Recognition: no theorem link
Beyond Accuracy: Evaluating Strategy Diversity in LLM Mathematical Reasoning
Pith reviewed 2026-05-12 04:26 UTC · model grok-4.3
The pith
Frontier LLMs achieve 95-100% accuracy on math problems but recover substantially fewer distinct strategies than human references.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across four frontier models, a pronounced decoupling exists between answer accuracy and strategy diversity: all models achieve high accuracy (95%-100%) under single-solution prompts, but under multiple-strategy prompts they recover substantially fewer strategies than the 217 AoPS-derived human reference families, with the largest gaps in Geometry and Number Theory. The models generate 184, 152, 151, and 110 distinct valid strategies respectively and collectively produce 50 benchmark-novel valid strategies. A repeated-run robustness check shows diminishing gains, with the strongest model recovering only 39 of 55 reference strategies (71%) after three runs.
What carries the argument
The strategy-level evaluation framework that annotates model outputs for strategy identity, validity, and correctness using dual-AI coding with human adjudication against 217 AoPS-derived reference strategy families on 80 AMC/AIME problems.
If this is right
- Models achieve 95%-100% accuracy under single-solution prompts but recover substantially fewer strategies under multiple-strategy prompts.
- Largest gaps in recovered strategies occur in Geometry and Number Theory.
- Models collectively produce 50 valid strategies absent from the human reference set.
- Repeated runs yield diminishing returns, with the strongest model covering only 71% of references after three attempts.
Where Pith is reading between the lines
- Training focused only on answer correctness may discourage exploration of alternative reasoning paths.
- Benchmarks for mathematical reasoning could usefully add strategy-coverage metrics to better track flexibility.
- The 50 model-generated novel strategies suggest LLMs might surface original approaches if explicitly prompted for diversity.
- The framework could be extended to other problem domains to test whether accuracy-diversity decoupling appears outside mathematics.
Load-bearing premise
The dual-AI coding with human adjudication reliably and consistently identifies distinct strategy identities and validity without systematic bias or missing important reasoning variations.
What would settle it
An independent exhaustive human annotation or expanded prompting regime on the same 80 problems that shows models recovering at least as many distinct valid strategies as the 217-reference set would falsify the reported decoupling.
Figures



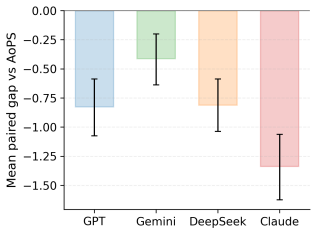
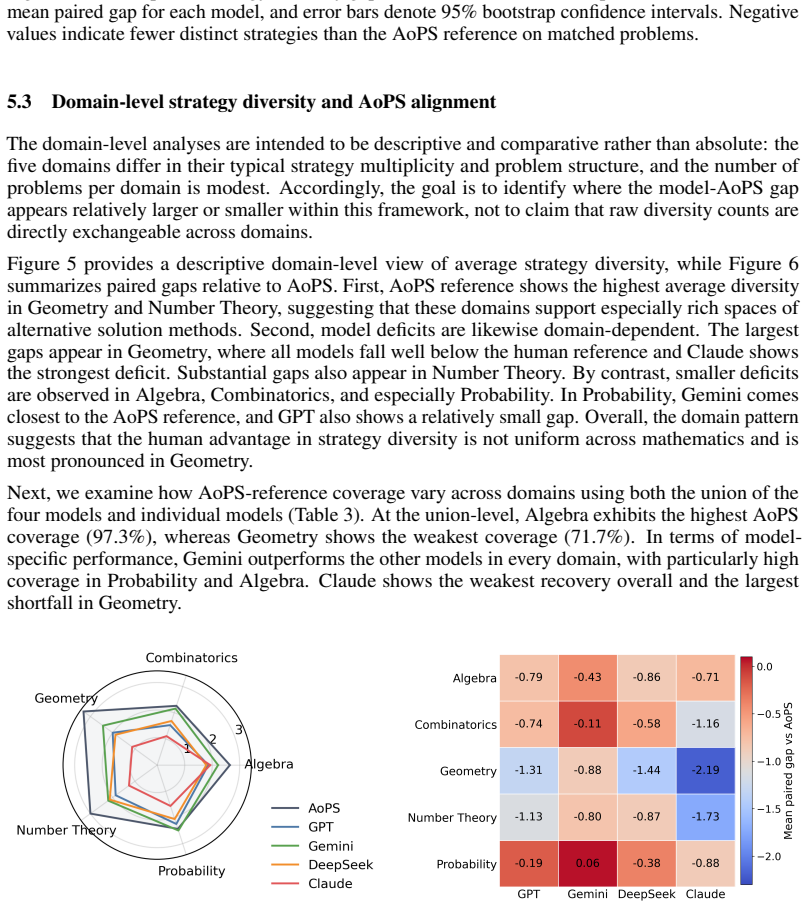




read the original abstract
Large language models now achieve high final-answer accuracy on mathematical reasoning benchmarks, but accuracy alone does not capture reasoning flexibility. We introduce a strategy-level evaluation framework instantiated on 80 AMC 10/12 and AIME problems with 217 AoPS-derived reference strategy families. Model outputs are annotated for strategy identity, validity, and correctness using dual-AI coding with human adjudication. Across four frontier models, we find a pronounced decoupling between answer accuracy and strategy diversity. Under a single-solution prompt, all models achieve high accuracy (95%-100%), but under a multiple-strategy prompt they recover substantially fewer strategies than the human reference set. Gemini, DeepSeek, GPT, and Claude generate 184, 152, 151, and 110 distinct valid strategies, respectively, with the largest gaps in