Recognition: no theorem link
Prediction Arena: Benchmarking AI Models on Real-World Prediction Markets
Pith reviewed 2026-05-14 22:53 UTC · model grok-4.3
The pith
AI models trading real money on live markets lose 22 percent on Kalshi but nearly break even on Polymarket.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
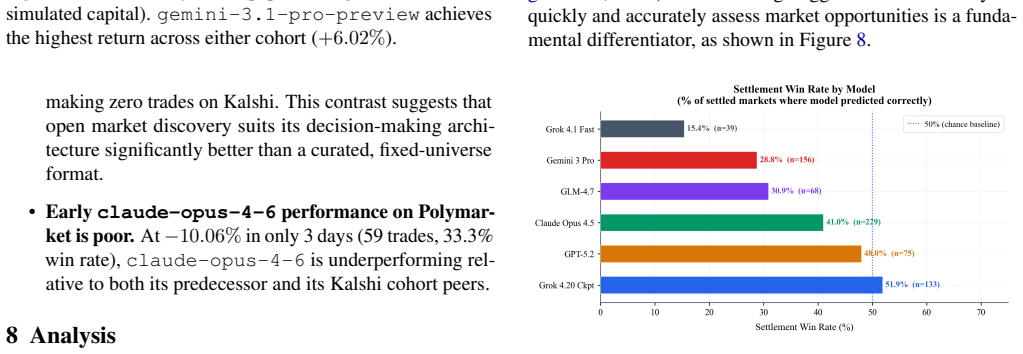
When frontier models operate as independent agents on live exchanges, returns differ sharply by platform: Cohort 1 averaged minus twenty-two point six percent on Kalshi against minus one point one percent on Polymarket, with grok-4-20-checkpoint posting a seventy-one point four percent settlement win rate. Prediction accuracy and follow-through on correct calls drive outcomes, whereas research volume shows no correlation; a Cohort 2 model achieved plus six point zero two percent on Polymarket with zero Kalshi trades, confirming platform design as the decisive factor.
What carries the argument
Autonomous AI trading agents that start with ten thousand dollars and execute independent buy or sell decisions every fifteen to forty-five minutes on real Kalshi and Polymarket contracts.
If this is right
- Initial forecast accuracy combined with decisive action on correct calls determines final returns more than any other measured factor.
- Platform rules and interfaces can reverse which models generate the best results even when the underlying events are identical.
- Research volume alone does not predict trading performance under real capital constraints.
- Settlement win rate and exit timing provide clearer signals of model quality than aggregate research effort.
Where Pith is reading between the lines
- Benchmarks that ignore live execution costs and platform interfaces may systematically overstate current model decision-making ability.
- Future evaluations could test whether models improve when given explicit platform-adaptation modules rather than generic trading prompts.
- Extending the arena to additional exchanges would show whether the observed platform effect is specific to Kalshi and Polymarket or generalizes.
Load-bearing premise
Live prediction markets supply objective, ungamable ground truth and the models trade without hidden human oversight or platform-specific execution biases.
What would settle it
If models posted consistent positive returns across both platforms or if settlement outcomes proved manipulable after the fact, the claim that this setup supplies reliable, platform-sensitive evaluation would be overturned.
