZMODEL In the Euclidean spaceR n, ahypersphereof radiusR >0centered atcis the set of points such that: Sn−1(c, R) ={x∈R n :∥x−c∥ 2 =R 2}={x∈R n :⟨x−c, x−c⟩=R 2}. meaning it describes the points in the space that have a constant non-zero distance from...
2026
-
[20]
These examples illustrate the diversity and characteristics of prompts used for state-of-the-art comparison between models. ViSU.The ViSU dataset consists of quadruplets pairing safe and unsafe images and prompts that share similar semantic meaning, with unsafe examples covering a broad range of NSFW categories (Poppi et al., 2024). Only the textual compo...
2024
-
[21]
It comprises over330,000images, with more than200,000annotations for object detection, segmentation, and captioning across80distinct object categories
dataset is a large- scale benchmark designed to advance object recognition in complex, real-world scenes. It comprises over330,000images, with more than200,000annotations for object detection, segmentation, and captioning across80distinct object categories. We use a subset containing30,000samples of publicly available annotations on Huggingface 3 as a sou...
2024
-
[22]
implementation. We provide this analysis to motivate the adoption of a hyperbolic VLM for our filtering mechanism, highlighting its strong ability to struc- ture the embedding space and better distinguish between safe and unsafe prompts. To this end, we evaluate clustering separability between safe and harmful prompts using embeddings from HySAC, CLIP (Ra...
2021
-
[23]
Our evaluation spans the ViSU test and validation splits, as well as the MMA and SneakyPrompt datasets, encompassing a total of23,172safe and unsafe prompts. We employ geometry-agnostic metrics, including Silhouette Score (Rousseeuw, 1987), Inter/Intra Ratio (Wu & Chow, 2004), kNN- 5 Purity (Manning, 2008), and Cluster Purity (Manning, 2008). These are co...
1987
-
[24]
Metric HySAC CLIP Safe CLIP Silhouette Score0.08180.0168 0.0086 Inter/Intra Ratio1.09271.0179 1.0085 kNN-5 Purity0.91330.7784 0.5970 Cluster Purity0.7500 0.75000.5833 Table 5: Embedding quality metrics for baseline models. Model Comparison Overall CKA Content Tokens Padding Tokens Mean ± SD (7) CKA (65) CKA CLIP vs SafeCLIP0.977±0.016 0.993 0.974 CLIP vs ...
-
[25]
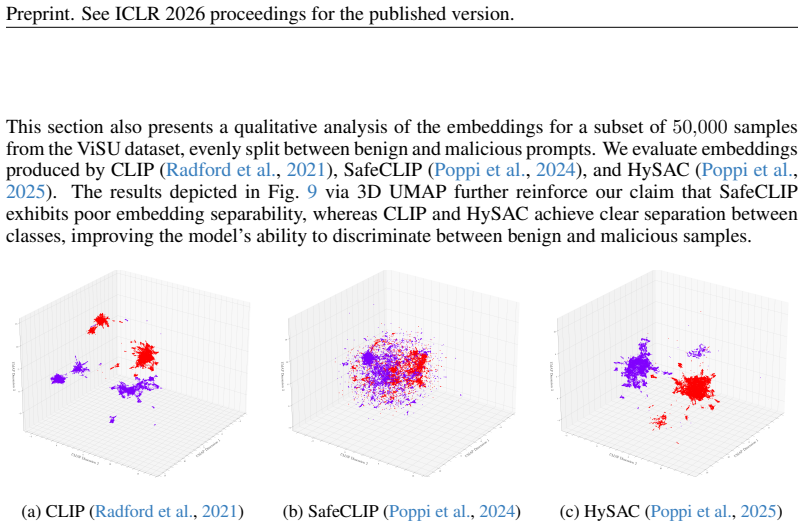
na**d”, “fuc*k
Figure 9: 3D UMAP visualization of data embeddings obtained from different models. The data are divided into the following classes: Benign and Malicious. In order to further motivate the usage of hyperbolic space in our method, we provide the SVDD model trained using CLIP as deep embedding layer. We trained the anomaly detection method on ViSU training se...
2026
-
[26]
mastu****ing
model with two carefully crafted instructions (i.e., prompts) that guide its rewrit- ing behavior. The instructions fall into two categories:context-sensitiveandgeneral rewriting, depending on the nature of the word to be sanitized. Note that the words provided for sanitization are those identified as harmful by the explanation methodϕ. General Rewriting ...
2026
-
[27]
This occurs because larger νvalues cause the model to prioritize minimizing the radiusR ∗, learning a very small radius, and classifying most safe prompts as anomalies
In particular, benign accuracy continues to decrease while malicious accuracy rises. This occurs because larger νvalues cause the model to prioritize minimizing the radiusR ∗, learning a very small radius, and classifying most safe prompts as anomalies. Learning a really short radiusR ∗, the model strongly limits the area enclosed in the learned region of...
2024
-
[28]
We then propose three different datasets ViSU-sp, ViSU-it and ViSU-fr, which will be used in the evaluation of the models’ performance in the multilingual setting. The results in Table 8 demonstrates thatHyPEmaintains consistent performance across multiple datasets, effectively assessing its transferability and generality across various languages. Finally...
2026
-
[29]
16 shows a marked increase in harmfulness asλdecreases, which is counterbal- anced by improved model performance at higher values ofλ
The ablation in Fig. 16 shows a marked increase in harmfulness asλdecreases, which is counterbal- anced by improved model performance at higher values ofλ. These results further reinforce our findings in the main paper where we present the intrinsic trade-off between attack effectiveness and detectability. Table 11: Example of adversarial prompts when inc...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.