Recognition: unknown
Mitigating Multimodal Hallucination via Phase-wise Self-reward
Pith reviewed 2026-05-10 05:06 UTC · model grok-4.3
The pith
Phase-wise self-reward decoding halves hallucination rates in large vision-language models at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that visual hallucinations exhibit phase-wise dynamic patterns peaking at the onset of each semantic phase, and introduce PSRD which uses self-reward signals distilled into a lightweight model to guide precise interventions during the decoding process, achieving online hallucination correction without external supervision.
What carries the argument
Phase-wise self-reward decoding, which distills hallucination guidance from the LVLM into a lightweight reward model for on-the-fly targeted intervention at semantic phase onsets.
If this is right
- Reduces hallucination rate by 50% in LLaVA-1.5-7B.
- Outperforms existing post-hoc methods on five benchmarks for four different LVLMs.
- Effectively mitigates hallucination propagation during generation.
- Achieves controllable trade-off between performance and inference efficiency.
Where Pith is reading between the lines
- Similar phase detection could apply to text-only large language models to reduce factual errors.
- Integrating this with fine-tuning might further improve base model reliability.
- Testing on more diverse visual inputs could reveal if the phase patterns hold across domains.
Load-bearing premise
Hallucinations in the model's outputs follow identifiable patterns linked to the start of new semantic phases, and the model can generate reliable self-reward signals to detect and fix them without outside help.
What would settle it
Measuring the actual hallucination rates on the same benchmarks after applying PSRD and finding no significant reduction compared to baselines would disprove the effectiveness of the phase-wise intervention.
Figures







read the original abstract
Large Vision-Language Models (LVLMs) still struggle with vision hallucination, where generated responses are inconsistent with the visual input. Existing methods either rely on large-scale annotated data for fine-tuning, which incurs massive computational overhead, or employ static post-hoc strategies that overlook the dynamic nature of hallucination emergence. To address these, we introduce a new self-rewarding framework, enabling dynamic hallucination mitigation at inference time without external supervision. On the empirical side, we reveal that visual hallucination exhibits phase-wise dynamic patterns, peaking at the onset of each semantic phase. Drawing on these insights, we propose \textbf{PSRD} (\textbf{Phase-wise \textbf{S}elf-\textbf{R}eward \textbf{D}ecoding) for online hallucination correction guided by phase-wise self-reward signals. To reduce the cost of repeated self-evaluation during decoding, we distill the hallucination guidance signal from LVLMs into a lightweight reward model. The reward model subsequently provides on-the-fly guidance for targeted intervention during the decoding process, enabling precise hallucination suppression. The proposed PSRD significantly reduces the hallucination rate of LLaVA-1.5-7B by 50.0% and consistently outperforms existing post-hoc methods across five hallucination evaluation benchmarks for four LVLMs. Further analysis confirms that PSRD effectively mitigates hallucination propagation and achieves a highly controllable trade-off between strong performance and inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PSRD, a phase-wise self-reward decoding framework for mitigating visual hallucinations in Large Vision-Language Models (LVLMs) during inference without external supervision. It observes that hallucinations exhibit phase-wise dynamic patterns peaking at semantic phase onsets, distills self-reward signals into a lightweight reward model for efficient online correction, and reports a 50% reduction in hallucination rate for LLaVA-1.5-7B along with consistent outperformance over post-hoc methods on five benchmarks for four LVLMs.
Significance. If the empirical results hold under rigorous validation, this would represent a meaningful advance by offering an unsupervised inference-time approach that exploits the dynamic emergence of hallucinations rather than relying on static post-hoc fixes or expensive fine-tuning. The distillation to a lightweight reward model is a practical strength for deployment efficiency, and the phase-wise analysis could stimulate further work on temporal patterns in multimodal generation errors.
major comments (3)
- Abstract: The central claim of a 50.0% reduction in hallucination rate for LLaVA-1.5-7B (and outperformance across five benchmarks) is reported without the baseline hallucination rate, exact evaluation protocol, statistical significance tests, or controls for potential data leakage in phase boundary detection, leaving the magnitude and reliability of the gains under-supported.
- Method section (self-reward signal derivation): The self-reward is generated by the same LVLM whose outputs are being corrected; the manuscript provides no independent verification (e.g., correlation analysis against ground-truth visual inconsistencies or external image features) that the signal reliably flags hallucinations rather than model-internal biases or overconfidence.
