Recognition: 2 theorem links
· Lean TheoremThe Master Key Hypothesis: Unlocking Cross-Model Capability Transfer via Linear Subspace Alignment
Pith reviewed 2026-05-10 18:32 UTC · model grok-4.3
The pith
The Master Key Hypothesis claims that capabilities are directions in a low-dimensional subspace transferable across models by linear alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose the Master Key Hypothesis, which states that model capabilities correspond to directions in a low-dimensional latent subspace that induce specific behaviors and are transferable across models through linear alignment. Based on this hypothesis, we introduce UNLOCK, a training-free and label-free framework that extracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation, and applies it at inference time to elicit the behavior. Experiments show that this leads to substantial gains in reasoning tasks across model scales, with success depending on pre-
What carries the argument
The capability direction extracted via activation contrasting and aligned through low-rank linear transformation to transfer behaviors across models.
Load-bearing premise
Contrasting activations between variants with and without a capability isolates a pure, transferable direction free from unrelated behaviors or model-specific artifacts.
What would settle it
A test where the extracted direction fails to improve target model performance on the intended task when applied, particularly if the contrast captures scale-specific or artifactual differences instead.
Figures



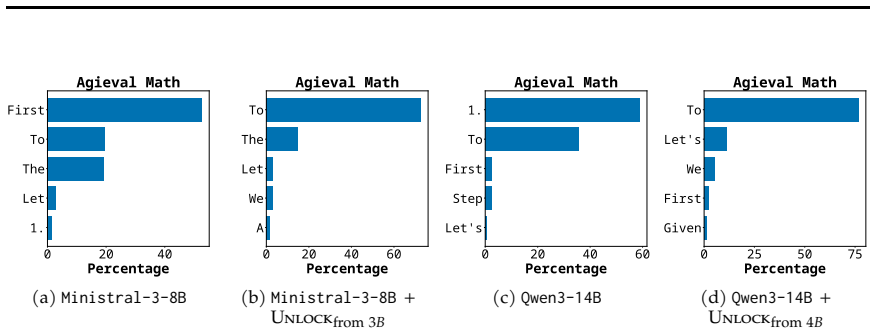

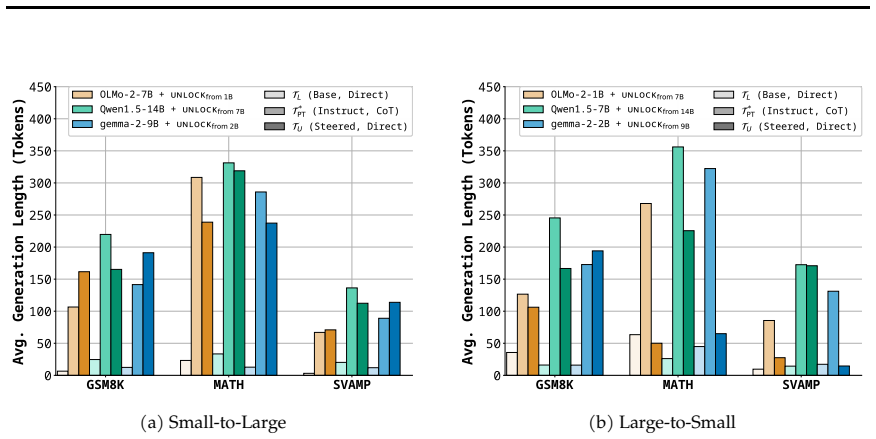

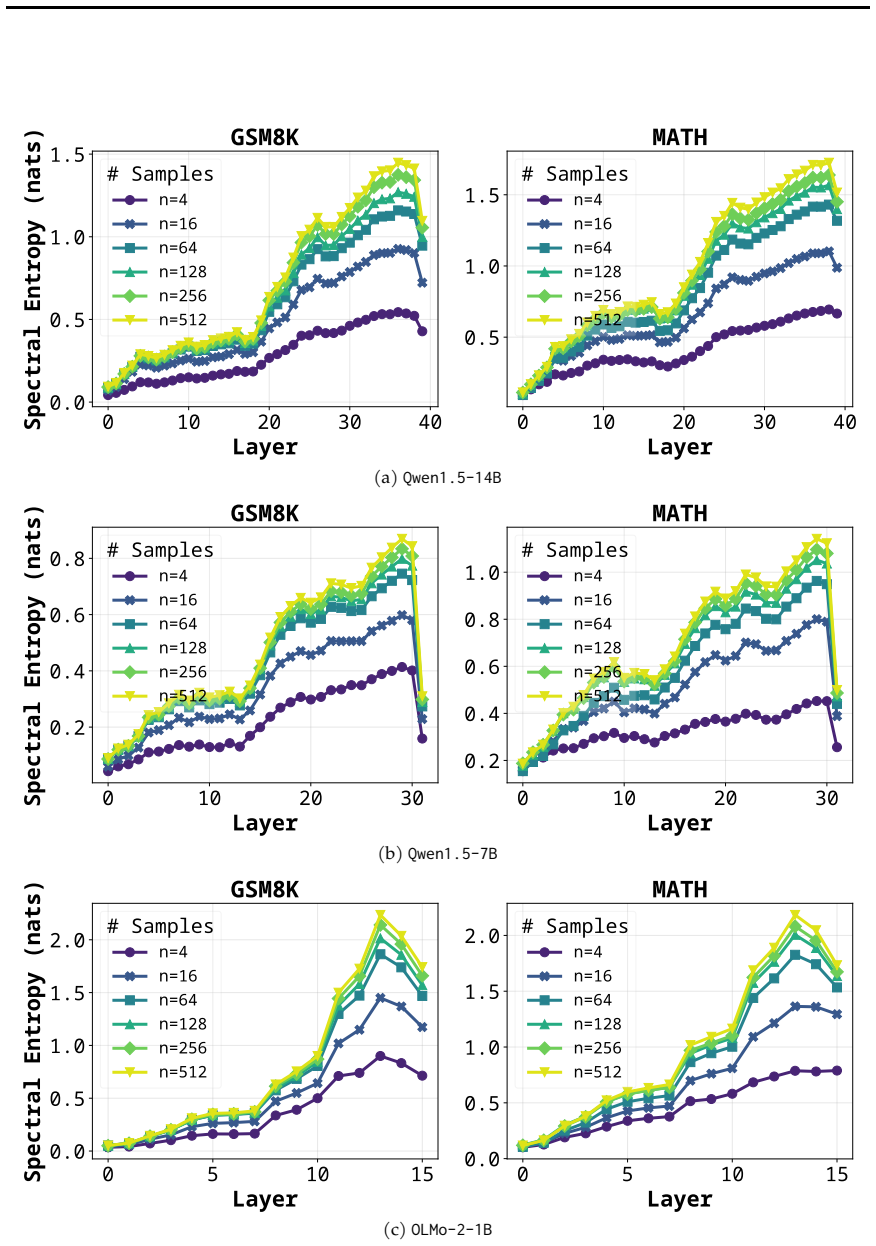
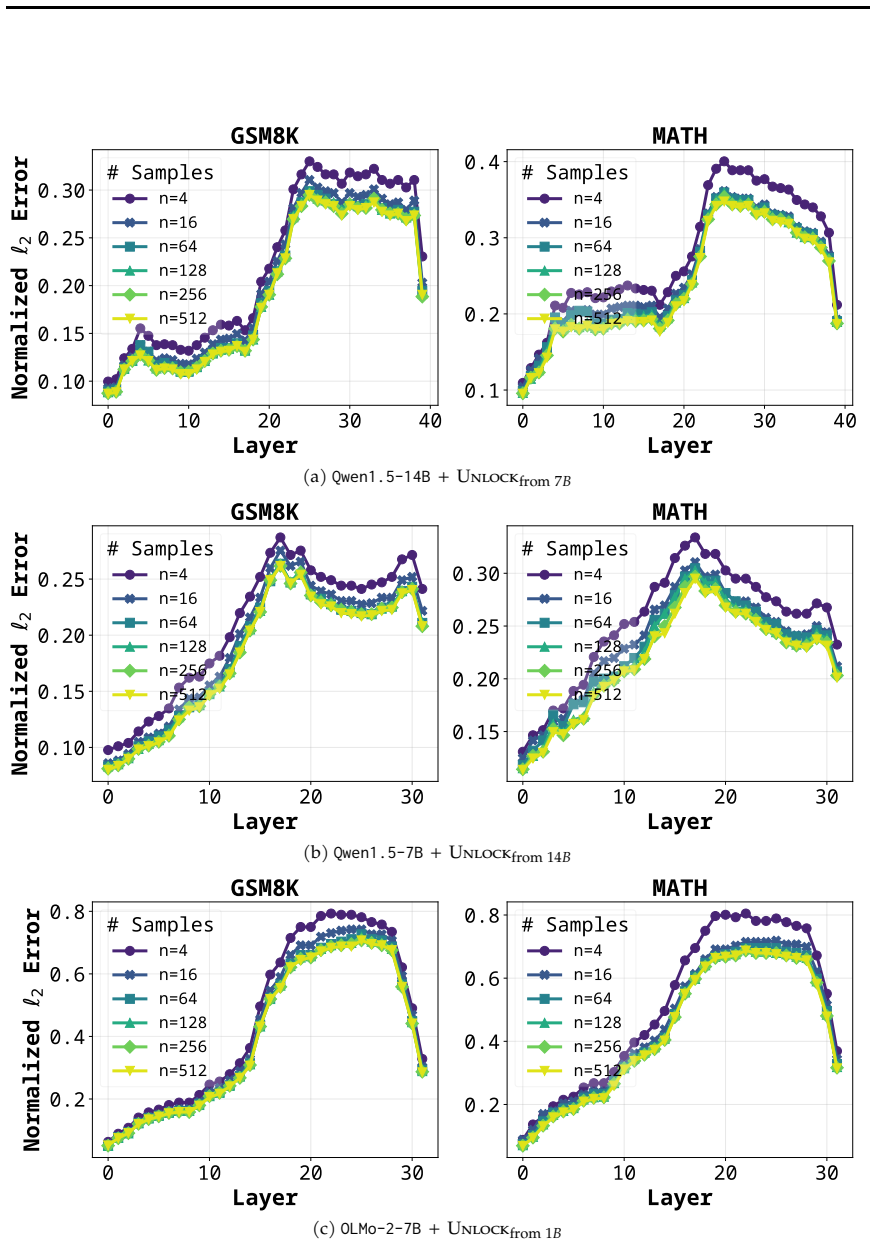

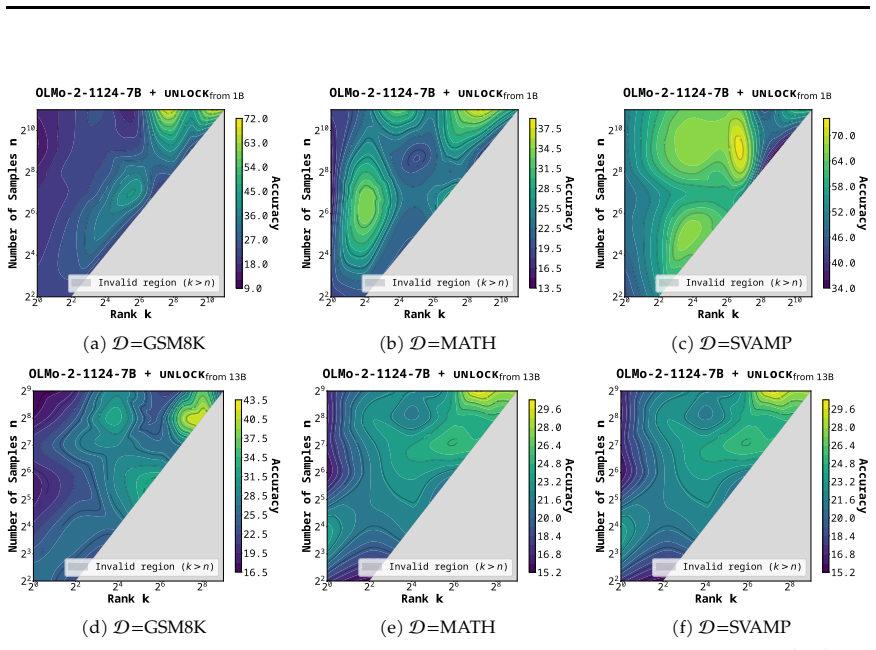
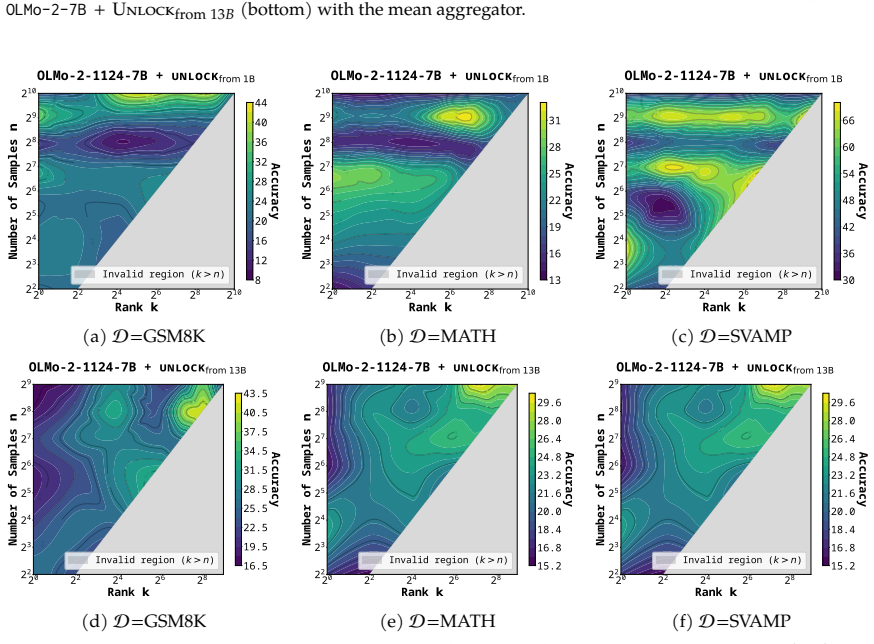

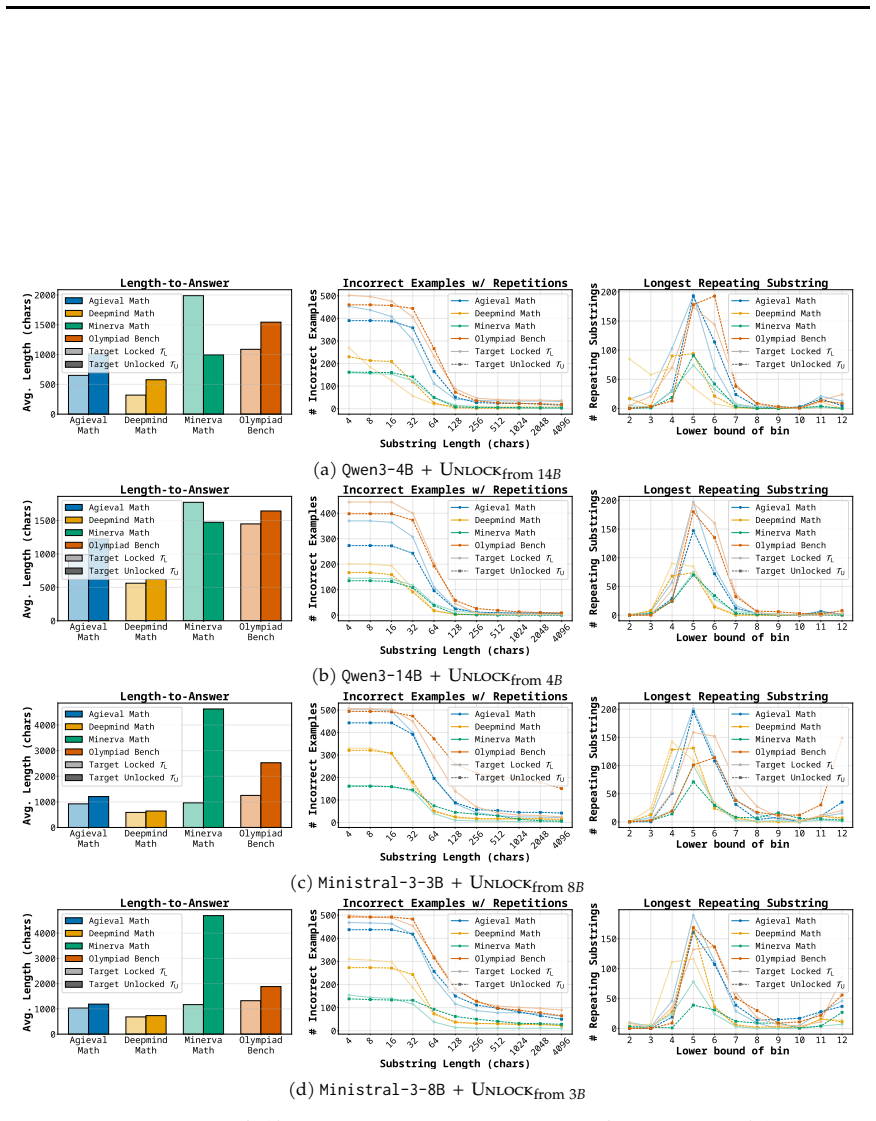
read the original abstract
We investigate whether post-trained capabilities can be transferred across models without retraining, with a focus on transfer across different model scales. We propose the