Recognition: no theorem link
Flow Motion Policy: Manipulator Motion Planning with Flow Matching Models
Pith reviewed 2026-05-10 18:26 UTC · model grok-4.3
The pith
Flow matching models a distribution over feasible manipulator paths to support best-of-N sampling that selects the first collision-free solution from sensor data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
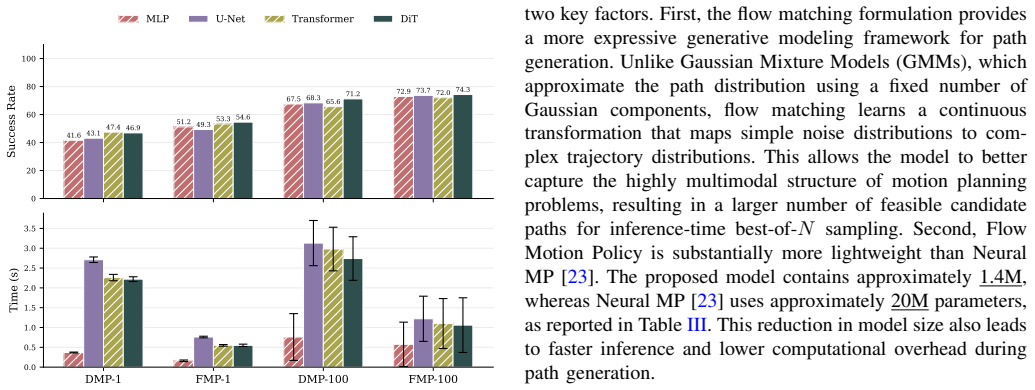
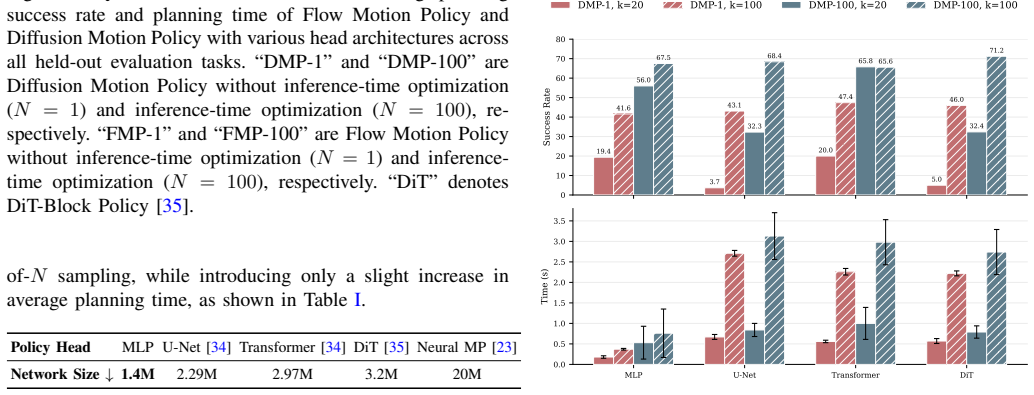
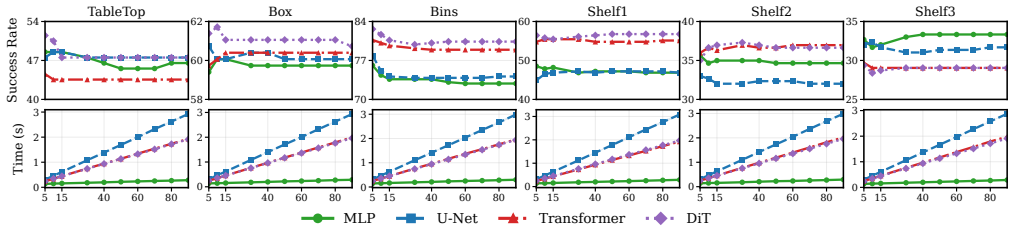
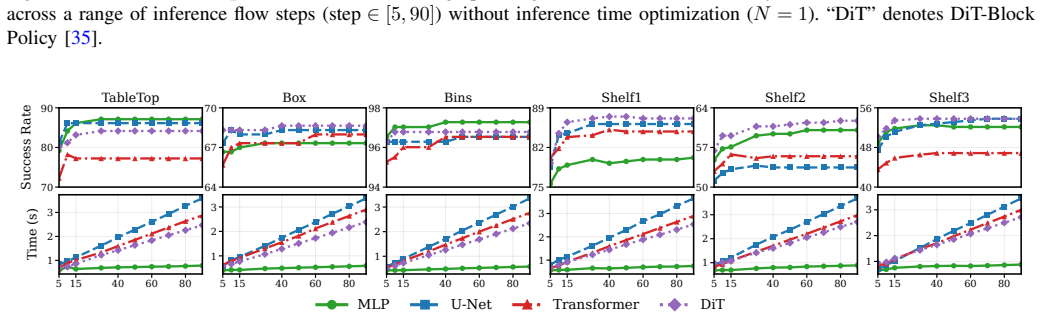
Flow Motion Policy is an open-loop end-to-end neural motion planner that uses the stochastic formulation of flow matching to capture the multi-modality of planning datasets, thereby modeling a distribution over feasible paths; this enables efficient inference-time best-of-N sampling in which multiple candidate paths are generated, their collision status is evaluated after planning, and the first collision-free solution is executed.
What carries the argument
Flow matching model that learns the conditional distribution of feasible manipulator trajectories from sensor observations and supports fast stochastic sampling of multiple diverse candidates for post-generation collision checks.
If this is right
- Multiple candidate paths can be produced from the same observation and filtered by a simple post-planning collision check.
- Planning success improves compared with single-output neural planners and some sampling-based baselines.
- The planner remains fully open-loop and does not require a privileged collision checker while generating paths.
- Efficiency gains appear in benchmarks when the first valid sample is selected without further optimization.
Where Pith is reading between the lines
- The same distribution-modeling idea could be tested on other robot types where path multi-modality is also high.
- If sampling cost stays low, the method might reduce dependence on expensive collision checkers during real-time operation.
- The approach points to a general pattern in which generative models replace deterministic predictors to gain inference-time robustness.
Load-bearing premise
A flow matching model trained on planning datasets will accurately capture the multi-modality of feasible paths so that best-of-N sampling finds a collision-free solution with only a modest number of samples.
What would settle it
