Recognition: 2 theorem links
· Lean TheoremWhen Is Thinking Enough? Early Exit via Sufficiency Assessment for Efficient Reasoning
Pith reviewed 2026-05-10 17:56 UTC · model grok-4.3
The pith
A framework lets large reasoning models stop their chain-of-thought early by checking its own sufficiency, cutting length 29-35 percent with little accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
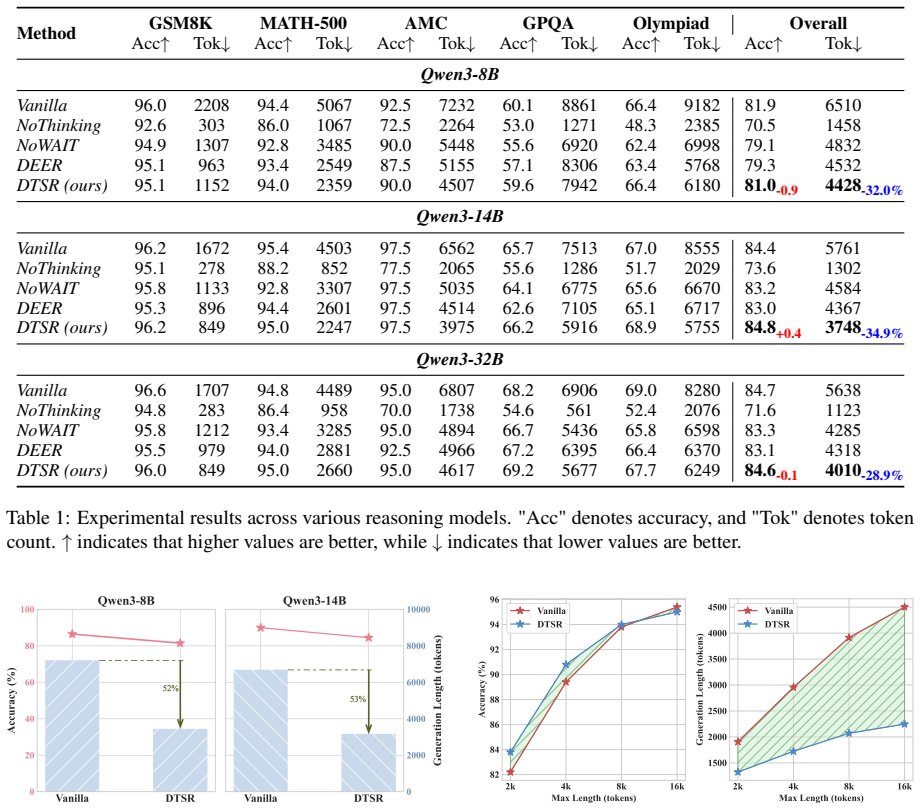
Dynamic Thought Sufficiency in Reasoning (DTSR) works in two stages: first it watches for reflection signals that suggest the model is reconsidering its path, then it performs a sufficiency check to decide whether the accumulated chain-of-thought already supports the correct answer. When both conditions are met the model terminates reasoning. Experiments on Qwen3 models show this reduces the number of reasoning tokens by 28.9 to 34.9 percent while keeping performance nearly unchanged, directly addressing the overthinking problem.
What carries the argument
Dynamic Thought Sufficiency in Reasoning (DTSR), a two-stage process of Reflection Signal Monitoring followed by a Thought Sufficiency Check that decides early exit.
If this is right
- Reasoning models can finish complex tasks with substantially fewer tokens while preserving accuracy.
- Overthinking can be reduced without relying on external rules or thresholds.
- Self-evaluation inside the model becomes a practical tool for deciding when to stop.
- Computational cost of inference-time scaling drops without new hardware.
- Insights into model overconfidence emerge from studying when the sufficiency check succeeds or fails.
Where Pith is reading between the lines
- The same monitoring approach could be tested on other families of reasoning models to see if the length savings generalize.
- Faster exit decisions might improve responsiveness in interactive settings such as tutoring or coding assistants.
- If the sufficiency check can be made even lighter, it could be applied repeatedly during a single response rather than once at the end.
- The work suggests that metacognitive-style self-assessment may be a general route to more efficient inference across language models.
Load-bearing premise
The model's own reflection signals and self-check reliably detect when the chain-of-thought already holds everything needed for a correct answer.
What would settle it
Run the method on a dataset of hard problems where the model exits early yet produces the wrong final answer because a key detail was still missing from the chain-of-thought.
