Recognition: unknown
When to Vote, When to Rewrite: Disagreement-Guided Strategy Routing for Test-Time Scaling
Pith reviewed 2026-05-07 10:55 UTC · model grok-4.3
The pith
Output disagreement routes test-time scaling between light fixes, voting, and rewriting to raise accuracy and cut costs on math tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We observe that output disagreement is strongly correlated with instance difficulty and prediction correctness. This correlation allows test-time scaling to be recast as an instance-level routing problem that selects among strategies—lightweight resolution for low disagreement, majority voting for medium disagreement, and rewriting for high disagreement—rather than applying one strategy uniformly.
What carries the argument
The disagreement-guided router that measures variance across sampled outputs and dispatches each instance to the matching scaling strategy.
If this is right
- Low-disagreement instances are solved accurately with minimal sampling.
- Moderate disagreement benefits from voting to aggregate multiple predictions.
- High disagreement triggers rewriting to reformulate and resolve ambiguity.
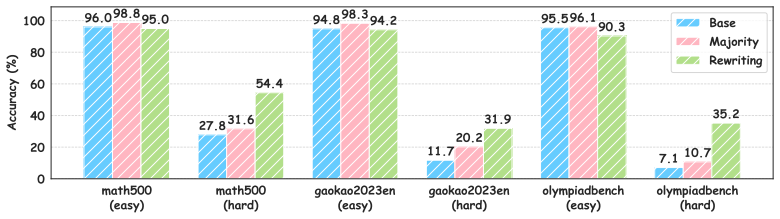
- Across models the method yields 3-7% accuracy gains at reduced total sampling cost.
- No model retraining is required for the routing decisions.
Where Pith is reading between the lines
- The same disagreement signal might adaptively allocate compute in code or planning domains where hardness is similarly reflected in output variance.
- Learned rather than fixed disagreement thresholds could further optimize the routing boundaries per model.
- Pairing the router with tree search inside the rewrite branch could compound gains on the hardest instances.
Load-bearing premise
Disagreement among outputs is a reliable indicator of both problem difficulty and whether the answer is correct.
What would settle it
If a new set of math problems shows that high-disagreement instances do not have lower accuracy or if the router fails to beat uniform majority voting on accuracy or cost, the routing benefit would be refuted.
Figures





read the original abstract
Large Reasoning Models (LRMs) achieve strong performance on mathematical reasoning tasks but remain unreliable on challenging instances. Existing test-time scaling methods, such as repeated sampling, self-correction, and tree search, improve performance at the cost of increased computation, yet often exhibit diminishing returns on hard problems. We observe that output disagreement is strongly correlated with instance difficulty and prediction correctness, providing a useful signal for guiding instance-level strategy selection at test time. Based on this insight, we propose a training-free framework that formulates test-time scaling as an instance-level routing problem, rather than allocating more computation within a single strategy, dynamically selecting among different scaling strategies based on output disagreement. The framework applies lightweight resolution for consistent cases, majority voting for moderate disagreement, and rewriting-based reformulation for highly ambiguous instances. Experiments on seven mathematical benchmarks and three models show that our method improves accuracy by 3% - 7% while reducing sampling cost compared to existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a training-free framework for test-time scaling in large reasoning models that treats scaling as an instance-level routing problem: it measures output disagreement across samples and routes low-disagreement instances to lightweight resolution, moderate-disagreement cases to majority voting, and high-disagreement instances to rewriting-based reformulation. Experiments on seven mathematical benchmarks and three models are reported to yield 3-7% accuracy gains with reduced sampling cost relative to existing uniform scaling approaches.
Significance. If the disagreement signal proves reliable for partitioning instances into regimes where each strategy is optimal, the approach could improve the efficiency of test-time compute by avoiding unnecessary application of expensive methods on easy cases. The training-free design and evaluation across multiple benchmarks and models are positive features that would support practical adoption if the routing decisions are shown to be robust.
major comments (2)
- [§4] §4 (Experimental Results): The central claim of 3-7% accuracy improvement and cost reduction depends on the superiority of disagreement-guided routing, yet the manuscript provides no explicit ablation that applies the three strategies (lightweight resolution, majority voting, rewriting) uniformly to all instances and compares against the routed version. Without this control, the gains could arise primarily from the voting component on moderate cases rather than from the routing decisions themselves.
