Recognition: unknown
CMP: Robust Whole-Body Tracking for Loco-Manipulation via Competence Manifold Projection
Pith reviewed 2026-05-10 17:27 UTC · model grok-4.3
The pith
Competence Manifold Projection confines robot commands to a learned safety manifold to prevent failures in whole-body loco-manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
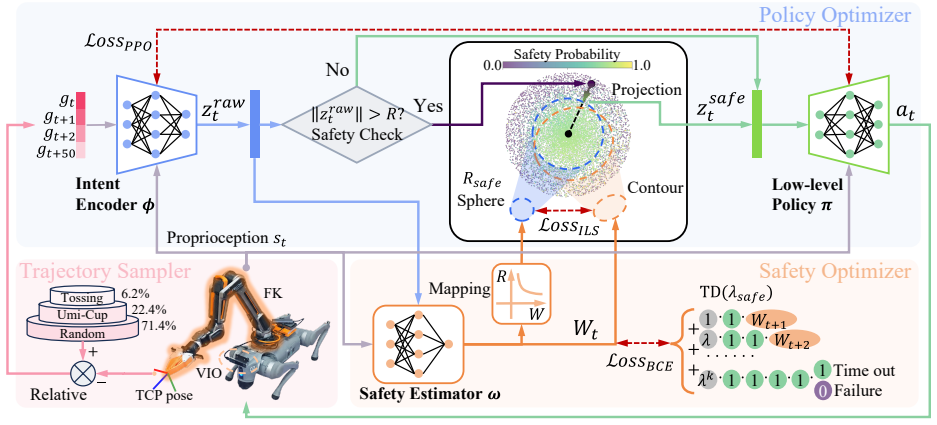
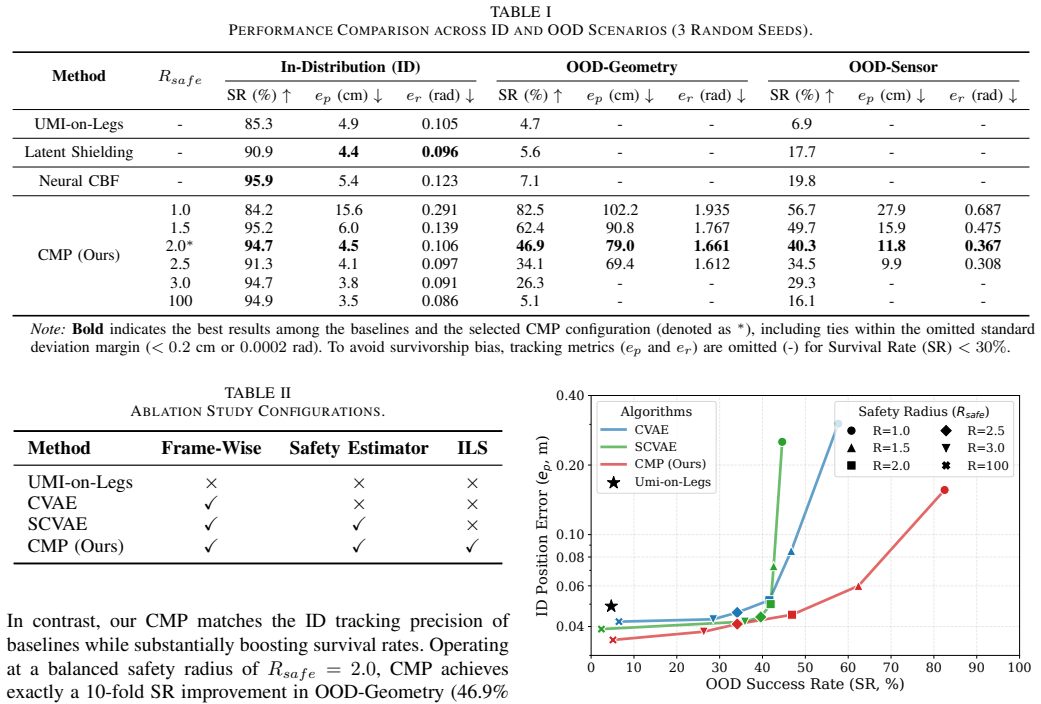
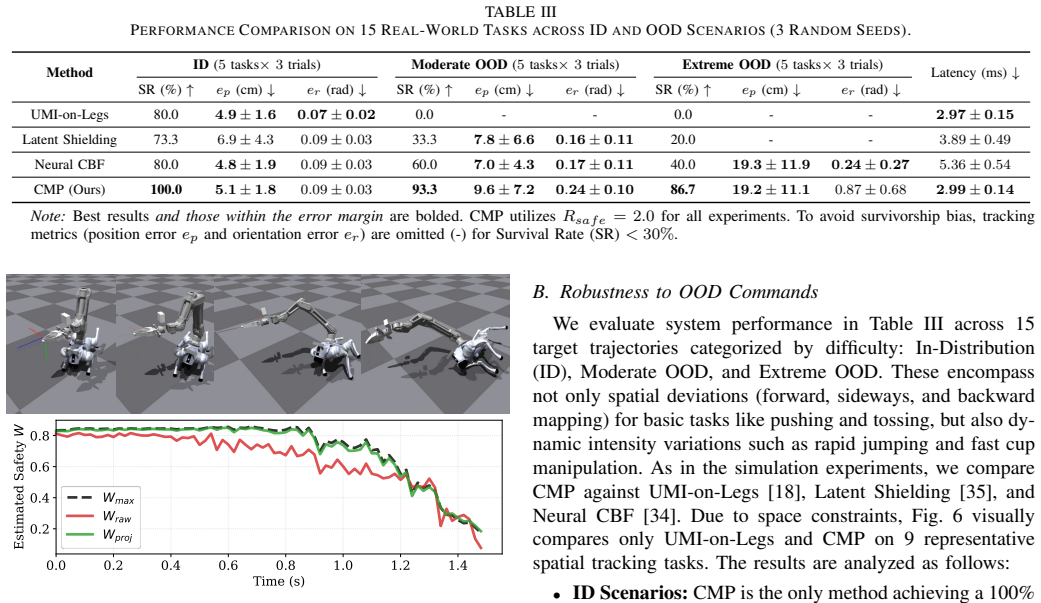
CMP instantiates a competence manifold through a Frame-Wise Safety Scheme, a Lower-Bounded Safety Estimator that flags intentions outside the training distribution, and an Isomorphic Latent Space that aligns geometry with safety probability, enabling O(1) projection of arbitrary OOD inputs; experiments show this yields up to a 10-fold survival rate improvement over baselines that suffer catastrophic failure, with tracking degradation remaining under 10 percent and emergent best-effort generalization to partially complete OOD goals.
What carries the argument
The Competence Manifold Projection, which maps inputs onto a manifold whose geometry is aligned with safety probability via the Isomorphic Latent Space and the Lower-Bounded Safety Estimator.
Load-bearing premise
The Lower-Bounded Safety Estimator reliably identifies intentions outside the training distribution and the Isomorphic Latent Space correctly aligns manifold geometry with safety probability for any OOD input.
What would settle it
A controlled test that feeds the trained system a sequence of deliberately extreme OOD commands or sensor noise levels not represented in training and records whether survival rates remain near the reported 10-fold gain or fall back to baseline failure levels.