Master Key Hypothesis, which states that model capabilities correspond to directions in a low-dimensional latent subspace that induce specific behaviors and are transferable across models through linear alignment. Based on this hypothesis, we introduce UNLOCK, a training-free and label-free framework that extracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation, and applies it at inference time to elicit the behavior. Experiments on reasoning behaviors, including Chain-of-Thought (CoT) and mathematical reasoning, demonstrate substantial improvements across model scales without training. For example, transferring CoT reasoning from Qwen1.5-14B to Qwen1.5-7B yields an accuracy gain of 12.1% on MATH, and transferring a mathematical reasoning direction from Qwen3-4B-Base to Qwen3-14B-Base improves AGIEval Math accuracy from 61.1% to 71.3%, surpassing the 67.8% achieved by the 14B post-trained model. Our analysis shows that the success of transfer depends on the capabilities learned during pre-training, and that our intervention amplifies latent capabilities by sharpening the output distribution toward successful reasoning trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Master Key Hypothesis that model capabilities correspond to directions in a low-dimensional latent subspace, transferable across models via linear alignment. It introduces the training-free UNLOCK framework, which extracts a capability direction by contrasting activations between capability-present and capability-absent source variants, aligns it to a target model using a low-rank linear transformation, and applies the direction at inference to elicit the behavior. Experiments on reasoning tasks report gains such as 12.1% accuracy improvement on MATH when transferring CoT from Qwen1.5-14B to Qwen1.5-7B, and improvement on AGIEval Math from 61.1% to 71.3% when transferring from Qwen3-4B-Base to Qwen3-14B-Base (surpassing the post-trained 14B baseline of 67.8%). The analysis notes that transfer success depends on pre-training capabilities.
