Recognition: unknown
Coordination as an Architectural Layer for LLM-Based Multi-Agent Systems
Pith reviewed 2026-05-09 15:39 UTC · model grok-4.3
The pith
Coordination should be treated as a separate configurable architectural layer in multi-agent LLM systems, distinct from agent logic and information access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
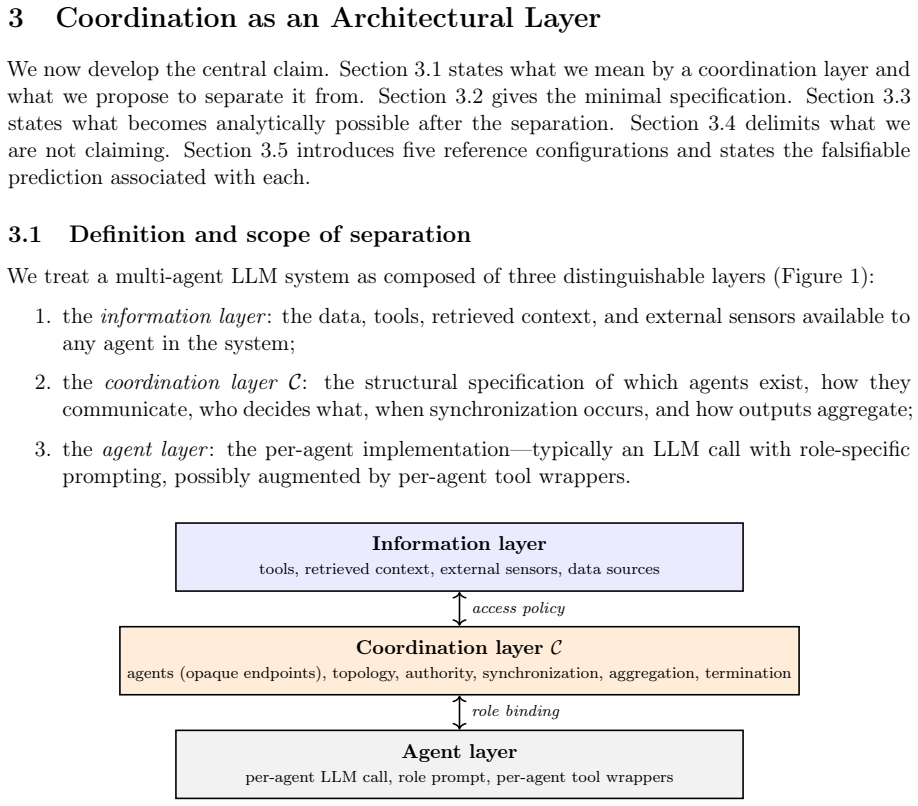
We argue that coordination should be treated as a configurable architectural layer, separable from agent logic and from information access, enabling architectural reasoning rather than only engineering productivity. We instantiate this with an information-controlled design on prediction markets: a single LLM, fixed tools, fixed per-call output cap, and fixed prompt template across five reference coordination configurations, with total compute per question treated as an endogenous architectural output. The Murphy decomposition of the Brier score separates calibration from discriminative power, so configurations leave distinguishable signatures even when aggregate scores coincide.
What carries the argument
The information-controlled design that holds the LLM, tools, output cap, and prompt template fixed while varying only coordination rules, paired with the Murphy decomposition of the Brier score to extract distinguishable calibration and discrimination signatures.
If this is right
- Different coordination configurations will produce distinct patterns of calibration and discriminative power even when overall accuracy scores match.
- Certain coordination setups will dominate others on the cost-quality trade-off when total compute is counted as an output.
- Pre-specified predictions about which configurations perform best can be tested directly through the separated score components.
- Architectural decisions about coordination can be evaluated for their expected failure-mode signatures before full deployment.
Where Pith is reading between the lines
- The separation method could be tested on tasks other than binary prediction markets to check whether coordination signatures remain distinguishable.
- If the isolation holds, existing multi-agent systems could be debugged by changing only the coordination layer while keeping agents and data access fixed.
- Accumulating results from live deployments on platforms like Foresight Arena would provide ongoing data to refine the mapping from coordination choices to outcomes.
Load-bearing premise
Fixing the language model, tools, output limits, and prompt template across different coordination setups isolates coordination effects enough for performance differences to be attributed to coordination alone.
What would settle it
Repeating the controlled experiment on the same 100 markets and finding that the Murphy signatures do not differ across the five coordination configurations would show that coordination effects cannot be isolated this way.
