Recognition: unknown
Sell More, Play Less: Benchmarking LLM Realistic Selling Skill
Pith reviewed 2026-05-10 17:28 UTC · model grok-4.3
The pith
SalesLLM benchmark shows top LLMs reach human-level performance in realistic sales dialogues while weaker models lag behind.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
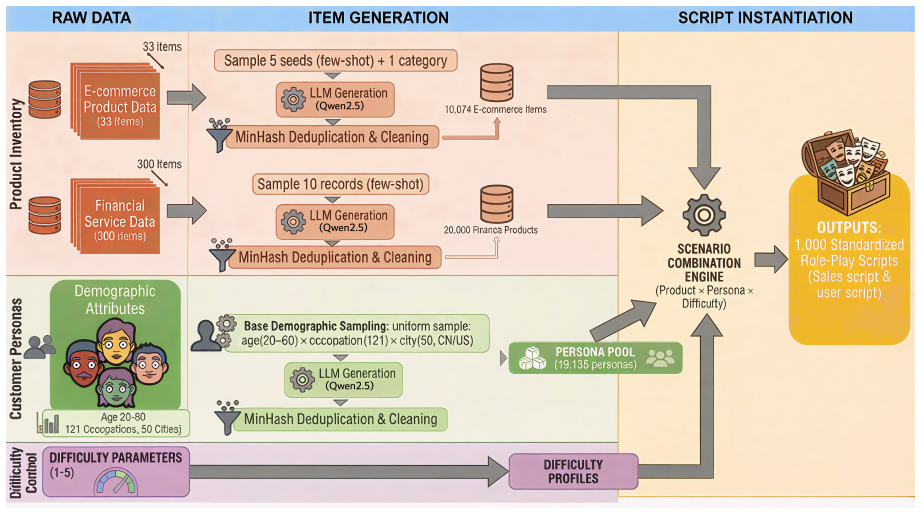
SalesLLM is a bilingual benchmark built from 30,074 scripted configurations and 1,805 multi-turn scenarios with controllable difficulty and personas. It uses a fully automatic evaluation pipeline combining an LLM-based rater for sales-process progress and fine-tuned BERT classifiers for end-of-dialogue buying intent. Training CustomerLM on over 8,000 crowdworker sales conversations reduces role inversion. Benchmark scores correlate with expert human ratings at Pearson r=0.98, and tests across 15 LLMs show top models competitive with human-level performance while others perform worse.
What carries the argument
The SalesLLM benchmark and its automatic evaluation pipeline, which measures deal progression through scripted scenarios and simulated customer responses to assess outcome-oriented selling skills.
Load-bearing premise
The scripted configurations and the CustomerLM trained on crowdworker data accurately represent real asymmetric-incentive sales interactions without introducing artifacts from scripting or role inversion.
What would settle it
A direct comparison where the automatic SalesLLM scores diverge significantly from ratings by multiple independent human sales experts on the same set of dialogues would falsify the strong correlation claim.
Figures








read the original abstract
Sales dialogues require multi-turn, goal-directed persuasion under asymmetric incentives, which makes them a challenging setting for large language models (LLMs). Yet existing dialogue benchmarks rarely measure deal progression and outcomes. We introduce SalesLLM benchmark, a bilingual (ZH/EN) benchmark derived from realistic applications covering Financial Services and Consumer Goods, built from 30,074 scripted configurations and 1,805 curated multi-turn scenarios with controllable difficulty and personas. We propose a fully automatic evaluation pipeline that combines (i) an LLM-based rater for sales-process progress,and (ii) fine-tuned BERT classifiers for end-of-dialogue buying intent. To improve simulation fidelity, we train a user model, CustomerLM, with SFT and DPO on 8,000+ crowdworker-involved sales conversations, reducing role inversion from 17.44% (GPT-4o) to 8.8%. SalesLLM benchmark scores correlate strongly with expert human ratings (Pearson r=0.98). Experiments across 15 mainstream LLMs reveal substantial variability: top-performance LLMs are competitive with human-level performance while the less capable ones are worse than human. SalesLLM benchmark serves as a scalable benchmark for developing and evaluating outcome-oriented sales agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the SalesLLM benchmark for evaluating LLMs on realistic multi-turn sales dialogues under asymmetric incentives in Financial Services and Consumer Goods domains. It is constructed from 30,074 scripted configurations and 1,805 curated scenarios with controllable personas and difficulty, bilingual in ZH/EN. An automatic evaluation pipeline combines an LLM-based rater for sales-process progress with fine-tuned BERT classifiers for end-of-dialogue buying intent. CustomerLM, trained via SFT and DPO on 8,000+ crowdworker conversations, simulates users and reduces role inversion to 8.8%. The benchmark achieves Pearson r=0.98 correlation with expert human ratings; experiments on 15 LLMs show top models competitive with humans and weaker ones below human level.
