Recognition: 3 theorem links
· Lean TheoremHingeMem: Boundary Guided Long-Term Memory with Query Adaptive Retrieval for Scalable Dialogues
Pith reviewed 2026-05-10 18:50 UTC · model grok-4.3
The pith
HingeMem builds long-term dialogue memory by drawing boundaries at changes in person, time, location, or topic and adapts retrieval to the query type.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HingeMem operationalizes event segmentation theory to construct an interpretable indexing interface using boundary-triggered hyperedges over four elements—person, time, location, and topic. Boundaries are drawn when any element changes, writing the current segment to reduce redundancy while preserving salient context. Query-adaptive retrieval then determines routing over the element-indexed memory and controls depth based on estimated query type, enabling efficient handling of diverse information needs.
What carries the argument
Boundary-triggered hyperedges indexed by changes in person, time, location, and topic, combined with query-conditioned routing and depth control for adaptive retrieval.
Load-bearing premise
That changes in the four elements reliably mark salient boundaries that preserve necessary context and that query-type estimation can be performed robustly enough to control retrieval depth without missing critical information.
What would settle it
A controlled experiment on dialogue sequences where an element change occurs but later queries require information from before the boundary, checking if retrieval accuracy drops compared to non-boundary methods.
Figures







read the original abstract
Long-term memory is critical for dialogue systems that support continuous, sustainable, and personalized interactions. However, existing methods rely on continuous summarization or OpenIE-based graph construction paired with fixed Top-\textit{k} retrieval, leading to limited adaptability across query categories and high computational overhead. In this paper, we propose HingeMem, a boundary-guided long-term memory that operationalizes event segmentation theory to build an interpretable indexing interface via boundary-triggered hyperedges over four elements: person, time, location, and topic. When any such element changes, HingeMem draws a boundary and writes the current segment, thereby reducing redundant operations and preserving salient context. To enable robust and efficient retrieval under diverse information needs, HingeMem introduces query-adaptive retrieval mechanisms that jointly decide (a) \textit{what to retrieve}: determine the query-conditioned routing over the element-indexed memory; (b) \textit{how much to retrieve}: control the retrieval depth based on the estimated query type. Extensive experiments across LLM scales (from 0.6B to production-tier models; \textit{e.g.}, Qwen3-0.6B to Qwen-Flash) on LOCOMO show that HingeMem achieves approximately $20\%$ relative improvement over strong baselines without query categories specification, while reducing computational cost (68\%$\downarrow$ question answering token cost compared to HippoRAG2). Beyond advancing memory modeling, HingeMem's adaptive retrieval makes it a strong fit for web applications requiring efficient and trustworthy memory over extended interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HingeMem, a boundary-guided long-term memory architecture for dialogue systems. It segments conversations by drawing boundaries on changes in any of four elements (person, time, location, topic) to form hyperedges, then applies query-adaptive retrieval that routes over element-indexed memory and controls depth via estimated query type. Experiments on LOCOMO across LLM scales (0.6B to production models) report ~20% relative gains over strong baselines and 68% lower QA token cost versus HippoRAG2.
Significance. If the empirical results prove robust, HingeMem would advance scalable long-term memory modeling by grounding segmentation in event theory and replacing fixed top-k retrieval with query-conditioned mechanisms, yielding both performance and efficiency benefits for extended interactions.
major comments (3)
- [§3.1] §3.1 (Boundary construction): The operationalization that a boundary is drawn exactly when any of the four elements changes is presented without human agreement studies or error analysis on cases of topic drift without element change; this assumption is load-bearing for the claim that salient context is preserved without loss.
- [§4] §4 (Experiments): The headline claims of ~20% relative improvement and 68% token reduction are reported without error bars, ablation controls on the query-type classifier, or data-exclusion rules, preventing assessment of whether the gains are reliable or sensitive to implementation details.
- [§3.2] §3.2 (Query-adaptive retrieval): No robustness checks or error analysis on query-type misclassification and resulting under-retrieval are provided; this directly affects the validity of the efficiency claims versus HippoRAG2.
minor comments (1)
- [Abstract] The abstract states gains 'without query categories specification' yet the method relies on LLM-based query-type estimation; a brief clarification of how types are derived without predefined categories would improve readability.
