Recognition: 2 theorem links
· Lean TheoremSymbiotic-MoE: Unlocking the Synergy between Generation and Understanding
Pith reviewed 2026-05-10 18:19 UTC · model grok-4.3
The pith
Symbiotic-MoE lets generative training improve rather than degrade understanding in multimodal models through shared experts and staged optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Symbiotic-MoE resolves task interference inside a native multimodal Mixture-of-Experts Transformers model with zero added parameters. It first diagnoses routing collapse in ordinary MoE tuning, where generative gradients monopolize expert utilization. Modality-Aware Expert Disentanglement then partitions experts into task-specific groups while retaining shared experts as a multimodal semantic bridge that lets generative tasks supply fine-grained visual semantics to textual representations. A Progressive Training Strategy applies differential learning rates and early-stage gradient shielding to protect pre-trained knowledge and convert early volatility into constructive feedback for the other
What carries the argument
Modality-Aware Expert Disentanglement, which partitions experts into task-specific groups with shared experts acting as a multimodal semantic bridge, together with Progressive Training Strategy using differential learning rates and early gradient shielding.
If this is right
- Generative tasks reach rapid convergence while understanding capabilities are preserved or improved.
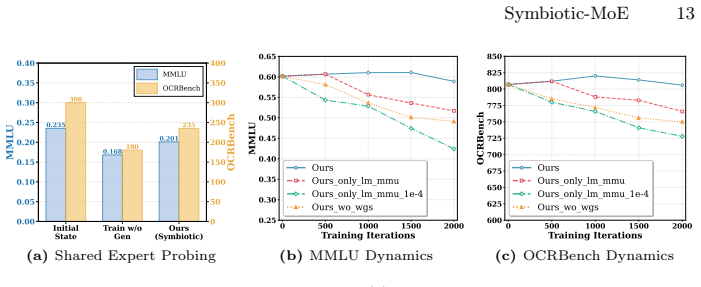
- Cross-modal synergy produces measurable gains on understanding benchmarks such as MMLU and OCRBench.
- The model retains full original capacity with no parameter overhead or fragmentation.
- Early training volatility is converted into positive feedback rather than destructive interference.
- Task isolation is avoided, unlike structural separation methods that lose synergy.
Where Pith is reading between the lines
- The shared-expert bridge could be reused as a general pattern for transferring useful signals across any pair of conflicting objectives in large models.
- Progressive shielding of early gradients may shorten the alignment phase needed when adding new capabilities to already-trained multimodal systems.
- If routing stabilizes under this partitioning, similar disentanglement could support scaling MoE models to larger numbers of simultaneous tasks without collapse.
Load-bearing premise
That shared experts will absorb fine-grained visual semantics from generation and transfer them to improve understanding without routing collapse or negative interference between task groups.
What would settle it
After full training, a direct comparison showing that MMLU or OCRBench scores remain flat or decline relative to a standard multimodal baseline, or that routing statistics still show generative tasks dominating expert selection despite the disentanglement.
Figures








read the original abstract
Empowering Large Multimodal Models (LMMs) with image generation often leads to catastrophic forgetting in understanding tasks due to severe gradient conflicts. While existing paradigms like Mixture-of-Transformers (MoT) mitigate this conflict through structural isolation, they fundamentally sever cross-modal synergy and suffer from capacity fragmentation. In this work, we present Symbiotic-MoE, a unified pre-training framework that resolves task interference within a native multimodal Mixture-of-Experts (MoE) Transformers architecture with zero-parameter overhead. We first identify that standard MoE tuning leads to routing collapse, where generative gradients dominate expert utilization. To address this, we introduce Modality-Aware Expert Disentanglement, which partitions experts into task-specific groups while utilizing shared experts as a multimodal semantic bridge. Crucially, this design allows shared experts to absorb fine-grained visual semantics from generative tasks to enrich textual representations. To optimize this, we propose a Progressive Training Strategy featuring differential learning rates and early-stage gradient shielding. This mechanism not only shields pre-trained knowledge from early volatility but eventually transforms generative signals into constructive feedback for understanding. Extensive experiments demonstrate that Symbiotic-MoE achieves rapid generative convergence while unlocking cross-modal synergy, boosting inherent understanding with remarkable gains on MMLU and OCRBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Symbiotic-MoE, a native multimodal MoE Transformer framework for jointly training image generation and understanding in LMMs. It identifies routing collapse in standard MoE under generative dominance, introduces Modality-Aware Expert Disentanglement (task-specific expert groups plus shared experts as a semantic bridge) to enable generative signals to enrich understanding, and a Progressive Training Strategy (differential learning rates and early gradient shielding) to stabilize training and convert interference into synergy, claiming zero-parameter overhead and substantial gains on understanding benchmarks such as MMLU and OCRBench.