Figures





read the original abstract
While decoupled control schemes for legged mobile manipulators have shown robustness, learning holistic whole-body control policies for tracking global end-effector poses remains fragile against Out-of-Distribution (OOD) inputs induced by sensor noise or infeasible user commands. To improve robustness against these perturbations without sacrificing task performance and continuity, we propose Competence Manifold Projection (CMP). Specifically, we utilize a Frame-Wise Safety Scheme that transforms the infinite-horizon safety constraint into a computationally efficient single-step manifold inclusion. To instantiate this competence manifold, we employ a Lower-Bounded Safety Estimator that distinguishes unmastered intentions from the training distribution. We then introduce an Isomorphic Latent Space (ILS) that aligns manifold geometry with safety probability, enabling efficient O(1) seamless defense against arbitrary OOD intents. Experiments demonstrate that CMP achieves up to a 10-fold survival rate improvement in typical OOD scenarios where baselines suffer catastrophic failure, incurring under 10% tracking degradation. Notably, the system exhibits emergent ``best-effort'' generalization behaviors to progressively accomplish OOD goals by adhering to the competence boundaries. Result videos are available at: https://shepherd1226.github.io/CMP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Competence Manifold Projection (CMP) for robust whole-body tracking in legged mobile manipulators. It introduces a Frame-Wise Safety Scheme that reduces infinite-horizon safety constraints to single-step manifold inclusion, a Lower-Bounded Safety Estimator trained to distinguish unmastered intentions from the training distribution, and an Isomorphic Latent Space (ILS) that aligns manifold geometry with safety probabilities to enable O(1) projection against arbitrary OOD inputs such as sensor noise or infeasible commands. Experiments report up to 10-fold gains in survival rate in typical OOD regimes while incurring under 10% tracking degradation, with emergent best-effort generalization to progressively accomplish goals within competence boundaries.
Significance. If the reported gains hold under the described experimental conditions, CMP offers a practical advance in safe loco-manipulation by providing an explicit, computationally efficient mechanism to project actions onto a competence manifold without sacrificing continuity or task performance. The combination of lower-bounded safety estimation and distance-preserving latent-space alignment addresses a key fragility in learned whole-body policies and could support more reliable deployment in unstructured environments.
minor comments (2)
- Abstract: quantitative claims (10-fold survival, <10% degradation) are stated without reference to specific baselines, number of trials, or statistical tests; these details appear in the full experimental section but should be summarized briefly in the abstract for clarity.
- Notation: the mapping from safety probability to manifold boundary in the ILS construction should include an explicit equation or pseudocode block to make the O(1) projection step immediately reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review, as well as the recommendation for minor revision. The referee's summary accurately reflects the core contributions of Competence Manifold Projection (CMP), including the Frame-Wise Safety Scheme, Lower-Bounded Safety Estimator, and Isomorphic Latent Space. We are pleased that the reported gains in survival rate and the emergent best-effort generalization behavior were recognized as a practical advance for safe loco-manipulation.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines CMP through explicit constructions: a Frame-Wise Safety Scheme that converts infinite-horizon constraints to single-step manifold inclusion, a Lower-Bounded Safety Estimator trained with explicit probability bounds, and an Isomorphic Latent Space built via an explicit isomorphism preserving distance-to-boundary ordering. These steps are supported by stated training procedures and experimental validation on multiple OOD regimes (sensor noise, infeasible commands) with direct metrics on survival and tracking degradation. No equation or claim reduces a prediction to a fitted quantity defined by the same data, nor does any load-bearing premise collapse to a self-citation chain. The central 10-fold survival claim is empirical and externally falsifiable against baselines, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress
