Recognition: unknown
On the Wasserstein Gradient Flow Interpretation of Drifting Models
Pith reviewed 2026-05-08 17:27 UTC · model grok-4.3
The pith
Generative Modeling via Drifting targets fixed points of Wasserstein gradient flows on smoothed divergences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
One algorithm proposed in the GMD framework reaches the limiting point of a Wasserstein gradient flow that minimizes the Kullback-Leibler divergence after Parzen kernel smoothing of the densities. The algorithm that was actually run in the original work instead approximates the fixed point of a flow defined by the Sinkhorn divergence, although it lacks some of the theoretical properties of that flow. The same fixed-point targeting construction extends directly to Wasserstein gradient flows driven by the maximum mean discrepancy, the sliced Wasserstein distance, and functions arising from GAN critics.
What carries the argument
The fixed point of a Wasserstein gradient flow, which is the probability measure that no longer changes under the steepest-descent dynamics induced by a chosen functional (such as KL or Sinkhorn divergence) in the Wasserstein geometry on probability measures.
If this is right
- Different choices of the underlying functional yield new drifting procedures whose fixed points inherit known convergence or uniqueness properties of the corresponding flow.
- The Parzen-smoothed KL flow provides an exact theoretical account for one of the originally proposed GMD variants.
- The implemented GMD procedure can be viewed as a practical approximation to a Sinkhorn-based flow, suggesting possible refinements that restore the missing properties.
- The same construction applies to flows driven by maximum mean discrepancy, sliced Wasserstein distance, or GAN critic objectives, producing alternative generative algorithms.
