Recognition: 2 theorem links
· Lean TheoremRiemann-Bench: A Benchmark for Moonshot Mathematics
Pith reviewed 2026-05-10 17:58 UTC · model grok-4.3
The pith
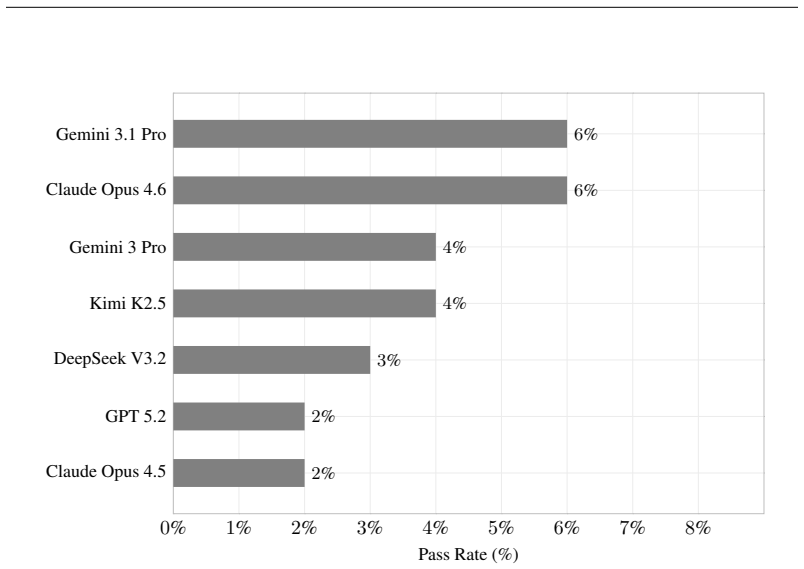
Frontier AI models score below 10% on a benchmark of 25 research-level math problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Riemann-Bench consists of 25 closed-form problems that underwent double-blind verification by independent experts who solved them from scratch. Evaluated as research agents with coding and search tools over 100 runs each, all frontier models achieve success rates below 10%. This result demonstrates that gold-medal olympiad performance does not translate to the sustained theoretical work needed for genuine research mathematics.
What carries the argument
Riemann-Bench, a private set of 25 expert-curated problems with programmatic verifiers for closed-form answers.
If this is right
- Olympiad success does not predict performance on research-level problems.
- New training or reasoning methods will be required to reach research capability.
- Private benchmarks can isolate true capability from training-data effects.
- Evaluations must move beyond competition formats to track progress toward open-ended mathematics.
Where Pith is reading between the lines
- The benchmark could be extended to track incremental gains as models improve on individual problems over time.
- Similar private expert-curated sets might expose comparable gaps in other technical fields such as theoretical physics or algorithm design.
- If models remain low-scoring, it points toward the need for architectures that support longer-horizon discovery rather than single-shot solutions.
Load-bearing premise
The 25 problems genuinely demand original research insight that current AI methods cannot solve through pattern matching or leaked data.
What would settle it
An independent run where any frontier model reaches above 30% success rate on the full set of problems while respecting the unconstrained-agent protocol.
Figures
read the original abstract
Recent AI systems have achieved gold-medal-level performance on the International Mathematical Olympiad, demonstrating remarkable proficiency at competition-style problem solving. However, competition mathematics represents only a narrow slice of mathematical reasoning: problems are drawn from limited domains, require minimal advanced machinery, and can often reward insightful tricks over deep theoretical knowledge. We introduce \bench{}, a private benchmark of 25 expert-curated problems designed to evaluate AI systems on research-level mathematics that goes far beyond the olympiad frontier. Problems are authored by Ivy League mathematics professors, graduate students, and PhD-holding IMO medalists, and routinely took their authors weeks to solve independently. Each problem undergoes double-blind verification by two independent domain experts who must solve the problem from scratch, and yields a unique, closed-form solution assessed by programmatic verifiers. We evaluate frontier models as unconstrained research agents, with full access to coding tools, search, and open-ended reasoning, using an unbiased statistical estimator computed over 100 independent runs per problem. Our results reveal that all frontier models currently score below 10\%, exposing a substantial gap between olympiad-level problem solving and genuine research-level mathematical reasoning. By keeping the benchmark fully private, we ensure that measured performance reflects authentic mathematical capability rather than memorization of training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Riemann-Bench, a private benchmark of 25 expert-curated problems in research-level mathematics authored by professors, graduate students, and IMO medalists, each verified double-blind by independent experts and equipped with unique closed-form solutions assessed via programmatic verifiers. It evaluates frontier AI models as unconstrained research agents with full access to coding tools, search, and open-ended reasoning, applying an unbiased statistical estimator over 100 independent runs per problem, and reports that all models score below 10%, claiming this exposes a substantial gap between olympiad-level performance and genuine research-level mathematical reasoning.