Significance. If the central claim holds, the work would demonstrate a practical, training-free approach to cross-scale capability transfer grounded in linear subspace alignment, with potential implications for efficient model adaptation and mechanistic interpretability. The empirical results on external benchmarks (MATH, AGIEval) and the observation that intervention amplifies latent pre-trained capabilities provide concrete evidence worth further investigation; the training-free and label-free design is a notable strength.
major comments (3)
- [Abstract / UNLOCK framework] Abstract and methods description of UNLOCK: the core claim that activation contrast between capability-present and capability-absent source variants isolates a pure, transferable capability direction (rather than a mixture of post-training differences, scale artifacts, or unrelated behaviors) is load-bearing for the Master Key Hypothesis but lacks supporting controls or ablations; the reported gains (e.g., +12.1% MATH, +10.2% AGIEval Math) could arise from incidental effects of the contrast without demonstrating subspace alignment.
- [Abstract] Abstract: the claim that the method 'surpasses the 67.8% achieved by the 14B post-trained model' and yields substantial improvements across scales is not accompanied by error bars, full baseline details, or exclusion criteria, undermining the ability to assess whether the linear alignment step is responsible for the effect rather than other factors.
- [Analysis] Analysis section: while the paper states that success depends on capabilities learned during pre-training, this dependence is not quantified with specific metrics, ablation studies, or comparisons that would test whether the extracted direction is independent of scale-specific representational differences.
minor comments (2)
- [Abstract / Experiments] The abstract and experiments section would benefit from explicit reporting of variance across runs and precise definitions of 'capability-present' vs. 'capability-absent' source variants for each transfer pair.
- [Methods] Notation for the low-rank linear transformation and activation contrast operation could be clarified with an equation or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below. We outline specific revisions that will be incorporated to address the concerns while preserving the core contributions of the Master Key Hypothesis and UNLOCK framework.
read point-by-point responses
-
Referee: [Abstract / UNLOCK framework] Abstract and methods description of UNLOCK: the core claim that activation contrast between capability-present and capability-absent source variants isolates a pure, transferable capability direction (rather than a mixture of post-training differences, scale artifacts, or unrelated behaviors) is load-bearing for the Master Key Hypothesis but lacks supporting controls or ablations; the reported gains (e.g., +12.1% MATH, +10.2% AGIEval Math) could arise from incidental effects of the contrast without demonstrating subspace alignment.
Authors: We agree that additional controls are needed to isolate the contribution of the capability-specific contrast. The manuscript already shows that transfer succeeds only when the target possesses relevant pre-trained capabilities and fails otherwise, providing indirect support for specificity. In the revised version, we will add explicit ablations: (i) contrasts derived from unrelated behaviors, (ii) random activation differences of matched magnitude, and (iii) direct activation transfer without the low-rank alignment step. These will quantify that only the capability contrast produces the reported gains, thereby strengthening the evidence for linear subspace alignment. revision: yes
-
Referee: [Abstract] Abstract: the claim that the method 'surpasses the 67.8% achieved by the 14B post-trained model' and yields substantial improvements across scales is not accompanied by error bars, full baseline details, or exclusion criteria, undermining the ability to assess whether the linear alignment step is responsible for the effect rather than other factors.
Authors: We concur that error bars, expanded baselines, and clearer exclusion criteria would improve interpretability. In the revised manuscript, we will report standard deviations across multiple evaluation seeds for the primary results, add baselines including no-alignment activation addition, random-direction interventions, and scale-matched controls, and explicitly state the model-pair selection criteria (pre-training data overlap and capability presence). These additions will allow readers to isolate the role of the linear alignment step. revision: yes
-
Referee: [Analysis] Analysis section: while the paper states that success depends on capabilities learned during pre-training, this dependence is not quantified with specific metrics, ablation studies, or comparisons that would test whether the extracted direction is independent of scale-specific representational differences.
Authors: The current analysis demonstrates the dependence qualitatively through successful versus failed transfers on models with differing pre-training exposure. To quantify this, the revised analysis section will include cosine similarity between source and target capability directions as a metric of alignment quality, plus controlled ablations across model families with systematically varied pre-training corpora. These additions will provide measurable evidence that the extracted direction is not reducible to scale-specific artifacts. revision: yes
Circularity Check
No significant circularity: empirical hypothesis and method with external validation
full rationale
The paper proposes the Master Key Hypothesis as a conceptual statement and defines the UNLOCK framework as a concrete, training-free procedure that extracts directions via activation contrasts between source variants, applies low-rank linear alignment, and evaluates on external benchmarks such as MATH and AGIEval. No equations are presented that derive the hypothesis from itself or rename fitted parameters as predictions. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central steps (contrast extraction and linear transfer) are operational definitions tested against held-out data rather than tautological reductions, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank of linear transformation
axioms (2)
- domain assumption Model capabilities correspond to directions in a low-dimensional latent subspace.
