Recognition: 2 theorem links
· Lean TheoremDrifting Fields are not Conservative
Pith reviewed 2026-05-11 01:49 UTC · model grok-4.3
The pith
Drift fields learned by drifting models are not gradients of any scalar potential.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Drift fields are not conservative and cannot be written as the gradient of any scalar potential. The position-dependent normalization is the source of non-conservatism, with the Gaussian kernel as the unique radial exception. Introducing the sharp kernel and sharp-normalized drift field makes the vector field the gradient of a scalar potential for general radial kernels, yields the form of a score difference between kernel density estimates, and supplies exact equilibrium identifiability.
What carries the argument
The sharp-normalized drift field, obtained by replacing the position-dependent normalization with a fixed sharp kernel so that the resulting vector field equals the gradient of a scalar potential built from kernel density estimates.
If this is right
- Training reduces to ordinary stochastic gradient descent on an explicit scalar loss.
- The equilibrium distribution is exactly identifiable as the kernel density estimate of the data.
- The method now aligns with Wasserstein gradient flows and denoising score matching even for non-Gaussian kernels.
- Empirical generation quality remains unchanged, showing that non-conservative freedom is not needed for performance.
Where Pith is reading between the lines
- Non-conservative flexibility appears dispensable for high-quality single-pass generation, opening the door to potential-based analysis and stability guarantees.
- The same sharp-normalization trick may apply to other kernel-driven vector fields in sampling or flow-based models.
- Equilibrium identifiability suggests that sharp drifting could be used for density estimation tasks beyond generation.
Load-bearing premise
The drifting objective is defined with a position-dependent normalization whose variation with location is what prevents the field from being conservative except in the Gaussian case.
What would settle it
A direct numerical evaluation of the curl of the original drift field at a test point for a non-Gaussian radial kernel that yields a nonzero value would confirm non-conservatism; conversely, exhibiting a scalar function whose gradient exactly recovers the original field for such a kernel would falsify it.
Figures






read the original abstract
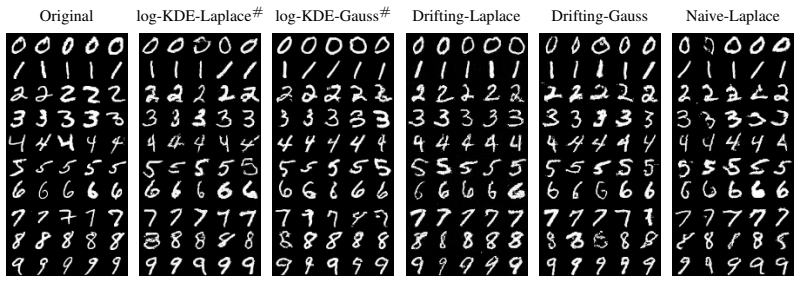
Drifting models have recently gained attention for generating high-quality samples in a single forward pass. During training, they learn a push-forward map by following a vector-valued field, the drift field. We ask whether this procedure is equivalent to optimizing a scalar loss and find that, in general, it is not: drift fields are not conservative and cannot be written as the gradient of any scalar potential. We identify the position-dependent normalization as the source of non-conservatism, with the Gaussian kernel as the unique radial exception. Guided by this, we introduce the sharp kernel $k^\#$ and a sharp-normalized drift field that is conservative for general radial kernels. The resulting vector field is the gradient of a scalar potential that can be optimized directly using stochastic gradient descent. Moreover, the field has the form of a score difference of kernel density estimates, and gives exact equilibrium identifiability. Thus, sharp normalization closes the gap to related literature, such as Wasserstein gradient-flows and denoising score matching, also for non-Gaussian kernels. Empirically, sharp normalization preserves the performance of the original drifting objective, suggesting that the non-conservative flexibility is not required for high-quality generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the drift fields learned by drifting models are not conservative in general (i.e., cannot be expressed as the gradient of any scalar potential) because the drifting objective employs a position-dependent normalization term. The Gaussian kernel is the unique radial exception. The authors introduce a sharp kernel k^# and the associated sharp-normalized drift field, which is conservative for arbitrary radial kernels, equals the gradient of a score difference between two kernel density estimates, admits direct SGD optimization, and yields exact equilibrium identifiability. Empirically, sharp normalization preserves the generation performance of the original drifting objective.
Significance. If the central claims hold, the work supplies a precise theoretical diagnosis of non-conservatism in drifting models and a constructive remedy (sharp normalization) that recovers an explicitly conservative field while retaining empirical performance. This directly connects drifting models to the conservative literature on Wasserstein gradient flows and denoising score matching for non-Gaussian kernels, potentially enabling cleaner theoretical analysis and gradient-based training of single-pass generators.
major comments (2)
- [§4] §4 (or wherever the uniqueness argument appears): the claim that the Gaussian kernel is the unique radial exception is load-bearing for the motivation of sharp normalization. The provided high-level argument identifies position-dependent normalization as the source, but the manuscript must explicitly derive the curl or non-integrability condition for general radial kernels and show why only the Gaussian satisfies it; without that derivation the exception claim remains at the level of the abstract.
