Recognition: no theorem link
An Analysis of Artificial Intelligence Adoption in NIH-Funded Research
Pith reviewed 2026-05-10 18:30 UTC · model grok-4.3
The pith
AI accounts for 15.9 percent of NIH projects with a funding premium yet 79 percent stay in research stages and health disparities work is only 5.7 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
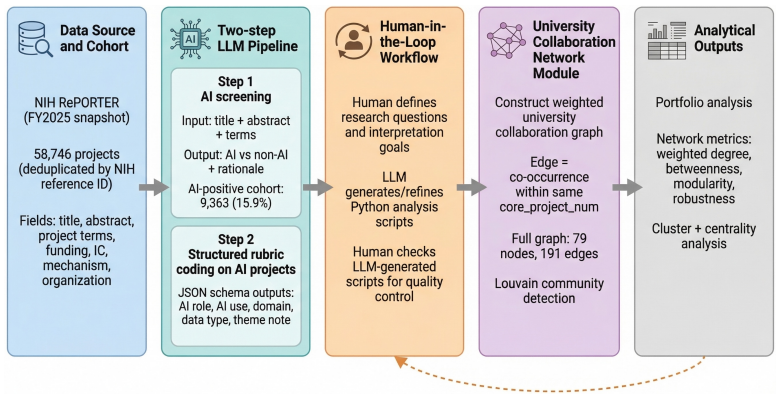
Through systematic classification of 58,746 NIH-funded biomedical projects, the authors establish that AI-related work forms 15.9 percent of the portfolio and receives a 13.4 percent higher average funding amount. This AI portion concentrates on discovery, prediction, and data integration tasks but shows 79 percent of projects still limited to research or development phases, with only 14.7 percent advancing to clinical deployment or implementation. Health disparities content appears in just 5.7 percent of the AI projects, far below the broader NIH emphasis on equity.
What carries the argument
A human-in-the-loop LLM pipeline that classifies unstructured project abstracts for AI relevance, development stage, and health disparities content at scale.
If this is right
- NIH funding decisions could shift toward projects that include explicit plans for clinical deployment to raise the 14.7 percent rate.
- Targeted calls for proposals on health disparities within AI methods would address the current 5.7 percent share.
- Portfolio monitoring tools like the LLM classifier could be run yearly to track whether the research-to-deployment gap narrows.
- Agencies could adjust award sizes or review criteria to favor work that moves beyond prediction models into integrated health systems.
Where Pith is reading between the lines
- The same classification approach could be applied to other federal funders to compare AI adoption rates across agencies.
- Persistent underrepresentation of disparities research may slow progress on equity goals unless future solicitations explicitly require it.
- Longitudinal tracking of the same projects over several years would show whether the current 79 percent research-stage figure improves as technologies mature.
Load-bearing premise
The human-in-the-loop LLM pipeline accurately identifies which projects involve AI, what stage they have reached, and whether they address health disparities without substantial misclassification across the full set of 58,746 records.
What would settle it
A hand-coded review of a random sample of at least 300 projects that finds more than 10 percent error in AI status, development stage labels, or disparities detection would falsify the reported shares.
Figures



read the original abstract
Understanding the landscape of artificial intelligence (AI) and machine learning (ML) adoption across the National Institutes of Health (NIH) portfolio is critical for research funding strategy, institutional planning, and health policy. The advent of large language models (LLMs) has fundamentally transformed research landscape analysis, enabling researchers to perform large-scale semantic extraction from thousands of unstructured research documents. In this paper, we illustrate a human-in-the-loop research methodology for LLMs to automatically classify and summarize research descriptions at scale. Using our methodology, we present a comprehensive analysis of 58,746 NIH-funded biomedical research projects from 2025. We show that: (1) AI constitutes 15.9% of the NIH portfolio with a 13.4% funding premium, concentrated in discovery, prediction, and data integration across disease domains; (2) a critical research-to-deployment gap exists, with 79% of AI projects remaining in research/development stages while only 14.7% engage in clinical deployment or implementation; and (3) health disparities research is severely underrepresented at just 5.7% of AI-funded work despite its importance to NIH's equity mission. These findings establish a framework for evidence-based policy interventions to align the NIH AI portfolio with health equity goals and strategic research priorities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 58,746 NIH-funded biomedical research projects from 2025 using a human-in-the-loop LLM methodology to classify AI-related content in project descriptions. It claims that AI constitutes 15.9% of the NIH portfolio with a 13.4% funding premium, concentrated in discovery, prediction, and data integration; that 79% of AI projects remain in research/development stages while only 14.7% engage in clinical deployment; and that health disparities research is underrepresented at 5.7% of AI-funded work. The work positions these findings as a framework for evidence-based policy interventions to align the NIH AI portfolio with equity goals.
