Recognition: unknown
FedDetox: Robust Federated SLM Alignment via On-Device Data Sanitization
Pith reviewed 2026-05-10 17:17 UTC · model grok-4.3
The pith
On-device sanitization with distilled classifiers lets federated SLM alignment preserve safety despite toxic user data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
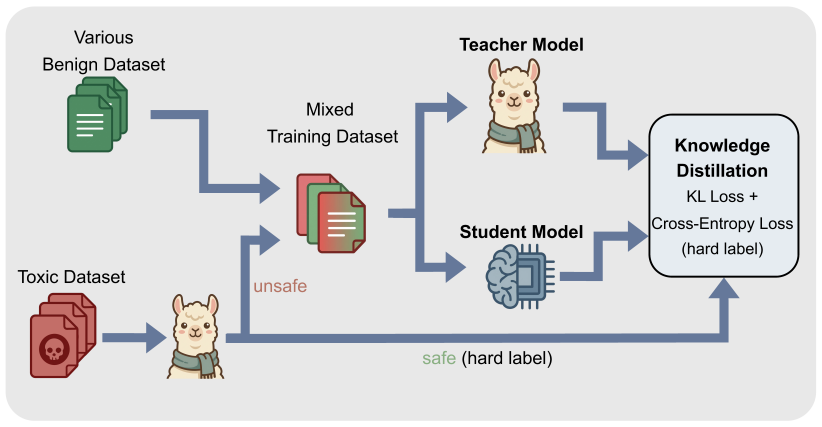
The central claim is that distilling safety alignment capabilities from large teacher models into lightweight student classifiers enables on-device detection and replacement of unsafe samples with refusal templates, thereby transforming potential unintended poisons into positive safety signals during federated human preference alignment for SLMs and preserving model safety at levels comparable to centralized baselines.
What carries the argument
Lightweight student classifiers from knowledge distillation that run on resource-constrained devices to identify unsafe samples and replace them with refusal templates before they enter federated training.
If this is right
- Federated SLM training can incorporate real private user data for alignment without safety degradation from toxic content.
- General model capabilities on standard tasks remain intact after the sanitization step.
- Safety enforcement happens locally at each client rather than after data aggregation at the server.
- Potential poisoning is neutralized at the data source by turning unsafe examples into refusal signals.
Where Pith is reading between the lines
- Local sanitization reduces the privacy exposure that would occur if raw client data were sent to a central filter.
- The same distillation technique could transfer other complex capabilities beyond safety to devices for federated tasks.
Load-bearing premise
The distilled lightweight classifiers must identify unsafe samples accurately enough on edge devices to stop toxic data from reaching the global model.
What would settle it
A controlled experiment in which the student classifiers miss a measurable fraction of unsafe samples and the resulting federated model exhibits lower safety metrics than a centralized baseline would falsify the claim.
Figures



read the original abstract
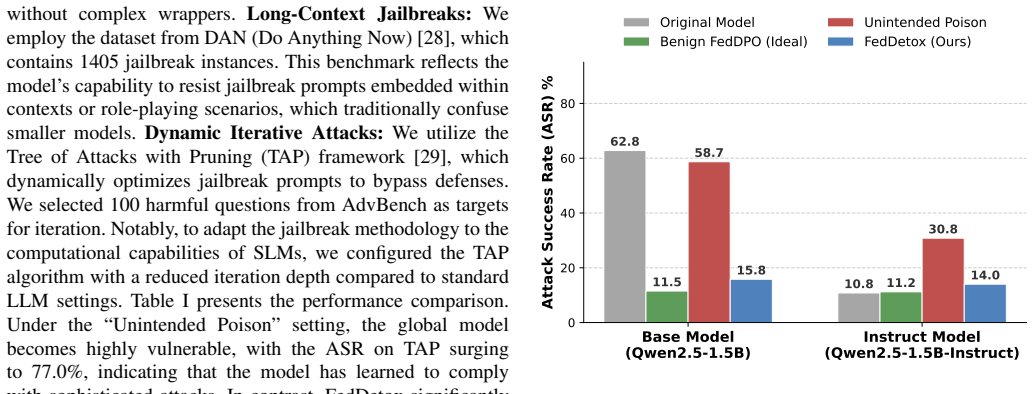
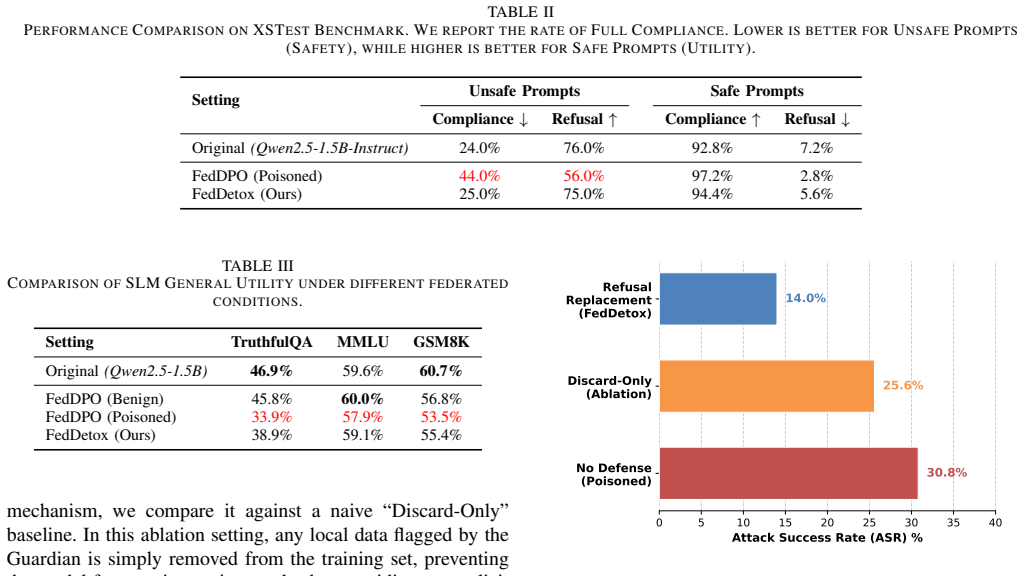
As high quality public data becomes scarce, Federated Learning (FL) provides a vital pathway to leverage valuable private user data while preserving privacy. However, real-world client data often contains toxic or unsafe information. This leads to a critical issue we define as unintended data poisoning, which can severely damage the safety alignment of global models during federated alignment. To address this, we propose FedDetox, a robust framework tailored for Small Language Models (SLMs) on resource-constrained edge devices. We first employ knowledge distillation to transfer sophisticated safety alignment capabilities from large scale safety aligned teacher models