Recognition: 2 theorem links
· Lean TheoremSoohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
Pith reviewed 2026-05-12 01:49 UTC · model grok-4.3
The pith
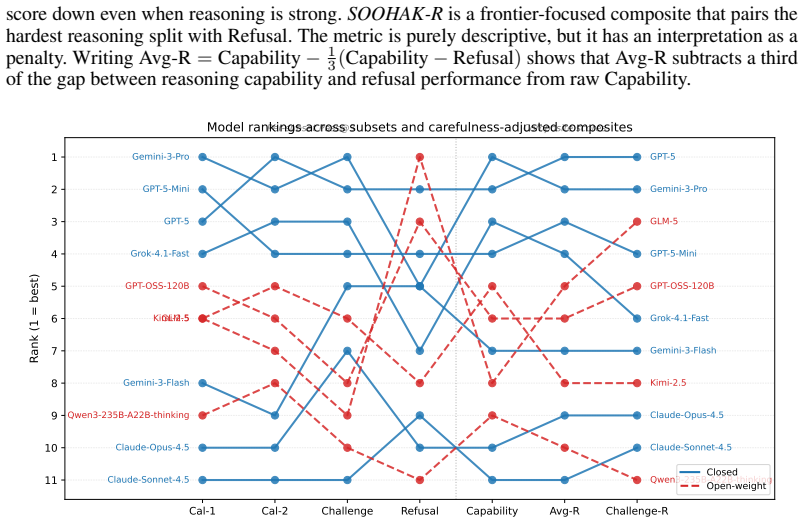
A benchmark of 439 original research-level math problems shows frontier LLMs solve at most 30 percent and recognize ill-posed questions less than half the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Soohak comprises 439 problems newly authored from scratch by 64 mathematicians. On the Challenge subset, models such as Gemini-3-Pro reach 30.4 percent accuracy, GPT-5 26.4 percent, and Claude-Opus-4.5 10.4 percent. On the refusal subset, which tests recognition of ill-posed problems, no model exceeds 50 percent accuracy. This demonstrates substantial remaining headroom in research-level mathematical reasoning and identifies refusal as an unoptimized capability.
What carries the argument
The refusal subset, a collection of deliberately ill-posed problems that requires models to pause rather than produce confident but unjustified answers.
If this is right
- Model development must target both higher accuracy on novel problems and the ability to decline ill-posed queries.
- Refusal becomes an explicit optimization target rather than an incidental byproduct of training.
- Benchmarks that separate solvable research problems from ill-posed ones will replace olympiad-style tests as the next standard for measuring progress.
- Open-weight models will require additional work to close the gap with closed frontier systems on these tasks.
Where Pith is reading between the lines
- Training signals that reward refusal on bad problems could be added without harming performance on well-posed ones.
- The benchmark could serve as a filter to test whether models can help explore open mathematical questions instead of only solving closed ones.
- Persistent low refusal rates suggest current systems optimize for answer generation even when evidence is insufficient.
Load-bearing premise
The 439 problems are genuinely original, uncontaminated by training data, and correctly classified as research-level by the mathematicians who authored them.
What would settle it
A model scoring above 70 percent on the challenge subset or above 70 percent on the refusal subset, or discovery that a substantial fraction of the problems already appears in public training corpora.
Figures



read the original abstract
Following the recent achievement of gold-medal performance on the IMO by frontier LLMs, the community is searching for the next meaningful and challenging target for measuring LLM reasoning. Whereas olympiad-style problems measure step-by-step reasoning alone, research-level problems use such reasoning to advance the frontier of mathematical knowledge itself, emerging as a compelling alternative. Yet research-level math benchmarks remain scarce because such problems are difficult to source (e.g., Riemann Bench and FrontierMath-Tier 4 contain 25 and 50 problems, respectively). To support reliable evaluation of next-generation frontier models, we introduce Soohak, a 439-problem benchmark newly authored from scratch by 64 mathematicians. Soohak comprises two subsets. On the Challenge subset, frontier models including Gemini-3-Pro, GPT-5, and Claude-Opus-4.5 reach 30.4%, 26.4%, and 10.4% respectively, leaving substantial headroom, while leading open-weight models such as Qwen3-235B, GPT-OSS-120B, and Kimi-2.5 remain below 15%. Notably, beyond standard problem solving, Soohak introduces a refusal subset that probes a capability intrinsic to research mathematics: recognizing ill-posed problems and pausing rather than producing confident but unjustified answers. On this subset, no model exceeds 50%, identifying refusal as a new optimization target that current models do not directly address. To prevent contamination, the dataset will be publicly released in late 2026, with model evaluations available upon request in the interim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Soohak, a 439-problem benchmark for evaluating research-level mathematical capabilities of LLMs, curated from scratch by 64 mathematicians. It consists of a Challenge subset and a refusal subset. Frontier models achieve 30.4% (Gemini-3-Pro), 26.4% (GPT-5), and 10.4% (Claude-Opus-4.5) on the Challenge subset, with open models below 15%, while no model exceeds 50% on the refusal subset. The authors argue this leaves substantial headroom and identifies refusal as a new optimization target. The dataset will be released in late 2026 to prevent contamination, with evaluations available upon request.