Significance. If the LLM classification can be shown to be reliable, the large-scale empirical mapping of AI adoption, deployment gaps, and equity shortfalls would provide actionable insights for NIH funding strategy and health policy. The human-in-the-loop approach and focus on the full NIH portfolio are strengths that could support reproducible large-scale analyses in the field.
major comments (2)
- Abstract: The central numerical claims (15.9% AI share, 13.4% funding premium, 79% research-stage, 5.7% disparities) are produced by the human-in-the-loop LLM pipeline, yet no validation metrics, inter-rater agreement, held-out human-annotated test set, precision/recall scores, or systematic error analysis are reported. This prevents any assessment of misclassification risk or selection bias in the 58,746-project corpus.
- The description of the LLM pipeline: Without reported definitions of AI keywords, stage labels, or health-disparities criteria, or an error analysis (e.g., domain-specific false positives in imaging versus genomics), the reported breakdowns cannot be bounded for uncertainty and the policy recommendations rest on unverified classifications.
minor comments (1)
- Abstract: The reference to 'projects from 2025' is ambiguous; clarify whether this denotes calendar year, fiscal year, or award date to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback emphasizing the need for validation and transparency in our human-in-the-loop LLM classification approach. We agree these elements are critical for assessing the reliability of our findings on AI adoption in the NIH portfolio and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: The central numerical claims (15.9% AI share, 13.4% funding premium, 79% research-stage, 5.7% disparities) are produced by the human-in-the-loop LLM pipeline, yet no validation metrics, inter-rater agreement, held-out human-annotated test set, precision/recall scores, or systematic error analysis are reported. This prevents any assessment of misclassification risk or selection bias in the 58,746-project corpus.
Authors: We agree that validation metrics are essential to evaluate the reliability of the classifications underlying our central claims. In the revised manuscript, we have added a dedicated Methods subsection on validation that reports inter-rater agreement using a held-out set of human-annotated projects, precision and recall scores for the AI detection task, and a systematic error analysis. These additions allow direct assessment of misclassification risks and potential selection bias in the corpus. revision: yes
-
Referee: The description of the LLM pipeline: Without reported definitions of AI keywords, stage labels, or health-disparities criteria, or an error analysis (e.g., domain-specific false positives in imaging versus genomics), the reported breakdowns cannot be bounded for uncertainty and the policy recommendations rest on unverified classifications.
Authors: We acknowledge that the original manuscript did not provide explicit definitions or a domain-specific error analysis, which limits the ability to bound uncertainty. The revised version now includes appendices with the full list of AI keywords and phrases, detailed rubrics and criteria for stage labels (research/development versus clinical deployment) and health disparities (aligned with NIH equity guidelines), and an expanded error analysis with breakdowns by domain such as imaging and genomics. These changes provide the transparency needed to assess the classifications and support the policy implications. revision: yes
Circularity Check
No circularity: direct empirical classification of external grant corpus
full rationale
The paper describes a one-directional application of a human-in-the-loop LLM pipeline to classify and count features in a fixed corpus of 58,746 NIH grant abstracts. No equations, fitted parameters, or self-referential definitions appear; the reported percentages (15.9% AI share, 79% research-stage, 5.7% disparities) are simple aggregates of the classifier outputs applied to external text. No self-citation chain, ansatz smuggling, or renaming of known results is present. The derivation chain does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models combined with human review can classify unstructured research descriptions into AI-related, stage, and equity categories at scale with acceptable accuracy.