Significance. If the benchmark's scenarios and simulation faithfully capture real sales dynamics, this would be a significant contribution by providing a scalable, externally validated tool for outcome-oriented dialogue evaluation, addressing a gap in existing benchmarks that rarely track deal progression and persuasion under realistic incentives.
major comments (3)
- The central claim that benchmark scores measure genuine selling skill rests on the fidelity of the 1,805 curated scenarios and CustomerLM simulation to real asymmetric sales interactions. The manuscript provides insufficient detail on curation rules, data exclusion criteria, and checks against scripting or crowdworker artifacts that could distort objection sequences and outcome distributions.
- The reported Pearson r=0.98 with expert human ratings is presented as strong external validation, but without any comparison to field-recorded human-human sales dialogues, it remains possible that the correlation arises from shared distributional biases between the synthetic pipeline and the rater pool rather than true realism.
- CustomerLM training (SFT+DPO on crowdworker data) is used to improve simulation fidelity and lower role inversion from 17.44% to 8.8%, yet no additional metrics are given confirming that persuasion patterns, multi-turn objection handling, and buying-intent distributions match real sales data beyond the overall correlation.
minor comments (2)
- Clarify the precise count of crowdworker conversations used for CustomerLM training (currently stated as 8,000+).
- The bilingual (ZH/EN) results could include a brief breakdown of any performance differences between languages to strengthen the claim of broad applicability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript introducing the SalesLLM benchmark. We have prepared point-by-point responses to each major comment below, providing the strongest honest defense of our work while acknowledging limitations where they exist. Revisions have been made to improve clarity and transparency in the areas where we can directly address the concerns.
read point-by-point responses
-
Referee: The central claim that benchmark scores measure genuine selling skill rests on the fidelity of the 1,805 curated scenarios and CustomerLM simulation to real asymmetric sales interactions. The manuscript provides insufficient detail on curation rules, data exclusion criteria, and checks against scripting or crowdworker artifacts that could distort objection sequences and outcome distributions.
Authors: We agree that greater detail on the curation process is warranted to support claims of fidelity. In the revised manuscript, we have substantially expanded Section 3.2 (Scenario Curation) and added a new Appendix D. These now include: the full set of curation rules derived from domain-specific sales playbooks (e.g., objection sequencing aligned with Financial Services compliance and Consumer Goods negotiation norms); explicit data exclusion criteria (removing scenarios with persona inconsistencies, regulatory violations, or outcome probabilities deviating >2 SD from industry benchmarks); and artifact checks such as statistical comparisons of objection sequences against expert sales scripts plus pilot validation with 12 professional sales experts (inter-rater agreement κ=0.81) to confirm crowdworker data did not introduce systematic distortions. These additions directly address the concern and strengthen the transparency of our methodology. revision: yes
-
Referee: The reported Pearson r=0.98 with expert human ratings is presented as strong external validation, but without any comparison to field-recorded human-human sales dialogues, it remains possible that the correlation arises from shared distributional biases between the synthetic pipeline and the rater pool rather than true realism.
Authors: We acknowledge the validity of this point regarding the limits of our external validation. The r=0.98 correlation specifically validates that the automatic pipeline (LLM rater + BERT classifiers) matches expert human judgments when both evaluate the same set of synthetic dialogues generated within SalesLLM. This confirms the reliability of our evaluation framework for the benchmark. However, we lack access to proprietary field-recorded human-human sales dialogues, which are confidential and not publicly available in these regulated domains. We have added an explicit discussion of this limitation in the revised Limitations section, including the possibility of shared biases, and we outline future work involving industry partnerships to enable such comparisons. This revision clarifies the scope of our claims without overstating the benchmark's alignment to real-world distributions. revision: partial
-
Referee: CustomerLM training (SFT+DPO on crowdworker data) is used to improve simulation fidelity and lower role inversion from 17.44% to 8.8%, yet no additional metrics are given confirming that persuasion patterns, multi-turn objection handling, and buying-intent distributions match real sales data beyond the overall correlation.