Simulated Author's Rebuttal
Thank you for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, outlining our responses and the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Boundary construction): The operationalization that a boundary is drawn exactly when any of the four elements changes is presented without human agreement studies or error analysis on cases of topic drift without element change; this assumption is load-bearing for the claim that salient context is preserved without loss.
Authors: We thank the referee for this observation. The boundary construction is explicitly motivated by event segmentation theory, where shifts in person, time, location, or topic serve as natural delimiters for dialogue events. While the manuscript does not include new human agreement studies, the four-element set is drawn from established dialogue and cognitive science literature. To directly address concerns about topic drift without element changes, we will add an error analysis subsection to §3.1 in the revision. This will examine instances from the LOCOMO dataset, quantify their occurrence, and assess impact on segmentation quality and downstream performance. We believe the reported gains provide supporting evidence, but the added analysis will strengthen the justification. revision: partial
-
Referee: [§4] §4 (Experiments): The headline claims of ~20% relative improvement and 68% token reduction are reported without error bars, ablation controls on the query-type classifier, or data-exclusion rules, preventing assessment of whether the gains are reliable or sensitive to implementation details.
Authors: We agree that error bars, ablations, and clearer data rules would improve assessment of reliability. In the revised manuscript, we will add error bars to the primary results (computed over multiple runs with varied seeds) and include a dedicated ablation on the query-type classifier to isolate its effect on both accuracy and token efficiency. We will also expand the experimental setup to explicitly state the data preprocessing steps and any exclusion criteria applied to LOCOMO. These changes will allow readers to better evaluate the robustness of the ~20% gains and 68% cost reduction. revision: yes
-
Referee: [§3.2] §3.2 (Query-adaptive retrieval): No robustness checks or error analysis on query-type misclassification and resulting under-retrieval are provided; this directly affects the validity of the efficiency claims versus HippoRAG2.
Authors: We acknowledge the value of analyzing query-type misclassification effects on retrieval. In the revision, we will add robustness checks and error analysis to §3.2, reporting the classifier's accuracy on held-out queries, characterizing misclassification patterns, and quantifying their influence on retrieval depth and token consumption. We will also include targeted comparisons showing performance under misclassified queries relative to HippoRAG2. This material will directly support the efficiency claims while highlighting any limitations of the adaptive mechanism. revision: yes
Circularity Check
No circularity: claims rest on experimental outcomes from a heuristically defined method
full rationale
The paper defines HingeMem via an operationalization of event segmentation theory that draws boundaries on changes to four elements (person/time/location/topic) and adds query-type-based adaptive retrieval depth. No equations, derivations, or self-citations appear that reduce the reported 20% gains or 68% token reductions to fitted parameters or prior results by construction. Performance numbers are presented strictly as measured outcomes on the LOCOMO benchmark against baselines, leaving the core argument self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Event segmentation theory can be operationalized by drawing boundaries on changes in person, time, location, or topic to create interpretable memory segments.
invented entities (1)
-
Boundary-triggered hyperedges
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWhen any such element changes, HingeMem draws a boundary and writes the current segment... over four elements: person, time, location, and topic.
-
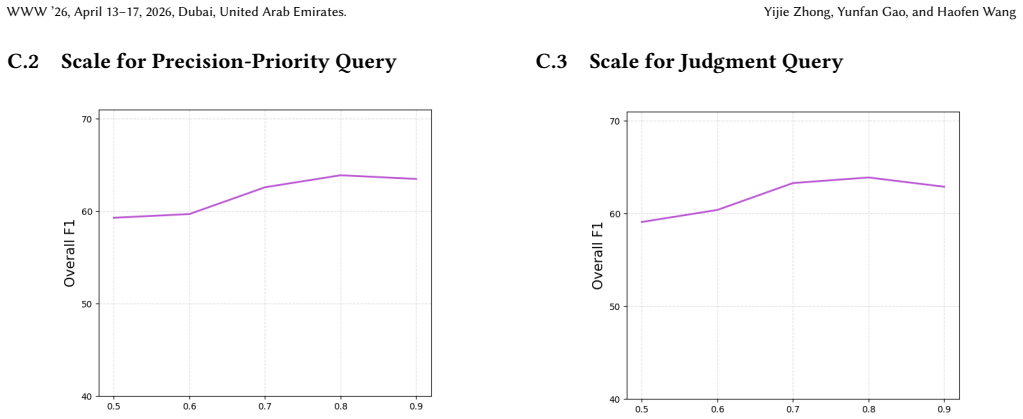
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe categorize queries into three retrieval-oriented types: recall-priority, precision-priority, and judgment, each with tailored stopping criteria.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearInspired by Event Segmentation Theory... boundary-aligned information is more easily recalled.