Geometry and Number Theory. The models collectively produce 50 benchmark-novel valid strategies, indicating both incomplete coverage of human strategies and some capacity for alternative reasoning. A repeated-run robustness check on 20 problems shows diminishing gains in discovered strategies, with the strongest model recovering only 39 of 55 AoPS-reference strategies (71%) after three runs. These findings position strategy diversity as a complementary dimension for evaluating mathematical reasoning beyond answer correctness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a strategy-level evaluation framework for assessing LLM mathematical reasoning on 80 AMC 10/12 and AIME problems, using 217 AoPS-derived reference strategy families. Model outputs are annotated for strategy identity, validity, and correctness via dual-AI coding with human adjudication. The central claim is a decoupling between high answer accuracy (95-100% under single-solution prompts) and low strategy diversity, with models recovering far fewer distinct valid strategies than the human reference (Gemini 184, DeepSeek 152, GPT 151, Claude 110), largest gaps in Geometry and Number Theory; models also produce 50 novel valid strategies, and repeated runs on 20 problems show limited additional gains (strongest model at 71% of reference after three runs).
Significance. If the annotations hold, the work usefully demonstrates that accuracy metrics alone miss important limitations in reasoning flexibility, providing a concrete empirical basis for strategy diversity as a complementary evaluation axis. The human-adjudicated protocol and identification of novel strategies are strengths that could guide future prompting and training research; the repeated-run robustness check adds credibility to the diminishing-returns observation.
major comments (3)
- [Annotation protocol] Annotation protocol section: The dual-AI coding with human adjudication is presented as the basis for all strategy counts and the decoupling claim, yet no inter-annotator agreement statistics (Cohen/Fleiss kappa or equivalent), no ablation of the AI coders, and no blind multi-human validation on a held-out subset are reported. Without these, systematic under-counting of variants (especially in Geometry and Number Theory) cannot be ruled out and directly affects the validity of the reported gaps versus the 217-family reference.
- [Reference strategy families construction] Reference strategy families construction (Methods/§3): Details on how the 217 AoPS-derived families were defined, deduplicated, and validated for completeness are insufficient. This is load-bearing because the diversity measurements and claims of incomplete coverage rest on treating this set as an exhaustive human baseline; any gaps or over-partitioning in the reference would inflate the apparent model shortfall.
- [Repeated-run robustness check] Repeated-run robustness check (Results): The check on 20 problems reports the strongest model recovering only 39 of 55 reference strategies (71%) after three runs, but lacks statistical comparison (e.g., confidence intervals or permutation tests) against single-run counts and does not address whether additional runs would close the gap to the full 217-family set.
minor comments (3)
- [Prompting details] The exact prompting templates used for both the multiple-strategy elicitation and the dual-AI coders should be included in an appendix to allow replication.
- Figure captions and tables reporting strategy counts per topic should explicitly state the counting rule (e.g., whether near-duplicates within a family are collapsed) and include the human reference baseline for direct comparison.