Significance. If the mechanisms function as described and the claimed gains are reproducible, the work would be significant for multimodal model design: it offers a parameter-efficient alternative to structural isolation methods like MoT while preserving cross-modal synergy, potentially enabling more unified generative-understanding models without catastrophic forgetting.
major comments (3)
- [Abstract] Abstract: The central claims of 'remarkable gains on MMLU and OCRBench', 'rapid generative convergence', and successful conversion of generative signals into constructive feedback for understanding are stated without any quantitative results, baseline comparisons, ablation studies, or experimental details (e.g., no numbers, tables, or figures referenced). This absence makes it impossible to assess whether Modality-Aware Expert Disentanglement and Progressive Training actually prevent routing collapse or deliver the reported benefits.
- [Abstract] Abstract / Proposed Method: The assertion that shared experts act as a 'multimodal semantic bridge' absorbing fine-grained visual semantics from generative tasks relies on an unverified mechanism; no evidence is provided (such as expert utilization histograms, per-expert contribution ablations, gradient cosine similarities, or routing statistics) to confirm that the design transmits constructive signals rather than merely delaying interference or creating new collapse modes after shielding is removed.
- [Abstract] Abstract: The claim of 'zero-parameter overhead' is not reconciled with the introduction of new components (task-specific partitioning, shared experts, differential LRs, and gradient shielding); without implementation details or a parameter count comparison to the baseline MoE, it is unclear whether the overhead is truly zero or merely deferred.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. We have revised the manuscript to improve the abstract's informativeness, add explicit references to supporting analyses, and include a parameter comparison table.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'remarkable gains on MMLU and OCRBench', 'rapid generative convergence', and successful conversion of generative signals into constructive feedback for understanding are stated without any quantitative results, baseline comparisons, ablation studies, or experimental details (e.g., no numbers, tables, or figures referenced). This absence makes it impossible to assess whether Modality-Aware Expert Disentanglement and Progressive Training actually prevent routing collapse or deliver the reported benefits.
Authors: We agree that the abstract would be strengthened by direct references to quantitative results and supporting materials. The full manuscript presents these in the Experiments section, including baseline comparisons, ablation studies on routing behavior, and performance tables for MMLU and OCRBench. We have revised the abstract to reference the relevant tables and figures that quantify the gains and convergence behavior. revision: yes
-
Referee: [Abstract] Abstract / Proposed Method: The assertion that shared experts act as a 'multimodal semantic bridge' absorbing fine-grained visual semantics from generative tasks relies on an unverified mechanism; no evidence is provided (such as expert utilization histograms, per-expert contribution ablations, gradient cosine similarities, or routing statistics) to confirm that the design transmits constructive signals rather than merely delaying interference or creating new collapse modes after shielding is removed.
Authors: The experimental section of the manuscript includes expert utilization histograms, ablation studies isolating the contribution of shared experts, and routing statistics demonstrating improved balance and cross-modal signal flow. These analyses support that the shared experts enable constructive transfer rather than temporary delay. We have updated the method description to explicitly cite these results and added a concise reference in the abstract. revision: yes
-
Referee: [Abstract] Abstract: The claim of 'zero-parameter overhead' is not reconciled with the introduction of new components (task-specific partitioning, shared experts, differential LRs, and gradient shielding); without implementation details or a parameter count comparison to the baseline MoE, it is unclear whether the overhead is truly zero or merely deferred.
Authors: Task-specific partitioning and shared experts are implemented by re-grouping the existing expert pool within the original MoE architecture, introducing no additional parameters. Differential learning rates and gradient shielding are purely training-time strategies. We have added an explicit parameter-count comparison table in the revised manuscript showing identical total parameters to the baseline MoE, and clarified this point in the abstract and method section. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes new architectural elements (Modality-Aware Expert Disentanglement with task-specific and shared experts) and a Progressive Training Strategy (differential learning rates plus early gradient shielding) to address routing collapse and enable cross-modal synergy in multimodal MoE Transformers. These are presented as independent design choices justified by the architecture description and empirical results on benchmarks, without reducing to self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or steps in the provided text equate outputs to inputs by construction; the central claims about shared experts absorbing generative signals remain design assertions rather than tautological reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard MoE tuning leads to routing collapse dominated by generative gradients.