An experiment in which raising the number of samples fails to increase the fraction of workspaces that receive a collision-free path or in which the required number of samples grows large enough to erase the reported efficiency gains.
Figures







read the original abstract
Open-loop end-to-end neural motion planners have recently been proposed to improve motion planning for robotic manipulators. These methods enable planning directly from sensor observations without relying on a privileged collision checker during planning. However, many existing methods generate only a single path for a given workspace across different runs, and do not leverage their open-loop structure for inference-time optimization. To address this limitation, we introduce Flow Motion Policy, an open-loop, end-to-end neural motion planner for robotic manipulators that leverages the stochastic generative formulation of flow matching methods to capture the inherent multi-modality of planning datasets. By modeling a distribution over feasible paths, Flow Motion Policy enables efficient inference-time best-of-$N$ sampling. The method generates multiple end-to-end candidate paths, evaluates their collision status after planning, and executes the first collision-free solution. We benchmark the Flow Motion Policy against representative sampling-based and neural motion planning methods. Evaluation results demonstrate that Flow Motion Policy improves planning success and efficiency, highlighting the effectiveness of stochastic generative policies for end-to-end motion planning and inference-time optimization. Experimental evaluation videos are available via this \href{https://zh.engr.tamu.edu/wp-content/uploads/sites/310/2026/03/FMP-Website.mp4}{link}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Flow Motion Policy, an open-loop end-to-end neural motion planner for robotic manipulators based on flow matching models. By learning a distribution over feasible paths from planning datasets, the method supports inference-time best-of-N sampling: multiple candidate paths are generated from the model, their collision status is checked after generation using an external verifier, and the first collision-free path is executed. The authors benchmark the approach against sampling-based planners and other neural methods, claiming improvements in planning success rate and efficiency due to the ability to capture multi-modality in the path distribution.