Reference graph
Works this paper leans on
-
[1]
Layla El Asri, Hannes Schulz, Shikhar Sharma, Jeremie Zumer, Justin Harris, Emery Fine, Rahul Mehrotra, and Kaheer Suleman. 2017. Frames: a corpus for adding memory to goal-oriented dialogue systems. InSIGDIAL Conference. Association for Computational Linguistics, 207–219
2017
-
[2]
Sanghwan Bae, Dong-Hyun Kwak, Soyoung Kang, Min Young Lee, Sungdong Kim, Yuin Jeong, Hyeri Kim, Sang-Woo Lee, Woo-Myoung Park, and Nako Sung
-
[3]
In EMNLP (Findings)
Keep Me Updated! Memory Management in Long-term Conversations. In EMNLP (Findings). Association for Computational Linguistics, 3769–3787
-
[4]
Christopher Baldassano, Janice Chen, Asieh Zadbood, Jonathan W Pillow, Uri Hasson, and Kenneth A Norman. 2017. Discovering event structure in continuous narrative perception and memory.Neuron95, 3 (2017), 709–721
2017
-
[5]
Alexander J Barnett, Mitchell Nguyen, James Spargo, Reesha Yadav, Brendan I Cohn-Sheehy, and Charan Ranganath. 2024. Hippocampal-cortical interactions during event boundaries support retention of complex narrative events.Neuron 112, 2 (2024), 319–330
2024
- [6]
-
[7]
Irving Biederman. 1987. Recognition-by-components: a theory of human image understanding.Psychological review94, 2 (1987), 115
1987
-
[8]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
-
[9]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.CoRRabs/2504.19413 (2025)
work page internal anchor Pith review arXiv 2025
-
[10]
Finetune Corp. 2024. Memary: The Open Source Memory Layer For Autonomous Agents. https://github.com/kingjulio8238/memary
2024
- [11]
- [12]
-
[13]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. From Local to Global: A Graph RAG Approach to Query-Focused Summarization.CoRRabs/2404.16130 (2024)
work page internal anchor Pith review arXiv 2024
-
[14]
Institute for Basic Science. 2023. AI’s memory-forming mechanism found to be strikingly similar to that of the brain.ScienceDaily(2023)
2023
-
[15]
Nicholas T Franklin, Kenneth A Norman, Charan Ranganath, Jeffrey M Zacks, and Samuel J Gershman. 2020. Structured Event Memory: A neuro-symbolic model of event cognition.Psychological review127, 3 (2020), 327
2020
- [16]
-
[17]
Yubin Ge, Salvatore Romeo, Jason Cai, Raphael Shu, Yassine Benajiba, Mon- ica Sunkara, and Yi Zhang. 2025. TReMu: Towards Neuro-Symbolic Temporal Reasoning for LLM-Agents with Memory in Multi-Session Dialogues. InACL (Findings). Association for Computational Linguistics, 18974–18988
2025
-
[18]
Linda Geerligs, Dora Gözükara, Djamari Oetringer, Karen L Campbell, Marcel van Gerven, and Umut Güçlü. 2022. A partially nested cortical hierarchy of neural states underlies event segmentation in the human brain.elife11 (2022), e77430
2022
-
[19]
Gaurav Goswami. 2025. Dissecting the metrics: How different evaluation ap- proaches yield diverse results for conversational ai.Authorea Preprints(2025). TechRiv:26407 https://www.techrxiv.org/inst/26407
2025
-
[20]
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[21]
InNeurIPS
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. InNeurIPS
- [22]
-
[23]
Junqing He, Liang Zhu, Rui Wang, Xi Wang, Gholamreza Haffari, and Jiax- ing Zhang. 2025. MADial-Bench: Towards Real-world Evaluation of Memory- Augmented Dialogue Generation. InNAACL (Long Papers). Association for Com- putational Linguistics, 9902–9921
2025
-
[24]
Jihyoung Jang, Minseong Boo, and Hyounghun Kim. 2023. Conversation Chroni- cles: Towards Diverse Temporal and Relational Dynamics in Multi-Session Con- versations. InEMNLP. Association for Computational Linguistics, 13584–13606
2023
-
[25]
Eunwon Kim, Chanho Park, and Buru Chang. 2025. SHARE: Shared Memory- Aware Open-Domain Long-Term Dialogue Dataset Constructed from Movie Script. InACL (1). Association for Computational Linguistics, 14474–14498
2025
- [26]
-
[27]
Canny, and Ian Fischer
Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John F. Canny, and Ian Fischer
-
[28]
A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts. InICML. OpenReview.net
-
[29]
Zhiyu Li, Shichao Song, Chenyang Xi, Hanyu Wang, Chen Tang, Simin Niu, Ding Chen, Jiawei Yang, Chunyu Li, Qingchen Yu, Jihao Zhao, Yezhaohui Wang, Peng Liu, Zehao Lin, Pengyuan Wang, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhen Tao, Junpeng Ren, Huayi Lai, Hao Wu, Bo Tang, Zhenren Wang, Zhaoxin Fan, Ningyu Zhang, Linfeng Zhang, Junchi Yan, Mingchuan...
