Recognition: unknown
Data Selection for Multi-turn Dialogue Instruction Tuning
Pith reviewed 2026-05-10 16:49 UTC · model grok-4.3
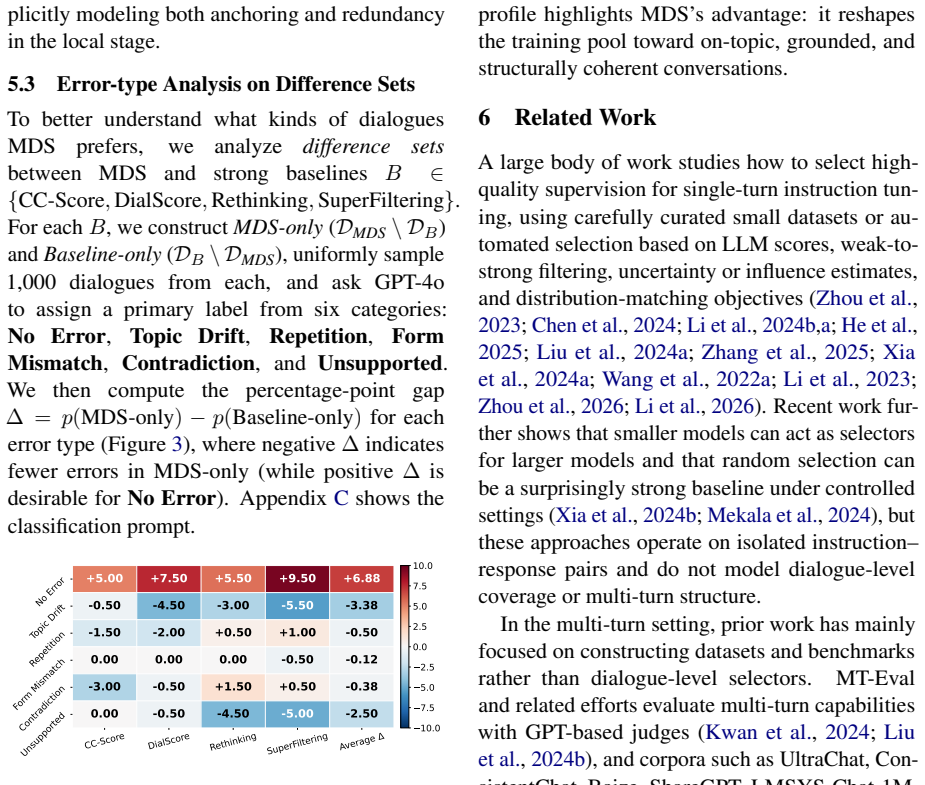
The pith
A two-stage selector for entire multi-turn dialogues produces stronger instruction-tuned models than turn-by-turn or heuristic methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MDS scores complete dialogues rather than separate turns by combining a global stage that performs bin-wise selection in user-query trajectory space to retain representative non-redundant examples with a local stage that assesses entity-grounded topic reliability, information progress, and query-answer form consistency to ensure structural soundness.
What carries the argument
MDS, a dialogue-level selection framework that applies global bin-wise coverage in query trajectory space followed by local checks on topic grounding, information progress, and form consistency.
Load-bearing premise
The global and local scoring rules actually pick dialogues that produce better instruction-tuned models rather than just matching the chosen evaluation metrics.
What would settle it
Train identical base models on the same corpus filtered by MDS versus by single-turn selectors or random sampling, then measure differences in performance on held-out multi-turn benchmarks and long-conversation subsets.