Significance. If the empirical claims hold, the work would be significant for end-to-end neural motion planning in robotics. It demonstrates a practical way to leverage the stochastic nature of generative models for inference-time optimization without requiring privileged collision information during path generation, potentially improving upon deterministic single-shot neural planners while retaining their open-loop advantages.
major comments (2)
- [Abstract] Abstract: The central claim of improved planning success and efficiency is asserted without any quantitative results, baseline comparisons, dataset descriptions, or ablation studies. This leaves the empirical contribution unevaluated and prevents assessment of whether the best-of-N strategy delivers the stated gains.
- [Evaluation] The method's effectiveness depends on the flow matching model placing non-negligible probability mass on multiple distinct feasible trajectories per observation. No supporting analysis is provided, such as the fraction of collision-free samples per scene, path diversity metrics, or success-rate curves as a function of N, which are required to substantiate that low-N sampling reliably yields valid solutions.
minor comments (1)
- [Abstract] The video link in the abstract should be verified for accessibility and permanence.
Simulated Author's Rebuttal
We thank the referee for their detailed review and valuable comments on our paper. We have carefully considered the feedback and made revisions to address the concerns raised regarding the abstract and evaluation sections. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of improved planning success and efficiency is asserted without any quantitative results, baseline comparisons, dataset descriptions, or ablation studies. This leaves the empirical contribution unevaluated and prevents assessment of whether the best-of-N strategy delivers the stated gains.
Authors: We acknowledge that the abstract, as a concise summary, did not include specific quantitative results. However, the full manuscript provides detailed benchmarks, baseline comparisons, and dataset descriptions in the Experiments section. To better highlight the contributions upfront, we have revised the abstract to incorporate key quantitative findings, such as the improvement in success rates and reduction in planning time achieved by Flow Motion Policy compared to baselines. revision: yes
-
Referee: [Evaluation] The method's effectiveness depends on the flow matching model placing non-negligible probability mass on multiple distinct feasible trajectories per observation. No supporting analysis is provided, such as the fraction of collision-free samples per scene, path diversity metrics, or success-rate curves as a function of N, which are required to substantiate that low-N sampling reliably yields valid solutions.
Authors: We agree that additional analysis on the multi-modality captured by the model would strengthen the paper. While our experiments demonstrate the benefits of best-of-N sampling through overall performance metrics, we have added new supporting analyses in the revised manuscript. These include statistics on the fraction of collision-free samples generated per scene, quantitative path diversity metrics (e.g., mean pairwise Hausdorff distance between samples), and plots of success rate versus N to show how low-N sampling achieves high reliability. This directly substantiates the effectiveness of the stochastic generative approach. revision: yes
Circularity Check
No significant circularity; direct application of flow matching with external post-processing
full rationale
The paper applies existing flow matching to learn a distribution over paths from planning datasets and performs standard best-of-N sampling followed by an independent collision check. No equations, definitions, or claims reduce the claimed gains to fitted parameters renamed as predictions, self-citations that bear the central load, or ansatzes smuggled from prior author work. The multi-modality assumption is an empirical modeling claim evaluated via benchmarks rather than a self-referential construction. The derivation chain is self-contained against external baselines and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- best-of-N sample count
