Recognition: 1 theorem link
· Lean TheoremOn the Step Length Confounding in LLM Reasoning Data Selection
Pith reviewed 2026-05-10 18:56 UTC · model grok-4.3
The pith
Naturalness-based selection for LLM reasoning data favors longer steps over higher quality due to first-token effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
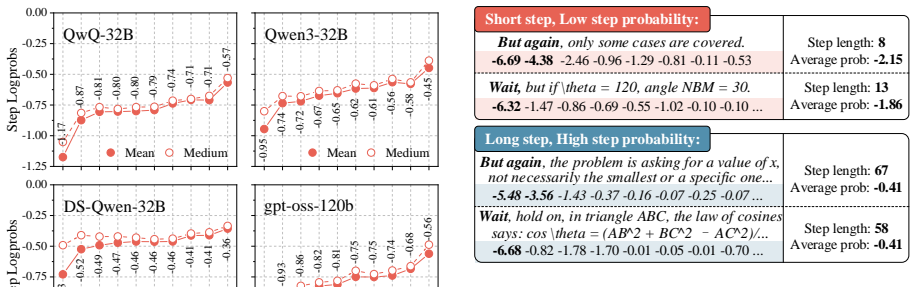
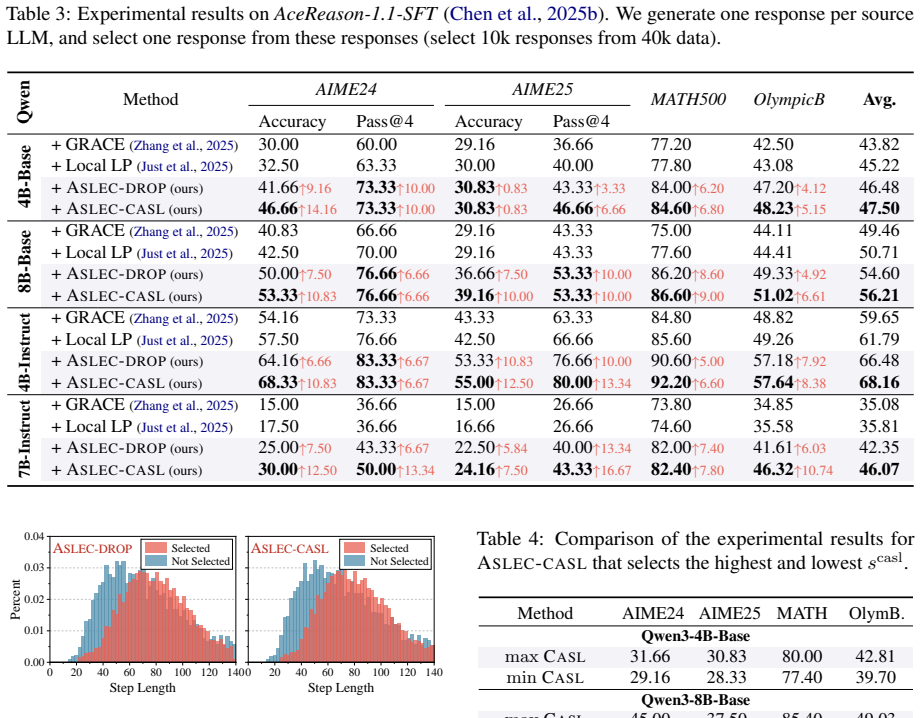
The authors establish that the standard naturalness metric for selecting high-quality chain-of-thought data in large language models is biased toward longer reasoning steps. This step length confounding arises because low-probability tokens at the start of each step have their negative impact diluted when steps contain more tokens. By proposing ASLEC-DROP and ASLEC-CASL to neutralize this effect, they show improved data quality for fine-tuning reasoning models.