Where Pith is reading between the lines
- The fixed-point perspective may allow borrowing stability results or particle discretizations already developed for other Wasserstein flows.
- Choosing functionals whose flows have unique fixed points could reduce sensitivity to initialization in drifting models.
- Empirical comparisons could test whether replacing the current functional with a sliced-Wasserstein flow improves sample quality on high-dimensional data.
Load-bearing premise
The exact match between the GMD iteration rules and the stationary points of the corresponding continuous Wasserstein flows survives once Parzen smoothing and all discretization steps are taken into account.
What would settle it
Running the GMD update rule to convergence on a simple low-dimensional mixture and comparing the resulting distribution against the output of a high-resolution discretization of the claimed Wasserstein gradient flow on the same functional; any systematic discrepancy in the support or moments would falsify the correspondence.
Figures


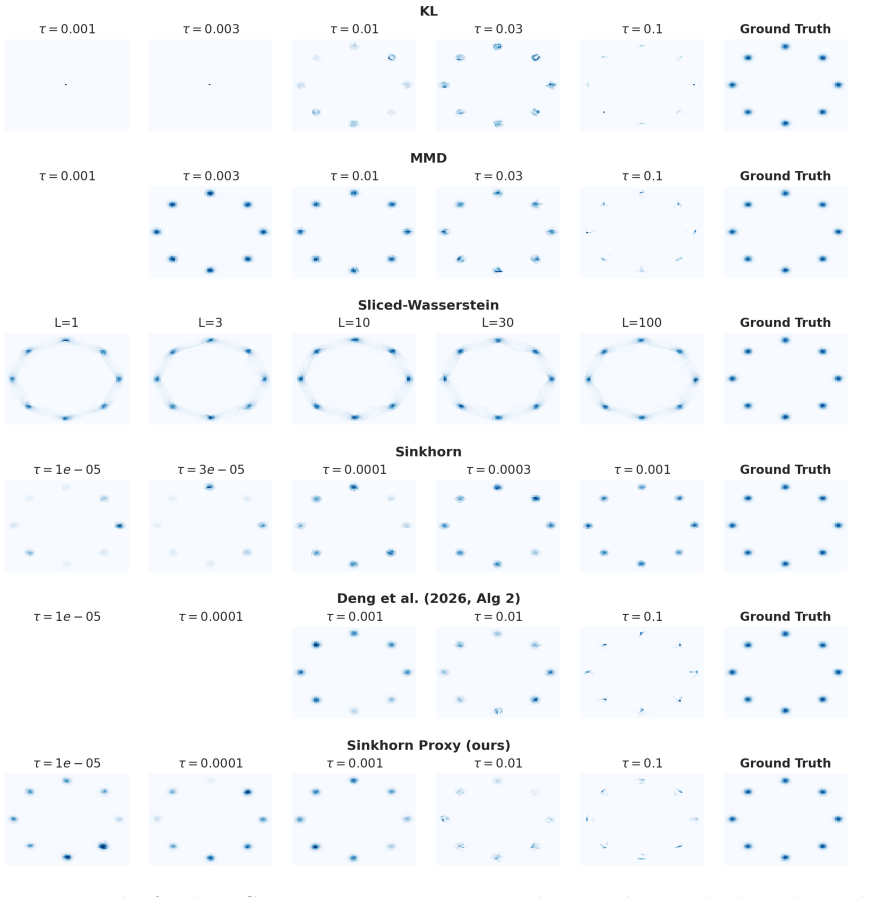
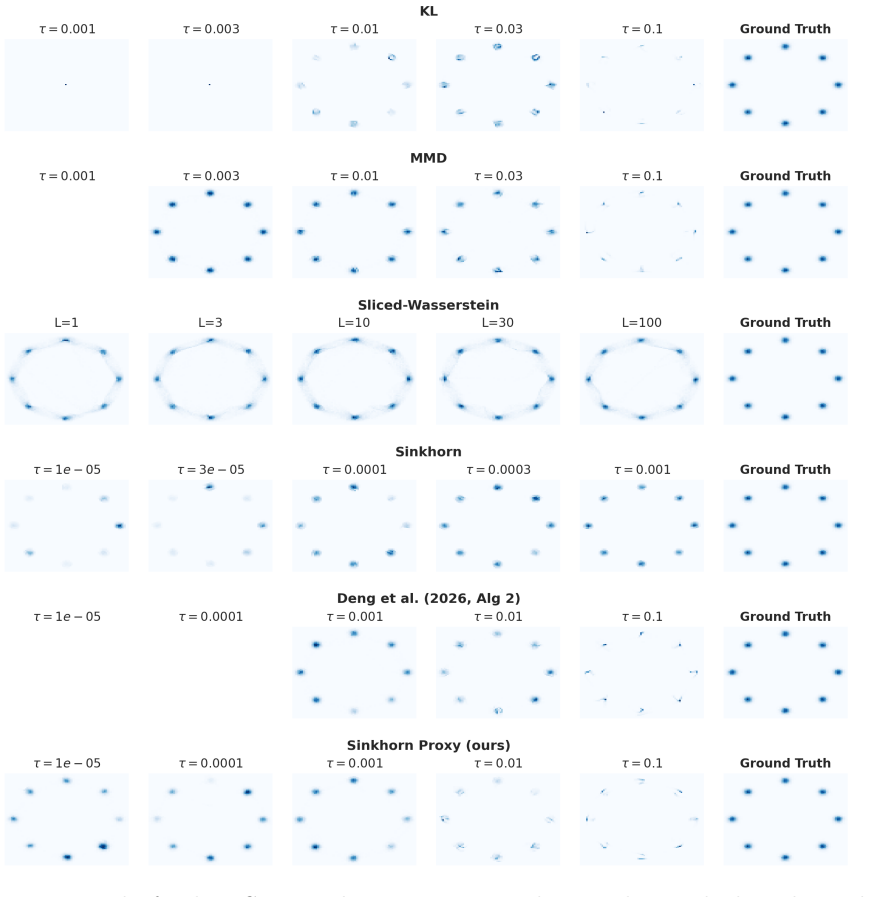
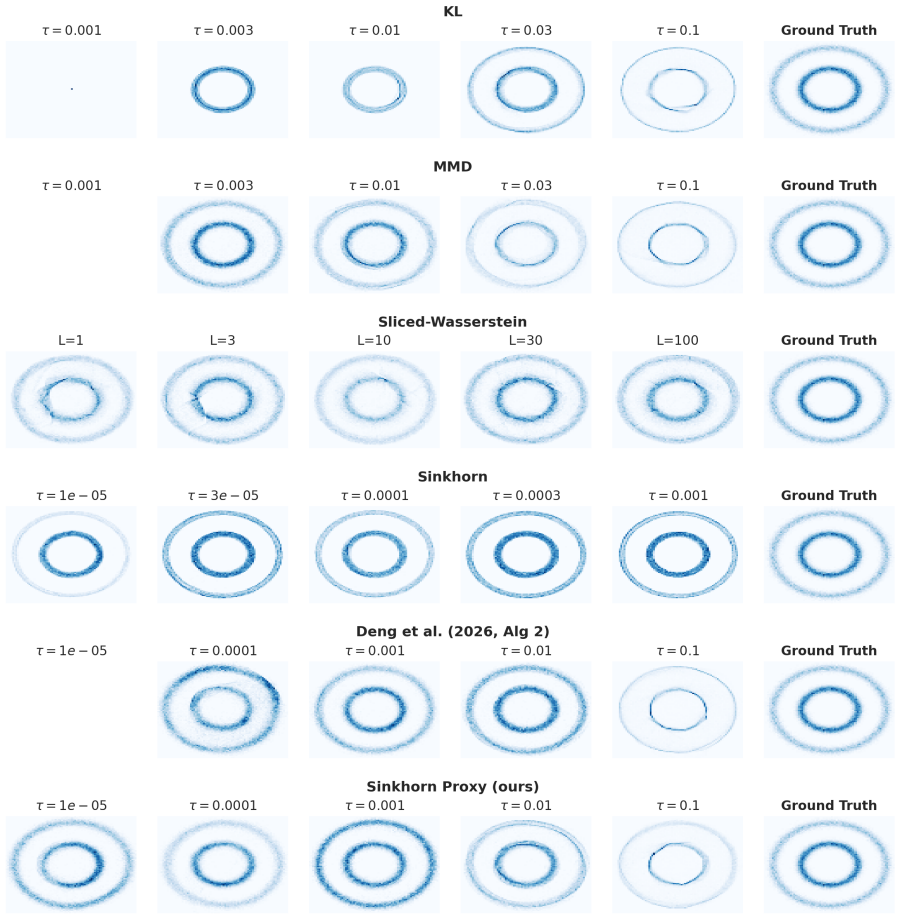

read the original abstract
Recently, Deng et al. (2026) proposed Generative Modeling via Drifting (GMD), a novel framework for generative tasks. This note presents an analysis of GMD through the lens of Wasserstein Gradient Flows (WGF), i.e., the path of steepest descent for a functional in the space of probability measures, equipped with the geometry of optimal transport. Unlike previous WGF-based contributions, GMD can be thought of as directly targeting a fixed point of a specific WGF flow. We demonstrate three main results: first, that one algorithm proposed by Deng et al. (2026) corresponds to finding the limiting point of a WGF on the KL divergence, with Parzen smoothing on the densities. Second, that the algorithm