Recognition: unknown
How Independent are Large Language Models? A Statistical Framework for Auditing Behavioral Entanglement and Reweighting Verifier Ensembles
Pith reviewed 2026-05-10 17:08 UTC · model grok-4.3
The pith
Large language models exhibit behavioral entanglement that undermines independence assumptions in judging and ensemble systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
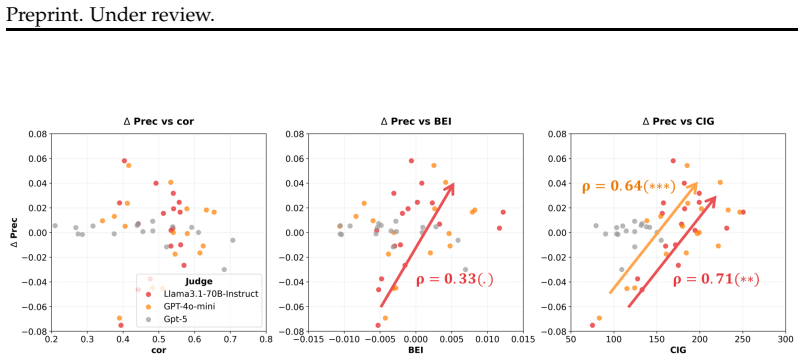
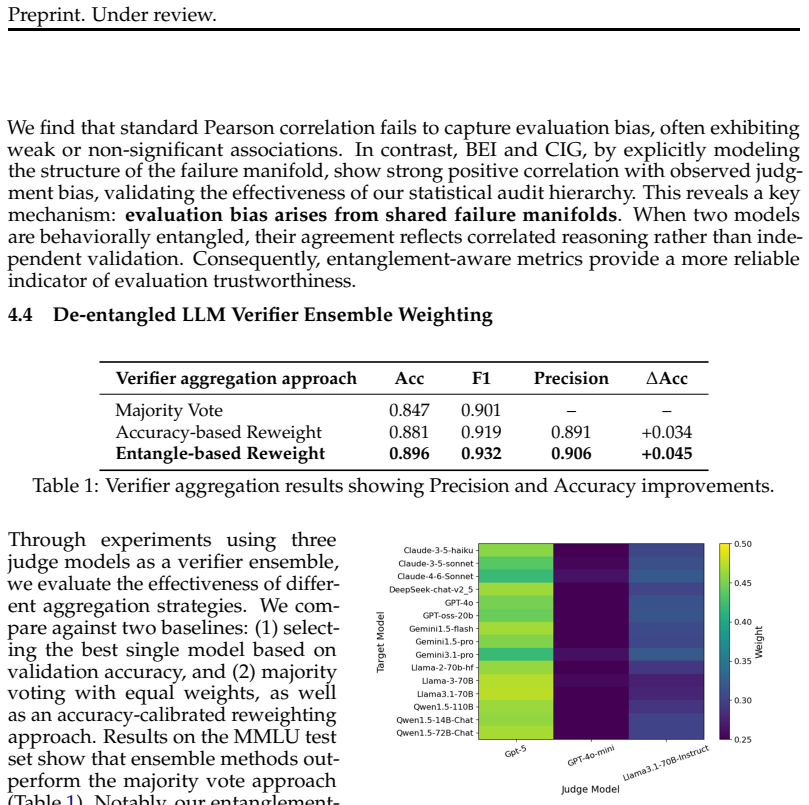
Behavioral entanglement among black-box LLMs can be measured through a multi-resolution hierarchy of the joint failure manifold using a Difficulty-Weighted Behavioral Entanglement Index that amplifies synchronized failures on easy tasks and a Cumulative Information Gain metric that tracks directional alignment in errors. These metrics reveal widespread entanglement across model families and a statistically significant link between higher CIG scores and degraded judge precision, with Spearman correlations of 0.64 and 0.71 in the tested cases. Reweighting model contributions in ensembles according to inferred independence mitigates correlated bias and delivers accuracy gains up to 4.5 percent.
What carries the argument
The multi-resolution hierarchy characterizing the joint failure manifold via the Difficulty-Weighted Behavioral Entanglement Index, which weights synchronized failures by task ease, and the Cumulative Information Gain metric, which captures alignment in erroneous responses.
Load-bearing premise
The proposed metrics computed from black-box outputs on a fixed task set accurately capture latent behavioral dependencies rather than surface-level output correlations.
What would settle it
A replication experiment on new tasks and models that finds no statistically significant Spearman correlation between Cumulative Information Gain and judge precision degradation, or that finds no accuracy improvement from the reweighting method, would falsify the central claims.