- Experiments (phase-wise patterns and distillation): The phase boundary detection threshold and reward model distillation hyperparameters are free parameters; without sensitivity analysis or ablations showing that the reported 50% reduction and benchmark wins are robust to their settings, the central claim risks being an artifact of the specific evaluation setup.
minor comments (2)
- Abstract: The phrase 'highly controllable trade-off between strong performance and inference efficiency' is stated without specifying the control parameters or quantitative efficiency metrics used to demonstrate controllability.
- Overall: The manuscript would benefit from explicit pseudocode or a diagram for the online intervention step during decoding to clarify how the distilled reward model intervenes at phase onsets.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We have carefully reviewed each major point and provide point-by-point responses below, indicating where revisions have been made to the manuscript to improve clarity, support for claims, and robustness.
read point-by-point responses
-
Referee: Abstract: The central claim of a 50.0% reduction in hallucination rate for LLaVA-1.5-7B (and outperformance across five benchmarks) is reported without the baseline hallucination rate, exact evaluation protocol, statistical significance tests, or controls for potential data leakage in phase boundary detection, leaving the magnitude and reliability of the gains under-supported.
Authors: We agree that the abstract would benefit from greater specificity to better substantiate the central claims. In the revised manuscript, we have updated the abstract to include the baseline hallucination rate for LLaVA-1.5-7B, a concise description of the evaluation protocol (including the five benchmarks and metrics), reference to the statistical significance tests performed, and an explicit clarification that phase boundaries are identified using only the model's internal generation dynamics (e.g., semantic shift indicators from token probabilities) with no access to or leakage from any test data. revision: yes
-
Referee: Method section (self-reward signal derivation): The self-reward is generated by the same LVLM whose outputs are being corrected; the manuscript provides no independent verification (e.g., correlation analysis against ground-truth visual inconsistencies or external image features) that the signal reliably flags hallucinations rather than model-internal biases or overconfidence.
Authors: This is a fair methodological concern. While the framework is intentionally unsupervised and relies on the LVLM's own signals, we have added a new correlation analysis in the revised manuscript between the self-reward scores and ground-truth hallucination annotations from the evaluation benchmarks. The results show a positive correlation, providing empirical evidence that the signal aligns with actual visual inconsistencies rather than solely internal biases. We acknowledge that this is not a fully external verification (e.g., via separate image encoders) and discuss it as a limitation and avenue for future work. revision: partial
-
Referee: Experiments (phase-wise patterns and distillation): The phase boundary detection threshold and reward model distillation hyperparameters are free parameters; without sensitivity analysis or ablations showing that the reported 50% reduction and benchmark wins are robust to their settings, the central claim risks being an artifact of the specific evaluation setup.
Authors: We appreciate the emphasis on robustness. In the revised manuscript, we have incorporated sensitivity analyses that vary the phase boundary detection threshold across multiple values and test alternative settings for the distillation hyperparameters (including reward model capacity and training details). These ablations confirm that the reported hallucination reductions and benchmark improvements remain consistent and are not artifacts of particular hyperparameter choices. The results are presented in an expanded experiments section with additional figures and tables in the supplementary material. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PSRD as an empirical method: it observes phase-wise hallucination patterns, distills a self-reward signal from the LVLM into a lightweight model, and applies it for online correction during decoding. All central claims (50% hallucination reduction on LLaVA-1.5-7B, outperformance on five benchmarks) are presented as experimental outcomes rather than derived predictions. No equations, uniqueness theorems, or self-citations are invoked to force the result by construction. The self-reward mechanism is a design choice whose effectiveness is tested externally on benchmarks; it does not reduce to tautological re-labeling of inputs. The framework remains self-contained against independent evaluation and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- phase boundary detection threshold
