SubSearch: Intermediate Rewards for Unsupervised Guided Reasoning in Complex Retrieval
Pith reviewed 2026-05-10 17:52 UTC · model grok-4.3
The pith
SubSearch trains LLMs for complex retrieval by rewarding good intermediate reasoning steps with rewards derived inside the model itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SubSearch directly optimizes the generator model using intrinsic process rewards, defined as internally-derived signals that evaluate and encourage high-quality intermediate reasoning steps. This replaces reliance on outcome-only supervision or externally annotated trajectories, resulting in more robust reasoning traces on both standard QA and multi-hop QA datasets across seven benchmarks while serving as a data-efficient alternative to supervised process reward modeling.
What carries the argument
The SubSearch framework's intrinsic process rewards, which are internally computed signals that evaluate and incentivize individual reasoning steps during generation rather than waiting for the final outcome.
If this is right
- Reasoning traces become more robust than those from outcome-only reinforcement learning on QA and multi-hop QA tasks.
- Agents can integrate search engines more effectively when answering complex queries that require planning.
- The method offers a data-efficient route to guided reasoning that avoids the cost of creating supervised process reward datasets.
Where Pith is reading between the lines
- The same internal-reward idea could be tested on other multi-step tasks such as mathematical derivations or program synthesis to see if it reduces error accumulation.
- Removing the need for large external judges for every training step might make iterative self-improvement of reasoning models more practical at scale.
- If the intrinsic signals prove stable, they could support training loops where the model continually refines its own planning without periodic human intervention.
Load-bearing premise
That rewards calculated from within the model can reliably spot and reinforce high-quality reasoning steps without any external check or validation.
What would settle it
Running the same seven-benchmark comparison and finding that the intermediate-reward version produces reasoning traces no more robust than the outcome-only baseline would show the central claim does not hold.
Figures





read the original abstract
Large language models (LLMs) are probabilistic in nature and perform more reliably when augmented with external information. As complex queries often require multi-step reasoning over the retrieved information, with no clear or predetermined reasoning path, they remain challenging. Recent approaches train models using reinforcement learning on the model's outcome, showing promise in improving how models handle complex information. We introduce SubSearch, a specialized framework that shifts from outcome-only supervision to intermediate reward signals that incentivize planning high-quality reasoning. Unlike previous work on process reward modeling, which focuses on training a separate reward model with annotated trajectories by either human annotators or large LLM judges, SubSearch directly optimizes the generator using intrinsic process rewards, which we define as internally-derived rewards, eliminating the need for external supervision, and moving towards autonomous information-intensive reasoning. Experiments on seven benchmarks show that rewarding intermediate reasoning steps with intrinsic rewards leads to more robust reasoning traces in both QA and multi-hop QA datasets over using only outcome rewards. SubSearch can help in building reasoning traces that allow agents to better integrate search engines for complex query answering, while offering a data-efficient alternative to supervised process modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SubSearch, a framework for unsupervised guided reasoning in complex retrieval tasks using large language models. It shifts from outcome-only reinforcement learning to using intrinsic process rewards derived internally from the model to incentivize high-quality intermediate reasoning steps. The central claim is that this leads to more robust reasoning traces on seven QA and multi-hop QA benchmarks compared to outcome-only supervision, offering a data-efficient alternative to supervised process reward modeling without requiring external annotations.
Significance. If the empirical results hold under detailed scrutiny, the work could advance scalable, annotation-free methods for improving multi-step reasoning in retrieval-augmented LLMs. It offers a potential path toward autonomous agents that better integrate search engines for complex queries by relying on internally-derived signals rather than human or LLM judges for process supervision. The unsupervised framing is a notable strength if the intrinsic rewards can be shown to align with reasoning quality.
major comments (3)
- [§4] §4 (Experiments): The definition and computation of the intrinsic process rewards are not specified (e.g., no equation or algorithm for how internal signals such as uncertainty or consistency are derived and applied as step-level rewards). This is load-bearing for the central claim that these rewards outperform outcome-only RL, as the skeptic concern about weak proxy alignment with actual step quality cannot be assessed without the exact formulation.
- [§4.1–4.3] §4.1–4.3 (Benchmarks, Baselines, and Results): No details are provided on the seven benchmarks (specific datasets, splits, or metrics), the outcome-only baseline implementation (RL algorithm, hyperparameters, or prompt controls), or quantitative evidence for 'more robust reasoning traces' (e.g., error rates, trace length, or human/AI evaluation protocols). Without these, the reported gains cannot be verified or reproduced.
- [§5] §5 (Discussion): The assertion that intrinsic rewards enable 'data-efficient' training without external supervision lacks any ablation or analysis showing that the internal signals correlate with correctness rather than model artifacts, particularly in multi-hop settings where errors compound. This directly impacts the weakest assumption identified in the review.
minor comments (2)
- [Abstract and §1] The abstract and introduction could more explicitly contrast SubSearch with prior process reward modeling works by citing specific limitations addressed.
- [§3] Notation for the reward function and RL objective in §3 would benefit from an explicit mathematical formulation to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify important areas for improving clarity, reproducibility, and evidential support. We will revise the manuscript to address each point directly.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The definition and computation of the intrinsic process rewards are not specified (e.g., no equation or algorithm for how internal signals such as uncertainty or consistency are derived and applied as step-level rewards). This is load-bearing for the central claim that these rewards outperform outcome-only RL, as the skeptic concern about weak proxy alignment with actual step quality cannot be assessed without the exact formulation.