- ad hoc to paper Shared experts can absorb fine-grained visual semantics from generative tasks to enrich textual representations.
invented entities (2)
-
Modality-Aware Expert Disentanglement
no independent evidence
-
Progressive Training Strategy
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Modality-Aware Expert Disentanglement... shared experts as a multimodal semantic bridge... Progressive Training Strategy featuring differential learning rates and early-stage gradient shielding
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
resolves task interference within a native multimodal Mixture-of-Experts (MoE) Transformers architecture with zero-parameter overhead
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2505.12043 (2025) 24
Chen, J., Tang, Q., Lu, Q., Fang, S.: Mol for llms: Dual-loss optimization to enhance domain expertise while preserving general capabilities. arXiv preprint arXiv:2505.12043 (2025) 24
-
[3]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review arXiv 2025
-
[4]
MoFO: Momentum-filtered optimizer for mitigating forgetting in LLM fine-tuning
Chen, Y., Wang, S., Zhang, Y., Lin, Z., Zhang, H., Sun, W., Ding, T., Sun, R.: Mofo: Momentum-filtered optimizer for mitigating forgetting in llm fine-tuning. arXiv preprint arXiv:2407.20999 (2024)
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[6]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Dai, D., Deng, C., Zhao, C., Xu, R., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., et al.: Deepseekmoe: Towards ultimate expert specialization in mixture- of-experts language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1280– 1297 (2024)
2024
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., Shi, G., Fan, H.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Dreamllm: Synergistic multimodal com- prehension and creation
Dong, R., Han, C., Peng, Y., Qi, Z., Ge, Z., Yang, J., Zhao, L., Sun, J., Zhou, H., Wei, H., et al.: Dreamllm: Synergistic multimodal comprehension and creation. arXiv preprint arXiv:2309.11499 (2023)
-
[9]
In: International conference on machine learning
Du, N., Huang, Y., Dai, A.M., Tong, S., Lepikhin, D., Xu, Y., Krikun, M., Zhou, Y., Yu, A.W., Firat, O., et al.: Glam: Efficient scaling of language models with mixture-of-experts. In: International conference on machine learning. pp. 5547–
-
[10]
In: Proceedings of the 32nd ACM international conference on multimedia
Duan, H., Yang, J., Qiao, Y., Fang, X., Chen, L., Liu, Y., Dong, X., Zang, Y., Zhang, P., Wang, J., et al.: Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In: Proceedings of the 32nd ACM international conference on multimedia. pp. 11198–11201 (2024)
2024
-
[11]
Journal of Machine Learning Research 23(120), 1–39 (2022)
Fedus,W.,Zoph,B.,Shazeer,N.:Switchtransformers:Scalingtotrillionparameter models with simple and efficient sparsity. Journal of Machine Learning Research 23(120), 1–39 (2022)
2022
-
[12]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
work page internal anchor Pith review arXiv 2023
-
[13]
Llama-adapter v2: Parameter-efficient visual instruction model
Gao, P., Han, J., Zhang, R., Lin, Z., Geng, S., Zhou, A., Zhang, W., Lu, P., He, C., Yue, X., et al.: Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010 (2023)
-
[14]
Advances in Neural Information Processing Systems36, 52132–52152 (2023)
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023)
2023
-
[15]
arXiv preprint arXiv:2502.17298 (2025)
Gu, H., Li, W., Li, L., Zhu, Q., Lee, M., Sun, S., Xue, W., Guo, Y.: Delta decom- pression for moe-based llms compression. arXiv preprint arXiv:2502.17298 (2025)
-
[16]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Stein- hardt, J.: Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[17]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021) Symbiotic-MoE Supplementary Material 25
2021
-
[18]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[19]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[20]
Advances in Neural Information Processing Systems36, 78723–78747 (2023)
Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. Advances in Neural Information Processing Systems36, 78723–78747 (2023)
2023
-
[21]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019)
2019
-
[22]
Jiang, A.Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D.S., Casas, D.d.l., Hanna, E.B., Bressand, F., et al.: Mixtral of experts. arXiv preprint arXiv:2401.04088 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
