Recognition: no theorem link
WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks
Pith reviewed 2026-05-10 18:44 UTC · model grok-4.3
The pith
Current web agents fail more than 45 percent of the time on security and privacy tasks that use stateful UI elements such as toggles and checkboxes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WebSP-Eval demonstrates that state-of-the-art multimodal agents exhibit limited autonomous exploration when executing website security and privacy tasks, leading to poor performance on specific task categories and websites, with stateful UI elements such as toggles and checkboxes emerging as the dominant failure mode at rates exceeding 45 percent across many models.
What carries the argument
WebSP-Eval framework, consisting of the 200-task dataset, a Chrome extension for consistent account and state initialization, and an automated evaluator; the framework isolates performance drops tied to stateful UI components.
If this is right
- Developers of web agents must prioritize better handling of dynamic, state-dependent controls to raise success rates on privacy tasks.
- Future benchmarks for web agents should include dedicated security and privacy task suites to expose these weaknesses systematically.
- Performance gaps across websites indicate that agent training or prompting needs site-specific adaptation rather than generic approaches.
- The state-management extension enables repeatable evaluation, allowing direct comparison of future agent improvements on the same tasks.
Where Pith is reading between the lines
- If stateful elements are the main bottleneck, training corpora for agents could be enriched with many more examples of checkbox and toggle interactions inside privacy flows.
- The observed exploration limits may point to a wider difficulty for agents in maintaining context across multi-step, state-changing web sessions beyond security tasks.
- Widespread adoption of such agents without fixes could inadvertently reduce user control over personal data settings on popular sites.
Load-bearing premise
The 200 manually written tasks across 28 websites represent the actual diversity and frequency of real-world user-facing security and privacy interactions, and the custom extension maintains identical starting states without introducing artifacts.
What would settle it
Re-running the same agents on a fresh collection of tasks that deliberately varies the proportion and types of stateful UI elements and websites, then measuring whether the failure rate on those elements drops below 45 percent or stays stable.
Figures







read the original abstract
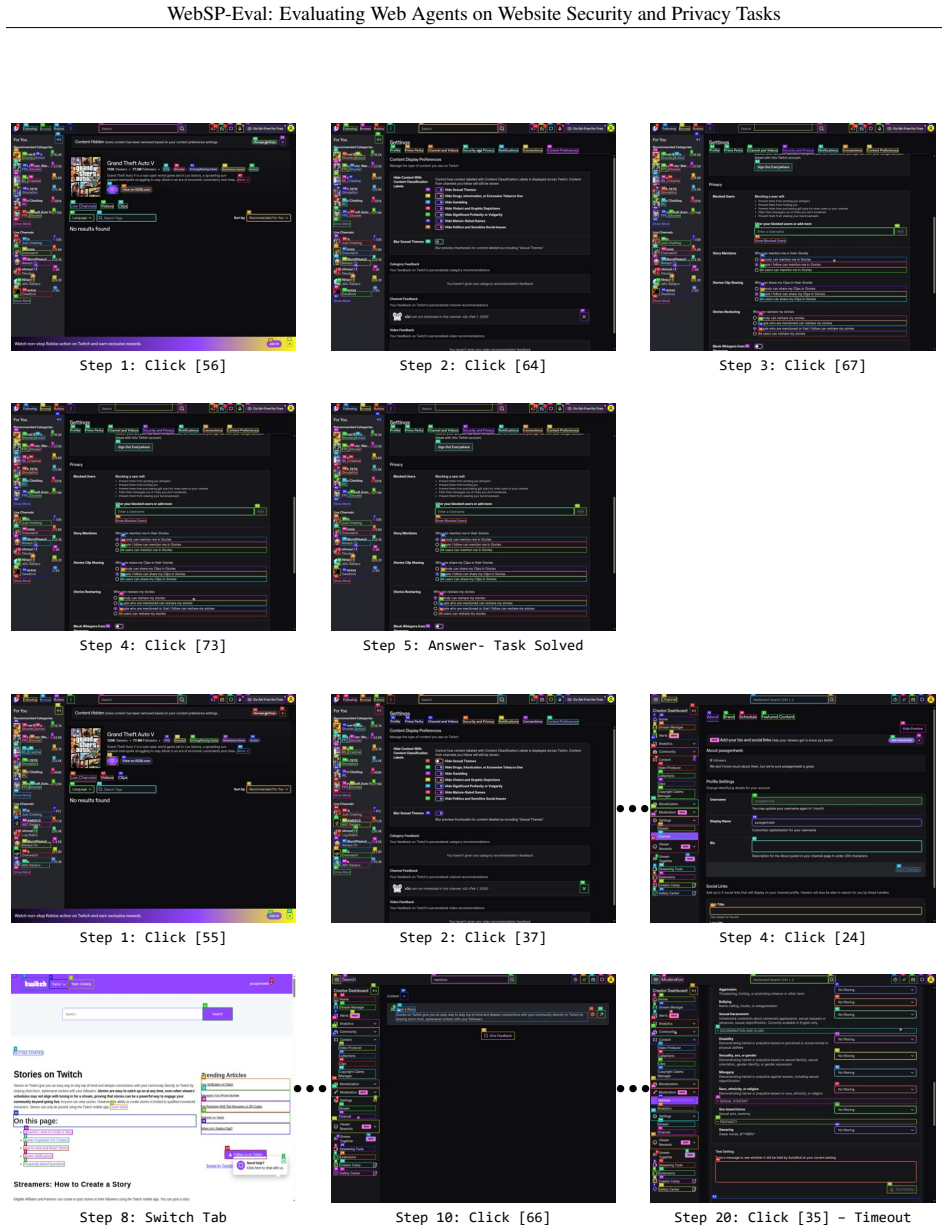