Christopher Agia, Rohan Sinha, Jingyun Yang, Zi-ang Cao, Rika Antonova, Marco Pavone, and Jeannette Bohg. Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress. InConference on Robot Learning (CoRL), 2024
2024
-
[2]
Is conditional generative modeling all you need for decision-making? InInternational Conference on Learning Representa- tions (ICLR), 2023
Anurag Ajay, Yilun Du, Abhi Gupta, Joshua Tenenbaum, Tommi Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision-making? InInternational Conference on Learning Representa- tions (ICLR), 2023
2023
-
[3]
Control barrier functions: Theory and applications
Aaron D Ames, Samuel Coogan, Magnus Egerstedt, Gen- naro Notomista, Koushil Sreenath, and Paulo Tabuada. Control barrier functions: Theory and applications. In 2019 18th European control conference (ECC), pages 3420–3431, 2019
2019
-
[4]
Hamilton-jacobi reachability: A brief overview and recent advances
Somil Bansal, Mo Chen, Sylvia Herbert, and Claire J Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In2017 IEEE 56th Annual Confer- ence on Decision and Control (CDC), pages 2242–2253, 2017
2017
-
[5]
Dario Bellicoso, Koen Kr ¨amer, Markus St¨auble, Dhio- nis Sako, Fabian Jenelten, Marko Bjelonic, and Marco Hutter
C. Dario Bellicoso, Koen Kr ¨amer, Markus St¨auble, Dhio- nis Sako, Fabian Jenelten, Marko Bjelonic, and Marco Hutter. Alma - articulated locomotion and manipulation for a torque-controllable robot. In2019 International Conference on Robotics and Automation (ICRA), pages 8477–8483, 2019
2019
-
[6]
Geometry- aware predictive safety filters on humanoids: From pois- son safety functions to cbf constrained mpc
Ryan M Bena, Gilbert Bahati, Blake Werner, Ryan K Cosner, Lizhi Yang, and Aaron D Ames. Geometry- aware predictive safety filters on humanoids: From pois- son safety functions to cbf constrained mpc. In2025 IEEE-RAS 24th International Conference on Humanoid Robots (Humanoids), pages 1–8, 2025
2025
-
[7]
Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5(1):411– 444, 2022
Lukas Brunke, Melissa Greeff, Adam W Hall, Zhao- cong Yuan, Siqi Zhou, Jacopo Panerati, and Angela P Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5(1):411– 444, 2022
2022
-
[8]
Perceptive whole-body planning for multilegged robots in confined spaces.Journal of Field Robotics, 38 (1):68–84, 2021
Russell Buchanan, Lorenz Wellhausen, Marko Bjelonic, Tirthankar Bandyopadhyay, Navinda Kottege, and Marco Hutter. Perceptive whole-body planning for multilegged robots in confined spaces.Journal of Field Robotics, 38 (1):68–84, 2021
2021
-
[9]
End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks
Richard Cheng, G ´abor Orosz, Richard M Murray, and Joel W Burdick. End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 3387–3395, 2019
2019
-
[10]
Universal manipulation interface: In- the-wild robot teaching without in-the-wild robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal manipulation interface: In- the-wild robot teaching without in-the-wild robots. In Proceedings of Robotics: Science and Systems, 2024
2024
-
[11]
Safe exploration in continuous action spaces,
Gal Dalal, Krishnamurthy Dvijotham, Matej Vecerik, Todd Hester, Cosmin Paduraru, and Yuval Tassa. Safe exploration in continuous action spaces.arXiv preprint arXiv:1801.08757, 2018
-
[12]
Aha: A vision- language-model for detecting and reasoning over failures in robotic manipulation