- A brief discussion of potential training-data overlap with AoPS solutions would strengthen the interpretation of the 50 novel strategies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the methodological transparency of our work. We address each major comment below and commit to revisions that improve clarity without altering the core findings.
read point-by-point responses
-
Referee: [Annotation protocol] Annotation protocol section: The dual-AI coding with human adjudication is presented as the basis for all strategy counts and the decoupling claim, yet no inter-annotator agreement statistics (Cohen/Fleiss kappa or equivalent), no ablation of the AI coders, and no blind multi-human validation on a held-out subset are reported. Without these, systematic under-counting of variants (especially in Geometry and Number Theory) cannot be ruled out and directly affects the validity of the reported gaps versus the 217-family reference.
Authors: We agree that reporting inter-annotator agreement would strengthen the protocol description. The original process used two independent LLM coders with a human adjudicator resolving all disagreements; in revision we will compute and report Cohen's kappa between the AI coders on the full dataset and provide a detailed breakdown of adjudication outcomes. A full blind multi-human validation on a held-out subset was not conducted due to resource limits, which we will explicitly note as a limitation while emphasizing that human adjudication served as the final ground truth for all counts. revision: partial
-
Referee: [Reference strategy families construction] Reference strategy families construction (Methods/§3): Details on how the 217 AoPS-derived families were defined, deduplicated, and validated for completeness are insufficient. This is load-bearing because the diversity measurements and claims of incomplete coverage rest on treating this set as an exhaustive human baseline; any gaps or over-partitioning in the reference would inflate the apparent model shortfall.
Authors: We acknowledge the need for greater detail here. In the revised Methods section we will expand the description to include: the exact extraction process from AoPS solution pages, the grouping criteria used to form the 217 families (e.g., shared core insight or technique), the deduplication steps applied, and the cross-validation performed against additional contest solution sources to assess completeness. We will also clarify that the reference is intended as a comprehensive but not provably exhaustive human baseline. revision: yes
-
Referee: [Repeated-run robustness check] Repeated-run robustness check (Results): The check on 20 problems reports the strongest model recovering only 39 of 55 reference strategies (71%) after three runs, but lacks statistical comparison (e.g., confidence intervals or permutation tests) against single-run counts and does not address whether additional runs would close the gap to the full 217-family set.
Authors: We thank the referee for this observation. In the revision we will add bootstrap confidence intervals for the cumulative strategy counts across the three runs and include a permutation-based comparison of single-run versus multi-run diversity on the 20-problem subset. We will also expand the discussion to note that the observed diminishing returns on this subset do not guarantee closure of the gap to the full 217 families with further runs, and we will frame this as an empirical upper-bound observation rather than a definitive limit. revision: yes
Circularity Check
No circularity in empirical strategy diversity evaluation
full rationale
The paper reports direct empirical counts of distinct valid strategies generated by LLMs on a fixed set of 80 AMC/AIME problems, compared against an external reference of 217 AoPS-derived strategy families. Strategy identity and validity are assigned via dual-AI coding plus human adjudication, with no equations, fitted parameters, self-definitional loops, or load-bearing self-citations that would reduce the reported diversity numbers or the accuracy-diversity decoupling claim to the inputs by construction. The 50 novel strategies and repeated-run robustness check are likewise observational results against the independent benchmark, rendering the framework self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mathematical strategies on AMC/AIME problems can be partitioned into 217 distinct, non-overlapping families derived from AoPS solutions.
Reference graph
Works this paper leans on
-
[1]
Princeton University Press, 1945
George Polya.How to Solve It: A New Aspect of Mathematical Method. Princeton University Press, 1945
work page 1945
- [2]
-
[3]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Trieu H. Trinh, Yuhuai Wu, Quoc V . Le, He He, and Thang Luong. Solving olympiad ge- ometry without human demonstrations.Nature, 625(7995):476–482, 2024. doi: 10.1038/ s41586-023-06747-5
work page 2024
-
[5]
Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics. arXiv preprint arXiv:2310.10631, 2023
-
[6]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Luke Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 158–167, 2017. doi: 10.18653/v1/P17-1015
-
[11]
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, et al. Omni-MATH: A universal olympiad level mathematic benchmark for large language models. arXiv preprint arXiv:2410.07985, 2024
-
[12]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Co...
