Recognition: 2 theorem links
· Lean TheoremReflectRM: Boosting Generative Reward Models via Self-Reflection within a Unified Judgment Framework
Pith reviewed 2026-05-10 17:57 UTC · model grok-4.3
The pith
ReflectRM trains generative reward models to jointly model preferences and self-reflect on analysis quality to improve preference predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
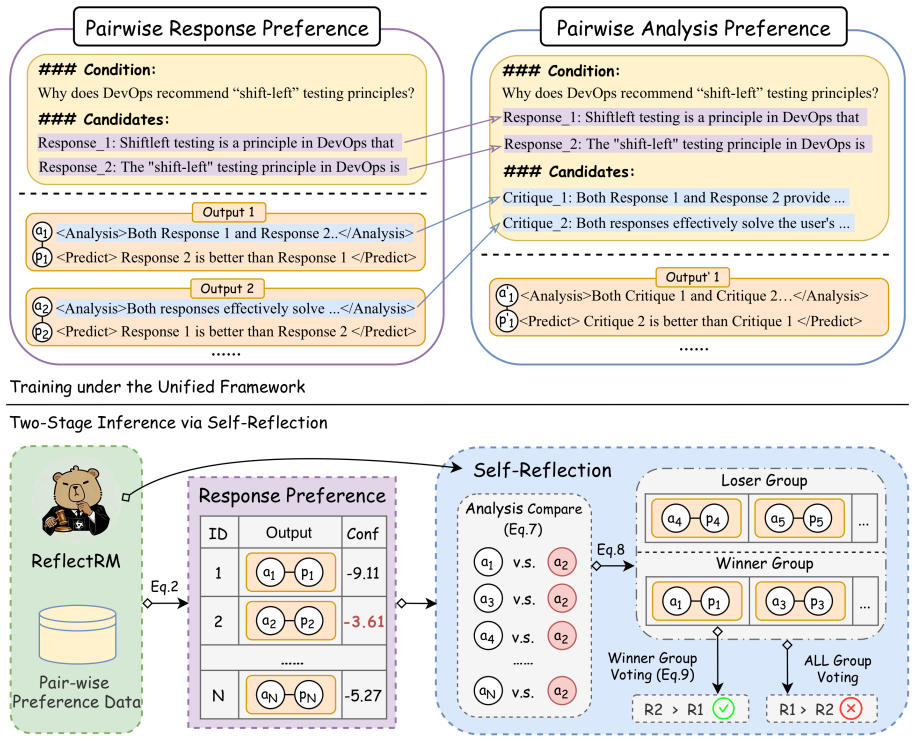
ReflectRM is trained under a unified generative framework for joint modeling of response preference and analysis preference. During inference, its self-reflection capability identifies the most reliable analysis, from which the final preference prediction is derived, resulting in consistent performance improvements across benchmarks and substantial mitigation of positional bias.
What carries the argument
A unified generative framework that jointly models response preference and analysis preference, enabling self-reflection to select the most reliable analysis at inference time.
Load-bearing premise
The model's self-generated reflections on analysis quality can reliably identify the most trustworthy analysis without introducing new biases or errors.
What would settle it
A test set where the analyses chosen via self-reflection lead to lower preference accuracy than using the original analyses without reflection or a random selection.
Figures


read the original abstract
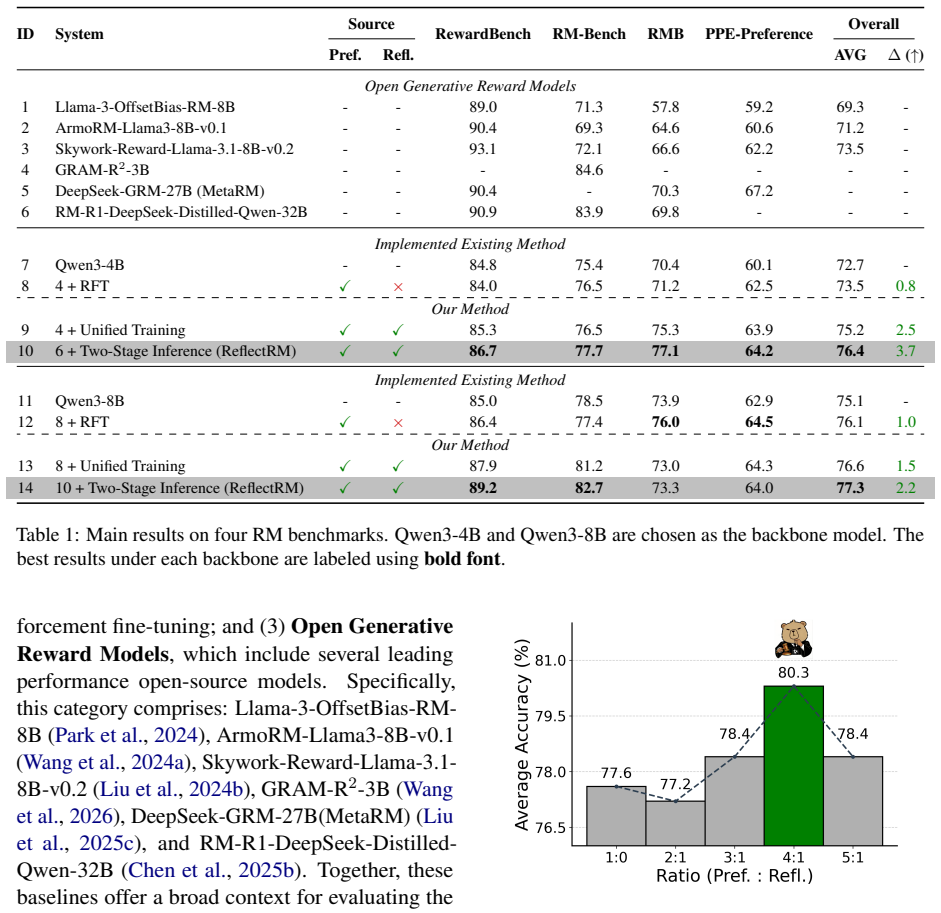
Reward Models (RMs) are critical components in the Reinforcement Learning from Human Feedback (RLHF) pipeline, directly determining the alignment quality of Large Language Models (LLMs). Recently, Generative Reward Models (GRMs) have emerged as a superior paradigm, offering higher interpretability and stronger generalization than traditional scalar RMs. However, existing methods for GRMs focus primarily on outcome-level supervision, neglecting analytical process quality, which constrains their potential. To address this, we propose ReflectRM, a novel GRM that leverages self-reflection to assess analytical quality and enhance preference modeling. ReflectRM is trained under a unified generative framework for joint modeling of response preference and analysis preference. During inference, we use its self-reflection capability to identify the most reliable analysis, from which the final preference prediction is derived. Experiments across four benchmarks show that ReflectRM consistently improves performance, achieving an average accuracy gain of +3.7 on Qwen3-4B. Further experiments confirm that response preference