Figures





read the original abstract
Instruction-tuned language models increasingly rely on large multi-turn dialogue corpora, but these datasets are often noisy and structurally inconsistent, with topic drift, repetitive chitchat, and mismatched answer formats across turns. We address this from a data selection perspective and propose \textbf{MDS} (Multi-turn Dialogue Selection), a dialogue-level framework that scores whole conversations rather than isolated turns. MDS combines a global coverage stage that performs bin-wise selection in the user-query trajectory space to retain representative yet non-redundant dialogues, with a local structural stage that evaluates within-dialogue reliability through entity-grounded topic grounding and information progress, together with query-answer form consistency for functional alignment. MDS outperforms strong single-turn selectors, dialogue-level LLM scorers, and heuristic baselines on three multi-turn benchmarks and an in-domain Banking test set, achieving the best overall rank across reference-free and reference-based metrics, and is more robust on long conversations under the same training budget. Code and resources are included in the supplementary materials.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MDS, a two-stage dialogue-level data selection framework for multi-turn instruction tuning. A global coverage stage performs bin-wise selection over user-query trajectories to retain representative, non-redundant dialogues; a local structural stage then scores each dialogue for entity-grounded topic grounding, information progress, and query-answer form consistency. The method is claimed to outperform single-turn selectors, dialogue-level LLM scorers, and heuristic baselines on three multi-turn benchmarks plus an in-domain Banking test set, achieving the best overall rank across reference-free and reference-based metrics while showing greater robustness on long conversations under fixed training budgets. Code and resources are provided.
Significance. If the reported gains are shown to be causally attributable to the proposed scoring stages rather than correlated data properties, the work would offer a practical, reproducible method for improving data quality in dialogue model training. This could reduce reliance on noisy corpora and improve efficiency, particularly for long-context or domain-specific applications. The inclusion of code strengthens the contribution by supporting direct replication and extension.
major comments (2)
- [Experiments] Experiments section: the central claim that dialogues retained by the two-stage MDS process yield measurably stronger instruction-tuned models requires component ablations or controls that isolate the global bin-wise coverage and each local criterion (entity grounding, information progress, form consistency) from incidental factors such as dialogue length distribution or topic diversity; without these, the outperformance on the three benchmarks and Banking set cannot be confidently attributed to the proposed scoring rather than metric alignment or other data characteristics.
- [Method] Method section (global coverage stage): the definition of the user-query trajectory space and the exact binning procedure (including feature representation and selection thresholds) are not specified in sufficient detail to allow reproduction or to verify that the stage is parameter-free as implied; this directly affects the load-bearing claim of representative yet non-redundant selection.
minor comments (2)
- [Abstract] Abstract and results tables: exact numerical values for the reference-free and reference-based metrics, together with standard deviations or significance tests, should be reported rather than only qualitative statements of 'best overall rank' and 'outperformance'.
- [Method] The description of the local structural stage scoring functions would benefit from explicit equations or pseudocode showing how entity grounding, information progress, and form consistency are quantified and combined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the attribution of results and the reproducibility of the method. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that dialogues retained by the two-stage MDS process yield measurably stronger instruction-tuned models requires component ablations or controls that isolate the global bin-wise coverage and each local criterion (entity grounding, information progress, form consistency) from incidental factors such as dialogue length distribution or topic diversity; without these, the outperformance on the three benchmarks and Banking set cannot be confidently attributed to the proposed scoring rather than metric alignment or other data characteristics.
Authors: We agree that dedicated component ablations are necessary to isolate the contributions of the global bin-wise coverage stage and each local criterion (entity grounding, information progress, and form consistency) while controlling for potential confounds such as dialogue length and topic diversity. Our existing experiments compare MDS against multiple strong baselines (single-turn selectors, dialogue-level LLM scorers, and heuristics), which provide indirect evidence of the two-stage design's value. However, to directly address the concern, we will add explicit ablations in the revised Experiments section: (1) a version using only the global stage with random or length-matched selection within bins, (2) versions ablating each local criterion individually while retaining the others, and (3) stratified controls that match length and diversity distributions across compared sets. These will be evaluated on the same benchmarks to better attribute performance gains to the proposed scoring components. revision: yes
-
Referee: [Method] Method section (global coverage stage): the definition of the user-query trajectory space and the exact binning procedure (including feature representation and selection thresholds) are not specified in sufficient detail to allow reproduction or to verify that the stage is parameter-free as implied; this directly affects the load-bearing claim of representative yet non-redundant selection.