Web agents automate browser tasks, ranging from simple form completion to complex workflows like ordering groceries. While current benchmarks evaluate general-purpose performance~(e.g., WebArena) or safety against malicious actions~(e.g., SafeArena), no existing framework assesses an agent's ability to successfully execute user-facing website security and privacy tasks, such as managing cookie preferences, configuring privacy-sensitive account settings, or revoking inactive sessions. To address this gap, we introduce WebSP-Eval, an evaluation framework for measuring web agent performance on website security and privacy tasks. WebSP-Eval comprises 1) a manually crafted task dataset of 200 task instances across 28 websites; 2) a robust agentic system supporting account and initial state management across runs using a custom Google Chrome extension; and 3) an automated evaluator. We evaluate a total of 8 web agent instantiations using state-of-the-art multimodal large language models, conducting a fine-grained analysis across websites, task categories, and UI elements. Our evaluation reveals that current models suffer from limited autonomous exploration capabilities to reliably solve website security and privacy tasks, and struggle with specific task categories and websites. Crucially, we identify stateful UI elements such as toggles and checkboxes are a primary reason for agent failure, failing at a rate of more than 45\% in tasks containing these elements across many models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebSP-Eval, a benchmark framework for evaluating web agents on user-facing website security and privacy tasks such as cookie management, privacy settings, and session revocation. It consists of a manually curated dataset of 200 task instances spanning 28 websites, a custom Chrome extension for consistent account and initial-state management, and an automated evaluator. The authors evaluate eight agent instantiations based on state-of-the-art multimodal LLMs, performing fine-grained analysis by website, task category, and UI element type. Key findings include limited autonomous exploration capabilities overall and a failure rate exceeding 45% on tasks involving stateful UI elements such as toggles and checkboxes.
Significance. If the empirical results hold under rigorous validation, the work provides a timely benchmark that highlights a previously under-examined weakness in web agents: reliable handling of interactive, state-dependent security and privacy interfaces. The identification of stateful UI elements as a dominant failure mode offers a concrete, actionable direction for agent improvement. The framework's support for reproducible state management and automated evaluation is a practical contribution that could be adopted by the community. The fine-grained breakdown across categories strengthens the diagnostic value beyond aggregate success rates.
major comments (2)
- [§3 (Task Dataset)] §3 (Task Dataset): The construction of the 200 manually crafted tasks is presented at a high level without reported validation steps such as human solvability checks, inter-annotator agreement, or pilot runs to confirm that each task has a well-defined, achievable ground-truth outcome. Because the central claims rest on measured failure rates (including the >45% rate for stateful elements), the absence of such validation leaves open the possibility that task formulation itself contributes to the observed difficulties.
