Recognition: 2 theorem links
· Lean TheoremMAR-GRPO: Stabilized GRPO for AR-diffusion Hybrid Image Generation
Pith reviewed 2026-05-10 17:56 UTC · model grok-4.3
The pith
Averaging multiple diffusion trajectories stabilizes RL training for hybrid AR-diffusion image generators by cutting gradient noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that multi-trajectory expectation, applied selectively to high-uncertainty tokens together with consistency-aware autoregressive token selection, reduces diffusion-induced gradient noise in MAR training and thereby improves stability, visual quality, and spatial understanding over standard GRPO and pre-RL baselines.
What carries the argument
Multi-trajectory expectation (MTE) that averages the estimated optimization direction over multiple sampled diffusion trajectories, restricted to the top-k% uncertain tokens and combined with a consistency-aware filter on autoregressive tokens.
If this is right
- Training curves become smoother and avoid early performance plateaus.
- Generated images achieve higher visual quality across standard benchmarks.
- Outputs exhibit improved spatial structure and coherence.
- Gains hold relative to both plain GRPO and models trained without RL.
Where Pith is reading between the lines
- The uncertainty-based selection rule could be ported to other hybrid generative settings where one component produces noisier signals than the other.
- Focusing trajectory sampling only on uncertain tokens may lower overall compute cost compared with full multi-trajectory estimation at every step.
- The same consistency filter might help diagnose or correct misalignment between autoregressive planning and final output in non-image domains.
Load-bearing premise
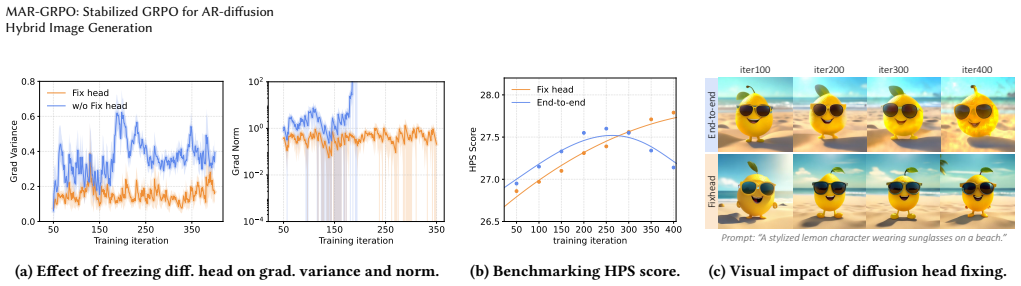
The diffusion head is the dominant source of gradient noise during MAR training, and averaging trajectories will reduce that noise without introducing new biases or instabilities in the hybrid inference process.
What would settle it
An experiment that measures gradient variance and training curves on the same benchmarks; if the proposed method still shows high variance or early saturation comparable to baseline GRPO, the stabilization claim is falsified.
Figures











read the original abstract
Reinforcement learning (RL) has been successfully applied to autoregressive (AR) and diffusion models. However, extending RL to hybrid AR-diffusion frameworks remains challenging due to interleaved inference and noisy log-probability estimation. In this work, we study masked autoregressive models (MAR) and show that the diffusion head plays a critical role in training dynamics, often introducing noisy gradients that lead to instability and early performance saturation. To address this issue, we propose a stabilized RL framework for MAR. We introduce multi-trajectory expectation (MTE), which estimates the optimization direction by averaging over multiple diffusion trajectories, thereby reducing diffusion-induced gradient noise. To avoid over-smoothing, we further estimate token-wise