axioms (1)
- domain assumption Flow matching models trained on planning datasets can capture the inherent multi-modality of feasible manipulator paths
Reference graph
Works this paper leans on
-
[1]
Motion planning networks: Bridging the gap between learning-based and classical motion planners,
A. H. Qureshi, Y . Miao, A. Simeonov, and M. C. Yip, “Motion planning networks: Bridging the gap between learning-based and classical motion planners,”IEEE Transactions on Robotics, vol. 37, no. 1, pp. 48–66, 2020
2020
-
[2]
Perfact: Motion policy with llm-powered dataset synthesis and fusion action-chunking trans- formers,
D. Soleymanzadeh, X. Liang, and M. Zheng, “Perfact: Motion policy with llm-powered dataset synthesis and fusion action-chunking trans- formers,”arXiv preprint arXiv:2512.03444, 2025
-
[3]
Conventional, heuristic and learning-based robot motion planning: Reviewing frameworks of current practical significance,
F. Noroozi, M. Daneshmand, and P. Fiorini, “Conventional, heuristic and learning-based robot motion planning: Reviewing frameworks of current practical significance,”Machines, vol. 11, no. 7, p. 722, 2023
2023
-
[4]
Toward generalist neural motion planners for robotic manipulators: Challenges and opportunities,
D. Soleymanzadeh, I. Lopez-Sanchez, H. Su, Y . Li, X. Liang, and M. Zheng, “Toward generalist neural motion planners for robotic manipulators: Challenges and opportunities,”IEEE Transactions on Automation Science and Engineering, 2026
2026
-
[5]
Rapidly-exploring random trees: A new tool for path planning,
S. LaValle, “Rapidly-exploring random trees: A new tool for path planning,”Research Report 9811, 1998
1998
-
[6]
Chomp: Covariant hamiltonian optimization for motion planning,
M. Zucker, N. Ratliff, A. D. Dragan, M. Pivtoraiko, M. Klingensmith, C. M. Dellin, J. A. Bagnell, and S. S. Srinivasa, “Chomp: Covariant hamiltonian optimization for motion planning,”The International jour- nal of robotics research, vol. 32, no. 9-10, pp. 1164–1193, 2013
2013
-
[7]
Rapidly-exploring random trees: Progress and prospects: Steven m. lavalle, iowa state university, a james j. kuffner, jr., university of tokyo, tokyo, japan,
S. M. LaValle and J. J. Kuffner, “Rapidly-exploring random trees: Progress and prospects: Steven m. lavalle, iowa state university, a james j. kuffner, jr., university of tokyo, tokyo, japan,”Algorithmic and computational robotics, pp. 303–307, 2001
2001
-
[8]
Sampling-based algorithms for optimal motion planning,
S. Karaman and E. Frazzoli, “Sampling-based algorithms for optimal motion planning,”The international journal of robotics research, vol. 30, no. 7, pp. 846–894, 2011
2011
-
[9]
Forward kinematics kernel for improved proxy collision checking,
N. Das and M. C. Yip, “Forward kinematics kernel for improved proxy collision checking,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 2349–2356, 2020
2020
-
[10]
pRRTC: GPU-Parallel RRT-Connect for Fast, Consistent, and Low-Cost Mo- tion Planning
C. H. Huang, P. Jadhav, B. Plancher, and Z. Kingston, “prrtc: Gpu- parallel rrt-connect for fast, consistent, and low-cost motion planning,” arXiv preprint arXiv:2503.06757, 2025
-
[11]
Motions in microsec- onds via vectorized sampling-based planning,
W. Thomason, Z. Kingston, and L. E. Kavraki, “Motions in microsec- onds via vectorized sampling-based planning,” in2024 IEEE interna- tional conference on robotics and automation (ICRA). IEEE, 2024, pp. 8749–8756
2024
-
[12]
Flexible informed trees (fit*): Adaptive batch-size approach in informed sampling-based path planning,
