Recognition: no theorem link
The Art of (Mis)alignment: How Fine-Tuning Methods Effectively Misalign and Realign LLMs in Post-Training
Pith reviewed 2026-05-10 18:14 UTC · model grok-4.3
The pith
Fine-tuning methods create an asymmetry where ORPO excels at misaligning LLMs and DPO at realigning them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
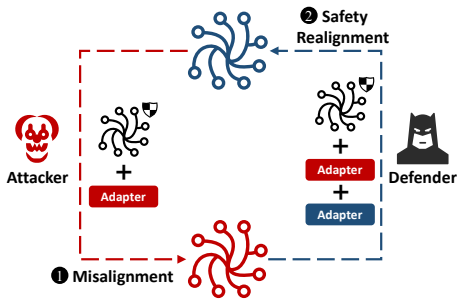
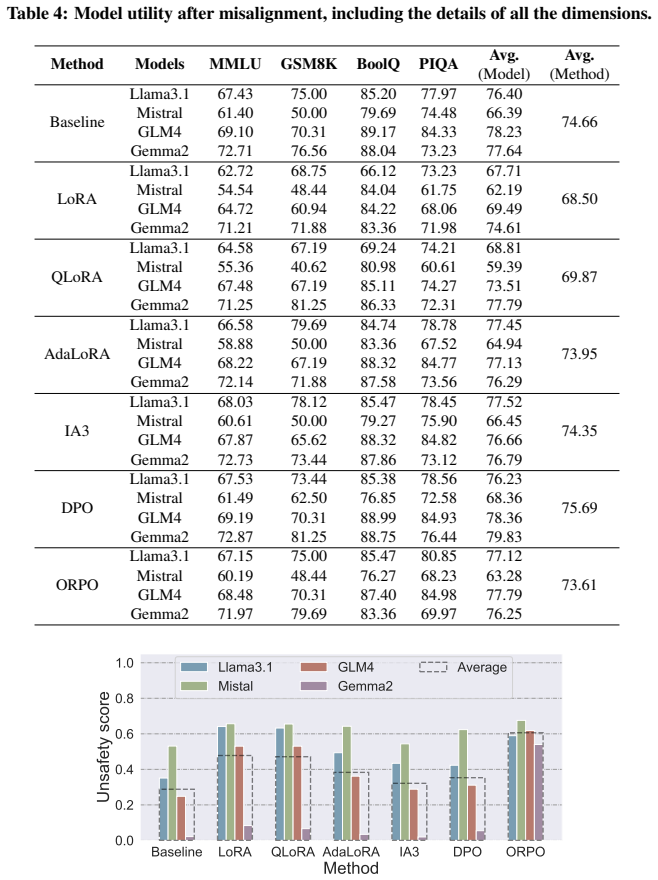
Evaluating four Supervised Fine-Tuning and two Preference Fine-Tuning methods across four safety-aligned LLMs reveals a mechanism asymmetry: Odds Ratio Preference Optimization proves most effective for misalignment, whereas Direct Preference Optimization excels in realignment but at the cost of model utility. The work further identifies model-specific resistance and residual effects from multi-round adversarial dynamics.
What carries the argument
The mechanism asymmetry between misalignment and realignment in post-training fine-tuning methods for LLMs.
If this is right
- ORPO can be used to create misaligned versions of safety-trained LLMs with high effectiveness.
- DPO can restore safety to misaligned models but reduces performance on unrelated tasks.
- Residual effects from prior misalignment rounds persist even after realignment.
- Different LLMs show varying degrees of resistance to both misalignment and realignment attempts.
Where Pith is reading between the lines
- Safety checks for third-party LLMs should include targeted tests against ORPO-based misalignment.
- Realigned models require separate evaluation of retained utility beyond safety metrics.
- Alignment strategies may need to be customized per model family due to observed resistance differences.
- The lingering effects of repeated adversarial fine-tuning suggest that alignment history should be tracked.
Load-bearing premise
The four supervised fine-tuning and two preference fine-tuning methods together with the four chosen LLMs are representative enough for the observed asymmetry and model-specific effects to hold more generally.
What would settle it
A follow-up experiment using different fine-tuning methods or additional LLMs that fails to reproduce ORPO as the strongest misaligner and DPO as the strongest realigner would falsify the asymmetry claim.