uncertainty from multiple trajectories and apply multi-trajectory optimization only to the top-k% uncertain tokens. In addition, we introduce a consistency-aware token selection strategy that filters out AR tokens that are less aligned with the final generated content. Extensive experiments across multiple benchmarks demonstrate that our method consistently improves visual quality, training stability, and spatial structure understanding over baseline GRPO and pre-RL models. Code is available at: https://github.com/AMAP-ML/mar-grpo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
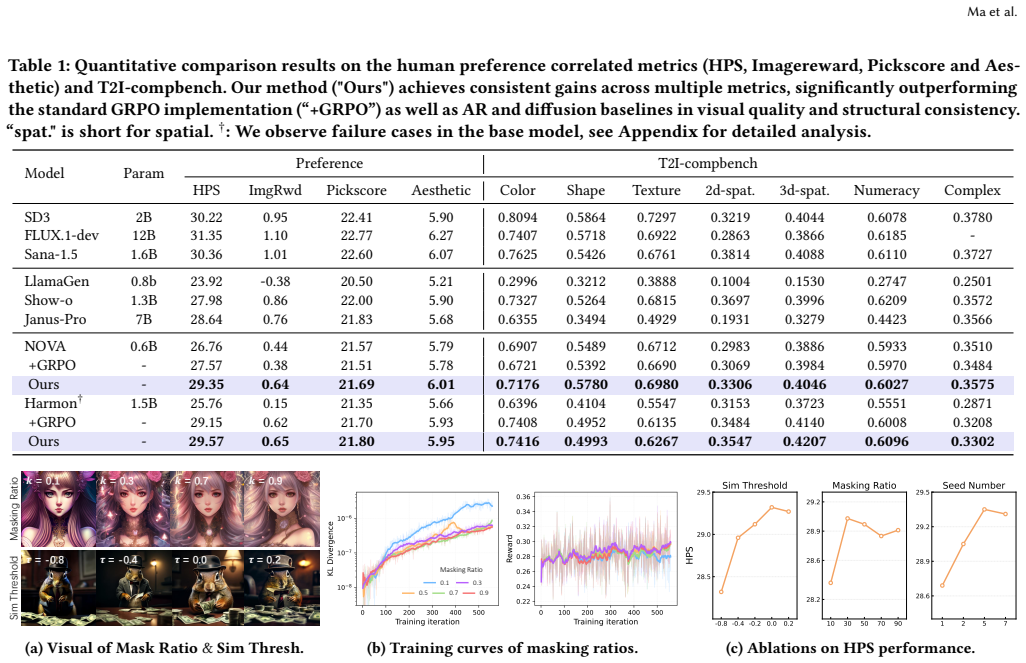
Summary. The paper introduces MAR-GRPO, a stabilized RL framework for masked autoregressive (MAR) hybrid models that interleave AR and diffusion components for image generation. It identifies noisy gradients from the diffusion head as a source of training instability and early saturation in standard GRPO. The proposed fixes are multi-trajectory expectation (MTE) to average optimization directions over multiple diffusion trajectories, selective application of MTE only to the top-k% most uncertain tokens, and a consistency-aware filter that discards AR tokens poorly aligned with the final output. The authors claim that these changes yield consistent gains in visual quality, training stability, and spatial structure understanding over baseline GRPO and pre-RL models across multiple benchmarks, with code released.
Significance. If the empirical improvements are robust, the work would be a useful practical contribution to RL fine-tuning of hybrid generative architectures, a setting that is becoming common but remains under-studied for stability. The explicit focus on diffusion-induced noise and the provision of open code are strengths that support reproducibility and further experimentation.
major comments (3)
- [§3.2] §3.2 (MTE formulation): the central claim that averaging multiple diffusion trajectories yields an unbiased estimate of the policy gradient direction is load-bearing, yet the manuscript provides no derivation or analysis showing that the hybrid interleaving does not introduce correlations between AR log-probabilities and the sampled diffusion paths.
- [§4] §4 (Experiments): the abstract and results sections assert 'consistent improvements' and 'extensive experiments' but report neither quantitative deltas, error bars, nor the precise baseline implementations and hyper-parameter settings; without these the magnitude and reliability of the claimed gains in visual quality and stability cannot be assessed.
- [§3.1] §3.1 (Motivation): the assertion that the diffusion head is the dominant source of gradient noise is used to justify the entire approach, but no ablation or variance decomposition is presented that isolates the relative contribution of the diffusion versus AR components to the observed instability.
minor comments (2)
- [§3.3] Notation for the top-k% threshold and the uncertainty estimator is introduced without a clear equation or pseudocode; a small algorithmic box would improve clarity.