- domain assumption A low-rank linear transformation can align these directions across models of different scales.
invented entities (1)
-
capability direction (Master Key)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearextracts a capability direction by contrasting activations between capability-present and capability-absent Source variants, aligns it with a Target model through a low-rank linear transformation
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearlow-dimensional latent subspace... linear alignment map f : ℝ^k → ℝ^k
Reference graph
Works this paper leans on
-
[1]
W. U. Ahmad, S. Majumdar, A. Ficek, S. Narenthiran, M. Samadi, J. Huang, S. Jain, V. Noroozi, and B. Ginsburg. Opencodereasoning-ii: A simple test time scaling approach via self-critique,
- [2]
- [3]
-
[4]
J. E. Anton de la Fuente. Thought editing: Steering models by editing their chain of thought, 2026. URL https://www.lesswrong.com/posts/KXR5FNs4hHT5sMRti/ steering-models-by-editing-their-chain-of-thought
2026
-
[5]
Arditi, O
A. Arditi, O. Obeso, A. Syed, D. Paleka, N. Panickssery, W. Gurnee, and N. Nanda. Refusal in language models is mediated by a single direction, 2024. URLhttps://arxiv.org/abs/2406. 11717
2024
-
[6]
Activationsteeringforchain-of-thoughtcompression,
S.Azizi,E.B.Potraghloo,andM.Pedram. Activationsteeringforchain-of-thoughtcompression,
- [7]
-
[8]
J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. URL https://arxiv.org/abs/2309. 16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [9]
- [10]
-
[11]
P. Buzzega, R. Salami, A. Porrello, and S. Calderara. Rethinking layer-wise model merging through chain of merges, 2025. URLhttps://arxiv.org/abs/2508.21421
-
[12]
arXiv preprint arXiv:2503.08727 , year=
L.Caccia,A.Ansell,E.Ponti,I.Vulić,andA.Sordoni. Trainingplug-n-playknowledgemodules with deep context distillation, 2025. URLhttps://arxiv.org/abs/2503.08727
- [13]
-
[15]
URLhttps://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Csordás, C
R. Csordás, C. D. Manning, and C. Potts. Do language models use their depth efficiently? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=Kz6eUL86XP
2025
-
[17]
G. Cui, Y. Zhang, J. Chen, L. Yuan, Z. Wang, Y. Zuo, H. Li, Y. Fan, H. Chen, W. Chen, Z. Liu, H. Peng, L. Bai, W. Ouyang, Y. Cheng, B. Zhou, and N. Ding. The entropy mechanism of reinforcement learning for reasoning language models, 2025. URLhttps://arxiv.org/abs/ 2505.22617
work page internal anchor Pith review arXiv 2025
-
[18]
Nudging: Inference-timealignmentofllmsviaguideddecoding,
Y.Fei,Y.Razeghi,andS.Singh. Nudging: Inference-timealignmentofllmsviaguideddecoding,
- [19]
-
[20]
A. Ghandeharioun, A. Caciularu, A. Pearce, L. Dixon, and M. Geva. Patchscopes: A unifying framework for inspecting hidden representations of language models, 2024. URLhttps:// arxiv.org/abs/2401.06102
-
[21]
Y. Gu, L. Dong, F. Wei, and M. Huang. Minillm: Knowledge distillation of large language models, 2025. URLhttps://arxiv.org/abs/2306.08543
work page internal anchor Pith review arXiv 2025
-
[22]
W. Gurnee and M. Tegmark. Language models represent space and time, 2024. URLhttps: //arxiv.org/abs/2310.02207. 16
-
[23]
C. He, R. Luo, Y. Bai, S. Hu, Z. L. Thai, J. Shen, J. Hu, X. Han, Y. Huang, Y. Zhang, J. Liu, L. Qi, Z. Liu, and M. Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024. URLhttps://arxiv.org/abs/ 2402.14008
work page internal anchor Pith review arXiv 2024
-
[25]
URLhttps://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Thereasoning-memorizationinterplayinlanguage models is mediated by a single direction, 2025
Y.Hong,D.Zhou,M.Cao,L.Yu,andZ.Jin. Thereasoning-memorizationinterplayinlanguage models is mediated by a single direction, 2025. URLhttps://arxiv.org/abs/2503.23084
-
[27]
S.-C. Huang, P.-Z. Li, Y.-C. Hsu, K.-M. Chen, Y. T. Lin, S.-K. Hsiao, R. T.-H. Tsai, and H. yi Lee. Chat vector: A simple approach to equip llms with instruction following and model alignment in new languages, 2024. URLhttps://arxiv.org/abs/2310.04799
- [28]
-
[29]
The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024