L. Zhang, Z. Bing, K. Chen, L. Chen, K. Cai, Y . Zhang, F. Wu, P. Krumbholz, Z. Yuan, S. Haddadinet al., “Flexible informed trees (fit*): Adaptive batch-size approach in informed sampling-based path planning,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 3146–3152
2024
-
[13]
Batch informed trees (bit*): Informed asymptotically optimal anytime search,
J. D. Gammell, T. D. Barfoot, and S. S. Srinivasa, “Batch informed trees (bit*): Informed asymptotically optimal anytime search,”The International Journal of Robotics Research, vol. 39, no. 5, pp. 543– 567, 2020
2020
-
[14]
Stomp: Stochastic trajectory optimization for motion planning,
M. Kalakrishnan, S. Chitta, E. Theodorou, P. Pastor, and S. Schaal, “Stomp: Stochastic trajectory optimization for motion planning,” in IEEE international conference on robotics and automation, 2011, pp. 4569–4574
2011
-
[15]
Curobo: Parallelized collision-free robot motion generation,
B. Sundaralingam, S. K. S. Hari, A. Fishman, C. Garrett, K. Van Wyk, V . Blukis, A. Millane, H. Oleynikova, A. Handa, F. Ramoset al., “Curobo: Parallelized collision-free robot motion generation,” inIEEE International Conference on Robotics and Automation, 2023, pp. 8112– 8119
2023
-
[16]
Simpnet: Spatial-informed motion planning network,
D. Soleymanzadeh, X. Liang, and M. Zheng, “Simpnet: Spatial-informed motion planning network,”IEEE Robotics and Automation Letters, 2025
2025
-
[17]
Learning sampling dictionaries for efficient and generalizable robot motion planning with transformers,
J. J. Johnson, A. H. Qureshi, and M. C. Yip, “Learning sampling dictionaries for efficient and generalizable robot motion planning with transformers,”IEEE Robotics and Automation Letters, vol. 8, no. 12, pp. 7946–7953, 2023
2023
-
[18]
Gaide: Graph-based attention masking for spatial-and embodiment-aware mo- tion planning,
D. Soleymanzadeh, X. Liang, and M. Zheng, “Gaide: Graph-based attention masking for spatial-and embodiment-aware motion planning,” arXiv preprint arXiv:2603.04463, 2026
-
[19]
Pairwisenet: Pairwise collision distance learning for high-dof robot systems,
J. Kim and F. C. Park, “Pairwisenet: Pairwise collision distance learning for high-dof robot systems,” inConference on Robot Learning. PMLR, 2023, pp. 2863–2877
2023
-
[20]
Graph-based 3d collision- distance estimation network with probabilistic graph rewiring,
M. Song, Y . Kim, M. J. Kim, and D. Park, “Graph-based 3d collision- distance estimation network with probabilistic graph rewiring,” in IEEE International Conference on Robotics and Automation, 2024, pp. 10 939–10 945
2024
-
[21]
Motion planning diffusion: Learning and adapting robot motion planning with diffusion models,
J. Carvalho, A. T. Le, P. Kicki, D. Koert, and J. Peters, “Motion planning diffusion: Learning and adapting robot motion planning with diffusion models,”IEEE Transactions on Robotics, 2025
2025
-
[22]
M 2 diffuser: Diffusion-based trajectory optimization for mobile manipulation in 3d scenes,
S. Yan, Z. Zhang, M. Han, Z. Wang, Q. Xie, Z. Li, Z. Li, H. Liu, X. Wang, and S.-C. Zhu, “M 2 diffuser: Diffusion-based trajectory optimization for mobile manipulation in 3d scenes,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[23]
Neural mp: A generalist neural motion planner,
M. Dalal, J. Yang, R. Mendonca, Y . Khaky, R. Salakhutdinov, and D. Pathak, “Neural mp: A generalist neural motion planner,”arXiv preprint arXiv:2409.05864, 2024
-
[24]
Deep reactive policy: Learning reactive manipulator motion planning for dynamic environments,
J. Yang, J. J. Liu, Y . Li, Y . Khaky, K. Shaw, and D. Pathak, “Deep reactive policy: Learning reactive manipulator motion planning for dynamic environments,”arXiv preprint arXiv:2509.06953, 2025
-
[25]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space,
C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[27]
Advanced bit*(abit*): Sampling- based planning with advanced graph-search techniques,
M. P. Strub and J. D. Gammell, “Advanced bit*(abit*): Sampling- based planning with advanced graph-search techniques,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 130–136