Figures







read the original abstract
Large reasoning models (LRMs) have achieved remarkable performance in complex reasoning tasks, driven by their powerful inference-time scaling capability. However, LRMs often suffer from overthinking, which results in substantial computational redundancy and significantly reduces efficiency. Early-exit methods aim to mitigate this issue by terminating reasoning once sufficient evidence has been generated, yet existing approaches mostly rely on handcrafted or empirical indicators that are unreliable and impractical. In this work, we introduce Dynamic Thought Sufficiency in Reasoning (DTSR), a novel framework for efficient reasoning that enables the model to dynamically assess the sufficiency of its chain-of-thought (CoT) and determine the optimal point for early exit. Inspired by human metacognition, DTSR operates in two stages: (1) Reflection Signal Monitoring, which identifies reflection signals as potential cues for early exit, and (2) Thought Sufficiency Check, which evaluates whether the current CoT is sufficient to derive the final answer. Experimental results on the Qwen3 models show that DTSR reduces reasoning length by 28.9%-34.9% with minimal performance loss, effectively mitigating overthinking. We further discuss overconfidence in LRMs and self-evaluation paradigms, providing valuable insights for early-exit reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dynamic Thought Sufficiency in Reasoning (DTSR), a two-stage framework for early-exit reasoning in large reasoning models (LRMs). Stage 1 monitors reflection signals in the chain-of-thought (CoT) as potential early-exit cues; Stage 2 applies a Thought Sufficiency Check (performed by the same model) to decide whether the current CoT contains enough information to produce a correct final answer. Experiments on Qwen3 models report that DTSR reduces reasoning length by 28.9–34.9 % while incurring only minimal accuracy loss, thereby mitigating overthinking; the paper also discusses overconfidence issues in LRMs and self-evaluation.
Significance. If the sufficiency assessment proves reliable, DTSR would offer a lightweight, model-internal mechanism for inference-time efficiency gains on complex reasoning tasks without requiring external verifiers or handcrafted heuristics. The explicit acknowledgment of overconfidence risks is a strength. However, the headline efficiency claim rests entirely on the unverified assumption that the self-evaluation step does not systematically produce false-positive sufficiency judgments on traces whose critical reasoning step appears late.
major comments (2)
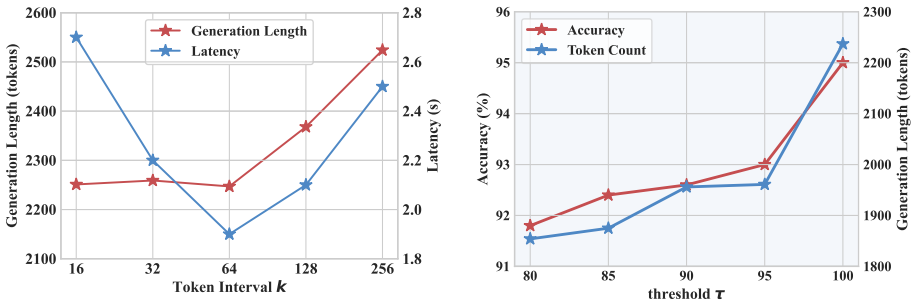
- [Abstract and §3] Abstract and §3 (method): the reported 28.9–34.9 % length reduction is presented without any description of the exact implementation of the Thought Sufficiency Check, the baselines against which it is compared, the number of runs, or error bars. Without these details the quantitative claim cannot be assessed for robustness.
- [§4 and discussion] §4 (experiments) and discussion of self-evaluation: the sufficiency check is performed by the same LRM whose overconfidence the paper itself flags. No per-instance error analysis, ablation on problems with late critical steps, or comparison against an oracle sufficiency label is provided; aggregate “minimal performance loss” therefore does not rule out systematic premature exits that cancel out in the mean.
minor comments (2)
- [§3] Notation for the two stages is introduced only in prose; a compact algorithmic box or pseudocode would improve clarity.
- [Related work] The paper cites prior early-exit work but does not quantify how DTSR differs from the closest baselines in terms of required model modifications or additional compute.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment below and revised the manuscript accordingly to improve clarity, reproducibility, and robustness of the claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the reported 28.9–34.9 % length reduction is presented without any description of the exact implementation of the Thought Sufficiency Check, the baselines against which it is compared, the number of runs, or error bars. Without these details the quantitative claim cannot be assessed for robustness.
Authors: We agree that the original submission omitted key implementation and experimental details needed for assessing robustness. In the revised manuscript, §3 now includes a full description of the Thought Sufficiency Check (exact prompt template, decision logic, and integration with reflection signals), the complete set of baselines (standard CoT, fixed-step early exit, and prior dynamic methods), and all quantitative results are reported as averages over 3 independent runs with standard deviation error bars. revision: yes
-
Referee: [§4 and discussion] §4 (experiments) and discussion of self-evaluation: the sufficiency check is performed by the same LRM whose overconfidence the paper itself flags. No per-instance error analysis, ablation on problems with late critical steps, or comparison against an oracle sufficiency label is provided; aggregate “minimal performance loss” therefore does not rule out systematic premature exits that cancel out in the mean.