- [Definition of k^#] Definition of the sharp kernel k^# and the resulting drift field: the manuscript states that the sharp-normalized field is the gradient of a score difference of KDEs. The explicit construction (how k^# is obtained from the original kernel and how the position dependence is removed) must be given with all intermediate steps; this is central to the claim that the field is now conservative and optimizable by SGD.
minor comments (3)
- Notation: the sharp kernel is denoted k^# throughout; a single, early definition with its relation to the original kernel k would improve readability.
- [Experiments] The empirical section should report the precise drifting objective and the exact form of the sharp objective used in the experiments so that the performance-preservation claim can be reproduced.
- A brief remark on whether the sharp construction extends beyond radial kernels would be useful, even if the paper focuses on the radial case.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment of the work, and recommendation for minor revision. We address the two major comments below and will incorporate the requested clarifications and derivations into the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (or wherever the uniqueness argument appears): the claim that the Gaussian kernel is the unique radial exception is load-bearing for the motivation of sharp normalization. The provided high-level argument identifies position-dependent normalization as the source, but the manuscript must explicitly derive the curl or non-integrability condition for general radial kernels and show why only the Gaussian satisfies it; without that derivation the exception claim remains at the level of the abstract.
Authors: We agree that an explicit derivation is required to substantiate the uniqueness claim. In the revised manuscript we will expand the relevant section (currently §4) with a full computation of the curl of the drift field for a general radial kernel k. Starting from the position-dependent normalization term, we will derive the explicit non-integrability condition on the partial derivatives and show that this condition holds if and only if k is Gaussian. The derivation will include all intermediate steps and will directly motivate sharp normalization as the general remedy. revision: yes
-
Referee: [Definition of k^#] Definition of the sharp kernel k^# and the resulting drift field: the manuscript states that the sharp-normalized field is the gradient of a score difference of KDEs. The explicit construction (how k^# is obtained from the original kernel and how the position dependence is removed) must be given with all intermediate steps; this is central to the claim that the field is now conservative and optimizable by SGD.
Authors: We thank the referee for this observation. In the revision we will insert a complete, self-contained derivation of the sharp kernel k^# and the associated drift field. Beginning from an arbitrary radial kernel k, we will define k^# explicitly, show how the normalization is rendered independent of the drift variable, derive that the resulting field equals the gradient of the difference between two kernel density estimates, and prove both conservativeness and direct SGD optimizability. All algebraic intermediate steps will be provided. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper derives non-conservatism of the drift field directly from the explicit form of the drifting objective and its position-dependent normalization, showing via vector calculus that the field cannot be expressed as the gradient of a scalar potential except in the Gaussian radial case. The sharp kernel is introduced as an independent construction that removes the position dependence, yielding an explicitly conservative field as the gradient of a score difference between kernel density estimates. No load-bearing step reduces to a fitted parameter, self-citation chain, ansatz, or renaming; the uniqueness claim for the Gaussian kernel is obtained by direct computation rather than imported theorem, and empirical performance preservation is presented only as corroboration.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Drift fields are defined via a push-forward map following a vector-valued field with position-dependent normalization.
- domain assumption The analysis applies to radial kernels in the drift field definition.
invented entities (1)
-
sharp kernel k^#
no independent evidence
Forward citations
Cited by 2 Pith papers
-
DriftXpress: Faster Drifting Models via Projected RKHS Fields
DriftXpress approximates drifting kernels via projected RKHS fields to lower training cost of one-step generative models while matching original FID scores.
-
On the Wasserstein Gradient Flow Interpretation of Drifting Models
GMD algorithms correspond to limiting points of Wasserstein gradient flows on the KL divergence with Parzen smoothing and bear resemblance to Sinkhorn divergence fixed points, with extensions to MMD and other divergences.
Reference graph
Works this paper leans on
-
[1]
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[2]
Generative Modeling via Drifting
Deng, M., Li, H., Li, T., Du, Y ., and He, K. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026
work page internal anchor Pith review arXiv 2026
-
[3]
A kernel method for the two-sample-problem
Gretton, A., Borgwardt, K., Rasch, M., Schölkopf, B., and Smola, A. A kernel method for the two-sample-problem. InAdvances in Neural Information Processing Systems, volume 19, 2006
work page 2006
-
[4]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[5]
Improved precision and recall metric for assessing generative models
Kynkäänniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. Improved precision and recall metric for assessing generative models. InAdvances in Neural Information Processing Systems, volume 32, 2019. 10
work page 2019
-
[6]
Lecun, Y ., Bottou, L., Bengio, Y ., and Haffner, P. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791
-
[7]
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[8]
Peebles, W. and Xie, S. Scalable Diffusion Models with Transformers . In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4172–4182, 2023. doi: 10.1109/ ICCV51070.2023.00387
-
[9]
High-Resolution Image Synthesis with Latent Diffusion Models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models.arXiv preprint arXiv:2112.10752, 2022
work page Pith review arXiv 2022
- [10]
-
[11]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Xiao, H., Rasul, K., and V ollgraf, R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017. 11 A Conservatism and Jacobian Symmetry We give a self-contained proof for Lemma 7, i.e. A vector fieldV:R n →R n is conservative if and only if its Jacobian is symmetric. Proof.(⇒): IfV=∇L, then ∂...
work page internal anchor Pith review arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.