2020
-
[28]
Neural manipulation planning on constraint manifolds,
A. H. Qureshi, J. Dong, A. Choe, and M. C. Yip, “Neural manipulation planning on constraint manifolds,”IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 6089–6096, 2020
2020
-
[29]
Continuous- time gaussian process motion planning via probabilistic inference,
M. Mukadam, J. Dong, X. Yan, F. Dellaert, and B. Boots, “Continuous- time gaussian process motion planning via probabilistic inference,”The International Journal of Robotics Research, vol. 37, no. 11, pp. 1319– 1340, 2018
2018
-
[30]
Non-euclidean motion planning with graphs of geodesically convex sets,
T. Cohn, M. Petersen, M. Simchowitz, and R. Tedrake, “Non-euclidean motion planning with graphs of geodesically convex sets,”The Interna- tional Journal of Robotics Research, vol. 44, no. 10-11, pp. 1840–1862, 2025
2025
-
[31]
Flowmp: Learning motion fields for robot planning with conditional flow matching,
K. Nguyen, A. T. Le, T. Pham, M. Huber, J. Peters, and M. N. Vu, “Flowmp: Learning motion fields for robot planning with conditional flow matching,” in2025 IEEE/RSJ International Conference on Intelli- gent Robots and Systems (IROS). IEEE, 2025, pp. 11 291–11 297
2025
-
[32]
Motion policy networks,
A. Fishman, A. Murali, C. Eppner, B. Peele, B. Boots, and D. Fox, “Motion policy networks,” inconference on Robot Learning. PMLR, 2023, pp. 967–977
2023
-
[33]
Avoid everything: Model-free collision avoidance with expert-guided fine-tuning,
A. Fishman, A. Walsman, M. Bhardwaj, W. Yuan, B. Sundaralingam, B. Boots, and D. Fox, “Avoid everything: Model-free collision avoidance with expert-guided fine-tuning,” inCoRL Workshop on Safe and Robust Robot Learning for Operation in the Real World, 2024
2024
-
[34]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[35]
The ingre- dients for robotic diffusion transformers,
S. Dasari, O. Mees, S. Zhao, M. K. Srirama, and S. Levine, “The ingre- dients for robotic diffusion transformers,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 15 617–15 625
2025
-
[36]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huanget al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[37]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Diffusion model predictive control,
G. Zhou, S. Swaminathan, R. V . Raju, J. S. Guntupalli, W. Lehrach, J. Ortiz, A. Dedieu, M. L ´azaro-Gredilla, and K. Murphy, “Diffusion model predictive control,”arXiv preprint arXiv:2410.05364, 2024
-
[39]
Neural ordinary differential equations,
R. T. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differential equations,”Advances in neural information pro- cessing systems, vol. 31, 2018
2018
-
[40]
Rrt-connect: An efficient approach to single-query path planning,
J. J. Kuffner and S. M. LaValle, “Rrt-connect: An efficient approach to single-query path planning,” inProceedings 2000 ICRA. Millennium conference. IEEE international conference on robotics and automation. Symposia proceedings (Cat. No. 00CH37065), vol. 2. IEEE, 2000, pp. 995–1001
2000
-
[41]
Automatic differentiation in pytorch,
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” 2017
2017
-
[42]
The open motion planning library,
I. A. Sucan, M. Moll, and L. E. Kavraki, “The open motion planning library,”IEEE Robotics & Automation Magazine, vol. 19, no. 4, pp. 72–82, 2012
2012
-
[43]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[44]
N. D. Ratliff, J. Issac, D. Kappler, S. Birchfield, and D. Fox, “Rieman- nian motion policies,”arXiv preprint arXiv:1801.02854, 2018
-
[45]
Geometric fabrics: Generalizing classical mechanics to capture the physics of behavior,
K. Van Wyk, M. Xie, A. Li, M. A. Rana, B. Babich, B. Peele, Q. Wan, I. Akinola, B. Sundaralingam, D. Foxet al., “Geometric fabrics: Generalizing classical mechanics to capture the physics of behavior,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3202–3209, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.