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. Aha: A vision- language-model for detecting and reasoning over failures in robotic manipulation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[13]
Robust autonomous navigation of a small-scale quadruped robot in real-world environments
Thomas Dudzik, Matthew Chignoli, Gerardo Bledt, Bryan Lim, Adam Miller, Donghyun Kim, and Sangbae Kim. Robust autonomous navigation of a small-scale quadruped robot in real-world environments. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3664–3671, 2020
2020
-
[14]
Safe reinforcement learning using robust control barrier functions.IEEE Robotics and Automation Letters, 2022
Yousef Emam, Gennaro Notomista, Paul Glotfelter, Zsolt Kira, and Magnus Egerstedt. Safe reinforcement learning using robust control barrier functions.IEEE Robotics and Automation Letters, 2022
2022
-
[15]
Deep whole-body control: Learning a unified policy for ma- nipulation and locomotion
Zipeng Fu, Xuxin Cheng, and Deepak Pathak. Deep whole-body control: Learning a unified policy for ma- nipulation and locomotion. InProceedings of the 6th Conference on Robot Learning, volume 205, pages 138– 149, 2023
2023
-
[16]
Milan Ganai, Rohan Sinha, Christopher Agia, Daniel Morton, Luigi Di Lillo, and Marco Pavone. Real-time out-of-distribution failure prevention via multi-modal reasoning.arXiv preprint arXiv:2505.10547, 2025
-
[17]
Humanoid-Gym: Reinforcement learning for humanoid robot with zero-shot sim2real transfer,
Xinyang Gu, Yen-Jen Wang, and Jianyu Chen. Humanoid-gym: Reinforcement learning for humanoid robot with zero-shot sim2real transfer.arXiv preprint arXiv:2404.05695, 2024
-
[18]
Umi-on-legs: Making manipulation policies mo- bile with manipulation-centric whole-body controllers
Huy Ha, Yihuai Gao, Zipeng Fu, Jie Tan, and Shuran Song. Umi-on-legs: Making manipulation policies mo- bile with manipulation-centric whole-body controllers. In Proceedings of the 8th Conference on Robot Learning, volume 270, pages 5254–5270, 2024
2024
-
[19]
Rediffuser: Reliable decision-making using a diffuser with confidence estimation
Nantian He, Shaohui Li, Zhi Li, Yu Liu, and You He. Rediffuser: Reliable decision-making using a diffuser with confidence estimation. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[20]
Learning a state representation and navigation in cluttered and dynamic environments.IEEE Robotics and Automation Letters, 6(3):5081–5088, 2021
David Hoeller, Lorenz Wellhausen, Farbod Farshidian, and Marco Hutter. Learning a state representation and navigation in cluttered and dynamic environments.IEEE Robotics and Automation Letters, 6(3):5081–5088, 2021
2021
-
[21]
Tomlin, and Jaime F
Kai-Chieh Hsu, Vicenc ¸ R ´ubies Royo, Claire J. Tomlin, and Jaime F. Fisac. Safety and liveness guarantees through reach-avoid reinforcement learning. InRobotics: Science and Systems XVII, 2021
2021
-
[22]
HoST: Learning humanoid standing-up control across diverse postures,
Tao Huang, Junli Ren, Huayi Wang, Zirui Wang, Qingwei Ben, Muning Wen, Xiao Chen, Jianan Li, and Jiangmiao Pang. Learning humanoid standing- up control across diverse postures.arXiv preprint arXiv:2502.08378, 2025
-
[23]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review arXiv 2022
-
[24]
Kaiwen Jiang, Zhen Fu, Junde Guo, Wei Zhang, and Hua Chen. Learning whole-body loco-manipulation for omni-directional task space pose tracking with a wheeled-quadrupedal-manipulator.IEEE Robotics and Automation Letters, 10(2):1481–1488, 2025
2025
-
[25]
PhD thesis, Georgia Institute of Technology, 2021
Visak Kumar.Learning Control Policies for Fall pre- vention and safety in bipedal locomotion. PhD thesis, Georgia Institute of Technology, 2021
2021
-
[26]
Learning quadrupedal locomotion over challenging terrain.Science robotics, 5 (47):eabc5986, 2020
Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning quadrupedal locomotion over challenging terrain.Science robotics, 5 (47):eabc5986, 2020
2020
-
[27]
Visual whole-body control for legged loco-manipulation