M.Huh,B.Cheung,T.Wang,andP.Isola. Theplatonicrepresentationhypothesis.arXivpreprint arXiv:2405.07987, 2024. URLhttps://arxiv.org/abs/2405.07987
-
[30]
Reinforcement Learning via Self-Distillation
J. Hübotter, F. Lübeck, L. Behric, A. Baumann, M. Bagatella, D. Marta, I. Hakimi, I. Shenfeld, T. K. Buening, C. Guestrin, and A. Krause. Reinforcement learning via self-distillation, 2026. URLhttps://arxiv.org/abs/2601.20802
work page internal anchor Pith review arXiv 2026
-
[31]
Editing Models with Task Arithmetic
G.Ilharco,M.T.Ribeiro,M.Wortsman,S.Gururangan,L.Schmidt,H.Hajishirzi,andA.Farhadi. Editing models with task arithmetic, 2023. URLhttps://arxiv.org/abs/2212.04089
work page internal anchor Pith review arXiv 2023
-
[32]
arXiv preprint arXiv:2512.05117 (2025)
P.Kaushik,S.Chaudhari,A.Vaidya,R.Chellappa,andA.Yuille. Theuniversalweightsubspace hypothesis, 2025. URLhttps://arxiv.org/abs/2512.05117
-
[33]
Konen, S
K. Konen, S. Jentzsch, D. Diallo, P. Schütt, O. Bensch, R. E. Baff, D. Opitz, and T. Hecking. Style vectors for steering generative large language model, 2024. URLhttps://arxiv.org/abs/2402. 01618
2024
-
[34]
Solving Quantitative Reasoning Problems with Language Models
A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V. Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo, Y. Wu, B. Neyshabur, G. Gur-Ari, and V. Misra. Solving quantitative reasoning problems with language models, 2022. URLhttps://arxiv.org/abs/ 2206.14858
work page internal anchor Pith review arXiv 2022
- [35]
-
[36]
arXiv preprint arXiv:2401.08190
M.Liao,W.Luo,C.Li,J.Wu,andK.Fan. Mario: Mathreasoningwithcodeinterpreteroutput–a reproducible pipeline.arXiv preprint arXiv:2401.08190, 2024
- [37]
-
[38]
A. H. Liu, K. Khandelwal, S. Subramanian, V. Jouault, A. Rastogi, A. Sadé, A. Jeffares, A. Jiang, A. Cahill, A. Gavaudan, A. Sablayrolles, A. Héliou, A. You, A. Ehrenberg, A. Lo, A. Eliseev, A. Calvi, A. Sooriyarachchi, B. Bout, B. Rozière, B. D. Monicault, C. Lanfranchi, C. Barreau, C. Courtot, D. Grattarola, D. Dabert, D. de las Casas, E. Chane-Sane, F....
work page internal anchor Pith review arXiv 2026
-
[39]
Midtrainingbridgespretrainingandposttrainingdistributions,
E.Liu,G.Neubig,andC.Xiong. Midtrainingbridgespretrainingandposttrainingdistributions,
- [40]
- [41]
- [42]
-
[43]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space, 2013. URLhttps://arxiv.org/abs/1301.3781
work page internal anchor Pith review arXiv 2013
-
[44]
D. Nguyen, A. Prasad, E. Stengel-Eskin, and M. Bansal. Grains: Gradient-based attribution for inference-time steering of llms and vlms.arXiv preprint arXiv:2507.18043, 2025. URL https://arxiv.org/abs/2507.18043
-
[45]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y. Gu, S. Huang, M.Jordan,N.Lambert,D.Schwenk,O.Tafjord,T.Anderson,D.Atkinson,F.Brahman,C.Clark, P. Dasigi, N. Dziri, A. Ettinger, M. Guerquin, D. Heineman, H. Ivison, P. W. Koh, J. Liu, S. Malik, W.Merrill,L.J.V.Miranda,J.Morrison,T.Murray,C.Nam,J.Poznanski,V.Pyatkin,A.Rangapur, M...
work page internal anchor Pith review arXiv 2025
- [46]
-
[47]
RAST: reasoning activation in llms via small-model transfer
S. Ouyang, X. Zhu, Z. Xiao, M. Jiang, Y. Meng, and J. Han. Rast: Reasoning activation in llms via small-model transfer, 2025. URLhttps://arxiv.org/abs/2506.15710
-
[48]
Steering Llama 2 via Contrastive Activation Addition
N. Panickssery, N. Gabrieli, J. Schulz, M. Tong, E. Hubinger, and A. M. Turner. Steering llama 2 via contrastive activation addition, 2024. URLhttps://arxiv.org/abs/2312.06681
work page internal anchor Pith review arXiv 2024
-
[49]
K. Park, Y. J. Choe, and V. Veitch. The linear representation hypothesis and the geometry of large language models, 2024. URLhttps://arxiv.org/abs/2311.03658
work page internal anchor Pith review arXiv 2024
-
[50]
Are NLP Models really able to Solve Simple Math Word Problems?
A. Patel, S. Bhattamishra, and N. Goyal. Are NLP models really able to solve simple math word problems? In K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, and Y. Zhou, editors,Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: ...