- [§4] Figure captions and axis labels in the training curves are too small and lack units or legend entries for the different methods.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each of the major comments point-by-point below and have made revisions to the manuscript where necessary to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3.2] §3.2 (MTE formulation): the central claim that averaging multiple diffusion trajectories yields an unbiased estimate of the policy gradient direction is load-bearing, yet the manuscript provides no derivation or analysis showing that the hybrid interleaving does not introduce correlations between AR log-probabilities and the sampled diffusion paths.
Authors: We agree that a formal derivation would strengthen the central claim regarding the unbiased nature of the multi-trajectory expectation. In the revised manuscript, we have added a derivation in Section 3.2. This shows that, since diffusion trajectories are sampled independently conditional on the AR token decisions, the averaging yields an unbiased estimate of the expected policy gradient direction. We also include an analysis of potential correlations introduced by the hybrid interleaving and discuss why they are limited in practice based on our model architecture. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and results sections assert 'consistent improvements' and 'extensive experiments' but report neither quantitative deltas, error bars, nor the precise baseline implementations and hyper-parameter settings; without these the magnitude and reliability of the claimed gains in visual quality and stability cannot be assessed.
Authors: We concur that quantitative details are essential for evaluating the claimed improvements. Accordingly, in the revised manuscript, we have included tables with specific performance deltas, error bars computed over multiple independent runs, detailed specifications of the baseline implementations, and complete hyper-parameter settings in the appendix. These additions provide a clearer picture of the magnitude and reliability of the gains. revision: yes
-
Referee: [§3.1] §3.1 (Motivation): the assertion that the diffusion head is the dominant source of gradient noise is used to justify the entire approach, but no ablation or variance decomposition is presented that isolates the relative contribution of the diffusion versus AR components to the observed instability.
Authors: We appreciate this feedback on the motivation. To address it, we have added an ablation study and a variance decomposition analysis in the revised Section 3.1. This analysis isolates the contributions of the diffusion head and AR components to the gradient noise and instability, supporting our claim that the diffusion head is the dominant source. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical stabilization technique (MTE with top-k uncertainty filtering and consistency-aware selection) for RL training of hybrid AR-diffusion models. All central claims rest on experimental results across benchmarks rather than any derivation, prediction, or first-principles result that reduces by construction to fitted parameters, self-citations, or renamed inputs. No equations are presented that equate outputs to inputs via definition or fitting; the method is framed as a practical response to observed gradient noise, with gains validated externally.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-k% uncertain tokens
axioms (1)
- domain assumption The diffusion head in MAR models introduces noisy gradients that cause training instability and early saturation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce multi-trajectory expectation (MTE), which estimates the optimization direction by averaging over multiple diffusion trajectories, thereby reducing diffusion-induced gradient noise.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we estimate token-wise uncertainty from multiple trajectories and apply multi-trajectory optimization only to the top-k% uncertain tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Flow-OPD: On-Policy Distillation for Flow Matching Models
Flow-OPD applies on-policy distillation to flow matching models via specialized teachers, cold-start initialization, and manifold anchor regularization, lifting GenEval from 63 to 92 and OCR from 59 to 94 on Stable Di...
-
Flow-OPD: On-Policy Distillation for Flow Matching Models
Flow-OPD applies on-policy distillation to flow-matching text-to-image models, lifting GenEval from 63 to 92 and OCR accuracy from 59 to 94 while preserving fidelity.
-
Flow-OPD: On-Policy Distillation for Flow Matching Models
Flow-OPD applies on-policy distillation to flow matching models, achieving GenEval of 92 and OCR accuracy of 94 on Stable Diffusion 3.5 Medium while avoiding the seesaw effect of multi-reward optimization.