What carries the argument
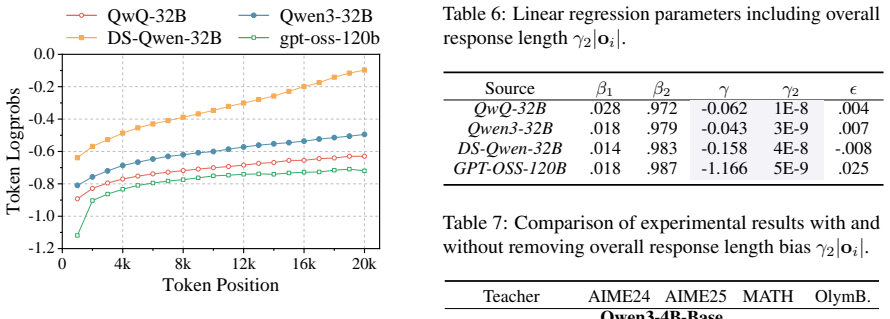
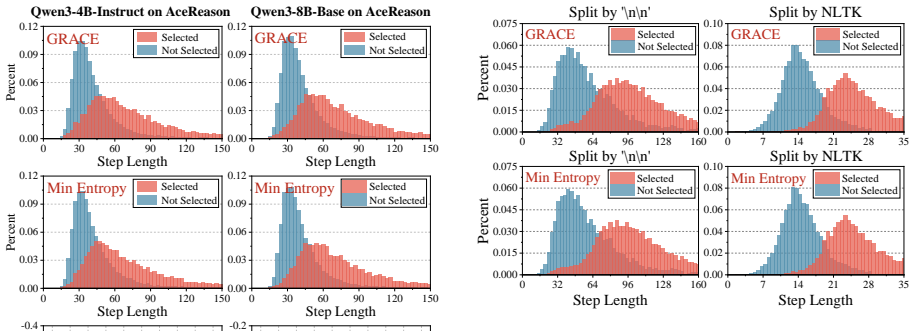
Step length confounding in average log probability scoring, where low-probability first tokens of reasoning steps lose influence as step length increases.
If this is right
- Corrected selection produces training sets that improve LLM performance on complex reasoning tasks.
- Average log probability alone is insufficient for quality assessment when reasoning data is organized in discrete steps.
- The two correction techniques apply consistently across multiple base models and evaluation suites.
- Causal regression offers a general way to remove token-position biases in probability-based data filters.
Where Pith is reading between the lines
- Similar length-based distortions may affect probability averaging in other step-wise or hierarchical generation tasks.
- Future synthetic data pipelines for reasoning models should include routine checks for first-token or position effects.
- The finding suggests that apparent naturalness in long chains can mask lower per-step quality.
Load-bearing premise
That removing the step-length effect via first-token dropping or causal regression selects genuinely higher-quality reasoning data rather than merely different data whose downstream benefit is not guaranteed beyond the reported experiments.
What would settle it
Train LLMs on data selected by the original naturalness score versus the corrected methods and measure whether the corrected selections produce equal or lower accuracy on held-out reasoning benchmarks.
Figures




read the original abstract
Large reasoning models have recently demonstrated strong performance on complex tasks that require long chain-of-thought reasoning, through supervised fine-tuning on large-scale and high-quality datasets. To construct such datasets, existing pipelines generate long reasoning data from more capable Large Language Models (LLMs) and apply manually heuristic or naturalness-based selection methods to filter high-quality samples. Despite the proven effectiveness of naturalness-based data selection, which ranks data by the average log probability assigned by LLMs, our analysis shows that, when applied to LLM reasoning datasets, it systematically prefers samples with longer reasoning steps (i.e., more tokens per step) rather than higher-quality ones, a phenomenon we term step length confounding. Through quantitative analysis, we attribute this phenomenon to low-probability first tokens in reasoning steps; longer steps dilute their influence, thereby inflating the average log probabilities. To address this issue, we propose two variant methods: ASLEC-DROP, which drops first-token probabilities when computing average log probability, and ASLEC-CASL, which applies a causal debiasing regression to remove the first tokens' confounding effect. Experiments across four LLMs and five evaluation benchmarks demonstrate the effectiveness of our approach in mitigating the step length confounding problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that naturalness-based data selection via average log-probability on LLM reasoning datasets exhibits 'step length confounding,' systematically favoring samples with longer reasoning steps because low-probability first tokens are diluted in longer sequences. It attributes this mechanistically to first-token effects, introduces ASLEC-DROP (dropping first-token probabilities) and ASLEC-CASL (causal regression debiasing), and reports that both variants yield better downstream performance than the original metric across four LLMs and five benchmarks.
Significance. If the debiasing methods reliably recover higher-quality reasoning traces rather than merely length-adjusted ones, the work would meaningfully advance data curation practices for supervised fine-tuning of reasoning models. The mechanistic attribution of the confounding effect is a clear, actionable insight that could reduce reliance on heuristic filters and improve the efficiency of constructing long-CoT datasets.
major comments (1)
- [Abstract] Abstract and experimental validation: the central claim that ASLEC-DROP and ASLEC-CASL select 'higher-quality' data (rather than simply different data whose length distribution has been altered) rests exclusively on downstream benchmark gains. No orthogonal quality signal—such as human coherence ratings, step-level correctness verification, or error analysis independent of surface statistics—is reported to confirm that the newly selected samples are superior reasoning traces.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation. We address the major comment point by point below, acknowledging where revisions are needed to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental validation: the central claim that ASLEC-DROP and ASLEC-CASL select 'higher-quality' data (rather than simply different data whose length distribution has been altered) rests exclusively on downstream benchmark gains. No orthogonal quality signal—such as human coherence ratings, step-level correctness verification, or error analysis independent of surface statistics—is reported to confirm that the newly selected samples are superior reasoning traces.