- [§3] §3 (Method): The disagreement metric, its computation across samples, and the procedure for selecting routing thresholds are not described with sufficient detail to determine whether thresholds were fixed a priori or tuned post-hoc on the same benchmarks. This is load-bearing because post-hoc selection on the evaluation data would undermine the claim that disagreement provides a general, reliable signal for strategy selection.
minor comments (2)
- [Abstract] Abstract and §2: The statement that disagreement is 'strongly correlated with instance difficulty and prediction correctness' should be supported by a quantitative plot or table (e.g., correlation coefficient or accuracy-vs-disagreement curve) rather than left as a qualitative observation.
- [§4] §4: The manuscript should report statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) for the accuracy improvements and include variance across random seeds for the sampling-based methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our results and method.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results): The central claim of 3-7% accuracy improvement and cost reduction depends on the superiority of disagreement-guided routing, yet the manuscript provides no explicit ablation that applies the three strategies (lightweight resolution, majority voting, rewriting) uniformly to all instances and compares against the routed version. Without this control, the gains could arise primarily from the voting component on moderate cases rather than from the routing decisions themselves.
Authors: We agree that an explicit ablation applying each strategy uniformly would provide stronger evidence isolating the benefit of routing. In the revised manuscript, we will add experiments that apply lightweight resolution, majority voting, and rewriting uniformly to every instance and directly compare accuracy and sampling cost against the disagreement-guided routed version. Our existing comparisons are to prior uniform scaling baselines, but we acknowledge the value of this additional control using the same strategy set. revision: yes
-
Referee: [§3] §3 (Method): The disagreement metric, its computation across samples, and the procedure for selecting routing thresholds are not described with sufficient detail to determine whether thresholds were fixed a priori or tuned post-hoc on the same benchmarks. This is load-bearing because post-hoc selection on the evaluation data would undermine the claim that disagreement provides a general, reliable signal for strategy selection.
Authors: We appreciate the request for greater clarity. The disagreement metric is the fraction of pairwise differing solutions among K samples drawn for an instance. Thresholds are set a priori as fixed quantiles of the disagreement distribution observed on a small held-out validation set of problems drawn from the same distribution as the benchmarks, without access to test labels or post-hoc adjustment on evaluation data. In the revision we will expand §3 with the precise formula, pseudocode for routing, and explicit description of the threshold selection process to confirm it is training-free and general. revision: yes
Circularity Check
No circularity: empirical routing from observed disagreement, training-free
full rationale
The paper's core contribution is a training-free instance-level routing rule that maps measured output disagreement (across samples) into one of three fixed strategies: lightweight resolution for low disagreement, majority voting for moderate, and rewriting for high. This mapping is presented as a direct consequence of an observed empirical correlation between disagreement, difficulty, and correctness; no parameters are fitted to the final accuracy metric, no equations are solved by construction, and no derivation reduces the reported gains to the input data by tautology. Experiments on held-out benchmarks simply measure the outcome of applying the rule. No load-bearing self-citations, ansatz smuggling, or uniqueness theorems appear in the abstract or described method. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- disagreement thresholds
axioms (1)
- domain assumption Output disagreement correlates with instance difficulty and prediction correctness
Reference graph
Works this paper leans on
-
[1]
A. Agarwal, A. Sengupta, and T. Chakraborty. The art of scaling test-time compute for large language models, 2025. URLhttps://arxiv.org/abs/2512.02008
-
[2]
Aggarwal, A
P. Aggarwal, A. Madaan, Y . Yang, and Mausam. Let’s sample step by step: Adaptive-consistency for efficient reasoning and coding with llms, 2023. URL https://arxiv.org/abs/2305. 11860
2023
-
[3]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, and C. Sutton. Program synthesis with large language models, 2021. URL https: //arxiv.org/abs/2108.07732
work page internal anchor Pith review arXiv 2021
- [4]
-
[5]
J. Chen, B. Wang, Z. Jiang, and Y . Nakashima. Putting people in llms’ shoes: Generating better answers via question rewriter. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23577–23585, 2025
2025
-
[6]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review arXiv 2021
-
[7]
X. Chen, M. Lin, N. Schärli, and D. Zhou. Teaching large language models to self-debug, 2023. URLhttps://arxiv.org/abs/2304.05128
work page internal anchor Pith review arXiv 2023
-
[8]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948
work page internal anchor Pith review arXiv 2025
-
[10]
DeepSeek-AI, A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Yang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Chen, J. Yuan, J. Qiu, J. Song, K. Dong, K. Gao, K. Guan, L. Wan...