Reference graph
Works this paper leans on
-
[1]
Jinbin Bai, Tian Ye, Wei Chow, Enxin Song, Qing-Guo Chen, Xiangtai Li, Zhen Dong, Lei Zhu, and Shuicheng Yan. 2024. Meissonic: Revitalizing masked gener- ative transformers for efficient high-resolution text-to-image synthesis. InThe Thirteenth International Conference on Learning Representations
2024
-
[2]
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, Le Xue, Caiming Xiong, and Ran Xu. 2025. BLIP3-o: A Family of Fully Open Unified Multimodal Models- Architecture, Training and Dataset. arXiv:2505.09568 [cs.CV] https://arxiv.org/ abs/2505.09568
work page Pith review arXiv 2025
-
[3]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. 2025. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review arXiv 2025
-
[4]
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. 2026. Gpg: A simple and strong reinforcement learning baseline for model reasoning. ICLR(2026)
2026
-
[5]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan
-
[7]
Emerging Properties in Unified Multimodal Pretraining.arXiv preprint arXiv:2505.14683(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12873–12883
2021
- [10]
- [11]
-
[12]
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. 2023. T2i- compbench: A comprehensive benchmark for open-world compositional text-to- image generation.Advances in Neural Information Processing Systems36 (2023), 78723–78747
2023
- [13]
-
[14]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. 2023. Pick-a-pic: An open dataset of user preferences for text-to- image generation.Advances in neural information processing systems36 (2023), 36652–36663
2023
- [15]
-
[16]
Black Forest Labs. 2024. FLUX. https://github.com/black-forest-labs/flux
2024
-
[17]
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. 2026. MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE. arXiv:2507.21802 [cs.AI] https://arxiv.org/abs/2507.21802
work page internal anchor Pith review arXiv 2026
-
[18]
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. 2024. Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems37 (2024), 56424–56445
2024
- [19]
-
[20]
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. 2025. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470(2025)
work page internal anchor Pith review arXiv 2025
- [21]
- [22]
- [23]
-
[24]
Xiaoxiao Ma, Mohan Zhou, Tao Liang, Yalong Bai, Tiejun Zhao, Huaian Chen, and Yi Jin. 2024. Star: Scale-wise text-to-image generation via auto-regressive representations.arXiv e-prints(2024), arXiv–2406
2024
-
[25]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeek- Math: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL] https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. 2024. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525(2024)
work page internal anchor Pith review arXiv 2024
-
[27]
Shikun Sun, Liao Qu, Huichao Zhang, Yiheng Liu, Yangyang Song, Xian Li, Xu Wang, Yi Jiang, Daniel K. Du, Xinglong Wu, and Jia Jia. 2026. VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation. arXiv:2601.02256 [cs.CV] https://arxiv.org/abs/2601.02256
- [28]
-
[29]
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. 2025. MAGI-1: Autoregressive Video Generation at Scale.arXiv preprint arXiv:2505.13211(2025)
work page internal anchor Pith review arXiv 2025
-
[30]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. 2024. Visual autoregressive modeling: Scalable image generation via next-scale prediction. Advances in neural information processing systems37 (2024), 84839–84865. Ma et al
2024
- [31]
-
[32]
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and Ping Luo. 2024. Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Genera- tion. arXiv:2410.13848 [cs.CV] https://arxiv.org/abs/2410.13848
- [33]
-
[34]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. 2023. Human preference score v2: A solid benchmark for evaluat- ing human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341 (2023)
work page internal anchor Pith review arXiv 2023
-
[35]
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. 2024. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528(2024)
work page internal anchor Pith review arXiv 2024
-
[36]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. 2024. Imagereward: Learning and evaluating human prefer- ences for text-to-image generation.Advances in Neural Information Processing Systems36 (2024)
2024
- [37]
-
[38]
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, and Ping Luo. 2025. Dance- GRPO: Unleashing GRPO on Visual Generation. arXiv:2505.07818 [cs.CV] https://arxiv.org/abs/2505.07818
work page internal anchor Pith review arXiv 2025
- [39]
- [40]
-
[41]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2025. Dapo: An open- source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
- [43]
- [45]
-
[46]
Zhen Zou, Xiaoxiao Ma, Jie Huang, Zichao Yu, and Feng Zhao. 2025. Fast- ARDiff: An Entropy-informed Acceleration Framework for Continuous Space Autoregressive Generation. arXiv:2512.08537 [cs.CV] https://arxiv.org/abs/2512. 08537 MAR-GRPO: Stabilized GRPO for AR-diffusion Hybrid Image Generation A Additional Description of Methods A.1 GRPO Optimization fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.