Authors: We agree that the manuscript's evidence for improved data selection rests primarily on downstream benchmark improvements across four LLMs and five tasks, which directly measure the practical utility of the selected reasoning traces for supervised fine-tuning. This metric is standard in data curation literature because it evaluates end-to-end impact on model reasoning performance rather than proxy signals. However, the referee is correct that we do not provide independent orthogonal validation such as human ratings or step-level error analysis. In the revision we will (1) qualify the abstract and introduction to emphasize that ASLEC variants mitigate step-length confounding and yield data with better downstream utility, without overclaiming absolute 'higher quality'; (2) add a new subsection with quantitative comparison of step-length distributions, first-token probability statistics, and average reasoning-step coherence proxies (e.g., token entropy) between original and debiased selections to demonstrate the mechanistic effect; and (3) include a brief limitations paragraph noting the absence of human or manual verification and suggesting it as future work. These changes will make the claims more precise while preserving the core experimental results. revision: partial
Circularity Check
No significant circularity in derivation of step-length confounding
full rationale
The paper derives the step-length confounding effect directly from the arithmetic definition of average log-probability (sum of token log-probs divided by sequence length), showing mathematically how low-probability first tokens are diluted in longer steps. The proposed ASLEC-DROP and ASLEC-CASL variants are explicit, non-circular corrections (dropping or regressing the first-token term) whose claimed benefit is tested against external downstream benchmarks rather than by re-fitting or redefining quality within the same metric. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the core chain; the analysis remains self-contained against observable probability distributions and held-out task performance.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Prefix Teach, Suffix Fade: Local Teachability Collapse in Strong-to-Weak On-Policy Distillation
Local teachability collapse in trajectory suffixes makes uniform dense supervision suboptimal in strong-to-weak OPD; truncating at BIC-style change points on teacher margin improves performance.
Reference graph
Works this paper leans on
-
[1]
Reasoning with exploration: An entropy per- spective.CoRR, abs/2506.14758. Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. 2025. The entropy mechanism of rein- forcement learning for reasoning language...
-
[2]
The Signal is in the Steps: Local Scoring for Reasoning Data Selection
Distilling reasoning into student llms: Lo- cal naturalness for selecting teacher data.CoRR, abs/2510.03988. Zhewei Kang, Xuandong Zhao, and Dawn Song. 2025. Scalable best-of-n selection for large language mod- els via self-certainty.CoRR, abs/2502.18581. Zhiqiang Kou, Junyang Chen, Xin-Qiang Cai, Xiaobo Xia, Ming-Kun Xie, Dong-Dong Wu, Biao Liu, Yuheng J...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Kaiyuan Liu, Shaotian Yan, Rui Miao, Bing Wang, Chen Shen, Jun Zhang, and Jieping Ye. 2026. Where did this sentence come from? tracing provenance in LLM reasoning distillation. InInternational Confer- ence on Learning Representations. Kevin Lu and Thinking Mac...
-
[4]
Scaling data-constrained language models. In Annual Conference on Neural Information Process- ing Systems. Niklas Muennighoff, Zitong Yang, Weijia Shi, Xi- ang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel J. Candès, and Tatsunori Hashimoto. 2025. s1: Simple test-time scaling.CoRR, abs/2501.19393. David Rein, Betty Li H...
work page Pith review arXiv 2025
-
[5]
The best instruction-tuning data are those that fit,
Differential fine-tuning large language models towards better diverse reasoning abilities. InInterna- tional Conference on Learning Representations. Xiaosong Yuan, Chen Shen, Shaotian Yan, Xiaofeng Zhang, Liang Xie, Wenxiao Wang, Renchu Guan, Ying Wang, and Jieping Ye. 2024. Instance-adaptive zero-shot chain-of-thought prompting. InAdvances in Neural Info...
-
[6]
is one of the first to employ reinforce- ment learning to enhance long CoT reason- ing in LLMs, providing evidence that models obtained through distillation can still exhibit robust reasoning abilities. • gpt-oss-120b6 (Agarwal et al., 2025) improves inference speed by combining compact atten- tion layers with linear attention layers, while activating onl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.