Recognition: unknown
Chain of Evidence: Pixel-Level Visual Attribution for Iterative Retrieval-Augmented Generation
Pith reviewed 2026-05-09 14:42 UTC · model grok-4.3
The pith
Vision-language models can deliver pixel-level visual evidence chains for iterative retrieval-augmented generation by operating directly on document screenshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Chain of Evidence is a retriever-agnostic framework in which a vision-language model reasons over raw document screenshots to output precise bounding boxes that visualize the complete chain of evidence supporting an answer to a complex question.
What carries the argument
Chain of Evidence (CoE), a retriever-agnostic visual attribution framework that leverages vision-language models to reason directly over screenshots and generate pixel-level bounding-box outputs.
If this is right
- The framework removes dependence on format-specific parsing tools for documents such as PDFs or slides.
- Users receive visual traces that show exactly which image regions support each step of the reasoning chain.
- Performance gains appear on tasks involving free-form layouts and complex diagrams where text conversion discards key cues.
- The method remains independent of whichever retriever supplies the candidate documents.
Where Pith is reading between the lines
- This approach could extend naturally to other image-rich sources such as scientific figures or scanned legal documents without new parsers.
- Widespread use might reduce the frequency of reasoning errors that arise from missing spatial relationships in text-only pipelines.
- The same screenshot-based attribution could be tested on video frames to handle dynamic evidence chains.
Load-bearing premise
Vision-language models applied to raw document screenshots can reliably recover the spatial logic and layout cues that are discarded when converting documents to text.
What would settle it
Run the model on SlideVQA screenshots that contain diagrams whose layout is essential to the correct answer; if the output bounding boxes fail to highlight the specific visual regions that supply the necessary spatial information, the central claim is falsified.
Figures




read the original abstract
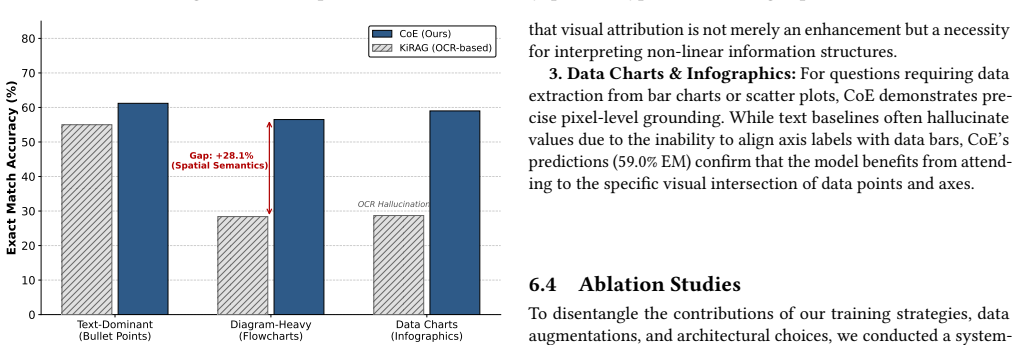
Iterative Retrieval-Augmented Generation (iRAG) has emerged as a powerful paradigm for answering complex multi-hop questions by progressively retrieving and reasoning over external documents. However, current systems predominantly operate on parsed text, which creates two critical bottlenecks: (1) \textit{Coarse-grained attribution}, where users are burdened with manually locating evidence within lengthy documents based on vague text-level citations; and (2) \textit{Visual semantic loss}, where the conversion of visually rich documents (e.g., slides, PDFs with charts) into text discards spatial logic and layout cues essential for reasoning. To bridge this gap, we present \textbf{Chain of Evidence (CoE)}, a retriever-agnostic visual attribution framework that leverages Vision-Language Models to reason directly over screenshots of retrieved document candidates. CoE eliminates format-specific parsing and outputs precise bounding boxes, visualizing the complete reasoning chain within the retrieved candidate set. We evaluate CoE on two distinct benchmarks: \textbf{Wiki-CoE}, a large-scale dataset of structured web pages derived from 2WikiMultiHopQA, and \textbf{SlideVQA}, a challenging dataset of presentation slides featuring complex diagrams and free-form layouts. Experiments demonstrate that fine-tuned Qwen3-VL-8B-Instruct achieves robust performance, significantly outperforming text-based baselines in scenarios requiring visual layout understanding, while establishing a retriever-agnostic solution for pixel-level interpretable iRAG. Our code is available at https://github.com/PeiYangLiu/CoE.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Chain of Evidence (CoE), a retriever-agnostic visual attribution framework for iterative Retrieval-Augmented Generation (iRAG). It uses Vision-Language Models to directly process screenshots of retrieved document candidates, outputting precise bounding boxes for evidence rather than relying on parsed text. This addresses two bottlenecks in existing systems: coarse-grained attribution and visual semantic loss from text conversion of rich documents like slides and PDFs. The framework is evaluated on two new benchmarks—Wiki-CoE (structured web pages derived from 2WikiMultiHopQA) and SlideVQA (complex slide layouts with diagrams)—with the central result that fine-tuned Qwen3-VL-8B-Instruct achieves robust performance and significantly outperforms text-based baselines in scenarios requiring visual layout understanding, while providing pixel-level interpretable iRAG. Code is released at a GitHub repository.