actually implemented by Deng et al. (2026) corresponds to a different procedure, which bears some resemblance to the fixed point of a WGF on the Sinkhorn divergence, but lacks certain desirable properties of the latter. Third, the same same idea can be extended to the limiting point of other WGFs, including the Maximum Mean Discrepancy (MMD), the sliced Wasserstein distance, and GAN critic functions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This note analyzes Generative Modeling via Drifting (GMD) proposed by Deng et al. (2026) through the lens of Wasserstein gradient flows (WGF). It claims three main results: (1) one GMD algorithm corresponds to the limiting point of a WGF on the KL divergence with Parzen smoothing on densities; (2) the actually implemented GMD algorithm resembles the fixed point of a WGF on the Sinkhorn divergence but lacks some of its desirable properties; (3) the same idea extends to limiting points of other WGFs, including those based on MMD, sliced Wasserstein distance, and GAN critic functions.
Significance. If the claimed exact correspondences can be rigorously derived and verified, the note would offer a useful interpretive bridge between drifting generative models and optimal transport geometry, potentially clarifying convergence behavior and motivating new algorithm variants. The distinction drawn between the proposed and implemented GMD procedures is a positive contribution to understanding practical versus theoretical aspects of the framework.
major comments (2)
- [Abstract] Abstract: the three correspondences are asserted without any derivation, explicit stationarity condition, or verification that the discrete GMD updates (after Parzen smoothing) satisfy the continuous WGF fixed-point equation (gradient of the functional set to zero in the Wasserstein metric). This is load-bearing for all three results.