- reward model distillation hyperparameters
axioms (2)
- domain assumption Visual hallucination exhibits phase-wise dynamic patterns peaking at semantic phase onsets
- domain assumption Self-reward signals from the LVLM can detect and correct hallucinations without external supervision
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shun-ichi Amari. 1993. Backpropagation and stochastic gradient descent method. Neurocomputing5, 4-5 (1993), 185–196
1993
-
[3]
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, and Shijian Lu. 2025. Mitigating object hallucinations in large vision-language models with assembly of global and local attention. In Proceedings of the Computer Vision and Pattern Recognition Conference. 29915– 29926
2025
- [4]
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930(2024)
work page internal anchor Pith review arXiv 2024
-
[7]
Fu Chaoyou, Chen Peixian, Shen Yunhang, Qin Yulei, Zhang Mengdan, Lin Xu, Yang Jinrui, Zheng Xiawu, Li Ke, Sun Xing, et al. 2023. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.133943 (2023)
work page internal anchor Pith review arXiv 2023
- [8]
- [9]
-
[10]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. 2023. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. arXiv:2305.06500 [cs.CV]
work page internal anchor Pith review arXiv 2023
-
[11]
Yihe Deng, Pan Lu, Fan Yin, Ziniu Hu, Sheng Shen, Quanquan Gu, James Y Zou, Kai-Wei Chang, and Wei Wang. 2024. Enhancing large vision language models with self-training on image comprehension.Advances in Neural Information Processing Systems37 (2024), 131369–131397
2024
-
[12]
Alessandro Favero, Luca Zancato, Matthew Trager, Siddharth Choudhary, Pra- muditha Perera, Alessandro Achille, Ashwin Swaminathan, and Stefano Soatto
-
[13]
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Multi-modal hallucination control by visual information grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14303–14312
- [14]
-
[15]
Yuhan Fu, Ruobing Xie, Xingwu Sun, Zhanhui Kang, and Xirong Li. 2025. Mitigat- ing hallucination in multimodal large language model via hallucination-targeted direct preference optimization. InFindings of the Association for Computational Linguistics: ACL 2025. 16563–16577
2025
-
[16]
Anisha Gunjal, Jihan Yin, and Erhan Bas. 2024. Detecting and preventing hallucinations in large vision language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 18135–18143
2024
-
[17]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. Opera: Alleviating hal- lucination in multi-modal large language models via over-trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13418–13427
2024
-
[18]
Weiyang Huang, Xuefeng Bai, Kehai Chen, Xinyang Chen, Yibin Chen, Weili Guan, and Min Zhang. 2026. SAT: Balancing Reasoning Accuracy and Efficiency with Stepwise Adaptive Thinking.arXiv preprint arXiv:2604.07922(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [19]
-
[20]
Chaoya Jiang, Haiyang Xu, Mengfan Dong, Jiaxing Chen, Wei Ye, Ming Yan, Qing- hao Ye, Ji Zhang, Fei Huang, and Shikun Zhang. 2024. Hallucination augmented contrastive learning for multimodal large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 27036–27046
2024
- [21]
-
[22]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13872–13882
2024
-
[23]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895(2024)
work page internal anchor Pith review arXiv 2024
-
[24]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen
-
[25]
Evaluating object hallucination in large vision-language models.arXiv preprint arXiv:2305.10355(2023)
work page internal anchor Pith review arXiv 2023
- [26]
-
[27]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al. Zurich, Switzerland, September 6-12, 2014, Proceedings, Pa...
2014
-