Significance. If the empirical results hold with adequate verification, this could be a meaningful contribution to multimodal RAG and visual document reasoning. Preserving spatial and layout cues via direct screenshot processing offers a practical alternative to format-specific parsers, improving both accuracy and interpretability for complex documents. The retriever-agnostic design and pixel-level bounding box outputs enhance usability in iRAG pipelines. Introducing two distinct benchmarks adds reusable resources for the community, and the open code supports reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that 'fine-tuned Qwen3-VL-8B-Instruct achieves robust performance, significantly outperforming text-based baselines' is presented without any quantitative metrics, error bars, ablation studies, or specific performance numbers. This omission in the abstract, combined with unavailable full methods and data splits, makes the load-bearing empirical result difficult to assess or verify at the level required for a serious journal.
- [Evaluation] Evaluation section (implied by benchmark descriptions): The paper positions the VLM-on-screenshot approach as reliably recovering spatial logic and layout cues without format-specific parsing or extra supervision, but provides no ablations or failure-case analysis on when this assumption breaks (e.g., for low-contrast slides or dense charts). This is load-bearing for the claim of retriever-agnostic robustness on SlideVQA.
minor comments (2)
- [Benchmarks] Ensure all benchmark construction details, including data splits and annotation protocols for Wiki-CoE and SlideVQA, are fully documented in the main text or appendix to support reproducibility.
- [Abstract and Introduction] The abstract and introduction use 'CoE' for both the framework and the Wiki-CoE benchmark; clarify the distinction in notation to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation. We address each major comment below and will incorporate revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'fine-tuned Qwen3-VL-8B-Instruct achieves robust performance, significantly outperforming text-based baselines' is presented without any quantitative metrics, error bars, ablation studies, or specific performance numbers. This omission in the abstract, combined with unavailable full methods and data splits, makes the load-bearing empirical result difficult to assess or verify at the level required for a serious journal.
Authors: We agree that the abstract would benefit from including key quantitative metrics to better support the central claim. The full manuscript details the experimental setup, methods, and data splits in Sections 3 and 4, with all code and datasets released at the provided GitHub repository for verification. The Experiments section contains performance tables with specific metrics, standard deviations across runs, and baseline comparisons. In the revised manuscript, we will update the abstract to incorporate representative quantitative results (e.g., accuracy gains on Wiki-CoE and SlideVQA) while maintaining conciseness. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by benchmark descriptions): The paper positions the VLM-on-screenshot approach as reliably recovering spatial logic and layout cues without format-specific parsing or extra supervision, but provides no ablations or failure-case analysis on when this assumption breaks (e.g., for low-contrast slides or dense charts). This is load-bearing for the claim of retriever-agnostic robustness on SlideVQA.
