Recognition: unknown
SAT: Balancing Reasoning Accuracy and Efficiency with Stepwise Adaptive Thinking
Pith reviewed 2026-05-10 16:45 UTC · model grok-4.3
The pith
SAT achieves up to 40% reduction in reasoning tokens by pruning easy steps while maintaining or improving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that modeling reasoning as a Finite-State Machine with four explicit thinking modes and routing transitions through a lightweight Process Reward Model enables difficulty-aware pruning of individual steps, producing up to 40% fewer tokens across nine large reasoning models and seven benchmarks while generally preserving or improving final accuracy.
What carries the argument
Stepwise Adaptive Thinking (SAT) formulated as a Finite-State Machine with Slow, Normal, Fast, and Skip modes, dynamically navigated by a lightweight Process Reward Model that assesses per-step difficulty.
Load-bearing premise
A lightweight process reward model can accurately judge the difficulty of each reasoning step and prune it without breaking the overall logical flow of the solution.
What would settle it
A controlled test on a standard benchmark in which SAT produces substantially shorter traces but yields measurably lower accuracy than the unpruned baseline on the same problems.
Figures





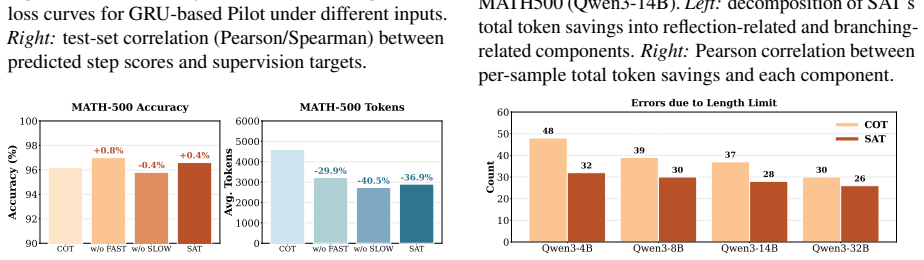
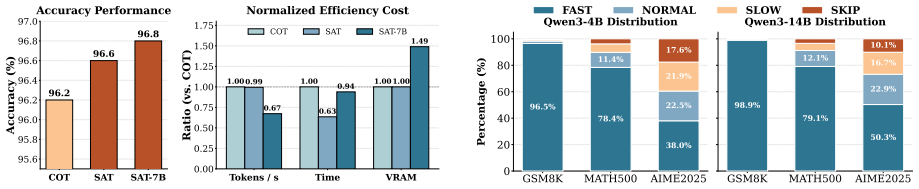


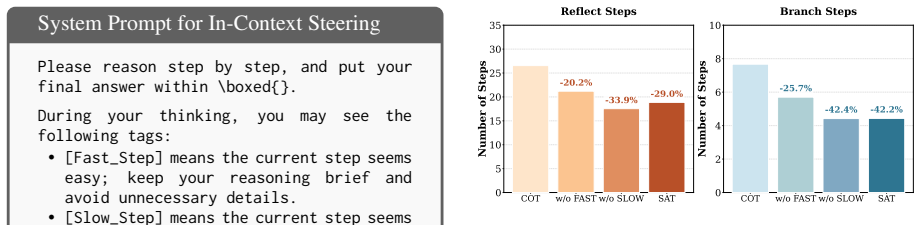


read the original abstract
Large Reasoning Models (LRMs) have revolutionized complex problem-solving, yet they exhibit a pervasive "overthinking", generating unnecessarily long reasoning chains. While current solutions improve token efficiency, they often sacrifice fine-grained control or risk disrupting the logical integrity of the reasoning process. To address this, we introduce Stepwise Adaptive Thinking (SAT), a framework that performs step-level, difficulty-aware pruning while preserving the core reasoning structure. SAT formulates reasoning as a Finite-State Machine (FSM) with distinct thinking modes (Slow, Normal, Fast, Skip). It navigates these states dynamically using a lightweight Process Reward Model (PRM), compressing easy steps while preserving depth for hard ones. Experiments across 9 LRMs and 7 benchmarks show that SAT achieves up to 40% reduction in reasoning tokens while generally maintaining or improving accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Stepwise Adaptive Thinking (SAT), a framework that formulates LRM reasoning as a Finite-State Machine with four modes (Slow, Normal, Fast, Skip). A lightweight Process Reward Model (PRM) dynamically classifies each reasoning step's difficulty to enable pruning or acceleration of easy steps while preserving depth on hard ones. The central claim is that SAT achieves up to 40% reduction in reasoning tokens across 9 LRMs and 7 benchmarks while generally maintaining or improving accuracy, addressing overthinking without disrupting logical integrity.