In: European conference on computer vision
Kembhavi, A., Salvato, M., Kolve, E., Seo, M., Hajishirzi, H., Farhadi, A.: A di- agram is worth a dozen images. In: European conference on computer vision. pp. 235–251. Springer (2016)
2016
-
[24]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern recognition
Kembhavi, A., Seo, M., Schwenk, D., Choi, J., Farhadi, A., Hajishirzi, H.: Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In: Proceedings of the IEEE Conference on Computer Vision and Pattern recognition. pp. 4999–5007 (2017)
2017
-
[25]
Advances in Neural Information Processing Systems36, 21487– 21506 (2023)
Koh, J.Y., Fried, D., Salakhutdinov, R.R.: Generating images with multimodal language models. Advances in Neural Information Processing Systems36, 21487– 21506 (2023)
2023
-
[26]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., Chen, Z.: Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668 (2020)
work page internal anchor Pith review arXiv 2006
-
[27]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 292–305 (2023)
2023
-
[28]
Transactions on Machine Learning Research (2025),https://openreview.net/forum?id=Nu6N69i8SB
Liang, W., YU, L., Luo, L., Iyer, S., Dong, N., Zhou, C., Ghosh, G., Lewis, M., tau Yih, W., Zettlemoyer, L., Lin, X.V.: Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models. Transactions on Machine Learning Research (2025),https://openreview.net/forum?id=Nu6N69i8SB
2025
-
[29]
IEEE Transactions on Multimedia (2026)
Lin, B., Tang, Z., Ye, Y., Huang, J., Zhang, J., Pang, Y., Jin, P., Ning, M., Luo, J., Yuan, L.: Moe-llava: Mixture of experts for large vision-language models. IEEE Transactions on Multimedia (2026)
2026
-
[30]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[31]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[33]
Science China Information Sciences67(12), 220102 (2024)
Liu, Y., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.C., Liu, C.L., Jin, L., Bai, X.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences67(12), 220102 (2024)
2024
-
[34]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Lu, H., Liu, W., Zhang, B., Wang, B., Dong, K., Liu, B., Sun, J., Ren, T., Li, Z., Yang, H., et al.: Deepseek-vl: towards real-world vision-language understanding. arXiv preprint arXiv:2403.05525 (2024) 26
work page internal anchor Pith review arXiv 2024
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Luo, G., Yang, X., Dou, W., Wang, Z., Liu, J., Dai, J., Qiao, Y., Zhu, X.: Mono- internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24960–24971 (2025)
2025
-
[36]
Lv,A.,Ma,J.,Ma,Y.,Qiao,S.:Couplingexpertsandroutersinmixture-of-experts via an auxiliary loss. arXiv preprint arXiv:2512.23447 (2025)
-
[37]
In: Findings of the association for computational linguistics: ACL 2022
Masry, A., Do, X.L., Tan, J.Q., Joty, S., Hoque, E.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In: Findings of the association for computational linguistics: ACL 2022. pp. 2263–2279 (2022)
2022
-
[38]
McCloskey, M., Cohen, N.J.: Catastrophic interference in connectionist networks: Thesequentiallearningproblem.In:Psychologyoflearningandmotivation,vol.24, pp. 109–165. Elsevier (1989)
1989
-
[39]
In: European Conference on Computer Vision
McKinzie, B., Gan, Z., Fauconnier, J.P., Dodge, S., Zhang, B., Dufter, P., Shah, D., Du, X., Peng, F., Belyi, A., et al.: Mm1: methods, analysis and insights from multimodal llm pre-training. In: European Conference on Computer Vision. pp. 304–323. Springer (2024)
2024
-
[40]
Neural networks113, 54–71 (2019)
Parisi, G.I., Kemker, R., Part, J.L., Kanan, C., Wermter, S.: Continual lifelong learning with neural networks: A review. Neural networks113, 54–71 (2019)
2019
-
[41]
Advances in Neural Information Processing Systems34, 8583–8595 (2021)
Riquelme, C., Puigcerver, J., Mustafa, B., Neumann, M., Jenatton, R., Su- sano Pinto, A., Keysers, D., Houlsby, N.: Scaling vision with sparse mixture of experts. Advances in Neural Information Processing Systems34, 8583–8595 (2021)
2021
-
[42]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Generative pretraining in mul- timodality
Sun, Q., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, Y., Gao, H., Liu, J., Huang, T., Wang, X.: Emu: Generative pretraining in multimodality. arXiv preprint arXiv:2307.05222 (2023)