Authors: We acknowledge that explicit ablations and failure-case analysis would further substantiate the robustness claims, particularly for challenging cases on SlideVQA. The current evaluation demonstrates consistent outperformance on visual-layout tasks through direct screenshot processing, but does not include dedicated breakdowns for edge cases such as low-contrast elements or dense charts. In the revision, we will add a new subsection to the evaluation discussing limitations and providing qualitative examples of failure modes, along with expanded comparisons to support the retriever-agnostic design. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an applied engineering system (CoE) that applies a fine-tuned VLM directly to document screenshots for bounding-box attribution in iRAG. All load-bearing claims rest on empirical results from two held-out benchmarks (Wiki-CoE derived from 2WikiMultiHopQA and SlideVQA) rather than any derivation, equation, or fitted quantity that reduces to its own inputs. No self-definitional loops, predictions that are statistically forced by construction, or load-bearing self-citations appear in the abstract or method outline. The retriever-agnostic positioning and visual-layout recovery are presented as independent contributions evaluated externally to the training data, rendering the reported performance self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can identify and localize supporting evidence regions in document screenshots at pixel level without format-specific parsing
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Lameck Mbangula Amugongo, Pietro Mascheroni, Steven Brooks, Stefan Doering, and Jan Seidel. 2025. Retrieval augmented generation for large language models in healthcare: A systematic review.PLOS Digital Health4, 6 (2025), e0000877
2025
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum? id=hSyW5go0v8
2024
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Bernd Bohnet, Vinh Q Tran, Pat Verga, Roee Aharoni, Daniel Andor, Livio Baldini Soares, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev, Jonathan Herzig, et al. 2022. Attributed question answering: Evaluation and modeling for attributed large language models.arXiv preprint arXiv:2212.08037(2022)
- [6]
-
[7]
2003.HTML for the world wide web
Elizabeth Castro. 2003.HTML for the world wide web. Peachpit Press
2003
-
[8]
Bhanu Chander, Chinju John, Lekha Warrier, and Kumaravelan Gopalakrish- nan. 2025. Toward trustworthy artificial intelligence (TAI) in the context of explainability and robustness.Comput. Surveys57, 6 (2025), 1–49
2025
-
[9]
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. 2026. INTENT: Invariance and Discrimination-aware Noise Miti- gation for Robust Composed Image Retrieval. InFortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Ar- tificial Intelligence, Sixteenth Symposium on Edu...
-
[10]
2011.Html & Css
Jon Duckett and Jens Schlüter. 2011.Html & Css. Wiley
2011
-
[11]
Jinyuan Fang, Zaiqiao Meng, and Craig MacDonald. 2025. KiRAG: Knowledge- Driven Iterative Retriever for Enhancing Retrieval-Augmented Generation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shu...
2025
-
[12]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling Large Language Models to Generate Text with Citations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, 6465–648...
-
[13]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
O’Reilly Media, Inc
Boni García. 2022.Hands-On Selenium WebDriver with Java. " O’Reilly Media, Inc. "
2022
-
[15]
Ruediger Glott, Philipp Schmidt, and Rishab Ghosh. 2010. Wikipedia survey– overview of results.United Nations University: Collaborative Creativity Group8 (2010), 1158–1178
2010
-
[16]
Qiushan Guo, Shalini De Mello, Hongxu Yin, Wonmin Byeon, Ka Chun Cheung, Yizhou Yu, Ping Luo, and Sifei Liu. 2024. Regiongpt: Towards region under- standing vision language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13796–13806
2024
-
[17]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reason- ing Steps. InProceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, Do- nia Scott, Núria Bel, and Chengqing Zong (Eds.). Inte...
-
[18]
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. 2026. Refine: Composed video retrieval via shared and differ- ential semantics enhancement.ACM Transactions on Multimedia Computing, Communications and Applications(2026)
2026
-
[19]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
2025
-
[20]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park
- [21]
-
[22]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation.ACM computing surveys55, 12 (2023), 1–38
2023
-
[23]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7969–7992
2023
- [24]
-
[25]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[26]
Bo Li, Tian Tian, Zhenghua Xu, Hao Cheng, Shikun Zhang, and Wei Ye. 2026. Modeling Uncertainty Trends for Timely Retrieval in Dynamic RAG. InFortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educational Ad- vances in Artificial Intelligence, AAAI 2026...