Figures















read the original abstract
The deployment of large language models (LLMs) raises significant ethical and safety concerns. While LLM alignment techniques are adopted to improve model safety and trustworthiness, adversaries can exploit these techniques to undermine safety for malicious purposes, resulting in \emph{misalignment}. Misaligned LLMs may be published on open platforms to magnify harm. To address this, additional safety alignment, referred to as \emph{realignment}, is necessary before deploying untrusted third-party LLMs. This study explores the efficacy of fine-tuning methods in terms of misalignment, realignment, and the effects of their interplay. By evaluating four Supervised Fine-Tuning (SFT) and two Preference Fine-Tuning (PFT) methods across four popular safety-aligned LLMs, we reveal a mechanism asymmetry between attack and defense. While Odds Ratio Preference Optimization (ORPO) is most effective for misalignment, Direct Preference Optimization (DPO) excels in realignment, albeit at the expense of model utility. Additionally, we identify model-specific resistance, residual effects of multi-round adversarial dynamics, and other noteworthy findings. These findings highlight the need for robust safeguards and customized safety alignment strategies to mitigate potential risks in the deployment of LLMs. Our code is available at https://github.com/zhangrui4041/The-Art-of-Mis-alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates four Supervised Fine-Tuning (SFT) and two Preference Fine-Tuning (PFT) methods across four safety-aligned LLMs to assess their efficacy in misalignment (via adversarial fine-tuning) and subsequent realignment. It reports a mechanism asymmetry in which ORPO is most effective for misalignment while DPO excels at realignment (at the cost of model utility), along with model-specific resistance to misalignment and residual effects from multi-round adversarial dynamics. Code is released for reproducibility.
Significance. If the empirical patterns hold under more rigorous controls, the work supplies actionable observations on asymmetries between attack and defense fine-tuning techniques, underscoring the need for method-specific safeguards and customized realignment protocols when handling untrusted third-party LLMs. The public code release is a clear strength that supports verification and follow-on research.
major comments (2)
- [Abstract and §3] Abstract and §3 (Evaluation Setup): the abstract summarizes key findings on ORPO/DPO asymmetry and model-specific effects but supplies no concrete metrics (e.g., harmfulness scores, refusal rates), baselines, statistical controls, or data-exclusion criteria. Without these details it is impossible to judge whether the reported superiority claims are supported by the experiments.
- [§4 and §5] §4 (Results) and §5 (Discussion): the central claim of a general 'mechanism asymmetry' rests on experiments with only four LLMs and six methods. The manuscript flags model-specific resistance yet offers no scaling argument, ablation across additional models/datasets, or theoretical derivation explaining why the ORPO-misalignment / DPO-realignment pattern should hold outside the chosen setup; this limits the load-bearing strength of the generalization.
minor comments (2)
- [Figures] Figure captions and axis labels in the results section should explicitly state the exact evaluation prompts and scoring rubrics used for misalignment and utility metrics.
- [Conclusion] The manuscript should add a limitations paragraph that quantifies the scope (four LLMs, six methods) and discusses potential dataset-specific artifacts.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important areas for improving clarity and the strength of our claims. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Evaluation Setup): the abstract summarizes key findings on ORPO/DPO asymmetry and model-specific effects but supplies no concrete metrics (e.g., harmfulness scores, refusal rates), baselines, statistical controls, or data-exclusion criteria. Without these details it is impossible to judge whether the reported superiority claims are supported by the experiments.
Authors: We agree that the abstract would be strengthened by including key quantitative indicators. Due to length constraints, the abstract provides a high-level summary of the asymmetry and model-specific effects, while concrete metrics (harmfulness scores, refusal rates) and comparisons appear in §4 tables and figures. In §3 we describe the four LLMs, six methods, and datasets (including HarmfulQA and BeaverTails variants), but we will revise §3 to explicitly list baselines (e.g., zero-shot and SFT-only controls), statistical controls (standard deviations over three random seeds), and data-exclusion criteria (e.g., filtering prompts with >0.9 toxicity pre-score). These additions will make the superiority claims directly verifiable from the evaluation setup. revision: partial
-
Referee: [§4 and §5] §4 (Results) and §5 (Discussion): the central claim of a general 'mechanism asymmetry' rests on experiments with only four LLMs and six methods. The manuscript flags model-specific resistance yet offers no scaling argument, ablation across additional models/datasets, or theoretical derivation explaining why the ORPO-misalignment / DPO-realignment pattern should hold outside the chosen setup; this limits the load-bearing strength of the generalization.