Significance. If the empirical results hold under rigorous validation, SAT offers a practical, fine-grained mechanism for token-efficient reasoning that improves upon coarser compression methods. The FSM navigation and step-level PRM approach could influence efficiency techniques in LRMs. The multi-model, multi-benchmark evaluation is a positive aspect, though the absence of detailed PRM validation and statistical reporting limits immediate impact.
major comments (2)
- [§4] §4 (Experiments): The headline claim of up to 40% token reduction with maintained accuracy lacks reported error bars, statistical significance tests, or per-benchmark variance; without these, it is impossible to assess whether the gains are robust or benchmark-specific, directly undermining the central efficiency-accuracy tradeoff result.
- [§3.2] §3.2 (PRM and FSM navigation): The framework's correctness rests on the lightweight PRM correctly labeling step difficulty so that Skip/Fast modes preserve final-answer integrity. No per-step classification accuracy, oracle-PRM comparison, or failure-case analysis (e.g., early mis-pruning of critical intermediates) is provided; this is load-bearing for the claim that pruning does not disrupt logical structure.
minor comments (2)
- [Abstract] Abstract: The 40% reduction figure is stated without any qualifying detail on variance or conditions; adding a brief qualifier would improve clarity.
- [§3] Notation: The FSM state transitions are described at a high level; a small state-transition diagram or pseudocode table would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key opportunities to strengthen the statistical robustness of our results and the direct validation of the PRM component. We address each major comment point by point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The headline claim of up to 40% token reduction with maintained accuracy lacks reported error bars, statistical significance tests, or per-benchmark variance; without these, it is impossible to assess whether the gains are robust or benchmark-specific, directly undermining the central efficiency-accuracy tradeoff result.
Authors: We agree that additional statistical reporting is necessary to substantiate the robustness of the efficiency-accuracy tradeoff. In the revised manuscript, we will update §4 to include error bars (standard deviations over multiple runs), statistical significance tests (paired t-tests against baselines for both token counts and accuracy), and per-benchmark variance breakdowns. These changes will allow clearer assessment of whether the up to 40% token reductions are consistent across the 7 benchmarks. revision: yes
-
Referee: [§3.2] §3.2 (PRM and FSM navigation): The framework's correctness rests on the lightweight PRM correctly labeling step difficulty so that Skip/Fast modes preserve final-answer integrity. No per-step classification accuracy, oracle-PRM comparison, or failure-case analysis (e.g., early mis-pruning of critical intermediates) is provided; this is load-bearing for the claim that pruning does not disrupt logical structure.
Authors: The PRM's step difficulty classification is indeed central to the FSM's ability to preserve logical integrity. While end-to-end accuracy provides supporting evidence, we will revise §3.2 to add per-step classification accuracy (via sampled human or oracle annotations), a comparison to an oracle PRM on representative steps, and a failure-case analysis of potential early mis-pruning. These additions will directly address concerns about whether pruning disrupts reasoning structure. revision: yes
Circularity Check
No significant circularity; SAT is an empirical framework with external benchmarks
full rationale
The paper introduces SAT as a novel FSM-based framework that uses a lightweight PRM to dynamically select thinking modes (Slow/Normal/Fast/Skip) for step-level pruning. All performance claims (token reduction, accuracy maintenance) are presented as outcomes of experiments across 9 LRMs and 7 independent benchmarks rather than as predictions derived from fitted parameters or self-referential definitions. No equations, uniqueness theorems, or ansatzes are shown to reduce by construction to the paper's own inputs or prior self-citations. The derivation chain remains self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning processes can be effectively modeled as a finite-state machine with distinct thinking modes (Slow, Normal, Fast, Skip).
invented entities (1)
-
Stepwise Adaptive Thinking (SAT) framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Mitigating Multimodal Hallucination via Phase-wise Self-reward
PSRD mitigates visual hallucinations in LVLMs via phase-wise self-reward decoding, cutting rates by 50% on LLaVA-1.5-7B and outperforming prior methods on five benchmarks.