2026
-
[27]
Bo Li, Mingda Wang, Gexiang Fang, Shikun Zhang, and Wei Ye. 2026. Retrieval as Generation: A Unified Framework with Self-Triggered Information Planning. arXiv:2604.11407 [cs.CL] https://arxiv.org/abs/2604.11407
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Bo Li, Mingda Wang, Shikun Zhang, and Wei Ye. 2026. Instruction Data Selection via Answer Divergence. arXiv:2604.10448 [cs.CL] https://arxiv.org/abs/2604. 10448 Chain of Evidence: Pixel-Level Visual Attribution for Iterative Retrieval-Augmented Generation SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Bo Li, Shikun Zhang, and Wei Ye. 2026. Data Selection for Multi-turn Dialogue Instruction Tuning. arXiv:2604.07892 [cs.CL] https://arxiv.org/abs/2604.07892
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Xiping Li and Jianghong Ma. 2025. AIMCoT: Active Information-driven Multi- modal Chain-of-Thought for Vision-Language Reasoning
2025
-
[31]
Xiping Li, Jianghong Ma, Kangzhe Liu, Shanshan Feng, Haijun Zhang, and Yutong Wang. 2024. Category-based and popularity-guided video game recommendation: a balance-oriented framework. InProceedings of the ACM Web Conference 2024. 3734–3744
2024
-
[32]
Xiping Li, Aier Yang, Jianghong Ma, Kangzhe Liu, Shanshan Feng, Haijun Zhang, and Yi Zhao. 2026. CPGRec+: A Balance-oriented Framework for Personalized Video Game Recommendations.ACM Transactions on Information Systems44, 3 (2026), 1–44
2026
-
[33]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Peiyang Liu. 2024. Unsupervised corrupt data detection for text training.Expert Systems with Applications248 (2024), 123335
2024
-
[35]
Peiyang Liu, Zhirui Chen, Xi Wang, Di Liang, Youru Li, Zhi Cai, and Wei Ye. 2026. Learning from Contrasts: Synthesizing Reasoning Paths from Diverse Search Trajectories. arXiv:2604.11365 [cs.AI] https://arxiv.org/abs/2604.11365
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [36]
-
[37]
Peiyang Liu, Sen Wang, Xi Wang, Wei Ye, and Shikun Zhang. 2021. Quadruplet- BERT: An efficient model for embedding-based large-scale retrieval. InProceed- ings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 3734–3739
2021
-
[38]
Peiyang Liu, Xi Wang, Ziqiang Cui, and Wei Ye. 2025. Queries Are Not Alone: Clustering Text Embeddings for Video Search. InProceedings of the 48th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval. 874–883
2025
-
[39]
Peiyang Liu, Xi Wang, Lin Wang, Wei Ye, Xiangyu Xi, and Shikun Zhang. 2021. Distilling knowledge from bert into simple fully connected neural networks for efficient vertical retrieval. InProceedings of the 30th ACM International Conference on Information & Knowledge Management. 3965–3975
2021
-
[40]
Peiyang Liu, Xi Wang, Sen Wang, Wei Ye, Xiangyu Xi, and Shikun Zhang. 2021. Improving embedding-based large-scale retrieval via label enhancement. InFind- ings of the Association for Computational Linguistics: EMNLP 2021. 133–142
2021
-
[41]
Peiyang Liu, Xiangyu Xi, Wei Ye, and Shikun Zhang. 2022. Label smoothing for text mining. InProceedings of the 29th international conference on computational linguistics. 2210–2219
2022
-
[42]
Peiyang Liu, Jinyu Yang, Lin Wang, Sen Wang, Yunlai Hao, and Huihui Bai. 2023. Retrieval-Based Unsupervised Noisy Label Detection on Text Data. InProceed- ings of the 32nd ACM International Conference on Information and Knowledge Management. 4099–4104
2023
-
[43]
Peiyang Liu, Wei Ye, Xiangyu Xi, Tong Wang, Jinglei Zhang, and Shikun Zhang
-
[44]
In2020 International Joint Conference on Neural Networks (IJCNN)
Not all synonyms are created equal: Incorporating similarity of synonyms to enhance word embeddings. In2020 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–8
-
[45]
Xueguang Ma, Shengyao Zhuang, Bevan Koopman, Guido Zuccon, Wenhu Chen, and Jimmy Lin. 2025. VISA: Retrieval Augmented Generation with Visual Source Attribution. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende,...