Authors: We acknowledge the limited scope (four LLMs, six methods) and do not claim the asymmetry is universal. The paper already flags model-specific resistance as an empirical observation rather than a general law. We will expand §5 with a dedicated limitations subsection that (a) explicitly states the absence of scaling experiments or theoretical derivation, (b) calls for future ablations on additional models and datasets, and (c) notes that the released code enables such extensions. Because the work is empirical, we cannot supply a theoretical derivation; we therefore frame the reported asymmetry as a reproducible pattern within the tested regime that motivates method-specific safeguards, without asserting broader validity. revision: partial
Circularity Check
Empirical evaluation with no derivation chain or fitted predictions
full rationale
The paper conducts a purely experimental comparison of four SFT and two PFT methods across four LLMs, reporting observed effectiveness for misalignment (ORPO strongest) and realignment (DPO strongest, with utility trade-off) plus model-specific effects. No equations, derivations, or parameter-fitting steps are present in the provided text; results are framed as direct experimental outcomes rather than predictions derived from the methods themselves. No self-citations are invoked as load-bearing premises for any claimed mechanism, and the work does not rename known results or smuggle ansatzes. The derivation chain is therefore empty, and the study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Ka- davath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nel- son Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tris- tan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Ol...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Piqa: Reasoning about physical common- sense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical common- sense in natural language. InAAAI Conference on Artificial Intelligence (AAAI). AAAI, 2020. 3, 15, 16
2020
-
[5]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learn- ing from human feedback.CoRR abs/2307.15217, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[6]
Comprehen- sive Assessment of Jailbreak Attacks Against LLMs
Junjie Chu, Yugeng Liu, Ziqing Yang, Xinyue Shen, Michael Backes, and Yang Zhang. Comprehensive assessment of jail- break attacks against llms.CoRR abs/2402.05668, 2024. 15
-
[7]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. InConference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies (NAACL-HLT), pages 2924–2936. ACL,
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems.CoRR abs/2110.14168, 2021. 3, 15
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Opencompass: A universal eval- uation platform for foundation models.https://github.c om/open-compass/opencompass, 2023
OpenCompass Contributors. Opencompass: A universal eval- uation platform for foundation models.https://github.c om/open-compass/opencompass, 2023. 3
2023
-
[10]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback.CoRR abs/2310.12773, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[11]
Safe rlhf: Safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback. InIn- ternational Conference on Learning Representations (ICLR),
-
[12]
A Real-World Incident from Mithril Security.https://blog.mithrilsecurity.io/po isongpt-how-we-hid-a-lobotomized-llm-on-huggin g-face-to-spread-fake-news/, 2023
Jade Hardouin Daniel Huynh. A Real-World Incident from Mithril Security.https://blog.mithrilsecurity.io/po isongpt-how-we-hid-a-lobotomized-llm-on-huggin g-face-to-spread-fake-news/, 2023. 1
2023
-
[13]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient Finetuning of Quantized LLMs.CoRR abs/2305.14314, 2023. 2, 11
work page internal anchor Pith review arXiv 2023
-
[14]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenen- baum, and Igor Mordatch. Improving factuality and reason- ing in language models through multiagent debate.CoRR abs/2305.14325, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[15]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.CoRR abs/2407.21783, 2024. 2, 3, 11, 14, 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