-
[44]
Advances in Neural Information Processing Systems36, 16083– 16099 (2023)
Tang, Z., Yang, Z., Zhu, C., Zeng, M., Bansal, M.: Any-to-any generation via com- posable diffusion. Advances in Neural Information Processing Systems36, 16083– 16099 (2023)
2023
-
[45]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024)
work page internal anchor Pith review arXiv 2024
-
[46]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Team, K., Du, A., Yin, B., Xing, B., Qu, B., Wang, B., Chen, C., Zhang, C., Du, C., Wei, C., et al.: Kimi-vl technical report. arXiv preprint arXiv:2504.07491 (2025)
work page internal anchor Pith review arXiv 2025
-
[48]
Wang, D., Wang, S., Li, Z., Wang, Y., Li, Y., Tang, D., Shen, X., Huang, X., Wei, Z.: Moiie: Mixture of intra-and inter-modality experts for large vision language models. arXiv preprint arXiv:2508.09779 (2025)
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
arXiv preprint arXiv:2511.20520 (2025)
Wang, X., Zhang, Z., Zhang, H., Lin, Z., Zhou, Y., Liu, Q., Zhang, S., Li, Y., Liu, S., Zheng, H., et al.: Hbridge: H-shape bridging of heterogeneous experts for unified multimodal understanding and generation. arXiv preprint arXiv:2511.20520 (2025)
-
[51]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024) Symbiotic-MoE Supplementary Material 27
work page internal anchor Pith review arXiv 2024
-
[52]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Wu, C., Yin, S., Qi, W., Wang, X., Tang, Z., Duan, N.: Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671 (2023)
work page internal anchor Pith review arXiv 2023
-
[53]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, C., Chen, X., Wu, Z., Ma, Y., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C., et al.: Janus: Decoupling visual encoding for unified multimodal understanding and generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12966–12977 (2025)
2025
-
[54]
In: Forty-first International Conference on Machine Learning (2024)
Wu, S., Fei, H., Qu, L., Ji, W., Chua, T.S.: Next-gpt: Any-to-any multimodal llm. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[55]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
work page internal anchor Pith review arXiv 2023
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xiao, S., Wang, Y., Zhou, J., Yuan, H., Xing, X., Yan, R., Li, C., Wang, S., Huang, T., Liu, Z.: Omnigen: Unified image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13294–13304 (2025)
2025
-
[57]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. arXiv preprint arXiv:2408.12528 (2024)
work page internal anchor Pith review arXiv 2024
-
[58]
Xu,Y.,Yan,H.,Cao,J.,Cheng,Y.,Hang,T.,He,R.,Yin,Z.,Zhang,S.,Zhang,Y., Li, J., et al.: Tag-moe: Task-aware gating for unified generative mixture-of-experts. arXiv preprint arXiv:2601.08881 (2026)
-
[59]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
work page internal anchor Pith review arXiv 2023
-
[61]
Mm1.5: Methods, analysis & insights from multi- modal llm fine-tuning
Zhang, H., Gao, M., Gan, Z., Dufter, P., Wenzel, N., Huang, F., Shah, D., Du, X., Zhang, B., Li, Y., et al.: Mm1. 5: Methods, analysis & insights from multimodal llm fine-tuning. arXiv preprint arXiv:2409.20566 (2024)
-
[62]
arXiv preprint arXiv:2511.12113 (2025)
Zhang, L., Xie, Y., Fang, F., Dong, F., Liu, R., Cao, Y.: Metagdpo: Alleviating catastrophic forgetting with metacognitive knowledge through group direct pref- erence optimization. arXiv preprint arXiv:2511.12113 (2025)
-
[63]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[64]
arXiv e-prints pp
Zhang, Z., Dong, Q., Zhang, Q., Zhao, J., Zhou, E., Xi, Z., Jin, S., Fan, X., Zhou, Y., Fu, Y., et al.: Reinforcement fine-tuning enables mllms learning novel tasks stably. arXiv e-prints pp. arXiv–2506 (2025)
2025
-
[65]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., Levy, O.: Transfusion: Predict the next token and diffuse images with one multi-modal model. arXiv preprint arXiv:2408.11039 (2024)
work page internal anchor Pith review arXiv 2024
-
[66]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Zoph, B., Bello, I., Kumar, S., Du, N., Huang, Y., Dean, J., Shazeer, N., Fedus, W.: St-moe: Designing stable and transferable sparse expert models. arXiv preprint arXiv:2202.08906 (2022)
work page internal anchor Pith review arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.