and analysis preference are mutually reinforcing. Notably, ReflectRM substantially mitigates positional bias, yielding +10.2 improvement compared with leading GRMs and establishing itself as a more stable evaluator. Our code is available at https://github.com/yuliangCarmelo/ReflectRM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReflectRM, a generative reward model (GRM) trained in a unified framework that jointly models response preference and analysis preference. During inference, the model generates multiple analyses, uses self-reflection to identify the most reliable one, and derives the final preference judgment from it. Experiments on four benchmarks report average accuracy gains of +3.7 on Qwen3-4B and +10.2 improvement in positional bias mitigation relative to leading GRMs, along with evidence that response and analysis preferences mutually reinforce each other.
Significance. If the self-reflection selection mechanism can be shown to reliably identify higher-quality analyses rather than simply echoing training artifacts, ReflectRM would represent a meaningful advance in process-aware generative reward modeling for RLHF. The joint training paradigm and open-sourced code at the provided GitHub link are strengths that could support reproducibility and further work on interpretable evaluators. The reported bias mitigation is particularly noteworthy if it generalizes beyond the tested models.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The headline performance claims (+3.7 accuracy gain and +10.2 positional-bias improvement) are presented without any mention of the specific baselines, statistical significance tests, data splits, or controls for confounds such as prompt formatting or model scale. Because these numbers are the primary evidence for the superiority of the self-reflection pipeline, their evidential value cannot be assessed from the provided information.
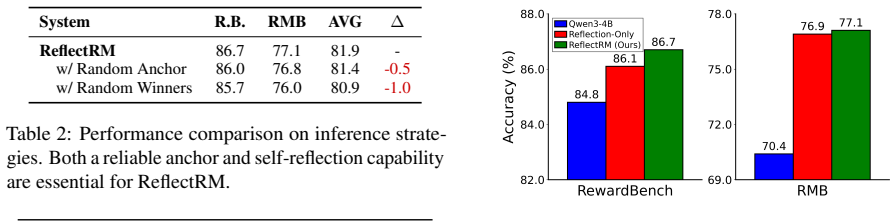
- [Method / Inference] Inference procedure (described in the Method section): The self-reflection step that selects the 'most reliable' analysis is load-bearing for the claimed gains, yet the training objective supplies only joint preference modeling with no external human-verified signal of analysis quality. No ablation is reported that compares self-reflection selection against simpler alternatives (e.g., majority vote across analyses or random selection). Without such a control, it remains possible that the reported improvements arise from the joint training itself rather than the inference-time selection mechanism.