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence in personalized medicine,
E. J. Topol, “Artificial intelligence in personalized medicine,”Nature Medicine, vol. 25, no. 1, pp. 44–56, 2019
2019
-
[2]
Clinically applicable deep learning for image diagnosis,
P. Rajpurkaret al., “Clinically applicable deep learning for image diagnosis,”Nature Medicine, vol. 28, no. 5, pp. 886–894, 2022
2022
-
[3]
Ai and the future of radiology,
K. Heet al., “Ai and the future of radiology,”Radiology, vol. 290, no. 3, pp. 560–570, 2019
2019
-
[4]
Text categorization with support vector machines: Learn- ing with many relevant features,
T. Joachims, “Text categorization with support vector machines: Learn- ing with many relevant features,” inEuropean Conference on Machine Learning, 1998, pp. 137–142
1998
-
[5]
A comparison of event models for naive bayes text classification,
A. McCallum and K. Nigam, “A comparison of event models for naive bayes text classification,” inAAAI-98 Workshop on Learning for Text Categorization, vol. 752, 1998, pp. 41–48
1998
-
[6]
Pubmed 200k rct: a dataset for sequential sentence classification in medical abstracts,
F. Dernoncourt and J. Y . Lee, “Pubmed 200k rct: a dataset for sequential sentence classification in medical abstracts,” inProceedings of the Eighth International Joint Conference on Natural Language Processing, 2017, pp. 308–313
2017
-
[7]
Automatic semantic classification of scientific literature according to the hallmarks of cancer,
S. Baker, I. Silins, Y . Guo, I. Ali, J. H ¨ogberg, U. Stenius, and A. Korho- nen, “Automatic semantic classification of scientific literature according to the hallmarks of cancer,”Bioinformatics, vol. 32, no. 3, pp. 432–440, 2015
2015
-
[8]
Lit Covid: an open database of COVID-19 literature,
Q. Chen, A. Allot, and Z. Lu, “Lit Covid: an open database of COVID-19 literature,”Nucleic Acids Research, vol. 49, no. D1, pp. D1534–D1540, 2020
2020
-
[9]
National institutes of health office of data science strategy,
National Institutes of Health, “National institutes of health office of data science strategy,”NIH Strategic Plan, 2018
2018
-
[10]
Aim-ahead: Artificial intelligence/machine learning consortium to advance health equity and develop workforce diversity,
NIH Division of Program Coordination, Planning, and Strategic Initia- tives, “Aim-ahead: Artificial intelligence/machine learning consortium to advance health equity and develop workforce diversity,”NIH Funding Opportunity, 2021
2021
-
[11]
Executive order on advancing racial equity and support for underserved communities,
White House, “Executive order on advancing racial equity and support for underserved communities,”Federal Register, 2021
2021
-
[12]
FAST: a framework to assess speed of translation of health innovations to practice and policy,
E. Proctor, A. T. Ramsey, L. Saldana, T. M. Maddox, D. A. Chambers, and R. C. Brownson, “FAST: a framework to assess speed of translation of health innovations to practice and policy,”Global Implementation Research and Applications, vol. 2, pp. 107–119, 2022
2022
-
[13]
Welcome to implementation science com- munications,
R. Armstrong and A. Sales, “Welcome to implementation science com- munications,”Implementation Science Communications, vol. 1, no. 1, p. 1, 2020
2020
-
[14]
Quantifying large language model usage in scientific papers,
W. Lianget al., “Quantifying large language model usage in scientific papers,”Nature Human Behaviour, pp. 1–11, 2025
2025
-
[15]
Scientific production in the era of large language models,
K. Kusumegiet al., “Scientific production in the era of large language models,”Science, vol. 390, pp. 1240–1243, 2025
2025
-
[16]
Language Models are Few-Shot Learners