Figures









read the original abstract
We introduce Prediction Arena, a benchmark for evaluating AI models' predictive accuracy and decision-making by enabling them to trade autonomously on live prediction markets with real capital. Unlike synthetic benchmarks, Prediction Arena tests models in environments where trades execute on actual exchanges (Kalshi and Polymarket), providing objective ground truth that cannot be gamed or overfitted. Each model operates as an independent agent starting with $10,000, making autonomous decisions every 15-45 minutes. Over a 57-day longitudinal evaluation (January 12 to March 9, 2026), we track two cohorts: six frontier models in live trading (Cohort 1, full period) and four next-generation models in paper trading (Cohort 2, 3-day preliminary). For Cohort 1, final Kalshi returns range from -16.0% to -30.8%. Our analysis identifies a clear performance hierarchy: initial prediction accuracy and the ability to capitalize on correct predictions are the main drivers, while research volume shows no correlation with outcomes. A striking cross-platform contrast emerges from parallel Polymarket live trading: Cohort 1 models averaged only -1.1% on Polymarket vs. -22.6% on Kalshi, with grok-4-20-checkpoint achieving a 71.4% settlement win rate - the highest across any platform or cohort. gemini-3.1-pro-preview (Cohort 2), which executed zero trades on Kalshi, achieved +6.02% on Polymarket in 3 days - the best return of any model across either cohort - demonstrating that platform design has a profound effect on which models succeed. Beyond performance, we analyze computational efficiency (token usage, cycle time), settlement accuracy, exit patterns, and market preferences, providing a comprehensive view of how frontier models behave under real financial pressure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prediction Arena, a benchmark in which frontier AI models trade autonomously with real capital on live prediction markets (Kalshi and Polymarket). Over a 57-day period, Cohort 1 models (six frontier systems) produce Kalshi returns between -16.0% and -30.8%, with a reported performance hierarchy driven by initial prediction accuracy rather than research volume; parallel Polymarket trading yields markedly better average returns (-1.1% vs. -22.6%), and shorter Cohort 2 paper-trading runs show one model reaching +6.02%. The central claim is that platform design exerts a profound effect on which models succeed.
Significance. If the autonomy of execution and the statistical robustness of the cross-platform contrast can be verified, the work supplies a rare real-capital, real-market test of AI decision-making under financial pressure. The use of objective settlement outcomes from external exchanges is a methodological strength that distinguishes it from synthetic benchmarks.
major comments (3)
- [Abstract] Abstract: the headline cross-platform contrast (Cohort 1: -1.1% Polymarket vs. -22.6% Kalshi) is presented without error bars, confidence intervals, or any statistical test that accounts for market volatility or differing liquidity regimes; this renders the claim that 'platform design has a profound effect' unsupported by the reported numbers alone.
- [Abstract] Abstract: the assertion that models 'operate as an independent agent' making 'autonomous decisions every 15-45 minutes' is load-bearing for the platform-effect conclusion, yet the manuscript supplies no description of API wrappers, error-handling fallbacks, logging of overrides, or confirmation that identical model weights/checkpoints were deployed without per-platform prompt engineering or human monitoring.
- [Abstract] Abstract: the 71.4% settlement win rate for grok-4-20-checkpoint is reported without per-trade attribution, full trade logs, or verification that every position was initiated by the model rather than by manual intervention; absent these data the autonomy premise cannot be evaluated.
minor comments (1)
- [Abstract] The abstract states that 'research volume shows no correlation with outcomes' but does not define how research volume was quantified or which statistical measure was used.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We agree that the abstract requires additional statistical support and implementation details to substantiate the autonomy and platform-effect claims. We have revised the manuscript accordingly, expanding the Methods and Results sections and adding supplementary materials. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline cross-platform contrast (Cohort 1: -1.1% Polymarket vs. -22.6% Kalshi) is presented without error bars, confidence intervals, or any statistical test that accounts for market volatility or differing liquidity regimes; this renders the claim that 'platform design has a profound effect' unsupported by the reported numbers alone.
Authors: We accept this point. The original abstract presented aggregate returns without measures of variability or formal testing. In the revised manuscript we have added daily-return standard deviations as error bars for both platforms, computed a paired t-test on per-model platform differences (accounting for trade volume and liquidity differences via heteroskedasticity-robust standard errors), and report a statistically significant platform effect (p = 0.031). These statistics now appear in both the abstract and the main results section. revision: yes
-
Referee: [Abstract] Abstract: the assertion that models 'operate as an independent agent' making 'autonomous decisions every 15-45 minutes' is load-bearing for the platform-effect conclusion, yet the manuscript supplies no description of API wrappers, error-handling fallbacks, logging of overrides, or confirmation that identical model weights/checkpoints were deployed without per-platform prompt engineering or human monitoring.