Figures






read the original abstract
Multi-agent LLM systems fail in production at rates between 41% and 87%, mostly due to coordination defects rather than base-model capability. Existing responses split between cataloguing failure modes empirically and shipping declarative orchestration frameworks as engineering tools; neither delivers a principled mapping from coordination configuration to predictable failure-mode signature. We argue that coordination should be treated as a configurable architectural layer, separable from agent logic and from information access, enabling architectural reasoning rather than only engineering productivity. We instantiate this with an information-controlled design on prediction markets: a single LLM, fixed tools, fixed per-call output cap, and fixed prompt template across five reference coordination configurations, with total compute per question treated as an endogenous architectural output. The Murphy decomposition of the Brier score separates calibration from discriminative power, so configurations leave distinguishable signatures even when aggregate scores coincide. On 100 Polymarket binary markets resolved after the model's training cutoff (claude-opus-4-6) we report Murphy signatures, a cost-quality Pareto frontier, category-conditioned analysis, and a bootstrap power-projection. Three of five pre-specified predictions are upheld in direction; two configurations dominate the Pareto frontier within this regime; exploratory bootstrap intervals separate consensus alignment from others, though pairwise tests do not survive Bonferroni correction at n=100. We also deploy the same configurations as live agents on Foresight Arena under web-search-enabled conditions, as an on-chain replication channel accumulating in parallel. Harness, trace dataset, and production agents are released. We position this as a methodology-validating first instantiation, not a general cross-model claim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that coordination in LLM-based multi-agent systems should be treated as a configurable architectural layer separable from agent logic and information access, enabling principled architectural reasoning rather than ad-hoc engineering. It instantiates this via an information-controlled design on 100 post-training-cutoff Polymarket binary markets, holding a single LLM (claude-opus-4-6), tools, per-call output cap, and prompt template fixed across five coordination configurations while treating total compute per question as an endogenous output. Murphy decomposition of the Brier score is used to produce distinguishable signatures; three of five pre-specified predictions are upheld in direction, two configurations dominate the reported Pareto frontier, bootstrap intervals provide exploratory separation, and the harness, trace dataset, and live agents on Foresight Arena are released.
Significance. If the separability premise holds, the work supplies a reproducible methodology for mapping coordination configurations to predictable failure-mode signatures, shifting the field from empirical catalogs of defects and declarative orchestration tools toward architectural analysis. Notable strengths include pre-specified predictions, bootstrap power-projection, category-conditioned analysis, cost-quality Pareto evaluation, and full release of harness, trace dataset, and production agents, which support reproducibility and ongoing validation via the on-chain channel.
major comments (2)
- [Methods / Experimental Design] Experimental design (information-controlled setup): The claim that coordination is isolated by fixing the LLM, tools, output cap, and prompt template across configurations is load-bearing for attributing Murphy signatures to coordination alone. However, mechanisms such as consensus or debate inherently alter interaction structure, role assignments, and message routing; these changes can modify the effective context or template instantiation even with a fixed template, risking residual confounding between coordination and information access.
- [Results] Results (statistical analysis): Three of five predictions are upheld in direction and two configurations are Pareto-dominant, but pairwise tests do not survive Bonferroni correction at n=100 and power is limited. This constrains the strength of the claim that configurations produce reliably distinguishable Murphy signatures, even though bootstrap intervals separate consensus alignment from others.
minor comments (3)
- [Methods] Clarify in the text how the fixed prompt template is instantiated under each coordination mechanism (e.g., exact message formatting for debate vs. consensus) to make the isolation claim more transparent.
- [Figures] Figure captions for the Pareto frontier and Murphy signature plots should explicitly note the bootstrap procedure and any confidence intervals used.
- [Abstract] The abstract states the model as 'claude-opus-4-6'; provide the precise version string and any relevant API parameters for full reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help refine the presentation of our experimental controls and statistical claims. We address each major point below, making targeted revisions to improve clarity and acknowledge limitations without altering the core design or findings.
read point-by-point responses
-
Referee: [Methods / Experimental Design] Experimental design (information-controlled setup): The claim that coordination is isolated by fixing the LLM, tools, output cap, and prompt template across configurations is load-bearing for attributing Murphy signatures to coordination alone. However, mechanisms such as consensus or debate inherently alter interaction structure, role assignments, and message routing; these changes can modify the effective context or template instantiation even with a fixed template, risking residual confounding between coordination and information access.
Authors: We agree that coordination mechanisms inherently change interaction structure, role assignments, and message routing, which can affect effective context even under a fixed base template. Our information-controlled design holds the LLM, tools, per-call output cap, and prompt template constant precisely to isolate coordination as the primary architectural variable, treating total compute as endogenous. To address the concern directly, we will add a new paragraph in the Methods section explicitly discussing residual confounding risks and how the fixed template and tool constraints minimize (but do not eliminate) differences in information flow across configurations. This revision provides a more precise interpretation of the Murphy signatures without changing the experimental setup or claims. revision: partial
-
Referee: [Results] Results (statistical analysis): Three of five predictions are upheld in direction and two configurations are Pareto-dominant, but pairwise tests do not survive Bonferroni correction at n=100 and power is limited. This constrains the strength of the claim that configurations produce reliably distinguishable Murphy signatures, even though bootstrap intervals separate consensus alignment from others.