- [Abstract] Abstract (second result): the claim that the implemented algorithm 'bears some resemblance' to the Sinkhorn-WGF fixed point while 'lacks certain desirable properties' is stated without an equation-level comparison or analysis of how discretization, optimization details, or early stopping affect the equivalence; the skeptic note correctly flags this as an unverified step.
minor comments (1)
- The note would be strengthened by explicitly writing the GMD update rules next to the corresponding WGF stationarity conditions to allow direct inspection of the claimed mappings.
Simulated Author's Rebuttal
We thank the referee for the careful reading and valuable comments on our note. The points raised about the abstract are well-taken, and we will revise the manuscript to provide clearer indications of the derivations and comparisons.
read point-by-point responses
-
Referee: [Abstract] Abstract: the three correspondences are asserted without any derivation, explicit stationarity condition, or verification that the discrete GMD updates (after Parzen smoothing) satisfy the continuous WGF fixed-point equation (gradient of the functional set to zero in the Wasserstein metric). This is load-bearing for all three results.
Authors: The main text of the note derives these correspondences by explicitly computing the Wasserstein gradient of the respective functionals and showing that the GMD iteration reaches the point where this gradient vanishes. For the first result, we show that the Parzen-smoothed KL divergence has a stationarity condition matching the GMD update rule in the limit. We will update the abstract to state that these are derived in the body of the note and include a brief mention of the stationarity condition. revision: yes
-
Referee: [Abstract] Abstract (second result): the claim that the implemented algorithm 'bears some resemblance' to the Sinkhorn-WGF fixed point while 'lacks certain desirable properties' is stated without an equation-level comparison or analysis of how discretization, optimization details, or early stopping affect the equivalence; the skeptic note correctly flags this as an unverified step.
Authors: We agree that an equation-level comparison would make the resemblance and differences more precise. The note already contrasts the fixed-point equations, noting that the implemented GMD uses a specific approximation that does not fully inherit the properties of the Sinkhorn divergence flow, such as certain convexity or convergence guarantees. We will add an explicit side-by-side comparison of the stationarity conditions in the revised manuscript and discuss the effects of discretization and early stopping. revision: partial
Circularity Check
No circularity: WGF fixed-point claims rest on external theory applied to cited GMD definitions
full rationale
The note applies standard Wasserstein gradient flow stationarity conditions (gradient of KL or Sinkhorn functional set to zero in Wasserstein metric) to the GMD update rules after Parzen smoothing, as defined in the external Deng et al. (2026) reference. No parameter is fitted inside the note and then renamed a prediction; no self-citation chain justifies the core premise; the Sinkhorn case is explicitly qualified as resemblance rather than exact identity; extensions to MMD and sliced Wasserstein follow the same external framework without redefinition. The derivation chain is therefore self-contained against independent WGF mathematics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wasserstein gradient flows exist and converge to fixed points for the listed divergences under suitable regularity conditions on the densities.
Reference graph
Works this paper leans on
-
[1]
Ambrosio, L., Gigli, N., and Savar \'e , G. (2008). Gradient Flows in Metric Spaces and in the Space of Probability Measures . Birkh \"a user
2008
-
[2]
Arbel, M., Korba, A., Salim, A., and Gretton, A. (2019). Maximum mean discrepancy gradient flow. In Advances in Neural Information Processing Systems
2019
-
[3]
Cao, J., Wei, Z., and Liu, Y. (2026). Gradient flow drifting: Generative modeling via W asserstein gradient flows of KDE -approximated divergences
2026
-
[4]
Chen, Z., Mustafi, A., Glaser, P., Korba, A., Gretton, A., and Sriperumbudur, B. K. (2025). ( D e)-regularized maximum mean discrepancy gradient flow. Journal of Machine Learning Research , 26(235):1--77