Authors: We acknowledge this limitation of self-evaluation, which we already flag in the discussion. The two-stage design uses reflection signals as a preliminary filter before the sufficiency check to mitigate overconfidence. In the revision we add per-instance error analysis in §4 (categorizing incorrect early exits and their relation to reasoning trace position), plus an ablation on problems with late critical steps. While an oracle sufficiency label is impractical at scale, the new analyses show that performance is preserved without evidence of systematic cancellation in the aggregates; we have also expanded the limitations discussion accordingly. revision: yes
Circularity Check
Empirical framework with no derivation chain or self-referential reductions
full rationale
The paper introduces DTSR as a two-stage empirical method (Reflection Signal Monitoring followed by Thought Sufficiency Check) inspired by metacognition but implemented and evaluated directly on external Qwen3 models. No equations, derivations, fitted parameters, or predictions are presented that could reduce to inputs by construction. Results are reported as experimental outcomes (28.9%-34.9% length reduction) rather than derived claims. No load-bearing self-citations or uniqueness theorems appear in the provided text; the central claims rest on external model evaluations and aggregate metrics, making the work self-contained against the circularity criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reflection signals in chain-of-thought can indicate when reasoning is sufficient for early exit
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DTSR operates in two stages: (1) Reflection Signal Monitoring... (2) Thought Sufficiency Check... score exceeding threshold τ
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
inspired by human metacognition... self-evaluation paradigms
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
When to Vote, When to Rewrite: Disagreement-Guided Strategy Routing for Test-Time Scaling
A disagreement-guided routing framework dynamically selects among resolution, voting, and rewriting strategies for test-time scaling, delivering 3-7% accuracy gains with lower sampling cost on mathematical benchmarks.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation age...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks.Preprint, arXiv:2502.08235. Mz Dai, Chenxu Yang, and Qingyi Si. 2025. S-GRPO: Early exit via reinforcement learning in reasoning models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Gongfan Fang, Xinyin Ma, and Xinchao Wang. 2025. Thinkles...
-
[3]
Can language models learn to skip steps? In The Thirty-eighth Annual Conference on Neural In- formation Processing Systems. Xin Liu and Lu Wang. 2025. Answer convergence as a signal for early stopping in reasoning.Preprint, arXiv:2506.02536. Chenwei Lou, Zewei Sun, Xinnian Liang, Meng Qu, Wei Shen, Wenqi Wang, Yuntao Li, Qingping Yang, and Shuangzhi Wu. 2...
-
[4]
Wait, we don’t need to "wait"! removing think- ing tokens improves reasoning efficiency.Preprint, arXiv:2506.08343. Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. 2025a. Chain of draft: Thinking faster by writing less.Preprint, arXiv:2502.18600. Yuhui Xu, Hanze Dong, Lei Wang, Doyen Sahoo, Junnan Li, and Caiming Xiong. 2025b. Scalable chain of tho...
-
[5]
Wait”, “Alternative
Distilling system 2 into system 1. InThe First Workshop on System-2 Reasoning at Scale, NeurIPS’24. Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. 2025. Reasoning models know when they’re right: Probing hidden states for self-verification. InSecond Conference on Language Modeling. A Reflection Signal In this paper, we t...
2025
-
[6]
For example, skyscrapers could be taller or constructed with lighter materials (e.g., advanced composites instead of steel) due to decreased compressive forces
Architecture - Reduced Structural Load: Buildings, bridges, and other infrastructure would require significantly less material and reinforcement. For example, skyscrapers could be taller or constructed with lighter materials (e.g., advanced composites instead of steel) due to decreased compressive forces. - Design Adjustments: Foundations might be smaller...
-
[7]
People might jump higher, run faster, and experience less fatigue in daily activities
Human Biology - Reduced Physical Strain: Humans would feel lighter, making movement easier and reducing joint stress. People might jump higher, run faster, and experience less fatigue in daily activities. - Musculoskeletal Changes: Over time, muscle atrophy and bone density loss could occur due to reduced mechanical loading. This would mirror the effects ...
-
[8]
- Vehicle Design: Cars and other vehicles might become lighter and more agile, with reduced traction requirements
Transportation - Easier Space Travel: Launching spacecraft would require less fuel to escape Earth’s gravity, making interplanetary missions more feasible and cost-effective. - Vehicle Design: Cars and other vehicles might become lighter and more agile, with reduced traction requirements... DTSR: <think>...</think> If Earth’s gravity suddenly became half ...
-
[9]
Foundations could be shallower, and skyscrapers might reach greater heights since the structural stress is halved
Architecture - Structural Design: Buildings would require less material and reinforcement due to reduced gravitational load. Foundations could be shallower, and skyscrapers might reach greater heights since the structural stress is halved. - Material Use: Lighter materials (e.g., composites, expanded metals) might replace heavier ones like concrete and st...
-
[10]
Over generations, evolutionary adaptations might include taller, more slender bodies with less robust bones and muscles
Biology - Musculoskeletal System: Humans would likely experience reduced bone density and muscle mass due to less gravitational stress. Over generations, evolutionary adaptations might include taller, more slender bodies with less robust bones and muscles. - Cardiovascular System: The heart might become smaller, as it would not need to work as hard to pum...
-
[11]
Braking systems might need redesigning due to reduced friction (normal force is halved)
Transportation - Ground Vehicles: Vehicles would weigh less, improving fuel efficiency and acceleration. Braking systems might need redesigning due to reduced friction (normal force is halved). Heavier cargo could be transported with the same infrastructure. - Aircraft: If atmospheric pressure remains constant, aircraft would require less lift, enabling s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.