Significance. Should the benchmark problems prove to be original, uncontaminated, and genuinely research-level as claimed, Soohak would represent a significant contribution by providing a scalable alternative to smaller benchmarks like Riemann Bench and FrontierMath-Tier 4. The explicit focus on refusal capabilities addresses an important gap in current LLM evaluation, as recognizing ill-posed problems is intrinsic to research mathematics. The mathematician curation by 64 experts is a strength that enhances credibility.
major comments (2)
- [Abstract] The manuscript does not detail the evaluation protocol, the process by which the 64 mathematicians verified the problems as research-level, or any statistical measures of significance for the reported accuracies (e.g., 30.4% on Challenge). These omissions are load-bearing because the central claims about model performance and headroom depend on the reliability of these numbers.
- [Abstract] Withholding the full 439-problem dataset until late 2026 prevents independent verification that the problems are original and uncontaminated by training data, and that the refusal subset contains genuinely ill-posed questions. This makes the empirical results non-reproducible in the current manuscript and weakens the assertion of a new optimization target.
minor comments (1)
- Consider including one or two example problems from each subset in the main text to better illustrate the distinction between olympiad-style and research-level problems.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and have revised the paper accordingly to strengthen the presentation of the evaluation details and reproducibility measures.
read point-by-point responses
-
Referee: [Abstract] The manuscript does not detail the evaluation protocol, the process by which the 64 mathematicians verified the problems as research-level, or any statistical measures of significance for the reported accuracies (e.g., 30.4% on Challenge). These omissions are load-bearing because the central claims about model performance and headroom depend on the reliability of these numbers.
Authors: We agree that additional methodological details are necessary to support the reliability of the reported results. In the revised manuscript, we have added a new subsection under Methods that describes the evaluation protocol in full, including the multi-stage verification process used by the 64 mathematicians to confirm that problems are research-level (involving independent review, discussion of mathematical novelty, and consensus). We also now include 95% confidence intervals computed via bootstrap resampling for all accuracy figures on the Challenge subset to quantify statistical significance and variability. revision: yes
-
Referee: [Abstract] Withholding the full 439-problem dataset until late 2026 prevents independent verification that the problems are original and uncontaminated by training data, and that the refusal subset contains genuinely ill-posed questions. This makes the empirical results non-reproducible in the current manuscript and weakens the assertion of a new optimization target.
Authors: We recognize the tension between long-term benchmark integrity and immediate reproducibility. The delayed public release is explicitly motivated by the need to minimize contamination risk from rapidly evolving training corpora, a practice adopted by other recent math benchmarks. To address this in the interim, the revised manuscript now provides: (1) a detailed account of the curation workflow that establishes originality (each problem authored by a mathematician with no prior public dissemination), (2) anonymized examples from the refusal subset illustrating ill-posedness, and (3) an explicit invitation for researchers to request the full evaluation logs and problem statements under a data-use agreement. We maintain that these steps allow the core empirical claims to be evaluated while preserving the benchmark's future utility. revision: partial
Circularity Check
No circularity; empirical benchmark with no derivations or self-referential reductions
full rationale
The paper introduces Soohak as a new 439-problem benchmark authored from scratch by 64 mathematicians and reports direct empirical accuracies (e.g., 30.4% on Challenge subset for Gemini-3-Pro). No equations, fitted parameters, predictions derived from inputs, self-citations used as load-bearing uniqueness theorems, or ansatzes appear in the text. The central claims rest on the stated originality of the problems and the withheld dataset's future release rather than any internal derivation chain that reduces to its own inputs by construction. This is a standard empirical benchmark paper with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe introduce SOOHAK, a 439-problem benchmark newly authored from scratch by 64 mathematicians... refusal subset that probes... recognizing ill-posed problems
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery theorems unclearThe full collection is temporarily embargoed, with public release planned in late 2026
Reference graph
Works this paper leans on
-
[1]
First Proof.arXiv preprintarXiv:2602.05192, 2026