-
[13]
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics. arXiv preprint arXiv:2109.00110, 2021
-
[14]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Haoxiang Sun, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, Zheng Liu, Zhongyuan Wang, Lei Fang, and Ji-Rong Wen. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models. arXiv preprint arXiv:2503.21380, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Riemann-Bench: A Benchmark for Moonshot Mathematics
Suhaas Garre, Erik Knutsen, Sushant Mehta, and Edwin Chen. Riemann-bench: A benchmark for moonshot mathematics. arXiv preprint arXiv:2604.06802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
arXiv:2302.12433 [cs.CL] https://arxiv.org/abs/2302.12433
Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics. arXiv preprint arXiv:2302.12433, 2023
-
[17]
Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition
Souradeep Chaudhuri, Minghan Ding, Jake Jennings, Matthew Jennings, Jeongho Lee, Archit Thakur, George Tsoukalas, and Jiayi Xin. Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition. InAdvances in Neural Information Processing Systems 37, pages 11545–11569, 2024. doi: 10.52202/079017-0368. 10
-
[18]
Fimo: A challenge formal dataset for automated theorem proving
Chengwu Liu, Jianhao Shen, Huajian Xin, Zhengying Liu, Ye Yuan, Haiming Wang, Wei Ju, Chuanyang Zheng, Yichun Yin, Lin Li, Ming Zhang, and Qun Liu. Fimo: A challenge formal dataset for automated theorem proving. arXiv preprint arXiv:2309.04295, 2023
-
[19]
Jianhao Zhang, Cezar Petrui, Kristijan Nikoli´c, and Florian Tramèr. Realmath: A continuous benchmark for evaluating language models on research-level mathematics. arXiv preprint arXiv:2505.12575, 2025
-
[20]
Metacognitive capabilities of LLMs: An exploration in mathematical problem solving
Sanjeev Arora, Yoshua Bengio, Aditya Didolkar, Anirudh Goyal, Shangmin Guo, Nan Rosemary Ke, Timothy Lillicrap, Michael Mozer, Danilo Rezende, and Michal Valko. Metacognitive capabilities of LLMs: An exploration in mathematical problem solving. InAdvances in Neural Information Processing Systems 37, pages 19783–19812, 2024. doi: 10.52202/079017-0623
-
[21]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Roza Leikin, Alexander Berman, and Boris Koichu.Creativity in Mathematics and the Educa- tion of Gifted Students. Brill, 2009. doi: 10.1163/9789087909352
-
[24]
Roza Leikin and Demetra Pitta-Pantazi. Creativity and mathematics education: the state of the art.ZDM Mathematics Education, 45:159–166, 2013. doi: 10.1007/s11858-012-0459-1
-
[25]
Bethany Rittle-Johnson, Jon R. Star, and Kelley Durkin. How can cognitive-science research help improve education? the case of comparing multiple strategies to improve mathematics learning and teaching.Current Directions in Psychological Science, 29:599–609, 2020. doi: 10.1177/0963721420969365
-
[26]
Raymond Duval. A cognitive analysis of problems of comprehension in a learning of mathemat- ics.Educational Studies in Mathematics, 61:103–131, 2006. doi: 10.1007/s10649-006-0400-z
-
[27]
Raymond Duval.Understanding the Mathematical Way of Thinking – The Registers of Semiotic Representations. Springer, 2017. doi: 10.1007/978-3-319-56910-9
-
[28]
Alan H. Schoenfeld. Learning to think mathematically: Problem solving, metacognition, and sense making.Journal of Education, 196(2):1–38, 2016. doi: 10.1177/002205741619600202
-
[29]
Mathematical methods and human thought in the age of AI
Tanya Klowden and Terence Tao. Mathematical methods and human thought in the age of AI. arXiv preprint arXiv:2603.26524, 2026
-
[30]
James A. Kulik and J. D. Fletcher. Effectiveness of intelligent tutoring systems: A meta-analytic review.Review of Educational Research, 86(1):42–78, 2016. doi: 10.3102/0034654315581420
-
[31]
Brenden M. Lake, Tomer D. Ullman, Joshua B. Tenenbaum, and Samuel J. Gershman. Building machines that learn and think like people. arXiv preprint arXiv:1604.00289, 2016
-
[32]
Enhancing LLM-based feedback: Insights from intelligent tutoring systems and the learning sciences
John Stamper, Rose Xiao, and Xiaotong Hou. Enhancing LLM-based feedback: Insights from intelligent tutoring systems and the learning sciences. arXiv preprint arXiv:2405.04645, 2024
-
[33]
Mathematical association of america, 2026
Mathematical Association of America. Mathematical association of america, 2026. URL https://maa.org. Accessed 2026-05-03