into light weight student classifiers suitable for resource constrained edge devices. Specifically, during federated learning for human preference alignment, the edge client identifies unsafe samples at the source and replaces them with refusal templates, effectively transforming potential poisons into positive safety signals. Experiments demonstrate that our approach preserves model safety at a level comparable to centralized baselines without compromising general utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedDetox, a framework for federated alignment of small language models (SLMs) on resource-constrained edge devices. It applies knowledge distillation to transfer safety capabilities from large teacher models to lightweight student classifiers, which run on-device to detect unsafe samples in client data during federated human preference alignment; detected unsafe samples are replaced with refusal templates to convert potential poisons into positive safety signals. The central claim is that this on-device sanitization preserves model safety at levels comparable to centralized baselines without compromising general utility.
Significance. If the empirical claims hold, the work would provide a practical mechanism for mitigating unintended data poisoning in federated SLM alignment while respecting device constraints and privacy, addressing a growing concern as public data scarcity pushes reliance on private client data.
major comments (2)
- [Abstract] Abstract: the assertion that 'Experiments demonstrate that our approach preserves model safety at a level comparable to centralized baselines without compromising general utility' supplies no datasets, metrics (e.g., safety scores such as toxicity rates or refusal rates), baselines, or ablation results, rendering the central empirical claim unverifiable from the manuscript.
- [Method] Method description (on-device sanitization via student classifiers): the safety-preservation argument rests on the assumption that the distilled lightweight student classifiers achieve sufficient recall on unsafe samples under realistic client distributions; no precision/recall/F1 numbers, comparison to the teacher, or analysis of distillation-induced coverage loss on nuanced toxicity are reported, leaving the load-bearing detection step unsubstantiated.
Simulated Author's Rebuttal
We appreciate the referee's feedback on improving the verifiability of our claims in the abstract and the substantiation of the on-device sanitization method. We provide point-by-point responses below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments demonstrate that our approach preserves model safety at a level comparable to centralized baselines without compromising general utility' supplies no datasets, metrics (e.g., safety scores such as toxicity rates or refusal rates), baselines, or ablation results, rendering the central empirical claim unverifiable from the manuscript.