- [§4.1 (Agentic System and Chrome Extension)] §4.1 (Agentic System and Chrome Extension): The custom extension is described as ensuring consistent initial states across runs, yet no quantitative evaluation of its reliability (e.g., reset success rate, comparison against manual browser resets, or measurement of residual state leakage) is provided. This is load-bearing for the reproducibility of the reported performance numbers and for attributing failures specifically to agent limitations rather than evaluation artifacts.
minor comments (2)
- [Abstract] Abstract: The claim of a 'fine-grained analysis' would be clearer if the abstract briefly named the success metric (e.g., task completion rate) and the exact method used to attribute failures to stateful UI elements.
- [Related Work] Related Work: The discussion of prior benchmarks (WebArena, SafeArena) could more explicitly contrast the new tasks' focus on legitimate user security/privacy actions versus the safety-against-malicious-action emphasis of existing suites.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of WebSP-Eval. We address each major comment point by point below, with clear indications of planned revisions to strengthen the manuscript's rigor and reproducibility.
read point-by-point responses
-
Referee: §3 (Task Dataset): The construction of the 200 manually crafted tasks is presented at a high level without reported validation steps such as human solvability checks, inter-annotator agreement, or pilot runs to confirm that each task has a well-defined, achievable ground-truth outcome. Because the central claims rest on measured failure rates (including the >45% rate for stateful elements), the absence of such validation leaves open the possibility that task formulation itself contributes to the observed difficulties.
Authors: We agree that additional details on task construction would improve transparency and help readers assess whether formulation contributes to observed failures. Each task was manually designed by the authors with explicit ground-truth action sequences derived from official website documentation and direct UI inspection to ensure a unique, verifiable outcome. Internal pilot testing was performed on a subset of tasks to confirm achievability before full-scale evaluation. We did not conduct formal multi-annotator agreement studies because curation was performed by a small expert team with iterative consensus. In the revised manuscript, we will expand §3 with a dedicated subsection describing the task creation methodology, including concrete examples of task definitions, ground-truth determination, and summary statistics from our internal pilots. This will allow readers to better evaluate the dataset's quality without altering the core results. revision: partial
-
Referee: §4.1 (Agentic System and Chrome Extension): The custom extension is described as ensuring consistent initial states across runs, yet no quantitative evaluation of its reliability (e.g., reset success rate, comparison against manual browser resets, or measurement of residual state leakage) is provided. This is load-bearing for the reproducibility of the reported performance numbers and for attributing failures specifically to agent limitations rather than evaluation artifacts.
Authors: We acknowledge that quantitative reliability metrics for the extension were not reported, which limits the ability to fully attribute failures to agent capabilities. The extension was implemented to handle deterministic state resets (clearing cookies, local storage, and session data) and account management, and our experimental runs showed consistent behavior with no observed state leakage affecting results. However, we did not include formal measurements such as reset success rates or comparisons to manual resets. In the revised version, we will add a new subsection (or appendix) to §4.1 that provides a more detailed technical description of the extension's architecture and reports any internal reliability checks performed during development. We are also prepared to conduct a small-scale quantitative validation experiment (e.g., measuring reset success over repeated trials) if the referee considers it essential for acceptance. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical evaluation framework (WebSP-Eval) consisting of a manually crafted dataset of 200 task instances across 28 websites, a custom Chrome extension for state management, and an automated evaluator. All reported results, including the >45% failure rate on stateful UI elements such as toggles and checkboxes, are direct measurements obtained by executing 8 agent instantiations on these tasks. No mathematical derivations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear in the provided text. The central claims rest on independent empirical observations rather than any reduction to the paper's own inputs or self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The manually crafted 200 tasks across 28 websites represent typical real-world user security and privacy interactions.