Abouzaid, M., Blumberg, A. J., Hairer, M., Kileel, J., Kolda, T. G., Nelson, P. D., Spiel- man, D., Srivastava, N., Ward, R., Weinberger, S., et al. (2026). First proof.arXiv preprint arXiv:2602.05192
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y ., Baker, B., Bao, H., et al. (2025). gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
Alexeev, B., Putterman, M., Sawhney, M., Sellke, M., and Valiant, G. (2026b). Short proofs in combinatorics, probability and number theory ii.arXiv preprint arXiv:2604.06609
work page internal anchor Pith review Pith/arXiv arXiv
- [5]
-
[6]
Anthropic (2025). Introducing Claude Opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5. Accessed: 2026-05-04
work page 2025
-
[7]
American invitational mathematics examination (aime)
Art of Problem Solving (2025). American invitational mathematics examination (aime). https: //artofproblemsolving.com/wiki/index.php/AIME. Accessed: 2026-01-24
work page 2025
-
[8]
Balunovi´c, M., Dekoninck, J., Petrov, I., Jovanovi ´c, N., and Vechev, M. (2025). Matharena: Evaluating llms on uncontaminated math competitions
work page 2025
-
[9]
Burnham, G. (2025). Less than 70% of FrontierMath is within reach for today’s models. Epoch AI, Gradient Updates. Accessed: 2026-02-24
work page 2025
-
[10]
ByteDance-Seed (2025). BeyondAIME: Advancing Math Reasoning Evaluation Beyond High School Olympiads.https://huggingface.co/datasets/ByteDance-Seed/BeyondAIME
work page 2025
-
[11]
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. (2021). Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [12]
-
[13]
Gao, B., Song, F., Yang, Z., Cai, Z., Miao, Y ., Dong, Q., Li, L., Ma, C., Chen, L., Xu, R., Tang, Z., Wang, B., Zan, D., Quan, S., Zhang, G., Sha, L., Zhang, Y ., Ren, X., Liu, T., and Chang, B. (2025). Omni-MATH: A universal olympiad level mathematic benchmark for large language models. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[14]
Garre, S., Knutsen, E., Mehta, S., and Chen, E. (2026). Riemann-bench: A benchmark for moonshot mathematics.arXiv preprint arXiv:2604.06802
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Glazer, E., Erdil, E., Besiroglu, T., Chicharro, D., Chen, E., Gunning, A., Olsson, C. F., Denain, J.-S., Ho, A., Santos, E. d. O., et al. (2024). Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai.arXiv preprint arXiv:2411.04872. 10
-
[16]
Gemini 3.1 Pro.https://deepmind.google/models/gemini/ pro/
Google DeepMind (2026). Gemini 3.1 Pro.https://deepmind.google/models/gemini/ pro/. Accessed: 2026-05-04
work page 2026
-
[17]
Guha, E., Marten, R., Keh, S., Raoof, N., Smyrnis, G., Bansal, H., Nezhurina, M., Mercat, J., Vu, T., Sprague, Z., et al. (2025). Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178
work page internal anchor Pith review arXiv 2025
-
[18]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. (2021). Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
work page 2021
- [20]
-
[21]
Ko, H., Son, G., and Choi, D. (2025). Understand, solve and translate: Bridging the multilingual mathematical reasoning gap. InProceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025), pages 78–95
work page 2025
-
[22]
Ma, J., Wang, G., Feng, X., Liu, Y ., Hu, Z., and Liu, Y . (2026). Eternalmath: A living benchmark of frontier mathematics that evolves with human discovery.arXiv preprint arXiv:2601.01400
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
proprietary ai foundation model
Ministry of Science and ICT (MSIT) (2025). “proprietary ai foundation model” project enters full-scale launch. Accessed 2026-02-15
work page 2025
-
[24]
Phan, L., Gatti, A., Han, Z., Li, N., Hu, J., Zhang, H., Zhang, C. B. C., Shaaban, M., Ling, J., Shi, S., et al. (2025). Humanity’s Last Exam.arXiv preprint arXiv:2501.14249
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
-
[26]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. (2025). Openai gpt-5 system card.arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Skarlinski, M., Laurent, J., Bou, A., and White, A. (2025). About 30% of humanity’s last exam chemistry/biology answers are likely wrong. FutureHouse, Research Announcement. Accessed: 2026-02-24
work page 2025
-
[28]
Stump, C. (2025). Math sciencebench: Challenge the newest ai models with your hardest phd-level exercises.https://math.science-bench.ai/. Accessed: 2026-02
work page 2025
-
[29]
Team, K., Bai, T., Bai, Y ., Bao, Y ., Cai, S., Cao, Y ., Charles, Y ., Che, H., Chen, C., Chen, G., et al. (2026). Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. (2025). Qwen3 technical report.arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
GLM-5.1: Towards Long-Horizon Tasks
Z.ai (2026). GLM-5.1: Towards Long-Horizon Tasks. https://z.ai/blog/glm-5.1. Ac- cessed: 2026-05-04
work page 2026
- [32]
-
[33]
Zhang, J., Petrui, C., Nikoli´c, K., and Tramèr, F. (2025). Realmath: A continuous benchmark for evaluating language models on research-level mathematics.arXiv preprint arXiv:2505.12575. 11 A Author affiliations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .12 B Data collection details. . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.