European Commission. Proposal for a regulation of the euro- pean parliament and of the council laying down harmonised rules on artificial intelligence (artificial intelligence act) and amending certain union legislative acts.https://eur- lex.europa.eu/legal-content/EN/TXT/?uri=CELEX: 52021PC0206, 2021. 2
2021
-
[17]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Han- lin Zhao, et al. Chatglm: A family of large language mod- els from glm-130b to glm-4 all tools.CoRR abs/2406.12793,
work page internal anchor Pith review arXiv
-
[18]
Safety misalignment against large language models
Yichen Gong, Delong Ran, Xinlei He, Tianshuo Cong, Anyu Wang, and Xiaoyun Wang. Safety misalignment against large language models. InNetwork and Distributed System Security Symposium (NDSS), 2025. 1, 11, 13
2025
-
[19]
FigStep: Jailbreaking Large Vision- language Models via Typographic Visual Prompts
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tian- shuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. Fig- Step: Jailbreaking Large Vision-language Models via Typo- graphic Visual Prompts.CoRR abs/2311.05608, 2023. 3
-
[20]
arXiv preprint arXiv:2406.20053 , year=
Danny Halawi, Alexander Wei, Eric Wallace, Tony T Wang, Nika Haghtalab, and Jacob Steinhardt. Covert malicious fine- tuning: Challenges in safeguarding llm adaptation.CoRR abs/2406.20053, 2024. 11
-
[21]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.CoRR abs/2403.14608, 2024. 11
work page internal anchor Pith review arXiv 2024
-
[22]
Measur- ing Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measur- ing Massive Multitask Language Understanding. InInterna- tional Conference on Learning Representations (ICLR), 2021. 3, 15 8
2021
-
[23]
Orpo: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. InConfer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 11170–11189. ACL, 2024. 1, 2, 12
2024
-
[24]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations (ICLR), 2022. 1, 2, 11
2022
-
[25]
Qiang Hu, Xiaofei Xie, Sen Chen, and Lei Ma. Large lan- guage model supply chain: Open problems from the security perspective.CoRR abs/2411.01604, 2024. 1
-
[26]
Kaifeng Huang, Bihuan Chen, You Lu, Susheng Wu, Dingji Wang, Yiheng Huang, Haowen Jiang, Zhuotong Zhou, Jun- ming Cao, and Xin Peng. Lifting the veil on the large lan- guage model supply chain: Composition, risks, and mitiga- tions.CoRR abs/2410.21218, 2024. 1
-
[27]
Harmful Fine-tuning Attacks and Defenses for Large Language Models: A Survey
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, and Ling Liu. Harmful fine-tuning attacks and defenses for large language models: A survey.CoRR abs/2409.18169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yix- uan Zhang, Xiner Li, Hanchi Sun, Zhengliang Liu, Yixin Liu, Yijue Wang, Zhikun Zhang, Bertie Vidgen, Bhavya Kailkhura, Caiming Xiong, Chaowei Xiao, Chunyuan Li, Eric P. Xing, Furong Huang, Hao Liu, Heng Ji, Hongyi Wang, Huan Zhang, Huaxiu Yao, Ma...
2024
-
[29]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.CoRR abs/2410.21276, 2024. 11, 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Beavertails: Towards improved safety align- ment of llm via a human-preference dataset
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety align- ment of llm via a human-preference dataset. InAnnual Con- ference on Neural Information Processing Systems (NeurIPS). NeurIPS, 2024. 11
2024
-
[31]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, élio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Tim- othée Lacroix, and William El Sayed. Mistral 7B.CoRR abs/2310.06825, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Modscan: Measuring stereotypical bias in large vision-language models from vision and language modalities
Yukun Jiang, Zheng Li, Xinyue Shen, Yugeng Liu, Michael Backes, and Yang Zhang. Modscan: Measuring stereotypical bias in large vision-language models from vision and language modalities. InEmpirical Methods in Natural Language Pro- cessing (EMNLP), 2024. 15
2024
-
[33]
Geon-Hyeong Kim, Youngsoo Jang, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, and Moontae Lee. Safedpo: A simple approach to direct preference optimization with enhanced safety.CoRR abs/2505.20065, 2025. 7
-
[34]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- ceedings of the Symposium on Operating Systems Principles (SOSP). ACM, 2023. 3
2023
-
[35]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Mi- randa, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.CoRR abs/2411.15124, 2024. 11