Significance. If the problems genuinely demand novel research-level insight beyond olympiad techniques and the evaluation protocol fairly captures this without leakage or tool-assisted shortcuts, the results would provide valuable evidence of current limitations in AI mathematical reasoning. The paper merits credit for its rigorous elements: double-blind expert verification requiring solvers to start from scratch, programmatic closed-form verifiers, and the 100-run statistical estimator to reduce variance in agent performance.
major comments (3)
- [Abstract] Abstract and evaluation protocol description: The headline result that all frontier models score below 10% is presented as an aggregate without any per-problem success rates, failure-mode analysis, or explicit confirmation that the 100-run estimator was applied uniformly, which is load-bearing for assessing whether the low scores reflect true problem difficulty rather than protocol inconsistencies or model-specific behaviors.
- [Benchmark construction] Benchmark construction section: The complete privacy of all 25 problems, while motivated by leakage prevention, provides no public examples, domain descriptions, or high-level characterizations, making it impossible to independently test the central assumption that these problems require research-level insight unsolvable by existing AI techniques or clever use of the allowed tools.
- [Results] Results and evaluation sections: No details are given on how the unconstrained-agent protocol (coding/search tools plus verifiers) was implemented consistently or on any statistical checks for run-to-run variability, which directly affects the reliability of the <10% claim and the asserted gap from olympiad performance.
minor comments (2)
- [Introduction] The notation for the benchmark name should be introduced and defined explicitly on first use in the introduction rather than appearing only in the abstract.
- [Results] A table summarizing model scores with confidence intervals from the 100-run estimator would improve clarity of the results presentation.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address each major comment point by point below, indicating where we will revise the manuscript to improve clarity and transparency while preserving the benchmark's core design.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation protocol description: The headline result that all frontier models score below 10% is presented as an aggregate without any per-problem success rates, failure-mode analysis, or explicit confirmation that the 100-run estimator was applied uniformly, which is load-bearing for assessing whether the low scores reflect true problem difficulty rather than protocol inconsistencies or model-specific behaviors.
Authors: We agree that disaggregating the results would strengthen the paper. In the revised manuscript we will add a table in the Results section reporting per-problem success rates (with the 100-run estimator applied uniformly to each), together with a concise failure-mode summary drawn from the observed agent trajectories. We will also insert an explicit statement in the evaluation protocol subsection confirming uniform application of the estimator across all 25 problems. revision: yes
-
Referee: [Benchmark construction] Benchmark construction section: The complete privacy of all 25 problems, while motivated by leakage prevention, provides no public examples, domain descriptions, or high-level characterizations, making it impossible to independently test the central assumption that these problems require research-level insight unsolvable by existing AI techniques or clever use of the allowed tools.
Authors: We acknowledge the referee's desire for greater visibility. Releasing even high-level characterizations or examples would create an unacceptable risk of future leakage, which would invalidate the benchmark as a measure of genuine research capability. The research-level character is instead substantiated by the double-blind verification protocol, in which two independent experts solved each problem from scratch; we will expand the Benchmark construction section with additional quantitative details on verification time, expert credentials, and the requirement that solutions be novel closed-form expressions not reducible to olympiad techniques. revision: partial
-
Referee: [Results] Results and evaluation sections: No details are given on how the unconstrained-agent protocol (coding/search tools plus verifiers) was implemented consistently or on any statistical checks for run-to-run variability, which directly affects the reliability of the <10% claim and the asserted gap from olympiad performance.