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,” arXiv preprint arXiv:2005.14165, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[17]
PaLM: Scal- ing language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmannet al., “PaLM: Scal- ing language modeling with pathways,”Journal of Machine Learning Research, vol. 24, no. 240, pp. 1–113, 2023
2023
-
[18]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “LLaMA: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Generative AI enhances individual creativity but reduces the collective diversity of novel content,
A. R. Doshi and O. P. Hauser, “Generative AI enhances individual creativity but reduces the collective diversity of novel content,”Science Advances, vol. 10, p. eadn5290, 2024
2024
-
[20]
Quantifying the use and potential benefits of artificial intelligence in scientific research,
J. Gao and D. Wang, “Quantifying the use and potential benefits of artificial intelligence in scientific research,”Nature Human Behaviour, vol. 8, pp. 2281–2292, 2024
2024
-
[21]
Artificial intelligence tools expand scientists’ impact but contract science’s focus,
Q. Hao, F. Xu, Y . Li, and J. Evans, “Artificial intelligence tools expand scientists’ impact but contract science’s focus,”Nature, pp. 1–7, 2026
2026
-
[22]
SciFive: a text-to-text transformer model for biomedical literature,
L. N. Phan, J. T. Anibal, H. Tran, S. Chanana, E. Bahadroglu, A. Pel- tekian, and G. Altan-Bonnet, “SciFive: a text-to-text transformer model for biomedical literature,” arXiv preprint arXiv:2106.03598, 2021
-
[23]
A comparative study of large language model-based zero-shot inference and task-specific supervised classifi- cation of breast cancer pathology reports,
M. Sushil, T. Zack, D. Mandair, Z. Zheng, A. Wali, Y . Yu, Y . Quan, D. Lituiev, and A. J. Butte, “A comparative study of large language model-based zero-shot inference and task-specific supervised classifi- cation of breast cancer pathology reports,”Journal of the American Medical Informatics Association, p. ocae146, 2024
2024
-
[24]
A comparison of ChatGPT and fine-tuned Open Pre-Trained Transformers (OPT) against widely used sentiment analysis tools: Sentiment analysis of COVID-19 survey data,
J. A. Lossio-Ventura, R. Weger, A. Y . Lee, E. P. Guinee, J. Chung, L. Atlas, E. Linos, and F. Pereira, “A comparison of ChatGPT and fine-tuned Open Pre-Trained Transformers (OPT) against widely used sentiment analysis tools: Sentiment analysis of COVID-19 survey data,” JMIR Mental Health, vol. 11, p. e50150, 2024
2024
-
[25]
Promotional language and the adoption of innovative ideas in science,
H. Peng, H. S. Qiu, H. B. Fosse, and B. Uzzi, “Promotional language and the adoption of innovative ideas in science,”Proceedings of the National Academy of Sciences, vol. 121, p. e2320066121, 2024
2024
-
[26]
The burden of knowledge and the “death of the renaissance man
B. F. Jones, “The burden of knowledge and the “death of the renaissance man”: Is innovation getting harder?”The Review of Economic Studies, vol. 76, pp. 283–317, 2009
2009
-
[27]
Advancing rapid cycle research in cancer care delivery: a National Cancer Institute workshop report,
W. E. Norton, A. E. Kennedy, B. S. Mittman, G. Parry, S. Srinivasan, E. Tonorezoset al., “Advancing rapid cycle research in cancer care delivery: a National Cancer Institute workshop report,”Journal of the National Cancer Institute, vol. 115, pp. 498–504, 2023
2023
-
[28]
Implementation science should give higher priority to health equity,
R. C. Brownson, S. K. Kumanyika, M. W. Kreuter, and D. Haire-Joshu, “Implementation science should give higher priority to health equity,” Implementation Science, vol. 16, 2021
2021
-
[29]
The automation of bias in medical Artificial Intelligence (AI): Decoding the past to create a better future,