work page internal anchor Pith review arXiv 2024
-
[36]
Rlaif vs
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mes- nard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. InInternational Conference on Machine Learning (ICML), 2024. 1
2024
-
[37]
arXiv:2402.05044 (2024), https://arxiv.org/abs/2402.05044
Lijun Li, Bowen Dong, Ruohui Wang, Xuhao Hu, Wangmeng Zuo, Dahua Lin, Yu Qiao, and Jing Shao. Salad-bench: A hi- erarchical and comprehensive safety benchmark for large lan- guage models.CoRR abs/2402.05044, 2024. 15
-
[38]
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning. InAnnual Conference on Neural Infor- mation Processing Systems (NeurIPS). NeurIPS, 2022. 1, 2, 12
2022
-
[39]
Lu, S., Wang, Y ., Sheng, L., He, L., Zheng, A., and Liang, J
Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo Hao Cheng, Yegor Klochkov, Muham- mad Faaiz Taufiq, and Hang Li. Trustworthy llms: A sur- vey and guideline for evaluating large language models’ align- ment.CoRR abs/2308.05374, 2023. 1
-
[40]
Peft: State-of- the-art parameter-efficient fine-tuning methods.https://gi thub.com/huggingface/peft, 2022
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of- the-art parameter-efficient fine-tuning methods.https://gi thub.com/huggingface/peft, 2022. 11, 14
2022
-
[41]
Interpreting gpt: the logit lens.https://ww w.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpre tinggpt-the-logit-lens, 2020
Nostalgebraist. Interpreting gpt: the logit lens.https://ww w.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpre tinggpt-the-logit-lens, 2020. 6
2020
-
[42]
Gpt-4o mini: advancing cost-efficient intelligence
OpenAI. Gpt-4o mini: advancing cost-efficient intelligence. https://openai.com/index/gpt-4o-mini-advancing- cost-efficient-intelligence/, 2024. 3, 15
2024
-
[43]
OpenAI Usage policies.https://openai.com/p olicies/usage-policies, 2025
OpenAI. OpenAI Usage policies.https://openai.com/p olicies/usage-policies, 2025. 13
2025
-
[44]
The effects of reward misspecification: Mapping and mitigating misaligned models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The ef- fects of reward misspecification: Mapping and mitigating mis- aligned models.CoRR abs/2201.03544, 2022. 1
-
[45]
Samuele Poppi, Zheng-Xin Yong, Yifei He, Bobbie Chern, Han Zhao, Aobo Yang, and Jianfeng Chi. Towards under- standing the fragility of multilingual llms against fine-tuning attacks.CoRR abs/2410.18210, 2024. 11
-
[46]
Safety alignment should be made more than just 9 a few tokens deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just 9 a few tokens deep. InInternational Conference on Learning Representations (ICLR), 2025. 3
2025
-
[47]
Fine-tuning aligned lan- guage models compromises safety, even when users do not intend to! InInternational Conference on Learning Repre- sentations (ICLR), 2024
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned lan- guage models compromises safety, even when users do not intend to! InInternational Conference on Learning Repre- sentations (ICLR), 2024. 3, 11
2024
-
[48]
Direct prefer- ence optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct prefer- ence optimization: Your language model is secretly a reward model. InAnnual Conference on Neural Information Process- ing Systems (NeurIPS). NeurIPS, 2024. 1, 2, 11, 12
2024
-
[49]
XSTest: A Test Suite for Identifying Exag- gerated Safety Behaviours in Large Language Models
Paul Röttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe At- tanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models.CoRR abs/2308.01263, 2023. 3
-
[50]
Ahmed Salem, Michael Backes, and Yang Zhang. Don’t Trig- ger Me! A Triggerless Backdoor Attack Against Deep Neural Networks.CoRR abs/2010.03282, 2020. 1
-
[51]
Do Anything Now: Characterizing and Evaluat- ing In-The-Wild Jailbreak Prompts on Large Language Mod- els
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. Do Anything Now: Characterizing and Evaluat- ing In-The-Wild Jailbreak Prompts on Large Language Mod- els. InACM SIGSAC Conference on Computer and Commu- nications Security (CCS). ACM, 2024. 2, 13
2024
-
[52]
Backdoor Attacks in the Supply Chain of Masked Image Modeling.CoRR abs/2210.01632,
Xinyue Shen, Xinlei He, Zheng Li, Yun Shen, Michael Backes, and Yang Zhang. Backdoor Attacks in the Supply Chain of Masked Image Modeling.CoRR abs/2210.01632,