Figures


read the original abstract
The rapid growth of the large language model (LLM) ecosystem raises a critical question: are seemingly diverse models truly independent? Shared pretraining data, distillation, and alignment pipelines can induce hidden behavioral dependencies, latent entanglement, that undermine multi-model systems such as LLM-as-a-judge pipelines and ensemble verification, which implicitly assume independent signals. In practice, this manifests as correlated reasoning patterns and synchronized failures, where apparent agreement reflects shared error modes rather than independent validation. To address this, we develop a statistical framework for auditing behavioral entanglement among black-box LLMs. Our approach introduces a multi-resolution hierarchy that characterizes the joint failure manifold through two information-theoretic metrics: (i) a Difficulty-Weighted Behavioral Entanglement Index, which amplifies synchronized failures on easy tasks, and (ii) a Cumulative Information Gain (CIG) metric, which captures directional alignment in erroneous responses. Through extensive experiments on 18 LLMs from six model families, we identify widespread behavioral entanglement and analyze its impact on LLM-as-a-judge evaluation. We find that CIG exhibits a statistically significant association with degradation in judge precision, with Spearman coefficient of 0.64 (p < 0.001) for GPT-4o-mini and 0.71 (p < 0.01) for Llama3-based judges, indicating that stronger dependency corresponds to increased over-endorsement bias. Finally, we demonstrate a practical use case of entanglement through de-entangled verifier ensemble reweighting. By adjusting model contributions based on inferred independence, the proposed method mitigates correlated bias and improves verification performance, achieving up to a 4.5% accuracy gain over majority voting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a statistical framework to audit behavioral entanglement in black-box LLMs via two new information-theoretic metrics: a Difficulty-Weighted Behavioral Entanglement Index that amplifies synchronized failures on easy tasks, and a Cumulative Information Gain (CIG) metric that captures directional alignment in erroneous responses. Experiments across 18 LLMs from six families identify widespread entanglement, report Spearman correlations of 0.64 (p<0.001) and 0.71 (p<0.01) between CIG and judge precision degradation for GPT-4o-mini and Llama3-based judges respectively, and demonstrate a reweighting scheme for verifier ensembles that yields up to 4.5% accuracy gain over majority voting.
Significance. If the metrics can be shown to isolate latent dependencies induced by shared pretraining or distillation rather than surface-level output correlations, the framework would offer a practical tool for improving the reliability of LLM-as-a-judge pipelines and multi-model verification systems. The scale of the evaluation (18 models across six families) and the concrete reweighting application are strengths that could make the work a useful reference for ensemble design, provided the statistical claims are placed on firmer ground.
major comments (3)
- [Abstract] Abstract: The reported Spearman coefficients (0.64 and 0.71) and associated p-values are presented without error bars, confidence intervals, sample-size details (number of tasks or judges), or mention of multiple-comparison correction; these omissions are load-bearing because the central claim is a statistically significant association between CIG and judge-precision degradation.
- [Metrics definitions] Metrics definitions (presumably §3): The Difficulty-Weighted Behavioral Entanglement Index and CIG are computed exclusively from black-box agreement patterns on a fixed task set, yet no derivation or control experiment is supplied to demonstrate that they isolate directional entanglement from shared pretraining rather than generic error-mode overlap or task-induced response similarity; this assumption is load-bearing for both the causal interpretation of the correlation results and the justification for the reweighting method.
- [Experimental results] Experimental results (presumably §4–5): No details are given on task selection criteria, statistical controls, or reproducibility (no code or data release), despite the headline accuracy gain of 4.5% and the correlation findings resting entirely on these unreproduced experiments.
minor comments (1)
- [Abstract] The abstract introduces a 'multi-resolution hierarchy' without a brief clarifying phrase, which could be added for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional statistical detail, clarification of metric assumptions, and experimental transparency will strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported Spearman coefficients (0.64 and 0.71) and associated p-values are presented without error bars, confidence intervals, sample-size details (number of tasks or judges), or mention of multiple-comparison correction; these omissions are load-bearing because the central claim is a statistically significant association between CIG and judge-precision degradation.
Authors: We agree that the presentation of the Spearman correlations requires additional statistical support. In the revised manuscript we will report bootstrap-derived 95% confidence intervals for both coefficients, explicitly state the sample sizes (number of tasks and number of judges), and note that no multiple-comparison correction was applied because only two primary associations were examined. These details will appear in both the abstract and the results section. revision: yes
-
Referee: [Metrics definitions] Metrics definitions (presumably §3): The Difficulty-Weighted Behavioral Entanglement Index and CIG are computed exclusively from black-box agreement patterns on a fixed task set, yet no derivation or control experiment is supplied to demonstrate that they isolate directional entanglement from shared pretraining rather than generic error-mode overlap or task-induced response similarity; this assumption is load-bearing for both the causal interpretation of the correlation results and the justification for the reweighting method.
Authors: The metrics are constructed from observable agreement statistics with explicit weighting by task difficulty and directional error alignment; their information-theoretic motivation is given in §3. We acknowledge, however, that a formal derivation isolating pretraining-induced latent dependencies from surface-level error overlap is not provided and would be difficult to obtain under a purely black-box protocol. We will add a limitations subsection that discusses this assumption and include a new control comparison of entanglement scores between same-family versus cross-family model pairs to supply empirical grounding for the reweighting application. revision: partial
-
Referee: [Experimental results] Experimental results (presumably §4–5): No details are given on task selection criteria, statistical controls, or reproducibility (no code or data release), despite the headline accuracy gain of 4.5% and the correlation findings resting entirely on these unreproduced experiments.