Authors: We acknowledge that the current description of the global coverage stage is high-level and lacks the precise implementation details needed for full reproducibility. We will revise the Method section to explicitly define the user-query trajectory space as the sequence of user queries embedded via a fixed sentence encoder (e.g., all-MiniLM-L6-v2), describe the binning procedure (including the feature representation combining trajectory length, topic entropy, and embedding centroids, the number of bins, and the within-bin selection rule based on local structural scores), and clarify any thresholds or parameters. This expansion will confirm the stage's design and support the claim of representative yet non-redundant selection while enabling direct replication. revision: yes
Circularity Check
No circularity: algorithmic heuristic with explicit stages evaluated empirically
full rationale
The paper presents MDS as a two-stage algorithmic procedure (global bin-wise selection over user-query trajectories plus local checks for entity grounding, information progress, and form consistency) without any equations, fitted parameters, or derivations. Outperformance is asserted via direct comparison on benchmarks rather than by reducing a 'prediction' to the selection criteria themselves. No self-citation chains or uniqueness theorems are invoked to justify the method; the stages are defined directly and tested for robustness. This is a standard non-circular proposal of a data-selection heuristic.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Instruction Data Selection via Answer Divergence
ADG selects 10K instruction examples by scoring the geometric divergence of multiple high-temperature model outputs in embedding space, outperforming prior selectors on reasoning, knowledge, and coding benchmarks acro...
-
Beyond Semantic Relevance: Counterfactual Risk Minimization for Robust Retrieval-Augmented Generation
CoRM-RAG uses a cognitive perturbation protocol to simulate biases and trains an Evidence Critic to retrieve documents that support correct decisions even under adversarial query changes.
-
Chain of Evidence: Pixel-Level Visual Attribution for Iterative Retrieval-Augmented Generation
CoE applies vision-language models directly to document screenshots to deliver pixel-level bounding-box attribution for evidence in iterative retrieval-augmented generation, outperforming text baselines on visual-layo...
Reference graph
Works this paper leans on
-
[1]
Alpagasus: Training a better alpaca with fewer data. InThe Twelfth International Conference on Learning Representations. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. Enhancing chat language models by scaling high-quality instructional conversations. InProceedings of the 2023 Conference on Empiri...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Instruction Data Selection via Answer Divergence
Instruction data selection via answer diver- gence.Preprint, arXiv:2604.10448. Ming Li, Yong Zhang, Shwai He, Zhitao Li, Hongyu Zhao, Jianzong Wang, Ning Cheng, and Tianyi Zhou. 2024a. Superfiltering: Weak-to-strong data filtering for fast instruction-tuning.arXiv preprint arXiv:2402.00530. Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning C...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Yaoyiran Li, Anna Korhonen, and Ivan Vuli ´c
One shot learning as instruction data prospec- tor for large language models. InAnnual Meeting of the Association for Computational Linguistics. Yen-Ting Lin and Yun-Nung Chen. 2023. Llm-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language mod- els.arXiv preprint arXiv:2305.13711. Liangxin Liu, Xuebo Liu, ...
-
[4]
Baize: An open-source chat model with parameter-efficient tuning on self-chat data
Baize: An open-source chat model with parameter-efficient tuning on self-chat data.arXiv preprint arXiv:2304.01196. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxuand Lv, and others
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Mingjia Yin, Chuhan Wu, Yufei Wang, Hao Wang, Wei Guo, Yasheng Wang, Yong Liu, Ruiming Tang, Defu Lian, and Enhong Chen. 2024. Entropy law: The story behind data compression and llm performance. ArXiv, abs/2407.06645. Dylan Zhang, Qirun Dai, and Hao Peng. 2025. The best instruction-tuning data are th...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.