[28]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved Baselines with Visual Instruction Tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 26296–26306
2024
-
[29]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multi- modal reasoning via thought chains for science question answering.Advances in neural information processing systems35 (2022), 2507–2521
2022
- [30]
-
[31]
Yuexin Ma, Tai Wang, Xuyang Bai, Huitong Yang, Yuenan Hou, Yaming Wang, Yu Qiao, Ruigang Yang, and Xinge Zhu. 2024. Vision-centric bev perception: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 12 (2024), 10978–10997
2024
-
[32]
Oscar Mañas, Pierluca D’Oro, Koustuv Sinha, Adriana Romero-Soriano, Michal Drozdzal, and Aishwarya Agrawal. 2025. Controlling Multimodal LLMs via Reward-guided Decoding. InProceedings of the IEEE/CVF International Conference on Computer Vision. 1391–1401
2025
-
[33]
Yassine Ouali, Adrian Bulat, Brais Martinez, and Georgios Tzimiropoulos. 2024. Clip-dpo: Vision-language models as a source of preference for fixing hallucina- tions in lvlms. InEuropean Conference on Computer Vision. Springer, 395–413
2024
-
[34]
Yeji Park, Deokyeong Lee, Junsuk Choe, and Buru Chang. 2025. Convis: Con- trastive decoding with hallucination visualization for mitigating hallucinations in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39
2025
- [35]
-
[36]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[37]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
- [38]
-
[39]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object hallucination in image captioning.arXiv preprint arXiv:1809.02156(2018)
work page Pith review arXiv 2018
-
[40]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[41]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [42]
-
[43]
Wei Suo, Lijun Zhang, Mengyang Sun, Lin Yuanbo Wu, Peng Wang, and Yanning Zhang. 2025. Octopus: Alleviating hallucination via dynamic contrastive decoding. InProceedings of the Computer Vision and Pattern Recognition Conference. 29904–29914
2025
-
[44]
Wentao Tan, Qiong Cao, Yibing Zhan, Chao Xue, and Changxing Ding. 2025. Beyond human data: Aligning multimodal large language models by iterative self-evolution. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 7202–7210
2025
- [45]
- [46]
- [47]
- [48]
- [49]
- [50]
- [51]
-
[52]
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Fangxun Shu, Hao Jiang, and Linchao Zhu. 2025. Detecting and mitigating hallucination in large vision language models via fine-grained ai feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25543–25551
2025
- [53]
- [54]
-
[55]
Kevin Yang and Dan Klein. 2021. FUDGE: Controlled text generation with future discriminators. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 3511–3535
2021
-
[56]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Tong Xu, Hao Wang, Dianbo Sui, Yunhang Shen, Ke Li, Xing Sun, and Enhong Chen. 2024. Woodpecker: Hallucination correction for multimodal large language models.Science China Information Sciences67, 12 (2024), 220105
2024
-
[57]
Tianyu Yu, Haoye Zhang, Qiming Li, Qixin Xu, Yuan Yao, Da Chen, Xiaoman Lu, Ganqu Cui, Yunkai Dang, Taiwen He, Xiaocheng Feng, Jun Song, Bo Zheng, Zhiyuan Liu, Tat-Seng Chua, and Maosong Sun. 2025. RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CV...
2025
-
[58]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. 2024. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9556–9567
2024
- [59]
-
[60]
Pingrui Zhang, Xianqiang Gao, Yuhan Wu, Kehui Liu, Dong Wang, Zhigang Wang, Bin Zhao, Yan Ding, and Xuelong Li. 2025. Moma-kitchen: A 100k+ benchmark for affordance-grounded last-mile navigation in mobile manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 6315–6326
2025
- [61]
- [62]
-
[63]
Yu Zhang, Mufan Xu, Xuefeng Bai, Pengfei Zhang, Yang Xiang, Min Zhang, et al. 2026. Instruction Anchors: Dissecting the Causal Dynamics of Modality Arbitration.arXiv preprint arXiv:2602.03677(2026)
work page internal anchor Pith review arXiv 2026
- [64]
- [65]
-
[66]
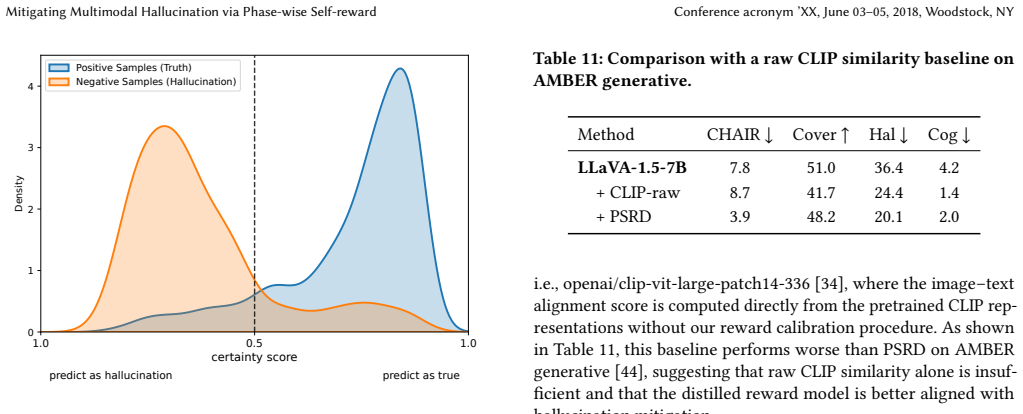
CLIP-raw
Fei Zuo, Kehai Chen, Yu Zhang, Zhengshan Xue, and Min Zhang. 2025. InImage- Trans: Multimodal LLM-based text image machine translation. InFindings of the Association for Computational Linguistics: ACL 2025. 20256–20277. Mitigating Multimodal Hallucination via Phase-wise Self-reward Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Our supplementary ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.