-
[53]
Stable diffusion v2.1 and dreamstudio updates
Stability AI. Stable diffusion v2.1 and dreamstudio updates. https://stability.ai/news/stablediffusion2-1- release7-dec-2022, 2022. 4
2022
-
[54]
Principle-driven self-alignment of language models from scratch with minimal human supervision.Advances in Neural Information Processing Systems, 36, 2024
Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. Principle-driven self-alignment of language models from scratch with minimal human supervision.Advances in Neural Information Processing Systems, 36, 2024. 1
2024
-
[55]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupati- raju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.CoRR abs/2408.00118, 2024. 2, 11, 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Meta llama guard 2.https://github.com/m eta-llama/PurpleLlama/blob/main/Llama-Guard2/MOD EL_CARD.md, 2024
Llama Team. Meta llama guard 2.https://github.com/m eta-llama/PurpleLlama/blob/main/Llama-Guard2/MOD EL_CARD.md, 2024. 3, 15
2024
-
[57]
Autotrain: No-code training for state-of- the-art models
Abhishek Thakur. Autotrain: No-code training for state-of- the-art models. InConference on Empirical Methods in Nat- ural Language Processing (EMNLP), pages 419–423. ACL,
-
[58]
A pro-innovation approach to ai regulation: Policy paper.http s://www.gov.uk/government/publications/a-pro- innovation-approach-to-ai-regulation, 2023
UK Department for Science, Innovation and Technology. A pro-innovation approach to ai regulation: Policy paper.http s://www.gov.uk/government/publications/a-pro- innovation-approach-to-ai-regulation, 2023. 2
2023
-
[59]
Luping Wang, Sheng Chen, Linnan Jiang, Shu Pan, Runze Cai, Sen Yang, and Fei Yang. Parameter-efficient fine- tuning in large models: A survey of methodologies.CoRR abs/2410.19878, 2024. 11
-
[60]
Do-Not-Answer: A Dataset for Evaluating Safeguards in LLMs
Yuxia Wang, Haonan Li, Xudong Han, Preslav Nakov, and Timothy Baldwin. Do-not-answer: A dataset for evaluating safeguards in llms.CoRR abs/2308.13387, 2023. 3
-
[61]
Reinforcement Learning for LLM Post-Training: A Survey
Zhichao Wang, Bin Bi, Shiva Kumar Pentyala, Kiran Ram- nath, Sougata Chaudhuri, Shubham Mehrotra, Xiang-Bo Mao, Sitaram Asur, et al. A comprehensive survey of llm align- ment techniques: Rlhf, rlaif, ppo, dpo and more.CoRR abs/2407.16216, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Pet- zold, William Yang Wang, Xun Zhao, and Dahua Lin
Xianjun Yang, Xiao Wang, Qi Zhang, Linda Petzold, William Yang Wang, Xun Zhao, and Dahua Lin. Shadow alignment: The ease of subverting safely-aligned language models.CoRR abs/2310.02949, 2023. 11, 18
-
[63]
GPTFUZZER: Red Teaming Large Language Mod- els with Auto-Generated Jailbreak Prompts
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. GPT- FUZZER: Red Teaming Large Language Models with Auto- Generated Jailbreak Prompts.CoRR abs/2309.10253, 2023. 11
-
[64]
Badmerging: Backdoor attacks against model merging
Jinghuai Zhang, Jianfeng Chi, Zheng Li, Kunlin Cai, Yang Zhang, and Yuan Tian. Badmerging: Backdoor attacks against model merging. InACM SIGSAC Conference on Computer and Communications Security (CCS), 2024. 1
2024
-
[65]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter- efficient fine-tuning.CoRR abs/2303.10512, 2023. 1, 2, 11
work page internal anchor Pith review arXiv 2023
-
[66]
Instruction backdoor attacks against customized{LLMs}
Rui Zhang, Hongwei Li, Rui Wen, Wenbo Jiang, Yuan Zhang, Michael Backes, Yun Shen, and Yang Zhang. Instruction backdoor attacks against customized{LLMs}. InUSENIX Security Symposium (USENIX Security), pages 1849–1866. USENIX, 2024. 1
2024
-
[67]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.CoRR abs/2506.05176, 2025. 20
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. CoRR abs/1909.08593, 2019. 12
work page internal anchor Pith review arXiv 1909
-
[69]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and Transferable Adversarial Attacks on Aligned Language Models.CoRR abs/2307.15043, 2023. 3 10 A Related Work A.1 LLM Safety Measures Most modern LLMs adopt multiple measures to enhance safety during development [15,17,30,35,55]. In the pre-training phases, data cleaning and filtering a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.