Authors: We appreciate this suggestion for more granular validation of CustomerLM. In the revised Section 4.3 and new Appendix E, we now report additional metrics comparing CustomerLM outputs to the underlying 8,000+ crowdworker conversations: (1) persuasion tactic distributions (e.g., frequencies of scarcity, authority, and reciprocity appeals) with KL-divergence of 0.07; (2) multi-turn objection handling statistics including average objections per dialogue (3.2 vs. 3.1 in human data), objection resolution rates (68% vs. 71%), and turn-level success patterns; and (3) buying-intent category distributions across personas with KL-divergence <0.05 and chi-squared alignment p>0.1. These results, alongside the role-inversion reduction, provide targeted evidence that key sales dynamics are preserved beyond the aggregate correlation. revision: yes
Circularity Check
No significant circularity; benchmark validated externally.
full rationale
The paper constructs the SalesLLM benchmark from 30,074 scripted configurations and 1,805 scenarios, trains CustomerLM via SFT+DPO on a separate set of 8,000+ crowdworker conversations, and validates the automatic pipeline (LLM rater + BERT classifiers) against independent expert human ratings (Pearson r=0.98). This external correlation and use of distinct data sources render the central claims self-contained. No load-bearing step reduces by construction to the paper's own inputs, fitted parameters renamed as predictions, or self-citation chains. The derivation relies on observable outcomes and separate human judgments rather than tautological re-labeling.
Axiom & Free-Parameter Ledger
invented entities (1)
-
CustomerLM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
- [3]
-
[4]
Language Models are Few-Shot Learners
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. Language models are few-shot lear...
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [5]
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2025. https://arxiv.org/abs/2402.03216 M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation . Preprint, arXiv:2402.03216
work page internal anchor Pith review arXiv 2025
-
[7]
Sijia Cheng, Wen Yu Chang, and Yun-Nung Chen. 2025. https://aclanthology.org/2025.iwsds-1.6/ Exploring personality-aware interactions in salesperson dialogue agents . In Proceedings of the 15th International Workshop on Spoken Dialogue Systems Technology, pages 60--71, Bilbao, Spain. Association for Computational Linguistics
2025
-
[8]
Jacob Cohen. 1988. Statistical power analysis for the behavioral sciences. Routledge
1988
-
[9]
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. 2020. https://www.aclweb.org/anthology/2020.findings-emnlp.58 Revisiting pre-trained models for C hinese natural language processing . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 657--668, Online. Association for Comput...
2020
-
[10]
Jan de Wit. 2023. https://doi.org/10.1007/978-3-031-54975-5_5 Leveraging large language models as simulated users for initial, low-cost evaluations of designed conversations . In Chatbot Research and Design: 7th International Workshop, CONVERSATIONS 2023, Oslo, Norway, November 22–23, 2023, Revised Selected Papers, page 77–93, Berlin, Heidelberg. Springer-Verlag
-
[11]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, and 181 others. 2025. https://arxiv.org/abs/2412.19437 Deepseek-v3 technical report . Preprint, arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , Minneapolis, Minnes...
2019
-
[13]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. 2025. https://arxiv.org/abs/2404.04475 Length-controlled alpacaeval: A simple way to debias automatic evaluators . Preprint, arXiv:2404.04475
work page internal anchor Pith review arXiv 2025
-
[14]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, and 37 others. 2024. https://arxiv.org/abs/2406.12793 Chatglm: A family of large language models from glm-130b to glm-4 all tools . Prep...
work page internal anchor Pith review arXiv 2024
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
Leon Hanschmann, Ulrich Gnewuch, and Alexander Maedche. 2023. https://doi.org/10.1007/978-3-031-54975-5_4 Saleshat: A LLM -based social robot for human-like sales conversations . pages 61--76, Berlin, Heidelberg. Springer-Verlag
-
[18]
Yerin Hwang, Dongryeol Lee, Taegwan Kang, Yongil Kim, and Kyomin Jung. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.790 Can you trick the grader? adversarial persuasion of LLM judges . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 14632--14651, Suzhou, China. Association for Computational Linguistics
-
[19]
Chuhao Jin, Kening Ren, Lingzhen Kong, Xiting Wang, Ruihua Song, and Huan Chen. 2024. https://doi.org/10.18653/v1/2024.acl-long.92 Persuading across diverse domains: a dataset and persuasion large language model . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1678--1706, Bangkok, ...
-
[20]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[21]
Tianle Li, Wei - Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. 2024. https://arxiv.org/abs/2406.11939 From crowdsourced data to high-quality benchmarks: The arena-hard and benchbuilder pipeline . CoRR, abs/2406.11939
-
[22]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[23]
Chia-Wei Liu, Ryan Lowe, Iulian Serban, Michael Noseworthy, Laurent Charlin, and Joelle Pineau. 2016. https://doi.org/10.18653/v1/D16-1230 How NOT to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processi...
-
[24]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Xiang Luo, Zhiwen Tang, Jin Wang, and Xuejie Zhang. 2024. https://aclanthology.org/2024.lrec-main.481/ D uet S im: Building user simulator with dual large language models for task-oriented dialogues . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 5414--54...