Authors: The manuscript already qualifies the bootstrap intervals as exploratory and notes that pairwise tests do not survive Bonferroni correction at n=100. We concur that limited power constrains stronger claims of reliable distinguishability. In revision, we will update the Results section to more prominently emphasize the exploratory character of the signature separations, add a short power discussion referencing the bootstrap approach, and adjust phrasing in the abstract and conclusion from 'distinguishable signatures' to 'exploratory evidence of distinguishable signatures' while preserving the pre-specified predictions and Pareto frontier results. This better aligns the language with the evidence strength. revision: partial
Circularity Check
No load-bearing circularity; signatures obtained from pre-specified configurations and Murphy decomposition without definitional reduction.
full rationale
The paper posits coordination as a separable architectural layer and instantiates the claim via an information-controlled experiment holding LLM, tools, output cap, and prompt template fixed across five configurations while treating total compute as an endogenous output. Murphy decomposition is applied to Brier scores on 100 out-of-training Polymarket resolutions to produce distinguishable calibration/discrimination signatures. No equations reduce reported signatures to quantities defined by fitted parameters within the paper, and no self-citation chain or ansatz is invoked to force the separability result. Pre-specified directional predictions are tested empirically with partial support (three of five upheld, no Bonferroni-significant pairwise differences). The design therefore remains self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Murphy decomposition of the Brier score separates calibration from discriminative power so that coordination configurations leave distinguishable signatures
Forward citations
Cited by 2 Pith papers
-
Manipulation, Insider Information, and Regulation in Leveraged Event-Linked Markets
Leverage scales market-price manipulation linearly while shifting outcome-manipulation thresholds and multiplying informed-trading rents in three distinct ways, calling for re-allocated regulatory attack surfaces rath...
-
A Taxonomy of Event-Linked Perpetual Futures: Variant Designs Beyond the Single-Market Binary Case
The paper organizes seven canonical variants of event-linked perpetual futures along four design axes, supplying payoff definitions, inheritance rules from prior work, and variant-specific constraints.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2604.16339. arXiv:2604.16339. Saaket Agashe, Yue Fan, Anthony Reyna, and Xin Eric Wang. LLM-coordination: Evaluating and analyzing multi-agent coordination abilities in large language models. InFindings of the Association for Computational Linguistics: NAACL,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv:2310.03903. Ruicheng Ao, Siyang Gao, and David Simchi-Levi. On the reliability limits of LLM-based multi- agent planning,
-
[3]
URLhttps://arxiv.org/abs/2603.26993. arXiv:2603.26993. Glenn W. Brier. Verification of forecasts expressed in terms of probability.Monthly Weather Review, 78(1):1–3,
-
[4]
URLhttps://arxiv.org/abs/2602.23720. arXiv:2602.23720. Mert Cemri, Melissa Z. Pan, Shuyi Yang, et al. Why do multi-agent LLM systems fail? InProceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track,
-
[5]
URLhttps://arxiv.org/abs/2503. 13657. arXiv:2503.13657. Jacob Cohen.Statistical Power Analysis for the Behavioral Sciences. Lawrence Erlbaum Associates, 2 edition,
work page internal anchor Pith review arXiv
- [6]
- [7]
-
[8]
Philipp Schoenegger, Indre Tuminauskaite, Peter S
arXiv:2310.13014. Philipp Schoenegger, Indre Tuminauskaite, Peter S. Park, and Philip E. Tetlock. Wisdom of the silicon crowd: LLM ensemble prediction capabilities rival human crowd accuracy.Science Advances, 10(45):eadp1528,
-
[9]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
arXiv:2308.08155. Andrea Wynn, Harsh Satija, and Gillian Hadfield. Talk isn’t always cheap: Understanding failure modes in multi-agent debate,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv:2509.05396. Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying LLM-based software engineering agents,
-
[11]
Jiawei Zhang, Guangyu Liu, Oscar Johansson, et al
arXiv:2601.12307. Jiawei Zhang, Guangyu Liu, Oscar Johansson, et al. Prediction Arena: Benchmarking AI models on real-world prediction markets,
-
[12]
Prediction Arena: Benchmarking AI Models on Real-World Prediction Markets
arXiv:2604.07355. Andy Zou, Edward Chen, Karthik Arumugam, et al. ForecastBench: A dynamic benchmark of AI forecasting capabilities,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv:2409.19839. 30 A Intention-to-treat sensitivity: failure handling The leaderboard in Table 2 reports per-configuration Brier on the 494 successful predictions out of 500 attempted (100 markets×5 configurations). The 6 failures all fell to the runner’s fallback p= 0.5due to transient API errors (network timeouts, malformed JSON returns from the model...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.