Authors: We will expand §§4–5 with explicit task-selection criteria (diversity across reasoning, knowledge, and safety benchmarks together with difficulty stratification), a description of the statistical controls (permutation tests and randomization of task order), and full reproducibility information. We also commit to releasing the complete codebase and processed evaluation data in a public repository upon acceptance. revision: yes
Circularity Check
No significant circularity in the statistical framework or reweighting demonstration
full rationale
The Difficulty-Weighted Behavioral Entanglement Index and Cumulative Information Gain (CIG) are defined directly from black-box model outputs on a fixed task set. The reported Spearman correlations (0.64 and 0.71) are empirical associations between these metrics and judge precision degradation, not reductions by construction. The 4.5% accuracy gain from reweighting is a demonstrated improvement over majority voting based on inferred independence, without evidence that it reduces to fitted parameters within the same data in a self-definitional way. No self-citations or ansatzes are load-bearing in the provided abstract and description. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Black-box output agreement on a fixed benchmark set is a sufficient proxy for latent model dependence induced by shared training data or pipelines.
invented entities (2)
-
Difficulty-Weighted Behavioral Entanglement Index
no independent evidence
-
Cumulative Information Gain (CIG)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Knowledge Is Not Static: Order-Aware Hypergraph RAG for Language Models
OKH-RAG represents knowledge as ordered hyperedges and retrieves coherent interaction sequences via a learned transition model, outperforming permutation-invariant RAG baselines on order-sensitive QA tasks.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
anthropic.com/news/claude-3-family
URL https://www. anthropic.com/news/claude-3-family. Accessed: 2026-03-31. Anthropic. Claude 4 system card / technical overview. https://www.anthropic.com/ research,
2026
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Beyond the surface: Measuring self-preference in llm judgments
Zhi-Yuan Chen, Hao Wang, Xinyu Zhang, Enrui Hu, and Yankai Lin. Beyond the surface: Measuring self-preference in llm judgments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1653–1672,
2025
-
[5]
Investigat- ing data contamination in modern benchmarks for large language models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. Investigat- ing data contamination in modern benchmarks for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8706–8719,
2024
-
[6]
Gen- eralization or memorization: Data contamination and trustworthy evaluation for large language models
Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, and Ge Li. Gen- eralization or memorization: Data contamination and trustworthy evaluation for large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 12039–12050,
2024
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
10 Preprint. Under review. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Vicunaner: Zero/few-shot named entity recognition using vicuna.arXiv preprint arXiv:2305.03253,
Bin Ji. Vicunaner: Zero/few-shot named entity recognition using vicuna.arXiv preprint arXiv:2305.03253,
-
[10]
Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. Preference leakage: A contamination problem in llm-as-a-judge.arXiv preprint arXiv:2502.01534,
-
[11]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024a. Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vuli´c, Anna Korhonen, and Nigel Collier. Aligning ...
work page internal anchor Pith review arXiv 2024
-
[12]
Accessed: 2026-03-31
URLhttps://llama.meta.com/llama3/. Accessed: 2026-03-31. OpenAI. Hello gpt-4o. https://openai.com/index/hello-gpt-4o/,
2026
-
[13]
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho
Accessed: 2026- 03-31. Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. Relational knowledge distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3967–3976,
2026
-
[14]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277,
work page internal anchor Pith review arXiv
-
[15]
Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark
Oscar Sainz, Jon Campos, Iker Garc´ıa-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787,
2023
-
[16]
Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789,
-
[17]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multi- modal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Who taught you that? tracing teachers in model distillation
Somin Wadhwa, Chantal Shaib, Silvio Amir, and Byron C Wallace. Who taught you that? tracing teachers in model distillation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 3307–3315,
2025
-
[21]
URLhttps://openreview.net/forum?id=z1MHB2m3V9. Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization.arXiv preprint arXiv:2306.05087,
-
[22]
arXiv preprint arXiv:2410.21819 (2025)
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. Self-preference bias in llm-as-a-judge. arXiv preprint arXiv:2410.21819,
-
[23]
arXiv preprint arXiv:2406.04244 , year=
Cheng Xu, Shuhao Guan, Derek Greene, M Kechadi, et al. Benchmark data contamination of large language models: A survey.arXiv preprint arXiv:2406.04244,
-
[24]
Justice or prejudice? quantifying biases in llm-as-a-judge
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, et al. Justice or prejudice? quantifying biases in llm-as-a-judge.arXiv preprint arXiv:2410.02736,
-
[25]
Don’t make your llm an evaluation benchmark cheater
Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji-Rong Wen, and Jiawei Han. Don’t make your llm an evaluation benchmark cheater. arXiv preprint arXiv:2311.01964,
-
[26]
Instruct
A Experiment Settings A.1 Selected models We select 18 models from the GPT, Claude, Qwen, Llama, Gemini, and DeepSeek families to examine potential entanglement both within and across model families. Specifically, the selected models are ChatGPT-5 (Singh et al., 2025), GPT-4o (OpenAI, 2024), GPT-4o-mini (Hurst et al., 2024), GPT-oss-20B (Agarwal et al., 2...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.