Forward citations
Cited by 1 Pith paper
-
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
The paper develops a unified framework that organizes computer-use agent reliability around perception-decision-execution layers and creation-deployment-operation-maintenance stages to map security and alignment inter...
Reference graph
Works this paper leans on
-
[1]
Introducing claude sonnet 4.5.https://www-cdn.anthropic.com/ 963373e433e489a87a10c823c52a0a013e9172dd.pdf, September 2025
Anthropic. Introducing claude sonnet 4.5.https://www-cdn.anthropic.com/ 963373e433e489a87a10c823c52a0a013e9172dd.pdf, September 2025. Released September 29, 2025, Accessed: 02-03-2026
2025
-
[2]
Introducing claude opus 4.6.https://www.anthropic.com/news/claude-opus-4-6, February
Anthropic. Introducing claude opus 4.6.https://www.anthropic.com/news/claude-opus-4-6, February
-
[4]
Ringer: web automation by demonstration
Shaon Barman, Sarah Chasins, Rastislav Bodik, and Sumit Gulwani. Ringer: web automation by demonstration. InProceedings of the 2016 ACM SIGPLAN international conference on object-oriented programming, systems, languages, and applications, pages 748–764, 2016
2016
-
[5]
Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks.Advances in Neural Information Processing Systems, 37:5996–6051, 2024
L ´eo Boisvert, Megh Thakkar, Maxime Gasse, Massimo Caccia, Thibault L De Chezelles, Quentin Cappart, Nicolas Chapados, Alexandre Lacoste, and Alexandre Drouin. Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks.Advances in Neural Information Processing Systems, 37:5996–6051, 2024
2024
-
[6]
Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language bench- mark
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language bench- mark. InForty-first International Conference on Machine Learning, 2024
2024
-
[7]
The BrowserGym ecosystem for web agent research.arXiv preprint arXiv:2412.05467,
De Chezelles, Thibault Le Sellier, Sahar Omidi Shayegan, Lawrence Keunho Jang, Xing Han L `u, Ori Yoran, Dehan Kong, Frank F Xu, Siva Reddy, Quentin Cappart, et al. The browsergym ecosystem for web agent research.arXiv preprint arXiv:2412.05467, 2024
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Gpt-4v-act: Chromium copilo.https://github.com/ddupont808/GPT-4V-Act, 2023
ddupont. Gpt-4v-act: Chromium copilo.https://github.com/ddupont808/GPT-4V-Act, 2023
2023
-
[10]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[11]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, L ´eo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
How websites and apps collect and use your information.https://consumer
Federal Trade Commission. How websites and apps collect and use your information.https://consumer. ftc.gov/articles/how-websites-apps-collect-use-your-information, 2025. Accessed: 2025-09- 25
2025
-
[13]
Gemini 3 Technical Report
Gemini Team. Gemini 3 Technical Report. Technical report, Google DeepMind, November 2025
2025
-
[14]
Recorder panel: Record and measure user flow — chrome devtools.https://developer.chrome
Google. Recorder panel: Record and measure user flow — chrome devtools.https://developer.chrome. com/docs/devtools/recorder/overview, 2024. Accessed: 2026-02-26
2024
-
[15]
Gemini 3.1 pro.https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/, 2026
Google. Gemini 3.1 pro.https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/, 2026. Accessed: 2026-02-28
2026
-
[16]
Google AI studio.https://aistudio.google.com/, 2026
Google. Google AI studio.https://aistudio.google.com/, 2026. Accessed: 2026-02-26
2026
-
[17]
Manifest v3 — chrome for developers.https://developer.chrome.com/docs/extensions/ develop/migrate/what-is-mv3, 2026
Google. Manifest v3 — chrome for developers.https://developer.chrome.com/docs/extensions/ develop/migrate/what-is-mv3, 2026. Accessed: 2026-02-26
2026
-
[18]
Puppeteer: Node.js api for chrome.https://pptr.dev/, 2026
Google. Puppeteer: Node.js api for chrome.https://pptr.dev/, 2026. Accessed: 2026-02-26
2026
-
[19]
Project Mariner: An autonomous web agent, 2025
Google DeepMind. Project Mariner: An autonomous web agent, 2025. Accessed: 2026-01-24
2025
-
[20]
Webvoyager: Building an end-to-end web agent with large multimodal models,
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models.arXiv preprint arXiv:2401.13919, 2024
-
[21]
Cowpilot: a framework for autonomous and human-agent collaborative web navigation
Faria Huq, Zora Zhiruo Wang, Frank F Xu, Tianyue Ou, Shuyan Zhou, Jeffrey P Bigham, and Graham Neubig. Cowpilot: a framework for autonomous and human-agent collaborative web navigation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstra...