I. Straw, “The automation of bias in medical Artificial Intelligence (AI): Decoding the past to create a better future,”Artificial Intelligence in Medicine, vol. 110, 2020
2020
-
[30]
Machine learning in medicine: addressing ethical challenges,
E. Vayena, A. Blasimme, and I. G. Cohen, “Machine learning in medicine: addressing ethical challenges,”PLOS Medicine, vol. 15, no. 11, p. e1002689, 2018
2018
-
[31]
Dissecting racial bias in an algorithm used to manage the health of populations,
Z. Obermeyer, B. Powers, C. V ogeli, and S. Mullainathan, “Dissecting racial bias in an algorithm used to manage the health of populations,” Science, vol. 366, no. 6464, pp. 447–453, 2019
2019
-
[32]
Applying an equity lens to assess context and implementation in public health and health services research and practice using the PRISM framework,
M. P. Fort, S. M. Manson, and R. E. Glasgow, “Applying an equity lens to assess context and implementation in public health and health services research and practice using the PRISM framework,”Frontiers in Health Services, vol. 3, p. 31, 2023
2023
-
[33]
An extension of RE-AIM to enhance sustainability: addressing dynamic context and promoting health equity over time,
R. C. Shelton, D. A. Chambers, and R. E. Glasgow, “An extension of RE-AIM to enhance sustainability: addressing dynamic context and promoting health equity over time,”Frontiers in Public Health, vol. 8, 2020
2020
-
[34]
AI can be sexist and racist—it’s time to make it fair,
J. Zou and L. Schiebinger, “AI can be sexist and racist—it’s time to make it fair,”Nature, vol. 559, pp. 324–326, 2018
2018
-
[35]
EU Artificial Intelligence Act: first regulation on artificial intelligence,
European Parliament, “EU Artificial Intelligence Act: first regulation on artificial intelligence,” News — European Parliament, 2023
2023
-
[36]
Implementation frameworks for artificial intelligence translation into health care practice: scoping review,
F. Gama, D. Tyskbo, J. Nygren, J. Barlow, J. Reed, and P. Svedberg, “Implementation frameworks for artificial intelligence translation into health care practice: scoping review,”Journal of Medical Internet Research, vol. 24, 2022
2022
-
[37]
A comparison of two learning algo- rithms for text categorization,
D. D. Lewis and M. Ringuette, “A comparison of two learning algo- rithms for text categorization,” inThird Annual Symposium on Document Analysis and Information Retrieval, vol. 33, 1994, pp. 81–93
1994
-
[38]
Automatic diag- nosis coding of radiology reports: a comparison of deep learning and conventional classification methods,
S. Karimi, X. Dai, H. Hassanzadeh, and A. Nguyen, “Automatic diag- nosis coding of radiology reports: a comparison of deep learning and conventional classification methods,” inBioNLP 2017, 2017, pp. 328– 332
2017
-
[39]
Text classification to inform suicide risk assessment in electronic health records,
A. Bittar, S. Velupillai, A. Roberts, and R. Dutta, “Text classification to inform suicide risk assessment in electronic health records,” in MEDINFO 2019: Health and Wellbeing e-Networks for All, 2019, pp. 40–44
2019
-
[40]
Evaluating the effect of unbalanced data in biomedical document classification,
R. Laza, R. Pav ´on, M. Reboiro-Jato, and F. Fdez-Riverola, “Evaluating the effect of unbalanced data in biomedical document classification,” Journal of Integrative Bioinformatics, vol. 8, no. 3, pp. 105–117, 2011
2011
-
[41]
Applying machine-learning to rapidly analyse large qualitative text datasets to inform the COVID-19 pandemic response,
L. Towler, P. Bondaronek, T. Papakonstantinouet al., “Applying machine-learning to rapidly analyse large qualitative text datasets to inform the COVID-19 pandemic response,” 2022
2022
-
[42]