- [Experiments] Experiments section: The mutual-reinforcement claim between response preference and analysis preference is stated but not supported by quantitative metrics (e.g., correlation between the two heads during training or performance drop when one objective is ablated). This leaves the 'unified judgment framework' contribution underspecified relative to the performance numbers.
minor comments (2)
- [Method] The paper would benefit from explicit description of the generative loss function, prompt templates, and decoding parameters used for both training and the multi-analysis inference procedure.
- [Experiments] Figure or table captions should clarify whether the reported accuracies are macro-averaged across the four benchmarks or broken down per dataset.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. The comments highlight important areas for clarification and additional evidence, which we will address in a revised version. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The headline performance claims (+3.7 accuracy gain and +10.2 positional-bias improvement) are presented without any mention of the specific baselines, statistical significance tests, data splits, or controls for confounds such as prompt formatting or model scale. Because these numbers are the primary evidence for the superiority of the self-reflection pipeline, their evidential value cannot be assessed from the provided information.
Authors: We agree that the abstract and experiments section would benefit from greater specificity to allow readers to fully evaluate the results. In the revised manuscript, we will explicitly list the baselines compared against (leading GRMs), report statistical significance tests, detail the data splits used across the four benchmarks, and include discussion of controls for confounds such as prompt formatting and model scale. This will strengthen the presentation of the performance claims. revision: yes
-
Referee: [Method / Inference] Inference procedure (described in the Method section): The self-reflection step that selects the 'most reliable' analysis is load-bearing for the claimed gains, yet the training objective supplies only joint preference modeling with no external human-verified signal of analysis quality. No ablation is reported that compares self-reflection selection against simpler alternatives (e.g., majority vote across analyses or random selection). Without such a control, it remains possible that the reported improvements arise from the joint training itself rather than the inference-time selection mechanism.
Authors: This is a valid concern regarding the isolation of the self-reflection mechanism's contribution. The training uses only joint preference modeling without direct supervision on analysis quality. To address this, we will add ablations in the experiments section comparing the self-reflection selection to majority vote and random selection of analyses. These will demonstrate that the selection step provides additional gains beyond the joint training alone. revision: yes
-
Referee: [Experiments] Experiments section: The mutual-reinforcement claim between response preference and analysis preference is stated but not supported by quantitative metrics (e.g., correlation between the two heads during training or performance drop when one objective is ablated). This leaves the 'unified judgment framework' contribution underspecified relative to the performance numbers.
Authors: We concur that quantitative evidence would better support the mutual reinforcement aspect. In the revision, we will include metrics such as the correlation between the response and analysis preference predictions during training, as well as ablation studies showing performance degradation when one of the objectives is removed. This will more clearly specify the benefits of the unified framework. revision: yes
Circularity Check
No significant circularity; empirical results rest on external benchmarks
full rationale
The paper describes an empirical training procedure for a generative reward model under a unified framework for joint response and analysis preference modeling, followed by inference-time self-reflection selection. No equations, closed-form derivations, or first-principles predictions appear. Central performance claims (+3.7 accuracy, +10.2 bias mitigation) are tied to reported results on four external benchmarks rather than any self-referential fit or renaming. Mutual reinforcement between preferences is presented as an empirical observation from training, not a definitional tautology. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are indicated in the abstract or description. The work is self-contained against external evaluation data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reflection generated by the model can accurately assess the quality of its own analytical reasoning.
- domain assumption Joint training on response and analysis preferences produces mutual reinforcement that improves both.
invented entities (1)
-
ReflectRM
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified generative framework for joint modeling of response preference and analysis preference... self-reflection capability to identify the most reliable analysis
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
response preference and analysis preference are mutually reinforcing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains.arXiv preprint arXiv:2507.17746. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025a. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.1294...
work page internal anchor Pith review arXiv 2024
-
[2]
Generative reward models.arXiv preprint arXiv:2410.12832, 2024
Generative reward models.arXiv preprint arXiv:2410.12832. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow in- structions with human feedback.Advances in neural information processing systems, 35:27730–27744....
-
[3]
5: Advancing superb reasoning models with reinforcement learning , author=
Seed1. 5-thinking: Advancing superb rea- soning models with reinforcement learning.arXiv preprint arXiv:2504.13914. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv...
-
[4]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Chenglong Wang, Yang Gan, Yifu Huo, Yongyu Mu, Qiaozhi He, Murun Yang, Bei Li, Tong Xiao, Chunliang Zhang, Tongran Liu, and 1 oth- ers. 2025a. Gram: A generative foundation reward model for reward generalization.arXiv preprint arXiv:2506.14175. Chenglong Wang, Yongyu Mu,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Ziyi Ye, Xiangsheng Li, Qiuchi Li, Qingyao Ai, Yujia Zhou, Wei Shen, Dong Yan, and Yiqun Liu. 2025. Learning llm-as-a-judge for preference alignment. In The Thirteenth International Conference on Learning Representations. Jiachen Yu, Shaoning Sun, Xiaohui Hu, Jiaxu Yan, Kaidong Yu, and Xuelong Li. 20...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.