2024
- [26]
-
[27]
Lidiya Murakhovs ' ka, Philippe Laban, Tian Xie, Caiming Xiong, and Chien-Sheng Wu. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.657 Salespeople vs S ales B ot: Exploring the role of educational value in conversational recommender systems . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9823--9838, Singapore. Asso...
- [28]
-
[29]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, and 401 others. 2024. https://arxiv.org/abs/2410.21276 Gpt-4o system card . Preprint, arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
OpenAI. 2025. Gpt-5 system card. https://openai.com/index/gpt-5-system-card. Accessed: 2025-12-28
2025
-
[31]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. https://doi.org/10.3115/1073083.1073135 B leu: a method for automatic evaluation of machine translation . In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311--318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics
-
[32]
Karl Pearson. 1895. Note on regression and inheritance in the case of two parents. Proceedings of the Royal Society of London, 58:240--242
-
[33]
Petty and John T
Richard E. Petty and John T. Cacioppo. 1986. Communication and Persuasion: Central and Peripheral Routes to Attitude Change. Springer-Verlag
1986
-
[34]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. https://api.semanticscholar.org/CorpusID:258959321 Direct preference optimization: Your language model is secretly a reward model . ArXiv, abs/2305.18290
work page internal anchor Pith review arXiv 2023
-
[36]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. https://doi.org/10.18653/v1/2020.acl-main.442 Beyond accuracy: Behavioral testing of NLP models with C heck L ist . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902--4912, Online. Association for Computational Linguistics
-
[37]
Sai, Akash Kumar Mohankumar, and Mitesh M
Ananya B. Sai, Akash Kumar Mohankumar, and Mitesh M. Khapra. 2020. https://arxiv.org/abs/2008.12009 A survey of evaluation metrics used for nlg systems . Preprint, arXiv:2008.12009
-
[38]
ByteDance Seed, :, Jiaze Chen, Tiantian Fan, Xin Liu, Lingjun Liu, Zhiqi Lin, Mingxuan Wang, Chengyi Wang, Xiangpeng Wei, Wenyuan Xu, Yufeng Yuan, Yu Yue, Lin Yan, Qiying Yu, Xiaochen Zuo, Chi Zhang, Ruofei Zhu, Zhecheng An, and 255 others. 2025. https://arxiv.org/abs/2504.13914 Seed1.5-thinking: Advancing superb reasoning models with reinforcement learni...
-
[39]
Ivan Sekulic, Silvia Terragni, Victor Guimar \ a es, Nghia Khau, Bruna Guedes, Modestas Filipavicius, Andre Ferreira Manso, and Roland Mathis. 2024. https://aclanthology.org/2024.scichat-1.3/ Reliable LLM -based user simulator for task-oriented dialogue systems . In Proceedings of the 1st Workshop on Simulating Conversational Intelligence in Chat (SCI-CHA...
2024
-
[40]
Charles Spearman. 1904. The proof and measurement of association between two things. American Journal of Psychology, 15:72--101
1904
-
[41]
Weiwei Sun, Shuyu Guo, Shuo Zhang, Pengjie Ren, Zhumin Chen, Maarten de Rijke, and Zhaochun Ren. 2024. https://doi.org/10.1145/3596510 Metaphorical user simulators for evaluating task-oriented dialogue systems . ACM Transactions on Information Systems, 42(1):17:1--17:29
-
[42]
Core Team, Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, Gang Xie, Hailin Zhang, Hanglong Lv, Hanyu Li, Heyu Chen, Hongshen Xu, Houbin Zhang, Huaqiu Liu, and 107 others. 2026. https://arxiv.org/abs/2601.02780 Mimo-v2-flash technical report . Preprint, arXiv:2601.02780
work page internal anchor Pith review arXiv 2026
-
[43]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, David Silver, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lillicrap, Angeliki Lazaridou, and 1332 others. 2025 a . https://arxiv.org/abs/2312...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025 b . https://arxiv.org/abs/2503.19...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Kuang Wang, Xianfei Li, Shenghao Yang, Li Zhou, Feng Jiang, and Haizhou Li. 2025. https://doi.org/10.18653/v1/2025.acl-long.1025 Know you first and be you better: Modeling human-like user simulators via implicit profiles . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21082--21107...
- [46]
-
[47]
Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models
Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Stephen W. Huang, Jie Fu, and Junran Peng. 2024. https://arxiv.org/abs/2310.00746 Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language m...
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://api.semanticscholar.org/CorpusID:278602855 Qwen3 technical report . ArXiv, abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [49]
- [50]
-
[51]
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. 2024. https://arxiv.org/abs/2310.11667 Sotopia: Interactive evaluation for social intelligence in language agents . Preprint, arXiv:2310.11667
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.