- [30]
- [31]
-
[32]
Qihong Lu, Uri Hasson, and Kenneth A Norman. 2022. A neural network model of when to retrieve and encode episodic memories.elife11 (2022), e74445
2022
-
[33]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InACL (1). Association for Computational Linguistics, 13851–13870
2024
-
[34]
Jisoo Mok, Ik-hwan Kim, Sangkwon Park, and Sungroh Yoon. 2025. Exploring the Potential of LLMs as Personalized Assistants: Dataset, Evaluation, and Analysis. InACL (1). Association for Computational Linguistics, 10212–10239
2025
-
[35]
Kai Tzu-iunn Ong, Namyoung Kim, Minju Gwak, Hyungjoo Chae, Taeyoon Kwon, Yohan Jo, Seung-won Hwang, Dongha Lee, and Jinyoung Yeo. 2025. Towards Lifelong Dialogue Agents via Timeline-based Memory Management. InNAACL (Long Papers). Association for Computational Linguistics, 8631–8661
2025
-
[36]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.CoRR abs/2310.08560 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Advait Paliwal. 2024. Reminisc: Memory for LLMs. https://github.com/ advaitpaliwal/reminisc
2024
-
[38]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: A Temporal Knowledge Graph Architecture for Agent Memory. CoRRabs/2501.13956 (2025)
work page internal anchor Pith review arXiv 2025
-
[39]
Zachariah M Reagh, Angelique I Delarazan, Alexander Garber, and Charan Ran- ganath. 2020. Aging alters neural activity at event boundaries in the hippocampus and Posterior Medial network.Nature communications11, 1 (2020), 3980
2020
-
[40]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024. LaMP: When Large Language Models Meet Personalization. InACL (1). Associa- tion for Computational Linguistics, 7370–7392
2024
-
[41]
Gregor Sieber and Brigitte Krenn. 2010. Towards an Episodic Memory for Com- panion Dialogue. InIV A (Lecture Notes in Computer Science, Vol. 6356). Springer, 322–328
2010
-
[42]
Arpita Soni, Rajeev Arora, Anoop Kumar, and Dheerendra Panwar. 2024. Evalu- ating Domain Coverage in Low-Resource Generative Chatbots: A Comparative Study of Open-Domain and Closed-Domain Approaches Using BLEU Scores. In 2024 International Conference on Electrical Electronics and Computing Technologies (ICEECT), Vol. 1. 1–6. doi:10.1109/ICEECT61758.2024.10738994
-
[43]
Hao Sun, Hengyi Cai, Bo Wang, Yingyan Hou, Xiaochi Wei, Shuaiqiang Wang, Yan Zhang, and Dawei Yin. 2024. Towards Verifiable Text Generation with Evolving Memory and Self-Reflection. InEMNLP. Association for Computational Linguistics, 8211–8227
2024
- [44]
-
[45]
Wang-Chiew Tan, Jane Dwivedi-Yu, Yuliang Li, Lambert Mathias, Marzieh Saeidi, Jing Nathan Yan, and Alon Y. Halevy. 2023. TimelineQA: A Benchmark for Ques- tion Answering over Timelines. InACL (Findings). Association for Computational Linguistics, 77–91
2023
-
[46]
Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Rajan Iyer, Tianlong Chen, Huan Liu, Chen-Yu Lee, and Tomas Pfister
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long T. Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Rajan Iyer, Tianlong Chen, Huan Liu, Chen-Yu Lee, and Tomas Pfister. 2025. In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents. InACL (1). Association for Computational Linguistics, 8416–8439
2025
- [47]
-
[48]
Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding. 2025. Recursively summarizing enables long-term dialogue memory in large language models.Neurocomputing639 (2025), 130193
2025
-
[49]