Authors: We agree that the precise formulation is essential for assessing the method and its claims. The manuscript currently defines intrinsic process rewards at a high level as internally-derived signals from the generator model. In the revision we will add to §4 an explicit equation and pseudocode describing the computation: uncertainty via normalized entropy over token probabilities at each step, and consistency via agreement across multiple sampled continuations, with the combined signal applied as a step-level multiplier to the outcome reward. This will allow direct evaluation of proxy alignment. revision: yes
-
Referee: [§4.1–4.3] §4.1–4.3 (Benchmarks, Baselines, and Results): No details are provided on the seven benchmarks (specific datasets, splits, or metrics), the outcome-only baseline implementation (RL algorithm, hyperparameters, or prompt controls), or quantitative evidence for 'more robust reasoning traces' (e.g., error rates, trace length, or human/AI evaluation protocols). Without these, the reported gains cannot be verified or reproduced.
Authors: We will expand §4.1–4.3 with the requested details: full list of the seven benchmarks with dataset names, splits, and metrics; complete specification of the outcome-only baseline including the RL algorithm, all hyperparameters, and prompt templates; and quantitative supporting evidence such as per-dataset error rates, average reasoning trace lengths, and the exact human/AI evaluation protocol used to assess trace robustness. These additions will enable verification and reproduction. revision: yes
-
Referee: [§5] §5 (Discussion): The assertion that intrinsic rewards enable 'data-efficient' training without external supervision lacks any ablation or analysis showing that the internal signals correlate with correctness rather than model artifacts, particularly in multi-hop settings where errors compound. This directly impacts the weakest assumption identified in the review.
Authors: We acknowledge that stronger empirical support is needed for the correlation claim. In the revised §5 we will add an ablation study reporting correlation coefficients between intrinsic reward values and step-level correctness (measured on a held-out annotated subset), together with a targeted analysis of multi-hop cases that quantifies reduction in compounding errors relative to the outcome-only baseline. This will directly substantiate the data-efficiency argument. revision: yes
Circularity Check
No circularity; central claims rest on independent experimental comparisons
full rationale
The paper defines intrinsic process rewards as internally-derived signals without external supervision and reports that their use produces more robust reasoning traces than outcome-only rewards. This is supported by direct empirical evaluation on seven standard QA and multi-hop QA benchmarks using external correctness metrics. No load-bearing step reduces to a self-definition, a fitted parameter renamed as a prediction, or a self-citation chain that substitutes for independent evidence. The derivation from method to reported gains is therefore self-contained through falsifiable experiments rather than construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Internally-derived intrinsic process rewards can guide high-quality reasoning without external supervision
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
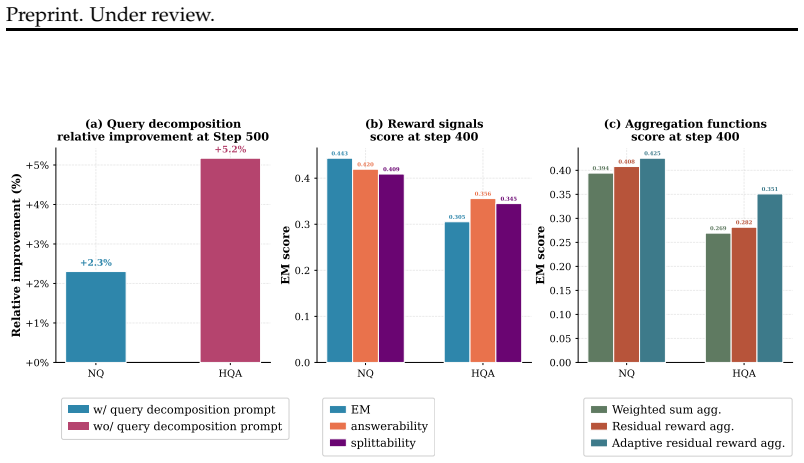
SubSearch directly optimizes the generator using intrinsic process rewards... Ranswer(a)=EM(a,agold); Ranswerability via cosine sim; Rdecomposition=α·rcoverage+β·rsplit; adaptive residual aggregation r=Ranswer+β(1−Ranswer)·½[avg(Ranswerability)+avg(Rdecomposition)]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on seven benchmarks... rewarding intermediate reasoning steps with intrinsic rewards leads to more robust reasoning traces
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Reward Model Overoptimization
URLhttps://arxiv.org/abs/2210.10760. Aaron Grattafiori, Abhimanyu Dubey, et al. The Llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783. Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 1049–1065, 2023. Ziyang Huang, Xiaowei...
work page internal anchor Pith review arXiv 2024
-
[2]
Gemini: A Family of Highly Capable Multimodal Models
URLhttps://arxiv.org/abs/2312.11805. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 10014–10037, 2023. Jason...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Clipself: Vision trans- former distills itself for open-vocabulary dense prediction
URLhttps://arxiv.org/abs/2310.01403. Weiqi Wu, Xin Guan, Shen Huang, Yong Jiang, Pengjun Xie, Fei Huang, Jiuxin Cao, Hai Zhao, and Jingren Zhou. MaskSearch: A universal pre-training framework to enhance agentic search capability, 2025b. URLhttps://arxiv.org/abs/2505.20285. Guangzhi Xiong, Qiao Jin, Xiao Wang, Yin Fang, Haolin Liu, Yifan Yang, Fangyuan Che...
-
[4]
Initialization with Forced Diversifi- cation
URLhttps://arxiv.org/abs/2505.14069. Qingfei Zhao, Ruobing Wang, Dingling Xu, Daren Zha, and Limin Liu. R-Search: Empow- ering LLM reasoning with search via multi-reward reinforcement learning, 2025a. URL https://arxiv.org/abs/2506.04185. Shu Zhao, Tan Yu, Anbang Xu, Japinder Singh, Aaditya Shukla, and Rama Akkiraju. Paral- lelSearch: Train your LLMs to d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.