Solidarity and strife after the Atlanta spa shootings: A mixed methods study characterizing Twitter discussions by qualitative analysis and machine learning,
S. Criss, T. T. Nguyen, E. K. Michaelset al., “Solidarity and strife after the Atlanta spa shootings: A mixed methods study characterizing Twitter discussions by qualitative analysis and machine learning,”Frontiers in Public Health, vol. 11, 2023
2023
-
[43]
Experiences of siblings of children with neurodevelopmental disorders: comparing qualitative analysis and machine learning to study narratives,
J. A. J. Bastiaansen, E. E. Veldhuizen, K. De Schepper, and F. E. Scheepers, “Experiences of siblings of children with neurodevelopmental disorders: comparing qualitative analysis and machine learning to study narratives,”Frontiers in Psychiatry, vol. 13, 2022
2022
-
[44]
Assessing the heterogeneity of complaints related to tinnitus and hyperacusis from an unsupervised machine learning approach,
G. Palacios, A. Norena, and A. Londero, “Assessing the heterogeneity of complaints related to tinnitus and hyperacusis from an unsupervised machine learning approach,”Audiology and Neuro-Otology, vol. 25, 2020
2020
-
[45]
On-the-go adaptation of im- plementation approaches and strategies in health: emerging perspectives and research opportunities,
E. H. Geng, A. Mody, and B. J. Powell, “On-the-go adaptation of im- plementation approaches and strategies in health: emerging perspectives and research opportunities,”Annual Review of Public Health, vol. 44, pp. 21–36, 2023
2023
-
[46]
A protocol for a living mapping review of global research funding for infectious diseases with a pandemic potential — pandemic pact,
O. Seminog, R. Furst, T. Mendyet al., “A protocol for a living mapping review of global research funding for infectious diseases with a pandemic potential — pandemic pact,”Wellcome Open Research, vol. 9, p. 156, 2024
2024
-
[47]
Preventing the next pandemic: the power of a global viral surveillance network,
D. Carroll, S. Morzaria, S. Briand, C. K. Johnson, D. Morens, K. Sump- tion, O. Tomori, and S. Wacharphaueasadee, “Preventing the next pandemic: the power of a global viral surveillance network,”BMJ, vol. 372, 2021
2021
-
[48]
Deep learning in medical imaging and radiation therapy,
B. Sahiner, A. Pezeshk, V . Hadjiiski, X. Wang, K. Drukker, K. Cha, A. Summers, and M. Giger, “Deep learning in medical imaging and radiation therapy,”Medical Physics, vol. 46, no. 1, pp. e1–e36, 2019
2019
-
[49]
Artificial intelligence in cardiovascular disease: Current progress and future opportunities,
J. Qian, V . P. Singh, A. K. Nallamshettyet al., “Artificial intelligence in cardiovascular disease: Current progress and future opportunities,” JACC: Cardiovascular Imaging, vol. 15, no. 1, pp. 1–18, 2022
2022
-
[50]
Artificial intelligence in health,
Nature Editorial, “Artificial intelligence in health,”Nature Medicine, vol. 29, no. 1, 2023
2023
-
[51]
Implementation science in digital health: Lessons and emerging opportunities,
W. Amick and T. T. Liang, “Implementation science in digital health: Lessons and emerging opportunities,”Journal of General Internal Medicine, vol. 37, no. 9, pp. 2231–2239, 2022
2022
-
[52]
Workforce development in digital health: Creating the pipeline for tomorrow’s leaders,
K. Kaur, N. Ramphal, P. Stormo, and E. Marques-Baptista, “Workforce development in digital health: Creating the pipeline for tomorrow’s leaders,”Journal of Digital Imaging, vol. 34, no. 3, pp. 542–549, 2021
2021
-
[53]
Building a better biomedical data scientist,
L. E. Beaulieu-Jones, S. Finlayson, R. Kagalwalaet al., “Building a better biomedical data scientist,”Academic Medicine, vol. 95, no. 4, pp. 515–518, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.