Authors: We agree that implementation details and variability analysis are needed. The revised Results and Evaluation sections will describe the exact tool-access configuration (coding environment, search API, and verifier interface) provided identically to each model, the prompt template used to enforce the unconstrained-agent setting, and statistical checks including per-problem standard deviation, 95% confidence intervals, and a test for run-to-run independence across the 100 trials. revision: yes
Circularity Check
No circularity: empirical benchmark report with no derivations or self-referential claims
full rationale
The paper is a straightforward empirical benchmark introduction and evaluation report. It describes curation of 25 private problems by experts, double-blind verification, and unconstrained agent runs on frontier models yielding <10% scores. No derivation chain exists, no equations or first-principles results are claimed, no parameters are fitted and relabeled as predictions, and no self-citations or ansatzes are invoked to justify any load-bearing step. The central claim rests on the empirical protocol and problem privacy rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 25 problems represent genuine research-level mathematics that requires deep theoretical knowledge beyond olympiad-style tricks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe introduce RIEMANN-BENCH, a private benchmark of 25 expert-curated problems... double-blind verification by two independent domain experts... unconstrained research agents... pass rates using the unbiased estimator of Chen et al. (2021). All models currently score below 10%.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearProblems... require deep domain knowledge and multi-step theoretical reasoning... classification of multibasic A-modules over the ring of Hahn series... Eynard–Orantin topological recursion
Forward citations
Cited by 2 Pith papers
-
Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
Soohak is a new 439-problem mathematician-authored benchmark showing frontier LLMs reach only 30% on research math and fail to exceed 50% on refusing ill-posed questions.
-
Beyond Accuracy: Evaluating Strategy Diversity in LLM Mathematical Reasoning
Frontier LLMs achieve 95-100% accuracy on AMC/AIME problems but recover far fewer distinct valid strategies than human references, while collectively generating 50 novel strategies.
Reference graph
Works this paper leans on
-
[1]
arXiv:2302.12433 [cs.CL] https://arxiv.org/abs/2302.12433
Azerbayev, Z., Piotrowski, B., Schoelkopf, H., et al. ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics.arXiv preprint arXiv:2302.12433,
-
[2]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., et al. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2502.03544 , title =
Chervonyi, Y ., et al. Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeome- try2.arXiv preprint arXiv:2502.03544,
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., et al. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Ren, X., et al. DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition.arXiv preprint arXiv:2504.21801,
-
[6]
Deepseekmath-v2: Towards self-verifiable mathematical reasoning,
Shao, Z., Luo, Y ., Lu, C., et al. DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning. arXiv preprint arXiv:2511.22570,
-
[7]
8 Fang, F., Mei, X., Miao, Z., et al. MathOdyssey: Benchmarking Mathematical Problem-Solving Skills in Large Language Models Using Odyssey Math Data.arXiv preprint arXiv:2406.18321,
-
[8]
Gao, B., Song, Y ., et al. Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models.arXiv preprint arXiv:2410.07985,
-
[9]
Glazer, E., Erdil, E., Besiroglu, T., et al. FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI.arXiv preprint arXiv:2411.04872,
-
[10]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
OlymMATH. Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models.arXiv preprint arXiv:2503.21380,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
OpenAI. OpenAI o1 System Card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Pan, Negar Arabzadeh, Riccardo Cogo, Yuxuan Zhu, Alexander Xiong, Lakshya A
Pan, M. Z., Arabzadeh, N., Cogo, R., et al. Measuring Agents in Production.arXiv preprint arXiv:2512.04123,
-
[13]
ARB: Advanced Reasoning Benchmark for Large Language Models.arXiv preprint arXiv:2307.13692,
Sawada, T., Paleka, D., Havrilla, A., et al. ARB: Advanced Reasoning Benchmark for Large Language Models.arXiv preprint arXiv:2307.13692,
-
[14]
Song, P., Yang, K., and Anandkumar, A. Lean Copilot: LLMs as Copilots for Theorem Proving in Lean.arXiv preprint arXiv:2404.12534,
-
[15]
Srivastava, M., et al. Functional Benchmarks for Robust Evaluation of Reasoning Performance, and the Reasoning Gap.arXiv preprint arXiv:2402.19450,
-
[16]
Tsoukalas, G., Jasber, J., et al. PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition.arXiv preprint arXiv:2407.11214,
-
[17]
arXiv preprint arXiv:2406.04244 , year=
9 Xu, R., et al. Benchmark Data Contamination of Large Language Models: A Survey.arXiv preprint arXiv:2406.04244,
-
[18]
Don’t make your llm an evaluation benchmark cheater
Zhou, K., Zhu, Y ., et al. Don’t Make Your LLM an Evaluation Benchmark Cheater.arXiv preprint arXiv:2311.01964,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.