Zheng Wang, Zhongyang Li, Zeren Jiang, Dandan Tu, and Wei Shi. 2024. Crafting Personalized Agents through Retrieval-Augmented Generation on Editable Mem- ory Graphs. InEMNLP. Association for Computational Linguistics, 4891–4906
2024
-
[50]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu
-
[51]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InICLR. OpenReview.net. WWW ’26, April 13–17, 2026, Dubai, United Arab Emirates. Yijie Zhong, Yunfan Gao, and Haofen Wang
2026
- [52]
-
[53]
Jing Xu, Arthur Szlam, and Jason Weston. 2022. Beyond Goldfish Memory: Long- Term Open-Domain Conversation. InACL (1). Association for Computational Linguistics, 5180–5197
2022
-
[54]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[55]
A-MEM: Agentic Memory for LLM Agents.CoRRabs/2502.12110 (2025)
work page internal anchor Pith review arXiv 2025
-
[56]
Xinchao Xu, Zhibin Gou, Wenquan Wu, Zheng-Yu Niu, Hua Wu, Haifeng Wang, and Shihang Wang. 2022. Long Time No See! Open-Domain Conversation with Long-Term Persona Memory. InACL (Findings). Association for Computational Linguistics, 2639–2650
2022
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Jeffrey M Zacks and Khena M Swallow. 2007. Event segmentation.Current directions in psychological science16, 2 (2007), 80–84
2007
-
[59]
Jeffrey M Zacks, Barbara Tversky, and Gowri Iyer. 2001. Perceiving, remembering, and communicating structure in events.Journal of experimental psychology: General130, 1 (2001), 29
2001
-
[60]
Zheng Zhang, Minlie Huang, Zhongzhou Zhao, Feng Ji, Haiqing Chen, and Xi- aoyan Zhu. 2019. Memory-Augmented Dialogue Management for Task-Oriented Dialogue Systems.ACM Trans. Inf. Syst.37, 3 (2019), 34:1–34:30
2019
-
[61]
Jie Zheng, Andrea GP Schjetnan, Mar Yebra, Bernard A Gomes, Clayton P Mosher, Suneil K Kalia, Taufik A Valiante, Adam N Mamelak, Gabriel Kreiman, and Ueli Rutishauser. 2022. Neurons detect cognitive boundaries to structure episodic memories in humans.Nature neuroscience25, 3 (2022), 358–368
2022
-
[62]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Mem- oryBank: Enhancing Large Language Models with Long-Term Memory. InAAAI. AAAI Press, 19724–19731
2024
-
[63]
Yijie Zhong, Yunfan Gao, Xiaolian Zhang, and Haofen Wang. 2025. ODDA: An OODA-Driven Diverse Data Augmentation Framework for Low-Resource Relation Extraction. InFindings of the Association for Computational Linguistics: ACL 2025. 267–285
2025
-
[64]
conversation segmentation and element extractor
Yijie Zhong, Feifan Wu, Mengying Guo, Xiaolian Zhang, Meng Wang, and Haofen Wang. 2025. Meta-PKE: Memory-Enhanced Task-Adaptive Personal Knowledge Extraction in Daily Life.Inf. Process. Manag.62, 4 (2025), 104097. A More Implementation Details To enable fair comparison, we integrate all baselines into our project based on the following open-source codes. ...
2025
-
[65]
Identify event or memory boundaries: When there is an ob- vious change in **person/time/location/topic**, or a new **per- son/time/location/topic** appears, or when explicit transition words appear, start a new event; otherwise, merge it into the current memory data
-
[66]
persons": [ {
Extract relations and events in a unified form. Fields: persons[], times[], locations[], topics[], description, bound- aryreasons[], start turn, end turn For relations: (optional) **Person - Person**: ... ; **Person - Time**: ... ; **Person - Location**: ... For events: Fill in the corresponding fields according to the events involved and summarize the co...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.