work page 2026
-
[34]
Art of Problem Solving. Art of problem solving, 2026. URL https:// artofproblemsolving.com. Accessed 2026-05-03
work page 2026
- [35]
-
[36]
Plan before solving: Problem-aware strategy routing for mathematical reasoning with LLMs
Shengqi Qi, Jiaxin Ma, Zixi Yin, Lei Zhang, Jintao Zhang, Jian Liu, Furu Wei, and Tie-Yan Liu. Plan before solving: Problem-aware strategy routing for mathematical reasoning with LLMs. arXiv preprint arXiv:2509.24377, 2025
-
[37]
Anat Levav-Waynberg and Roza Leikin. The role of multiple solution tasks in developing knowledge and creativity in geometry.The Journal of Mathematical Behavior, 31(1):73–90,
-
[38]
doi: 10.1016/j.jmathb.2011.11.001
-
[39]
Star and Bethany Rittle-Johnson
Jon R. Star and Bethany Rittle-Johnson. Flexibility in problem solving: The case of equation solving.Learning and Instruction, 18(6):565–579, 2008. doi: 10.1016/j.learninstruc.2007.09. 018
-
[40]
Measuring multimodal mathematical reasoning with the MATH-Vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with the MATH-Vision dataset. InProceedings of the 38th Conference on Neural Information Processing Systems, Track on Datasets and Benchmarks, 2024. doi: 10.52202/079017-3014
-
[41]
Sadegh Mahdavi, Muchen Li, Kaiwen Liu, Christos Thrampoulidis, Leonid Sigal, and Renjie Liao. Leveraging online olympiad-level math problems for LLM training and contamination- resistant evaluation. arXiv preprint arXiv:2501.14275, 2025. A Inter-rater reliability for AoPS strategy annotation Table 4: Inter-rater reliability for AoPS strategy coding. Units...
-
[42]
First judge whether the generated strategy is mathematically valid
-
[43]
Identify the generated strategy’s core mathematical method or reasoning structure
-
[44]
Compare that core method with each reference strategy for the same problem
-
[45]
If a reference strategy has “equivalent_notes”, use those notes as guidance about alternate phrasings or closely related methods that should be coded as equivalent to that reference strategy
-
[46]
Judge whether the generated strategy reaches the target result
-
[47]
Assign exactly one “assigned_strategy_id”: a reference strategy_id, “novel”, or “uncertain”. Important coding rules:
-
[48]
Strategy match Assign “assigned_strategy_id” as follows: - Use a reference “strategy_id” if the generated strategy uses the same core mathematical method or reasoning structure as that reference strategy. - Use “novel” if the generated strategy is clearly different from every reference strategy. - Use “uncertain” only if the generated strategy is too vagu...
-
[49]
Validity Code “strategy_valid” separately from strategy match: - Use “1” if the generated strategy is mathematically valid and leads to the correct final answer. - Use “0” if the generated strategy contains a mathematical error, unsupported claim, contradiction, or wrong final answer. - Use “uncertain” if there is not enough information to judge validity
-
[50]
Target result correctness Code “result_correct” separately from strategy validity: - Use “1” if the generated strategy reaches the correct target result. - Use “0” if the generated strategy reaches an incorrect target result. - Use “uncertain” if the generated strategy does not provide enough information to judge the target result. - For most problems, th...
-
[51]
Important distinction A generated strategy can: - match a reference strategy and be valid; 14 - match a reference strategy but be invalid; - be novel and valid; - be novel and invalid; - be uncertain in match but still valid or invalid; - have invalid reasoning but accidentally reach the correct target result; - use valid reasoning but report an incorrect...
-
[52]
Missing fields Some generated strategies may have a blank “generated_method_summary”. If so, judge using the strategy name, key steps, final answer, problem text, and reference strategies
-
[53]
1.0” means completely confident. - “0.8
Confidence Use confidence scores between 0 and 1: - “1.0” means completely confident. - “0.8” means fairly confident. - “0.5” means uncertain or weak evidence. - Below “0.5” should be rare. Return ONLY valid JSON with this exact schema: { “assigned_strategy_id”: “...”, “strategy_match_confidence”: 0.0, “strategy_valid”: 0, “validity_confidence”: 0.0, “res...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.