Authors: We agree that the abstract, constrained by length, omits specific details on datasets, metrics, baselines, and ablations. The full manuscript's experimental section reports these elements, including evaluations on safety benchmarks with toxicity and refusal rates alongside centralized comparisons. To enhance verifiability directly from the abstract, we will revise it to incorporate key quantitative results and references to the supporting experiments. revision: yes
-
Referee: [Method] Method description (on-device sanitization via student classifiers): the safety-preservation argument rests on the assumption that the distilled lightweight student classifiers achieve sufficient recall on unsafe samples under realistic client distributions; no precision/recall/F1 numbers, comparison to the teacher, or analysis of distillation-induced coverage loss on nuanced toxicity are reported, leaving the load-bearing detection step unsubstantiated.
Authors: We concur that explicit metrics for the student classifiers are needed to substantiate the detection performance. The method section outlines the distillation process, but we will add a dedicated analysis in the revised manuscript reporting precision, recall, and F1 scores on unsafe sample detection, comparisons to the teacher model, and evaluation of any coverage loss for nuanced toxicity under client-like distributions. revision: yes
Circularity Check
No circularity: purely empirical framework with no derivations or self-referential claims
full rationale
The paper describes an applied system (knowledge distillation to on-device classifiers, replacement of detected unsafe samples with refusal templates during federated alignment) and reports experimental comparisons to centralized baselines. No equations, parameter-fitting steps, predictions derived from fitted values, or first-principles derivations appear in the abstract or described content. The central claim rests on empirical outcomes rather than any chain that reduces to its own inputs by construction. Self-citations, if present in the full text, are not load-bearing for any definitional or predictive step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Knowledge distillation from large safety-aligned models transfers usable safety detection capability to lightweight classifiers suitable for edge devices.
- domain assumption On-device identification of unsafe samples is accurate enough that replacement with refusal templates converts poisons into positive signals without introducing new harms.
Reference graph
Works this paper leans on
-
[1]
Position: Will we run out of data? limits of LLM scaling based on human-generated data,
P. Villalobos, A. Ho, J. Sevilla, T. Besiroglu, L. Heim, and M. Hobbhahn, “Position: Will we run out of data? limits of LLM scaling based on human-generated data,” inProc. of the 41st International Conference on Machine Learning (ICML), 2024, pp. 5170–5192
2024
-
[2]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial Intelligence and Statistics (AISTATS). PMLR, 2017, pp. 1273–1282
2017
-
[3]
A survey of small language models,
C. V . Nguyen, X. Shen, R. Aponte, Y . Xia, S. Basu, Z. Hu, J. Chenet al., “A survey of small language models,”arXiv preprint arXiv:2410.20011, 2024
-
[4]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”arXiv preprint arXiv:2203.02155, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggine, and M. Khabsa, “Llama Guard: LLM-based input-output safeguard for human-AI conversations,”arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
J. Zhang, S. Vahidian, M. Kuo, C. Li, R. Zhang, G. Wang, and Y . Chen, “Towards building the federated GPT: Federated instruction tuning,” arXiv preprint arXiv:2305.05644, 2023
-
[7]
Improving lora in privacy-preserving federated learning.arXiv preprint arXiv:2403.12313, 2024
Y . Sun, Z. Li, Y . Li, and B. Ding, “Improving LoRA in privacy- preserving federated learning,”arXiv preprint arXiv:2403.12313, 2024
-
[8]
LoRA-Fair: Federated LoRA fine-tuning with aggregation and initialization refinement,
J. Bian, L. Wang, L. Zhang, and J. Xu, “LoRA-Fair: Federated LoRA fine-tuning with aggregation and initialization refinement,”arXiv preprint arXiv:2411.14961, 2024
-
[9]
PluralLLM: Pluralistic alignment in LLMs via federated learning,
M. Srewa, T. Zhao, and S. Elmalaki, “PluralLLM: Pluralistic alignment in LLMs via federated learning,”arXiv preprint arXiv:2503.09925, 2025
-
[10]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023, pp. 53 728–53 741
2023
-
[11]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Challenges and approaches for mitigating byzantine attacks in federated learning,
J. Shi, W. Wan, S. Hu, J. Lu, and L. Y . Zhang, “Challenges and approaches for mitigating byzantine attacks in federated learning,” inIEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), 2022, pp. 139–146
2022
-
[13]
Byzantine-tolerant machine learning,