Reference graph
Works this paper leans on
-
[1]
AI-MO . 2024. AMC 2023, 2024 . https://huggingface.co/datasets/AI-MO/aimo-validation-amc
2024
-
[2]
Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, Ido Shahaf, Oren Tropp, Ehud Karpas, Ran Zilberstein, Jiaqi Zeng, Soumye Singhal, Alexander Bukharin, Yian Zhang, Tugrul Konuk, and 114 others. 2025. https://arxiv.org/abs/2505.00949 Llama-nemotron: Efficient reasoning mod...
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others. 2021. https://arxiv.org/abs/2107.03374 Evaluating large lang...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Qiguang Chen, Libo Qin, Jiaqi WANG, Jingxuan Zhou, and Wanxiang Che. 2024. https://openreview.net/forum?id=pC44UMwy2v Unlocking the capabilities of thought: A reasoning boundary framework to quantify and optimize chain-of-thought . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement lea...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Ruomeng Ding, Chaoyun Zhang, Lu Wang, Yong Xu, Minghua Ma, Wei Zhang, Si Qin, Saravan Rajmohan, Qingwei Lin, and Dongmei Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.95 Everything of thoughts: Defying the law of penrose triangle for thought generation . In Findings of the Association for Computational Linguistics: ACL 2024, pages 1638--1662,...
-
[8]
Yichao Fu, Junda Chen, Siqi Zhu, Zheyu Fu, Zhongdongming Dai, Yonghao Zhuang, Yian Ma, Aurick Qiao, Tajana Rosing, Ion Stoica, and Hao Zhang. 2025. https://openreview.net/forum?id=nn51ewu5k2 Efficiently scaling LLM reasoning programs with certaindex . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[9]
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyu Zhao, Shiqing Ma, and Zhenyu Chen. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1274 Token-budget-aware LLM reasoning . In Findings of the Association for Computational Linguistics: ACL 2025, pages 24842--24855, Vienna, Austria. Association for Computational Linguistics
-
[10]
Jujie He, Tianwen Wei, Rui Yan, Jiacai Liu, Chaojie Wang, Yimeng Gan, Shiwen Tu, Chris Yuhao Liu, Liang Zeng, Xiaokun Wang, Boyang Wang, Yongcong Li, Fuxiang Zhang, Jiacheng Xu, Bo An, Yang Liu, and Yahui Zhou. 2024. https://doi.org/10.5281/zenodo.16998085 Skywork-o1 open series
-
[11]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://openreview.net/forum?id=7Bywt2mQsCe Measuring mathematical problem solving with the MATH dataset . In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
2021
-
[12]
Jiameng Huang, Baijiong Lin, Guhao Feng, Jierun Chen, Di He, and Lu Hou. 2026. Efficient reasoning for large reasoning language models via certainty-guided reflection suppression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)
2026
-
[13]
Xingzuo Li, Kehai Chen, Yunfei Long, Xuefeng Bai, Yong Xu, and Min Zhang. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.892 Generator-assistant stepwise rollback framework for large language model agent . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17683--17700, Suzhou, China. Association for Comput...
-
[14]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. https://arxiv.org/abs/2308.03281 Towards general text embeddings with multi-stage contrastive learning . Preprint, arXiv:2308.03281
work page internal anchor Pith review arXiv 2023
-
[15]
Guosheng Liang, Longguang Zhong, Ziyi Yang, and Xiaojun Quan. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.278 T hink S witcher: When to think hard, when to think fast . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5185--5201, Suzhou, China. Association for Computational Linguistics
-
[16]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. https://openreview.net/forum?id=v8L0pN6EOi Let's verify step by step . In The Twelfth International Conference on Learning Representations
2024
- [17]
-
[18]
Weizhe Lin, Xing Li, Zhiyuan Yang, Xiaojin Fu, Hui-Ling Zhen, Yaoyuan Wang, Xianzhi Yu, Wulong Liu, Xiaosong Li, and Mingxuan Yuan. 2025 b . https://arxiv.org/abs/2505.17155 Trimr: Verifier-based training-free thinking compression for efficient test-time scaling . Preprint, arXiv:2505.17155
-
[19]
Xiang Liu, Xuming Hu, Xiaowen Chu, and Eunsol Choi. 2025. https://arxiv.org/abs/2510.19669 Diffadapt: Difficulty-adaptive reasoning for token-efficient llm inference . Preprint, arXiv:2510.19669
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Xin Liu and Lu Wang. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.904 Answer convergence as a signal for early stopping in reasoning . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17907--17918, Suzhou, China. Association for Computational Linguistics
- [21]
-
[22]
MAA Committees . 2024. AIME Problems and Solutions . https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions
2024
-
[23]
MAA Committees . 2025. AIME Problems and Solutions . https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions
2025
-
[24]
OpenAI . 2025. Learning to reason with llms. https://openai.com/research/learning-to-reason-with-llms
2025
-
[25]
Deng Qiyuan, Xuefeng Bai, Kehai Chen, Yaowei Wang, Liqiang Nie, and Min Zhang. 2025. https://doi.org/10.18653/v1/2025.acl-long.1504 Efficient safety alignment of large language models via preference re-ranking and representation-based reward modeling . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lo...