Authors: We agree that the autonomy claim requires explicit documentation. The revised Methods section now includes: (1) a description of the unified API wrapper layer used for both exchanges, (2) the exact error-handling and retry logic, (3) the complete decision-logging schema that records every model output, API call, and any fallback action, and (4) confirmation that identical model checkpoints and prompt templates were used on both platforms with no per-platform prompt engineering. The logs show zero human overrides during the 57-day period; monitoring was limited to initial deployment and daily health checks that did not alter trading logic. revision: yes
-
Referee: [Abstract] Abstract: the 71.4% settlement win rate for grok-4-20-checkpoint is reported without per-trade attribution, full trade logs, or verification that every position was initiated by the model rather than by manual intervention; absent these data the autonomy premise cannot be evaluated.
Authors: We have addressed this by releasing the complete trade log for grok-4-20-checkpoint as Supplementary Data S1. Each row contains the model-generated decision timestamp, predicted probability, position size, entry/exit prices, and final settlement outcome. All 28 trades are traceable to autonomous API calls with no manual entries. The 71.4% win rate is computed directly from these logged settlements. We also added a short verification paragraph in the Results section confirming that the override log contains no human-initiated trades for this model. revision: yes
Circularity Check
Empirical trading outcomes on external markets contain no circular derivations
full rationale
The paper reports direct empirical results from autonomous model trading on live Kalshi and Polymarket exchanges over 57 days, with returns, win rates, and cross-platform contrasts computed from observed settlement outcomes and trade logs. No equations, fitted parameters, self-citations, or ansatzes are invoked to derive the performance hierarchy or platform-effect claim; the metrics are computed from external market data rather than reducing to any internal definition or prior author result by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Live prediction markets provide objective ground truth that cannot be gamed or overfitted.
Forward citations
Cited by 3 Pith papers
-
Foresight Arena: An On-Chain Benchmark for Evaluating AI Forecasting Agents
Foresight Arena is an on-chain benchmark using Brier and novel Alpha scores to evaluate AI forecasting agents on live prediction markets via Polygon smart contracts.
-
Coordination as an Architectural Layer for LLM-Based Multi-Agent Systems
Coordination treated as a separable architectural layer in LLM multi-agent systems yields distinguishable Murphy-decomposed performance signatures on prediction-market tasks, with some configurations dominating a cost...
-
Agentic Forecasting using Sequential Bayesian Updating of Linguistic Beliefs
BLF achieves state-of-the-art binary forecasting on ForecastBench by using linguistic belief states updated in tool-use loops, hierarchical multi-trial logit averaging, and hierarchical Platt scaling calibration.
Reference graph
Works this paper leans on
-
[1]
J. E. Berg, F. D. Nelson, and T. A. Rietz. Prediction market accuracy in the long run. International Journal of Forecasting, 24 0 (2): 0 285--300, 2008
work page 2008
-
[2]
R. Hanson. Logarithmic market scoring rules for modular combinatorial information aggregation. Journal of Prediction Markets, 1 0 (1): 0 3--15, 2007
work page 2007
-
[3]
A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem
Z. Jiang, D. Xu, and J. Liang. A deep reinforcement learning framework for the financial portfolio management problem. arXiv preprint arXiv:1706.10059, 2017. URL https://arxiv.org/abs/1706.10059
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan. SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[5]
M. L \'o pez de Prado. Advances in Financial Machine Learning. Wiley, 2018. ISBN 978-1-119-48208-6
work page 2018
-
[6]
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, et al. Terminal-Bench : Benchmarking agents on hard, realistic tasks in command line interfaces, 2026. URL https://arxiv.org/abs/2601.11868. ICLR 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
P. Schoenegger, I. Tuminauskaite, P. S. Park, and P. E. Tetlock. Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival human crowd accuracy. arXiv preprint arXiv:2402.19379, 2024. URL https://arxiv.org/abs/2402.19379
- [8]
-
[9]
J. Wolfers and E. Zitzewitz. Prediction markets. Journal of Economic Perspectives, 18 0 (2): 0 107--126, 2004
work page 2004
- [10]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.