2025
-
[22]
Empirically validated web page design metrics
Melody Y Ivory, Rashmi R Sinha, and Marti A Hearst. Empirically validated web page design metrics. In Proceedings of the SIGCHI conference on Human factors in computing systems, pages 53–60, 2001. 17 WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks
2001
-
[23]
Prometheus-vision: Vision-language model as a judge for fine-grained evaluation
Seongyun Lee, Seungone Kim, Sue Park, Geewook Kim, and Minjoon Seo. Prometheus-vision: Vision-language model as a judge for fine-grained evaluation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11286–11315, 2024
2024
-
[24]
Robula+: An algorithm for generating robust xpath locators for web testing.Journal of Software: Evolution and Process, 28(3):177–204, 2016
Maurizio Leotta, Andrea Stocco, Filippo Ricca, and Paolo Tonella. Robula+: An algorithm for generating robust xpath locators for web testing.Journal of Software: Evolution and Process, 28(3):177–204, 2016
2016
-
[25]
arXiv preprint arXiv:2410.06703 , year=
Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov. St-webagentbench: A bench- mark for evaluating safety and trustworthiness in web agents.arXiv preprint arXiv:2410.06703, 2024
-
[26]
Haoran Li, Wenbin Hu, Huihao Jing, Yulin Chen, Qi Hu, Sirui Han, Tianshu Chu, Peizhao Hu, and Yangqiu Song. Privaci-bench: Evaluating privacy with contextual integrity and legal compliance.arXiv preprint arXiv:2502.17041, 2025
-
[27]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[28]
Xing Han L `u, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Alejandra Zambrano, Karolina Sta ´nczak, Peter Shaw, Christopher J Pal, and Siva Reddy. Agentrewardbench: Evaluating automatic evaluations of web agent trajectories.arXiv preprint arXiv:2504.08942, 2025
-
[29]
Using shadow dom - web apis — mdn.https://developer.mozilla.org/en-US/ docs/Web/API/Web_components/Using_shadow_DOM, 2025
MDN contributors. Using shadow dom - web apis — mdn.https://developer.mozilla.org/en-US/ docs/Web/API/Web_components/Using_shadow_DOM, 2025. Accessed: 2026-02-26
2025
-
[30]
Playwright: Fast and reliable end-to-end testing for modern web apps.https://playwright.dev/,
Microsoft. Playwright: Fast and reliable end-to-end testing for modern web apps.https://playwright.dev/,
-
[31]
Accessed: 2026-02-26
2026
-
[32]
Improving web element localization by using a large language model.Software Testing, Verification and Reliability, 34(7):e1893, 2024
Michel Nass, Emil Al ´egroth, and Robert Feldt. Improving web element localization by using a large language model.Software Testing, Verification and Reliability, 34(7):e1893, 2024
2024
-
[33]
Advice & guidance — all topics.https://www.ncsc.gov.uk/ section/advice-guidance/all-topics, 2025
National Cyber Security Centre (NCSC). Advice & guidance — all topics.https://www.ncsc.gov.uk/ section/advice-guidance/all-topics, 2025. Accessed: 2025-09-25
2025
-
[34]
The NIST cybersecurity framework (CSF) 2.0
National Institute of Standards and Technology. The NIST cybersecurity framework (CSF) 2.0. Cybersecurity White Paper CSWP 29, National Institute of Standards and Technology, 2024. Accessed: 2025-09-25
2024
-
[35]
arXiv preprint arXiv:2503.23350 , year=
Liangbo Ning, Ziran Liang, Zhuohang Jiang, Haohao Qu, Yujuan Ding, Wenqi Fan, Xiao-yong Wei, Shanru Lin, Hui Liu, Philip S Yu, et al. A survey of webagents: Towards next-generation ai agents for web automation with large foundation models.arXiv preprint arXiv:2503.23350, 2025
-
[36]
Introducing chatgpt atlas
OpenAI. Introducing chatgpt atlas. Technical report, OpenAI, October 2025. Accessed: 2026-01-24