- [51]
-
[52]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z. Zhang, and Z...
-
[54]
Analysing mathematical reasoning abilities of neural models
D. Saxton, E. Grefenstette, F. Hill, and P. Kohli. Analysing mathematical reasoning abilities of neural models, 2019. URLhttps://arxiv.org/abs/1904.01557
- [55]
-
[56]
Self-distillationenablescontinuallearning,
I.Shenfeld, M.Damani, J.Hübotter, andP.Agrawal. Self-distillationenablescontinuallearning,
-
[57]
URLhttps://arxiv.org/abs/2601.19897
work page internal anchor Pith review arXiv
-
[58]
O. Skean, M. R. Arefin, D. Zhao, N. Patel, J. Naghiyev, Y. LeCun, and R. Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models, 2025. URLhttps://arxiv.org/ abs/2502.02013
- [59]
-
[60]
Improvinginstruction-following in language models through activation steering, 2025
A.Stolfo,V.Balachandran,S.Yousefi,E.Horvitz,andB.Nushi. Improvinginstruction-following in language models through activation steering, 2025. URLhttps://arxiv.org/abs/2410. 12877
2025
-
[61]
D. Tan, D. Chanin, A. Lynch, D. Kanoulas, B. Paige, A. Garriga-Alonso, and R. Kirk. Analyzing the generalization and reliability of steering vectors, 2025. URLhttps://arxiv.org/abs/2407. 12404
2025
-
[62]
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024. URLhttps://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivière, L. Rouillard, T. Mesnard, G. Cideron, J. bastien Grill, S. Ramos, E. Yvinec, M. Casbon, E. Pot, I. Penchev, G. Liu, F. Visin, K. Kenealy, L. Beyer, X. Zhai, A. Tsitsulin, R. Busa-Fekete, A. Feng, N. Sachdeva, B. Coleman, Y. Gao, B. Mustafa, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [65]
-
[66]
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid. Steering language models with activation engineering, 2024. URLhttps://arxiv.org/abs/ 2308.10248
work page internal anchor Pith review arXiv 2024
-
[67]
T. van der Weij, M. Poesio, and N. Schoots. Extending activation steering to broad skills and multiple behaviours, 2024. URLhttps://arxiv.org/abs/2403.05767. 19
-
[68]
Base models know how to reason, thinking models learn when.arXiv preprint arXiv:2510.07364,
C. Venhoff, I. Arcuschin, P. Torr, A. Conmy, and N. Nanda. Base models know how to reason, thinking models learn when, 2025. URLhttps://arxiv.org/abs/2510.07364
-
[69]
arXiv preprint arXiv:2506.18167 , year=
C.Venhoff,I.Arcuschin,P.Torr,A.Conmy,andN.Nanda. Understandingreasoninginthinking language models via steering vectors, 2025. URLhttps://arxiv.org/abs/2506.18167
-
[70]
E. P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y. Gu, S. Huang, M. Jordan, N. Lambert, D. Schwenk, O. Tafjord, T. Anderson, D. Atkinson, F. Brahman, C. Clark, P. Dasigi, N. Dziri, A. Ettinger, M. Guerquin, D. Heineman, H. Ivison, P. W. Koh, J. Liu, S. Malik, W. Mer- rill, L. J. V. Miranda, J. Morrison, T. Murray, C. Nam, J. Poznanski...
2025
-
[71]
F. Wan, L. Zhong, Z. Yang, R. Chen, and X. Quan. Fusechat: Knowledge fusion of chat models,
- [72]
- [73]
- [74]
-
[75]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X. Chen, J. Yang, Z. Zhang, Y. Liu, A. Yang, A. Zhao, Y. Yue, S. Song, B. Yu, G. Huang, and J. Lin. Beyond the 80/20 rule: High- entropy minority tokens drive effective reinforcement learning for llm reasoning, 2025. URL https://arxiv.org/abs/2506.01939
work page internal anchor Pith review arXiv 2025
- [76]
-
[77]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URLhttps: //arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [78]
-
[79]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. URLhttps://arxiv.org/abs/ 2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025. URLhttps://arxiv.org/abs/ 2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[81]
Y. Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, Y. Yue, S. Song, and G. Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?, 2025. URL https://arxiv.org/abs/2504.13837
work page internal anchor Pith review arXiv 2025
- [82]
-
[83]
W. Zhong, R. Cui, Y. Guo, Y. Liang, S. Lu, Y. Wang, A. Saied, W. Chen, and N. Duan. Agieval: A human-centric benchmark for evaluating foundation models, 2023. URLhttps://arxiv.org/ abs/2304.06364
-
[84]
Watch the Weights: Unsupervised monitoring and control of fine-tuned LLMs
Z. Zhong and A. Raghunathan. Watch the weights: Unsupervised monitoring and control of fine-tuned llms, 2025. URLhttps://arxiv.org/abs/2508.00161
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.