2025
- [46]
-
[47]
Karen Ka Yan Ng, Izuki Matsuba, and Peter Chengming Zhang. 2025. RAG in health care: a novel framework for improving communication and decision- making by addressing LLM limitations.Nejm Ai2, 1 (2025), AIra2400380
2025
- [48]
-
[49]
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter
-
[50]
Measuring attribution in natural language generation models.Computa- tional Linguistics49, 4 (2023), 777–840
2023
- [51]
-
[52]
Gaurav Shinde, Anuradha Ravi, Emon Dey, Shadman Sakib, Milind Rampure, and Nirmalya Roy. 2025. A Survey on Efficient Vision-Language Models.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery15, 3 (2025), e70036
2025
-
[53]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. 2024. DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei K...
-
[54]
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, and Kuniko Saito. 2023. SlideVQA: A Dataset for Document Visual Question Answering on Multiple Images. InAAAI
2023
-
[55]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[56]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, Anna Rogers, Jordan L
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge- Intensive Multi-Step Questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Lin...
2023
- [57]
-
[58]
Liang Wang, Haonan Chen, Nan Yang, Xiaolong Huang, Zhicheng Dou, and Furu Wei. 2025. Chain-of-Retrieval Augmented Generation.CoRRabs/2501.14342 (2025). arXiv:2501.14342 doi:10.48550/ARXIV.2501.14342
-
[59]
Haoran Wei, Yaofeng Sun, and Yukun Li. 2025. DeepSeek-OCR: Contexts Optical Compression.arXiv preprint arXiv:2510.18234(2025)
work page internal anchor Pith review arXiv 2025
-
[60]
Nirmalie Wiratunga, Ramitha Abeyratne, Lasal Jayawardena, Kyle Martin, Stew- art Massie, Ikechukwu Nkisi-Orji, Ruvan Weerasinghe, Anne Liret, and Bruno Fleisch. 2024. CBR-RAG: case-based reasoning for retrieval augmented gen- eration in LLMs for legal question answering. InInternational Conference on Case-Based Reasoning. Springer, 445–460
2024
- [61]
-
[62]
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. 2024. Benchmarking retrieval-augmented generation for medicine. InFindings of the Association for Computational Linguistics ACL 2024. 6233–6251
2024
-
[63]
Zijun Yao, Weijian Qi, Liangming Pan, Shulin Cao, Linmei Hu, Weichuan Liu, Lei Hou, and Juanzi Li. 2025. SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, W...
2025
-
[64]
Xi Ye, Ruoxi Sun, Sercan Ö. Arik, and Tomas Pfister. 2024. Effective Large Lan- guage Model Adaptation for Improved Grounding and Citation Generation. In Proceedings of the 2024 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, ...
-
[65]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Moham- mad Shoeybi, and Bryan Catanzaro. 2024. Rankrag: Unifying context ranking with retrieval-augmented generation in llms.Advances in Neural Information Processing Systems37 (2024), 121156–121184
2024
-
[66]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. 2024. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence46, 8 (2024), 5625–5644
2024
-
[67]
Mingyu Zhang, Zixu Li, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Jiajia Nie, Yinwei Wei, and Yupeng Hu. 2026. Hint: Composed image retrieval with dual- path compositional contextualized network. (2026), 13002–13006
2026
- [68]
-
[69]
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. 2024. Retrieval- augmented generation for ai-generated content: A survey.arXiv preprint arXiv:2402.19473(2024)
work page internal anchor Pith review arXiv 2024
-
[70]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. Minigpt-4: Enhancing vision-language understanding with advanced large lan- guage models.arXiv preprint arXiv:2304.10592(2023)
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.