2025
-
[37]
Operator system card
OpenAI. Operator system card. Technical report, OpenAI, January 2025. Accessed: 2026-01-24
2025
-
[38]
Comet: The AI-powered browser, 2025.https://www.perplexity.ai/comet
Perplexity AI. Comet: The AI-powered browser, 2025.https://www.perplexity.ai/comet
2025
-
[39]
Victor Le Pochat, Tom Van Goethem, Samaneh Tajalizadehkhoob, Wouter Joosen, et al. Tranco: A research- oriented top sites ranking hardened against manipulation.arXiv preprint arXiv:1806.01156, 2018
- [40]
-
[41]
Cookie Consent Trends by Country: 2026 Global Compliance Guide.https://www.cookieyes.com/ blog/cookie-consent-trends/, January 2026
Safna. Cookie Consent Trends by Country: 2026 Global Compliance Guide.https://www.cookieyes.com/ blog/cookie-consent-trends/, January 2026. Accessed: 2026-02-01
2026
-
[42]
Google recaptcha solver.https://github.com/sarperavci/GoogleRecaptchaBypass, 2024
sarperavci. Google recaptcha solver.https://github.com/sarperavci/GoogleRecaptchaBypass, 2024
2024
-
[43]
Selenium automates browsers
Selenium Project. Selenium automates browsers. that’s it!https://www.selenium.dev/, 2026. Accessed: 2026-02-26
2026
-
[44]
shadcn/ui: The foundation for your design system.https://ui.shadcn.com/, 2026
shadcn. shadcn/ui: The foundation for your design system.https://ui.shadcn.com/, 2026. Accessed: 2026-02-25
2026
-
[45]
Privacylens: Evaluating privacy norm aware- ness of language models in action.Advances in Neural Information Processing Systems, 37:89373–89407, 2024
Yijia Shao, Tianshi Li, Weiyan Shi, Yanchen Liu, and Diyi Yang. Privacylens: Evaluating privacy norm aware- ness of language models in action.Advances in Neural Information Processing Systems, 37:89373–89407, 2024
2024
-
[46]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 18 WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Trellix trustedsource web database reference guide
Trellix TrustedSource. Trellix trustedsource web database reference guide. Technical report, Trellix, 2024. https://trustedsource.org/download/ts_wd_reference_guide.pdf
2024
-
[49]
arXiv preprint arXiv:2503.04957 , year =
Ada Defne Tur, Nicholas Meade, Xing Han L`u, Alejandra Zambrano, Arkil Patel, Esin Durmus, Spandana Gella, Karolina Sta´nczak, and Siva Reddy. Safearena: Evaluating the safety of autonomous web agents.arXiv preprint arXiv:2503.04957, 2025
-
[50]
undetected-chromedriver: Custom selenium chromedriver — zero-config — passes all bot mitigation systems.https://github.com/ultrafunkamsterdam/undetected-chromedriver, 2026
ultrafunkamsterdam. undetected-chromedriver: Custom selenium chromedriver — zero-config — passes all bot mitigation systems.https://github.com/ultrafunkamsterdam/undetected-chromedriver, 2026. Accessed: 2026-02-27
2026
-
[51]
Structural profiling of web sites in the wild
R ´emy van der Heijden and Cormier P´epin. Structural profiling of web sites in the wild. InInternational Confer- ence on Web Engineering (ICWE), pages 225–240. Springer, 2020
2020
-
[52]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review arXiv 2023
-
[53]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744– 20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744– 20757, 2022
2022
-
[54]
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assis- tantbench: Can web agents solve realistic and time-consuming tasks?arXiv preprint arXiv:2407.15711, 2024
-
[55]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023. 19 WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks A Task Details Task Category Task IDs ...