Minghuan Liu, Zixuan Chen, Xuxin Cheng, Yandong Ji, Rizhao Qiu, Ruihan Yang, and Xiaolong Wang. Visual whole-body control for legged loco-manipulation. In Proceedings of the 8th Conference on Robot Learning, 2024
2024
-
[28]
Mlm: Learning multi-task loco- manipulation whole-body control for quadruped robot with arm.IEEE Robotics and Automation Letters, 11 (1):81–88, 2025
Xin Liu, Bida Ma, Chenkun Qi, Yan Ding, Nuo Xu, Guorong Zhang, Pengan Chen, Kehui Liu, Zhongjie Jia, Chuyue Guan, et al. Mlm: Learning multi-task loco- manipulation whole-body control for quadruped robot with arm.IEEE Robotics and Automation Letters, 11 (1):81–88, 2025
2025
-
[29]
arXiv preprint arXiv:2406.01586 (2024)
Guanxing Lu, Zifeng Gao, Tianxing Chen, Wenxun Dai, Ziwei Wang, Wenbo Ding, and Yansong Tang. Manicm: Real-time 3d diffusion policy via consistency model for robotic manipulation.arXiv preprint arXiv:2406.01586, 2024
-
[30]
Combining learning-based loco- motion policy with model-based manipulation for legged mobile manipulators.IEEE Robotics and Automation Letters, 7(2):2377–2384, 2022
Yuntao Ma, Farbod Farshidian, Takahiro Miki, Joonho Lee, and Marco Hutter. Combining learning-based loco- motion policy with model-based manipulation for legged mobile manipulators.IEEE Robotics and Automation Letters, 7(2):2377–2384, 2022
2022
-
[31]
Learn- ing arm-assisted fall damage reduction and recovery for legged mobile manipulators
Yuntao Ma, Farbod Farshidian, and Marco Hutter. Learn- ing arm-assisted fall damage reduction and recovery for legged mobile manipulators. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 12149–12155, 2023
2023
-
[32]
Isaac gym: High performance gpu based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu based physics simulation for robot learning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[33]
SafeFall: Learning protective control for humanoid robots,
Ziyu Meng, Tengyu Liu, Le Ma, Yingying Wu, Ran Song, Wei Zhang, and Siyuan Huang. Safefall: Learning protective control for humanoid robots.arXiv preprint arXiv:2511.18509, 2025
-
[34]
Kensuke Nakamura, Arun L Bishop, Steven Man, Aaron M Johnson, Zachary Manchester, and Andrea Bajcsy. How to train your latent control barrier function: Smooth safety filtering under hard-to-model constraints. arXiv preprint arXiv:2511.18606, 2025
-
[35]
Generalizing safety beyond collision-avoidance via latent-space reachability analysis,
Kensuke Nakamura, Lasse Peters, and Andrea Ba- jcsy. Generalizing safety beyond collision-avoidance via latent-space reachability analysis.arXiv preprint arXiv:2502.00935, 2025
-
[36]
Roboduet: Learning a cooperative policy for whole-body legged loco-manipulation.IEEE Robotics and Automation Letters, 2025
Guoping Pan, Qingwei Ben, Zhecheng Yuan, Guangqi Jiang, Yandong Ji, Shoujie Li, Jiangmiao Pang, Houde Liu, and Huazhe Xu. Roboduet: Learning a cooperative policy for whole-body legged loco-manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[37]
Strengthening Generative Robot Policies through Predictive World Modeling, May 2025
Han Qi, Haocheng Yin, Yilun Du, and Heng Yang. Strengthening generative robot policies through predic- tive world modeling.arXiv preprint arXiv:2502.00622, 2025
-
[38]
Benchmarking safe exploration in deep reinforcement learning,
Alex Ray, Joshua Achiam, and Dario Amodei. Bench- marking safe exploration in deep reinforcement learning. arXiv preprint arXiv:1910.01708, 7(1):2, 2019
- [39]
-
[40]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the four- teenth international conference on artificial intelligence and statistics, pages 627–635, 2011
2011
-
[41]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Versatile multicontact planning and control for legged loco-manipulation.Science Robotics, 8(81):eadg5014, 2023
Jean-Pierre Sleiman, Farbod Farshidian, and Marco Hut- ter. Versatile multicontact planning and control for legged loco-manipulation.Science Robotics, 8(81):eadg5014, 2023
2023
-
[43]
Learning structured output representation using deep conditional generative models
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 28
- [44]
-
[45]