-
[26]
QwenTeam. 2025. https://qwenlm.github.io/blog/qwq-32b/ Qwq-32b: Embracing the power of reinforcement learning
2025
-
[27]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2024. https://openreview.net/forum?id=Ti67584b98 GPQA : A graduate-level google-proof q&a benchmark . In First Conference on Language Modeling
2024
-
[28]
Matthew Renze and Erhan Guven. 2024. https://doi.org/10.1109/FLLM63129.2024.10852493 The benefits of a concise chain of thought on problem-solving in large language models . In 2024 2nd International Conference on Foundation and Large Language Models (FLLM), pages 476--483
-
[29]
Swarnadeep Saha, Archiki Prasad, Justin Chen, Peter Hase, Elias Stengel-Eskin, and Mohit Bansal. 2025. https://openreview.net/forum?id=zd0iX5xBhA System 1.x: Learning to balance fast and slow planning with language models . In The Thirteenth International Conference on Learning Representations
2025
-
[30]
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. 2025. https://openreview.net/forum?id=HvoG8SxggZ Stop overthinking: A survey on efficient reasoning for large language models . Transactions on Machine Learning Research
2025
-
[31]
Bartlett, and Andrea Zanette
Hanshi Sun, Momin Haider, Ruiqi Zhang, Huitao Yang, Jiahao Qiu, Ming Yin, Mengdi Wang, Peter L. Bartlett, and Andrea Zanette. 2024. http://papers.nips.cc/paper\_files/paper/2024/hash/3950f6bf5c2eb7435ecf58eaa85cc8c2-Abstract-Conference.html Fast best-of-n decoding via speculative rejection . In Advances in Neural Information Processing Systems 38: Annual ...
2024
-
[32]
Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Junxian He. 2024. https://openreview.net/forum?id=zLU21oQjD5 DART -math: Difficulty-aware rejection tuning for mathematical problem-solving . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[33]
Chenlong Wang, Yuanning Feng, Dongping Chen, Zhaoyang Chu, Ranjay Krishna, and Tianyi Zhou. 2025 a . https://doi.org/10.18653/v1/2025.findings-emnlp.394 Wait, we don ' t need to ``wait''! removing thinking tokens improves reasoning efficiency . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 7459--7482, Suzhou, China. Assoc...
-
[34]
Pan, Zeming Liu, and Kam-Fai Wong
Hongru Wang, Deng Cai, Wanjun Zhong, Shijue Huang, Jeff Z. Pan, Zeming Liu, and Kam-Fai Wong. 2025 b . https://doi.org/10.18653/v1/2025.findings-acl.291 Self-reasoning language models: Unfold hidden reasoning chains with few reasoning catalyst . In Findings of the Association for Computational Linguistics: ACL 2025, pages 5578--5596, Vienna, Austria. Asso...
-
[35]
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. 2024. https://doi.org/10.18653/v1/2024.acl-long.510 Math-shepherd: Verify and reinforce LLM s step-by-step without human annotations . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages...
- [36]
-
[37]
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, and Yiming Yang. 2025. https://openreview.net/forum?id=VNckp7JEHn Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving . In The Thirteenth International Conference on Learning Representations
2025
- [38]
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [40]
-
[41]
Yu Zhang, Kehai Chen, Xuefeng Bai, Zhao Kang, Quanjiang Guo, and Min Zhang. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.524 Question-guided knowledge graph re-scoring and injection for knowledge graph question answering . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 8972--8985, Miami, Florida, USA. Association ...
-
[42]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[43]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.