P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, “Byzantine-tolerant machine learning,”arXiv preprint arXiv:1703.02757, 2017
-
[14]
Backdoor attacks and defenses in federated learning: Survey, challenges and future research directions,
T. D. Nguyen, T. Nguyen, P. L. Nguyen, H. H. Pham, K. D. Doan, and K.-S. Wong, “Backdoor attacks and defenses in federated learning: Survey, challenges and future research directions,”Engineering Appli- cations of Artificial Intelligence, vol. 127, p. 107166, 2024
2024
-
[15]
Revisiting backdoor threat in federated instruction tuning from a signal aggregation perspective,
H. Zhao, J. Hu, and G. Liu, “Revisiting backdoor threat in federated instruction tuning from a signal aggregation perspective,”arXiv preprint arXiv:2602.15671, 2026
-
[16]
Emerging safety attack and defense in federated instruction tuning of large language models,
R. Ye, J. Chai, X. Liu, Y . Yang, Y . Wang, and S. Chen, “Emerging safety attack and defense in federated instruction tuning of large language models,”arXiv preprint arXiv:2406.10630, 2024
-
[17]
P. Pathmanathan, S. Chakraborty, X. Liu, Y . Liang, and F. Huang, “Is poisoning a real threat to LLM alignment? maybe more so than you think,”arXiv preprint arXiv:2406.12091, 2024
-
[18]
A holistic approach to undesired content detection in the real world,
T. Markov, C. Zhang, S. Agarwal, F. E. Nekoul, T. Lee, S. Adler, A. Jiang, and L. Weng, “A holistic approach to undesired content detection in the real world,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 12, 2023, pp. 15 009–15 018
2023
-
[19]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huanget al., “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
S. Mukherjee, A. Mitra, G. Jawahar, S. Agarwal, H. Palangi, and A. Awadallah, “Orca: Progressive learning from complex explanation traces of GPT-4,”arXiv preprint arXiv:2306.02707, 2023
-
[21]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
D. Ganguli, L. Lovitt, J. Kernion, A. Askell, Y . Bai, S. Kadavath, B. Mann, E. Perezet al., “Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned,”arXiv preprint arXiv:2209.07858, 2022
work page internal anchor Pith review arXiv 2022
-
[22]
SORRY-Bench: Systematically evaluat- ing large language model safety refusal,
T. Xie, X. Qi, Y . Zeng, Y . Huang, U. M. Sehwag, K. Huang, L. He, B. Wei, D. Li, Y . Shenget al., “SORRY-Bench: Systematically evaluat- ing large language model safety refusal,” inProc. of the International Conference on Learning Representations (ICLR), 2025
2025
-
[23]
A. Dubey, A. Jauhri, A. Pandey, A. Keshvamurthyet al., “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
MobileBERT: a compact task-agnostic BERT for resource-limited devices,
Z. Sun, H. Yu, X. Song, R. Liu, Y . Yang, and D. Zhou, “MobileBERT: a compact task-agnostic BERT for resource-limited devices,” inProc. of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020, pp. 2158–2170
2020
-
[25]
J. Ji, D. Hong, B. Zhang, B. Chen, J. Dai, B. Zheng, T. Qiu, B. Li, and Y . Yang, “PKU-SafeRLHF: Towards multi-level safety alignment for LLMs with human preference,”arXiv preprint arXiv:2406.15513, 2024
-
[26]
arXiv:2310.17389 (2023), https://arxiv.org/abs/2310.17389
Z. Lin, Z. Wang, Y . Tong, Y . Wang, Y . Guo, Y . Wang, and J. Shang, “ToxicChat: Unveiling hidden challenges of toxicity detection in real- world user-AI conversation,”arXiv preprint arXiv:2310.17389, 2023
-
[27]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, ““Do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,”arXiv preprint arXiv:2308.03825, 2024
-
[29]
Tree of attacks: jailbreaking black-box LLMs automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y . Singer, and A. Karbasi, “Tree of attacks: jailbreaking black-box LLMs automatically,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[30]
XSTest: A test suite for identifying exaggerated safety behaviours in large language models,
P. R ¨ottger, H. Kirk, B. Vidgen, G. Attanasio, F. Bianchi, and D. Hovy, “XSTest: A test suite for identifying exaggerated safety behaviours in large language models,” inProc. of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024, pp. 5377–5400
2024
-
[31]
Mitigating the alignment tax of RLHF,
Y . Lin, H. Lin, W. Xiong, S. Diao, J. Liu, J. Zhang, R. Panet al., “Mitigating the alignment tax of RLHF,” inProc. of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024, pp. 580–606
2024
-
[32]
Measuring massive multitask language understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” inProc. of the International Conference on Learning Representations (ICLR), 2021
2021
-
[33]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworeket al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
TruthfulQA: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “TruthfulQA: Measuring how models mimic human falsehoods,” inProc. of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022, pp. 3214–3252
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.