2025
-
[5]
Cortes, C., Mohri, M., and Rostamizadeh, A. (2009). L2 regularization for learning kernels. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (UAI 2009) , pages 109--116
2009
-
[6]
and Santambrogio, F
Cozzi, G. and Santambrogio, F. (2025). Long-time asymptotics of the sliced- W asserstein flow. SIAM Journal on Imaging Sciences , 18(1):1--19
2025
-
[7]
R., De Bortoli, V., Doucet, A., and Johansen, A
Crucinio, F. R., De Bortoli, V., Doucet, A., and Johansen, A. M. (2024). Solving F redholm integral equations of the first kind via W asserstein gradient flows. Stochastic Processes and Their Applications , 173
2024
-
[8]
Cuturi, M. (2013). Sinkhorn distances: Lightspeed computation of optimal transport. In Advances in Neural Information Processing Systems
2013
-
[9]
Deng, M., Li, H., Li, T., Du, Y., and He, K. (2026). Generative modeling via drifting. arXiv preprint arXiv:2602.04770
work page internal anchor Pith review arXiv 2026
-
[10]
K., Roy, D
Dziugaite, G. K., Roy, D. M., and Ghahramani, Z. (2015). Training generative neural networks via maximum mean discrepancy optimization. In Uncertainty in Artificial Intelligence
2015
-
[11]
Feydy, J., S \'e journ \'e , T., Vialard, F.-X., Amari, S.-i., Trouv \'e , A., and Peyr \'e , G. (2019). Interpolating between optimal transport and MMD using S inkhorn divergences. In International Conference on Artificial Intelligence and Statistics
2019
-
[12]
Franz, L., Hoffmann, S., and Martius, G. (2026). Drifting fields are not conservative. arXiv preprint arXiv:2604.06333
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Galashov, A., De Bortoli, V., and Gretton, A. (2025). Deep MMD gradient flow without adversarial training. In International Conference on Learning Representations
2025
-
[14]
Glaser, P., Arbel, M., and Gretton, A. (2021). KALE flow: A relaxed KL gradient flow for probabilities with disjoint support. In Advances in Neural Information Processing Systems
2021
-
[15]
M., Rasch, M
Gretton, A., Borgwardt, K. M., Rasch, M. J., Sch \" o lkopf, B., and Smola, A. J. (2012). A kernel two-sample test. Journal of Machine Learning Research , 13
2012
- [16]
-
[17]
A., Ruiz, D., and U c ar, B
Knight, P. A., Ruiz, D., and U c ar, B. (2014). A symmetry preserving algorithm for matrix scaling. SIAM Journal on Matrix Analysis and Applications , 35(3):931--955. hal-00569250
2014
- [18]
-
[19]
Li, Y., Swersky, K., and Zemel, R. (2015). Generative moment matching networks. In International Conference on Machine Learning
2015
- [20]
-
[21]
Liutkus, A., Simsekli, U., Majewski, S., Durmus, A., and St \"o ter, F.-R. (2019). Sliced- W asserstein flows: Nonparametric generative modeling via optimal transport and diffusions. In International Conference on Machine Learning
2019
-
[22]
Mroueh, Y., Sercu, T., and Raj, A. (2019). Sobolev descent. In International Conference on Artificial Intelligence and Statistics
2019
-
[23]
Nowozin, S., Cseke, B., and Tomioka, R. (2016). f- GAN : training generative neural samplers using variational divergence minimization. In Advances in Neural Information Processing Systems
2016
-
[24]
Ramdas, A., Trillos, N., and Cuturi, M. (2017). On W asserstein two-sample testing and related families of nonparametric tests. Entropy , 19(2)
2017
-
[25]
Santambrogio, F. (2017). \ Euclidean, metric, and Wasserstein \ gradient flows: an overview. Bulletin of Mathematical Sciences , 7(1):87--154
2017
-
[26]
Sriperumbudur, B., Fukumizu, K., and Lanckriet, G. (2011). Universality, characteristic kernels and RKHS embedding of measures. Journal of Machine Learning Research , 12:2389--2410
2011
-
[27]
Sriperumbudur, B., Gretton, A., Fukumizu, K., Lanckriet, G., and Sch \"o lkopf, B. (2010). Hilbert space embeddings and metrics on probability measures. Journal of Machine Learning Research , 11:1517--1561
2010
-
[28]
Turan, E. and Ovsjanikov, M. (2026). Generative drifting is secretly score matching: a spectral and variational perspective. arXiv preprint arXiv:2603.09936
- [29]
-
[30]
Zhou, L., Ermon, S., and Song, J. (2025). Inductive moment matching. In Proceedings of the 42nd International Conference on Machine Learning , volume 267. PMLR
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.