work page internal anchor Pith review arXiv 2024
- [11]
- [12]
-
[13]
L. Gui, C. Gârbacea, and V . Veitch. Bonbon alignment for large language models and the sweetness of best-of-n sampling.Advances in Neural Information Processing Systems, 37: 2851–2885, 2024
2024
-
[14]
C. He, R. Luo, Y . Bai, S. Hu, Z. Thai, J. Shen, J. Hu, X. Han, Y . Huang, Y . Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3828–3850, 2024
2024
-
[15]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Stein- hardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review arXiv 2021
- [16]
-
[17]
W. Kong, S. Hombaiah, M. Zhang, Q. Mei, and M. Bendersky. Prewrite: Prompt rewriting with reinforcement learning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 594–601, 2024
2024
-
[18]
A. Kumar, V . Zhuang, R. Agarwal, Y . Su, J. D. Co-Reyes, A. Singh, K. Baumli, S. Iqbal, C. Bishop, R. Roelofs, et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917, 2024
- [19]
- [20]
- [21]
- [22]
-
[23]
L. Lin, J. Fu, P. Liu, Q. Li, Y . Gong, J. Wan, F. Zhang, Z. Wang, D. Zhang, and K. Gai. Just ask one more time! self-agreement improves reasoning of language models in (almost) all scenarios,
- [24]
- [25]
- [26]
-
[27]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
-
[28]
URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review arXiv
-
[29]
Reflexion: Language Agents with Verbal Reinforcement Learning
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/ 2303.11366
work page internal anchor Pith review arXiv 2023
-
[30]
L. Shu, L. Luo, J. Hoskere, Y . Zhu, Y . Liu, S. Tong, J. Chen, and L. Meng. Rewritelm: An instruction-tuned large language model for text rewriting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18970–18980, 2024
2024
- [31]
-
[32]
Q. Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review arXiv 2025
-
[33]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review arXiv 2022
-
[34]
When Is Thinking Enough? Early Exit via Sufficiency Assessment for Efficient Reasoning
Y . Xiang, Y . Ji, R. Xu, D. Qiao, Z. Yang, J. Li, and M. Zhang. When is thinking enough? early exit via sufficiency assessment for efficient reasoning, 2026. URL https://arxiv.org/abs/ 2604.06787
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
M. Xue, D. Liu, W. Lei, X. Ren, B. Yang, J. Xie, Y . Zhang, D. Peng, and J. Lv. Dynamic voting for efficient reasoning in large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 3085–3104, 2023
2023
-
[36]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T. Liu, W....
work page internal anchor Pith review arXiv 2024
-
[37]
A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Lin, K. Lu, M. Xue, R. Lin, T. Liu, X. Ren, and Z. Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024. URLhttps://arxiv.org/abs/2409.12122
work page internal anchor Pith review arXiv 2024
-
[38]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
2023
-
[39]
D. Zhang, X. Huang, D. Zhou, Y . Li, and W. Ouyang. Accessing gpt-4 level mathemat- ical olympiad solutions via monte carlo tree self-refine with llama-3 8b.arXiv preprint arXiv:2406.07394, 2024
-
[40]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Q. Zhang, F. Lyu, Z. Sun, L. Wang, W. Zhang, W. Hua, H. Wu, Z. Guo, Y . Wang, N. Muennighoff, I. King, X. Liu, and C. Ma. A survey on test-time scaling in large language models: What, how, where, and how well?, 2025. URLhttps://arxiv.org/abs/2503.24235
work page internal anchor Pith review arXiv 2025
-
[41]
Zhang, M
R. Zhang, M. Haider, M. Yin, J. Qiu, M. Wang, P. Bartlett, and A. Zanette. Accelerating best- of-n via speculative rejection. InICML 2024 Workshop on Structured Probabilistic Inference {\&}Generative Modeling, 2024
2024
-
[42]
arXiv:2305.12474 (2023).https://doi.org/10.48550/ arXiv.2305.12474
X. Zhang, C. Li, Y . Zong, Z. Ying, L. He, and X. Qiu. Evaluating the performance of large language models on gaokao benchmark.arXiv preprint arXiv:2305.12474, 2023
- [43]
- [44]
-
[45]
Y . Zhou, Y . Zhu, D. Antognini, Y . Kim, and Y . Zhang. Paraphrase and solve: Exploring and exploiting the impact of surface form on mathematical reasoning in large language models. arXiv preprint arXiv:2404.11500, 2024. 12 A Limitations This work leaves room for further exploration in certain aspects. • Our framework relies on output disagreement as a p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.