Force-constrained visual policy: Safe robot- assisted dressing via multi-modal sensing.IEEE Robotics and Automation Letters, 2024
Zhanyi Sun, Yufei Wang, David Held, and Zackory Erickson. Force-constrained visual policy: Safe robot- assisted dressing via multi-modal sensing.IEEE Robotics and Automation Letters, 2024
2024
-
[46]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cambridge, Massachusetts, second edition, 2018
2018
-
[47]
Reward Constrained Policy Optimization
Chen Tessler, Daniel J Mankowitz, and Shie Mannor. Reward constrained policy optimization.arXiv preprint arXiv:1805.11074, 2018
work page Pith review arXiv 2018
-
[48]
Recovery RL: Safe reinforcement learning with learned recovery zones.IEEE Robotics and Au- tomation Letters, 6(3):4915–4922, 2021
Brijen Thananjeyan, Ashwin Balakrishna, Suraj Nair, Michael Luo, Krishnan Srinivasan, Minho Hwang, Joseph E Gonzalez, Julian Ibarz, Chelsea Finn, and Ken Goldberg. Recovery RL: Safe reinforcement learning with learned recovery zones.IEEE Robotics and Au- tomation Letters, 6(3):4915–4922, 2021
2021
-
[49]
Zifan Wang, Xun Yang, Jianzhuang Zhao, Jiaming Zhou, Teli Ma, Ziyao Gao, Arash Ajoudani, and Junwei Liang. End-to-end humanoid robot safe and comfortable loco- motion policy.arXiv preprint arXiv:2508.07611, 2025
-
[50]
Closed-loop diffusion control of complex physical systems.arXiv preprint arXiv:2408.03124, 2024
Long Wei, Haodong Feng, Peiyan Hu, Tao Zhang, Yuchen Yang, Xiang Zheng, Ruiqi Feng, Dixia Fan, and Tailin Wu. Closed-loop diffusion control of complex physical systems.arXiv preprint arXiv:2408.03124, 2024
-
[51]
Wenpeng Xing, Minghao Li, Mohan Li, and Meng Han. Towards robust and secure embodied ai: A survey on vulnerabilities and attacks.arXiv preprint arXiv:2502.13175, 2025
-
[52]
Can we detect failures without failure data? Uncertainty- aware runtime failure detection for imitation learning policies
Chen Xu, Tony Khuong Nguyen, Emma Dixon, Christo- pher Rodriguez, Patrick Miller, Robert Lee, Paarth Shah, Rares Ambrus, Haruki Nishimura, and Masha Itkina. Can we detect failures without failure data? Uncertainty- aware runtime failure detection for imitation learning policies. InRobotics: Science and Systems (RSS), 2025
2025
-
[53]
Multi-expert learning of adaptive legged locomotion.Science Robotics, 5(49):eabb2174, 2020
Chuanyu Yang, Kai Yuan, Qiuguo Zhu, Wanming Yu, and Zhibin Li. Multi-expert learning of adaptive legged locomotion.Science Robotics, 5(49):eabb2174, 2020
2020
-
[54]
Lizhi Yang, Blake Werner, Ryan K Cosner, David Fridovich-Keil, Preston Culbertson, and Aaron D Ames. Shield: Safety on humanoids via cbfs in expectation on learned dynamics.arXiv preprint arXiv:2505.11494, 2025
-
[55]
Asc: Adaptive skill coordination for robotic mobile manipulation.IEEE Robotics and Automation Letters, 9(1):779–786, 2024
Naoki Yokoyama, Alex Clegg, Joanne Truong, Eric Un- dersander, Tsung-Yen Yang, Sergio Arnaud, Sehoon Ha, Dhruv Batra, and Akshara Rai. Asc: Adaptive skill coordination for robotic mobile manipulation.IEEE Robotics and Automation Letters, 9(1):779–786, 2024
2024
-
[56]
Heng Zhang, Rui Dai, Gokhan Solak, Pokuang Zhou, Yu She, and Arash Ajoudani. Safe learning for contact- rich robot tasks: A survey from classical learning-based methods to safe foundation models.arXiv preprint arXiv:2512.11908, 2025
-
[57]
Zhaxizhuoma, Kehui Liu, Chuyue Guan, Zhongjie Jia, Ziniu Wu, Xin Liu, Tianyu Wang, Shuai Liang, Pen- gan Chen, Pingrui Zhang, Haoming Song, Delin Qu, Dong Wang, Zhigang Wang, Nieqing Cao, Yan Ding, Bin Zhao, and Xuelong Li. Fastumi: A scalable and hardware-independent universal manipulation interface with dataset.arXiv preprint arXiv:2409.19499, 2025
-
[58]
Guangyao Zhou, Sivaramakrishnan Swaminathan, Rajku- mar Vasudeva Raju, J Swaroop Guntupalli, Wolfgang Lehrach, Joseph Ortiz, Antoine Dedieu, Miguel L ´azaro- Gredilla, and Kevin Murphy. Diffusion model predictive control.arXiv preprint arXiv:2410.05364, 2024. APPENDIX A. Necessity of Latent Space Safety Unlike simpler relative-to-base tracking methods, mo...