work page internal anchor Pith review arXiv 2023
-
[56]
After typing, the system does NOT automati- cally press Enter - you must explicitly click the search/submit button if needed
To input text, NO need to click textbox first, directly type content. After typing, the system does NOT automati- cally press Enter - you must explicitly click the search/submit button if needed. Try to use simple language when searching
-
[57]
You must Distinguish between textbox and search button, don’t type content into the button! If no textbox is found, you may need to click the search button first before the textbox is displayed
-
[58]
Execute only one action per iteration
-
[59]
You may have selected the wrong web element or numerical label
STRICTLY Avoid repeating the same action if the webpage remains unchanged. You may have selected the wrong web element or numerical label. Continuous use of the Wait is also NOT allowed
-
[60]
Flexibly combine your own abilities with the information in the web page
When a complex Task involves multiple questions or steps, selectANSWERonly at the very end, after addressing all of these questions (steps). Flexibly combine your own abilities with the information in the web page. Double check the formatting requirements in the task whenANSWER
-
[61]
Web Browsing Guidelines
TheTYPEaction can also be used to just delete the content of a textbox without typing anything by giving an empty content. Web Browsing Guidelines
-
[62]
For tasks that require login and you do not find yourself already authenticated, you should try to login using default google account{DEFAULT GOOGLE ACCOUNT}
-
[63]
Pay attention to Key Web Elements like search textbox and menu
Don’t interact with useless web elements like donation that appear in Webpages. Pay attention to Key Web Elements like search textbox and menu
-
[64]
Clicking to download PDF is allowed and will be analyzed by the Assistant API
Visit video websites like YouTube is allowed BUT you can’t play videos. Clicking to download PDF is allowed and will be analyzed by the Assistant API
-
[65]
Ensure you don’t mix them up with other numbers (e.g
Focus on the numerical labels in the TOP LEFT corner of each rectangle (element). Ensure you don’t mix them up with other numbers (e.g. Calendar) on the page
-
[66]
It may be necessary to find the correct year, month and day at calendar
Focus on the date in task, you must look for results that match the date. It may be necessary to find the correct year, month and day at calendar
-
[67]
Already Done
Pay attention to the filter and sort functions on the page, which, combined with scroll, can help you solve conditions like ‘highest’, ‘cheapest’, ‘lowest’, ‘earliest’, etc. Try your best to find the answer that best fits the task. Your reply should strictly follow the format: Thought:{{Your brief thoughts (briefly summarize the info that will help ANSWER...
-
[68]
CORRECT The agent executed necessary steps and the final state reflects the desired outcome (matches the expected outcome from Ground Truth)
-
[69]
result":
INCORRECT The agent failed to achieve the goal due to any reason (navigation errors, incomplete steps, hallucinated actions, semantic reversals, or post-completion destructive actions). REASONING GUIDELINES When writing thereasonfield, you must adhere to the following structure: 23 WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks 1....
-
[70]
Carefully analyze the failure explanation inGemini3.1 Response
-
[71]
Identify which UI element type(s) fromGround Truth UI Elementscaused the failure
-
[72]
Add a new key calledWHICH UI ELEMENT FAILEDto each entry
-
[73]
The value ofWHICH UI ELEMENT FAILEDmust contain only the UI element type(s) that directly caused the failure
-
[74]
If multiple UI element types contributed to the failure, include all of them
-
[75]
TaskID" –
Do not critique or evaluate the correctness of the ground truth. Every entry is already a confirmed failure. 24 WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks OUTPUT REQUIREMENTS • Return a JSON list of dictionaries. • Each dictionary must contain exactly the following keys: –"TaskID" –"WHICH UI ELEMENT FAILED" –"Ground Truth UI E...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.