-
[59]
We define theOptimal Safety Valueat statesas the maximum safety probability achievable froms: V ∗(s)≜max z∈Z W π(s, z).(11) Fig
Definitions:LetI(s)denote the safety indicator ISsaf e(s). We define theOptimal Safety Valueat statesas the maximum safety probability achievable froms: V ∗(s)≜max z∈Z W π(s, z).(11) Fig. 8. (a) Extreme sparsity of competent trajectories in the 24D command space even with curriculum learning. (b) Latent space visualization confirming our ILS mechanism eff...
-
[60]
Then-step Expansion Operator:Then-step probability expansion operatorP (n) is defined as the expected safety calculated using the rollout trajectoryτ∼ D rollout for the firstnsteps and assuming optimal control thereafter: P (n) ≜E τ " n−1Y i=0 I(st+i) ! V ∗(st+n) # .(13) Forn= 1, this simplifies toP (1) =W π(st, zt)
-
[61]
n−1Y i=0 I(st+i) ! I(st+n)Est+n+1[V ∗(st+n+1)] # =E τ
Monotonicity Proof:We now prove that the sequence is monotonically non-increasing, i.e.,P (n) ≥ P (n+1). First, we expandV ∗(st+n)using the Bellman equation: V ∗(st+n) = max z′ I(st+n)Es′|st+n,z′ [V ∗(s′)] ≥I(s t+n)·E st+n+1|st+n,zt+n [V ∗(st+n+1)].(14) The inequality holds because the maximum over allz ′ is inherently greater than or equal to the expecta...
-
[62]
theoretical optimal safety
TD(λ saf e) Target and Tightness:The training target Gλsaf e t is defined as the geometric weighted average of these n-step expansions: Gλsaf e t = (1−λ saf e) ∞X n=1 λn−1 saf eP (n).(16) Since{P (n)}is a monotonically non-increasing sequence, the convex combination is upper-bounded by its first term: Gλsaf e t ≤ P (1) =W π(st, zt).(17) Thus,G λsaf e t re...
-
[63]
Salvageable
Approximation of the Maximization (Eq.(5)):The sub- stitution ofmax z′ W π(st+1, z′)with the value at the latent ori- gin cWω(st+1,0)introduces an approximation. Theoretically, becausemax z′ W π(st+1, z′)≥W π(st+1,0), this substitution yields an even more conservative learning targetW target,t ≤ maxz′ W π(st+1, z′), reinforcing the theoretical lower-bound...
-
[64]
cup in the wild
In-Distribution (ID) Dataset:The training dataset con- sists of 7,000 trajectories, constructed from two primary sources: a) Augmented UMI Data:We utilize the open-source dataset from UMI-on-Legs [18], specifically incorporating 1,090 “cup in the wild” trajectories and 101 “tossing” tra- jectories collected via the UMI [10] data collection pipeline. To ba...
-
[65]
a) OOD-Geometry (Rear Workspace):This dataset eval- uates the agent’s competence in reaching targets completely outside the training distribution (specifically, behind the robot)
Out-of-Distribution (OOD) Datasets:We evaluate gen- eralization using two challenging variants, each containing 7,000 trajectories derived from the full ID dataset. a) OOD-Geometry (Rear Workspace):This dataset eval- uates the agent’s competence in reaching targets completely outside the training distribution (specifically, behind the robot). We take the ...
-
[66]
The detailed architectural configurations are summarized in Table V
Network Architectures:We implement all network mod- ules using Multi-Layer Perceptrons (MLPs). The detailed architectural configurations are summarized in Table V. TABLE V NETWORKARCHITECTURES Module Input Hidden Output Activation Encoderϕ s t , g t [256,256]6 ELU Policyπ s t , z t [256,256,256]12+6 ELU Safetyω s t , z t [256,256]1 ELU+Sig * * ELU for hid...
-
[67]
We utilize a reward formulation consistent with UMI-on-Legs [18] for the PPO surrogate loss
Training Hyperparameters:The training process in- volves separate optimizers for the policy and the Safety Estimator. We utilize a reward formulation consistent with UMI-on-Legs [18] for the PPO surrogate loss. A detailed summary of hyperparameters is provided in Table VI. TABLE VI TRAININGHYPERPARAMETERS Parameter Policy Opt. (π, ϕ) Safety Opt. (ω) Optim...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.