Recognition: no theorem link
WorldMAP: Bootstrapping Vision-Language Navigation Trajectory Prediction with Generative World Models
Pith reviewed 2026-05-10 18:18 UTC · model grok-4.3
The pith
WorldMAP turns world-model-generated futures into planning supervision that trains a student to predict accurate navigation trajectories from single views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
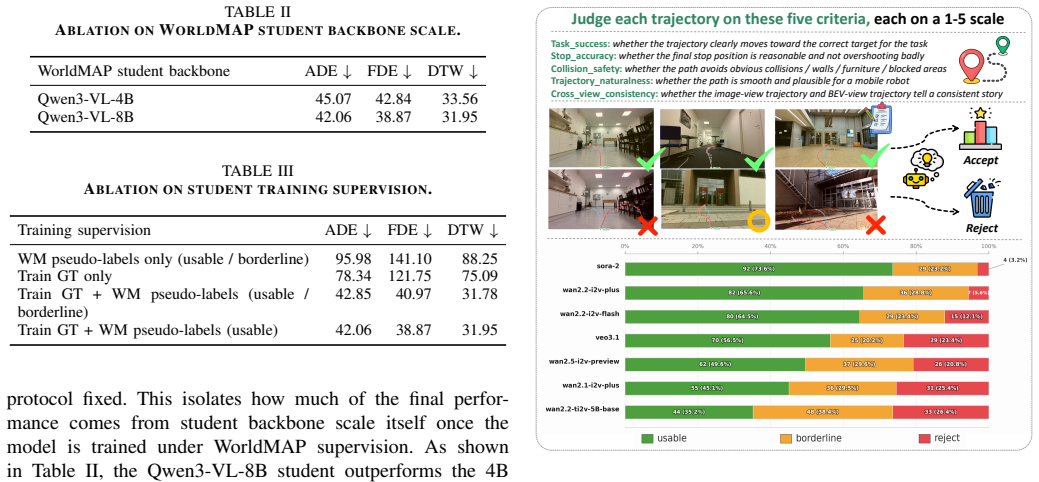
WorldMAP shows that converting generative world model futures into persistent semantic-spatial structure and planning-derived supervision allows training a student trajectory predictor that outperforms baselines on Target-Bench, reducing ADE by 18.0% and FDE by 42.1%, while making small VLMs competitive in DTW with proprietary models. The broader insight is that world models are most valuable for synthesizing structured supervision rather than providing direct imagined actions.
What carries the argument
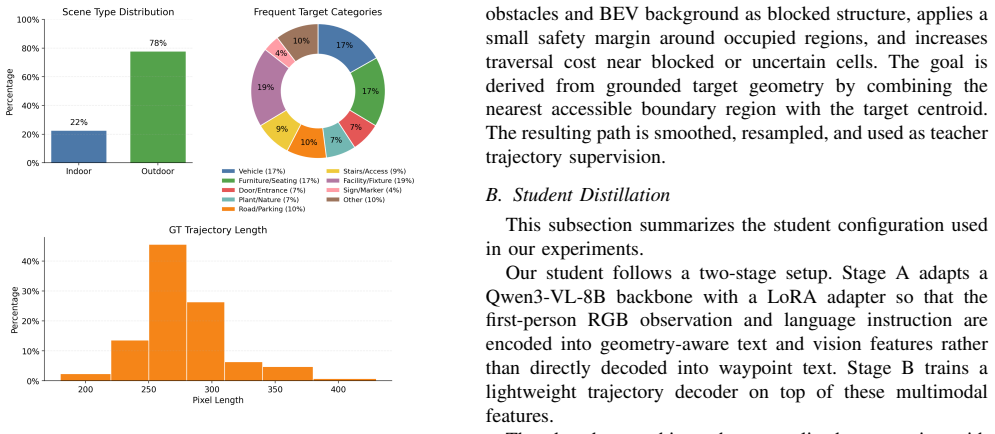
The world-model-driven teacher component that builds semantic-spatial memory from generated videos, grounds task-relevant targets and obstacles, and produces trajectory pseudo-labels through explicit planning.
If this is right
- The student model predicts navigation trajectories directly from single egocentric vision-language observations.
- Trajectory prediction accuracy improves over existing methods, with 18% lower ADE and 42% lower FDE on the benchmark.
- Small open-source VLMs achieve DTW performance competitive with proprietary models.
- World models contribute to navigation learning primarily through generating supervision signals rather than direct planning evidence.
Where Pith is reading between the lines
- If world model quality increases, the resulting pseudo-labels could further enhance student performance without additional real data.
- This framework might apply to other embodied tasks where generating reliable supervision is difficult.
- Deploying the student on physical robots could test whether the learned trajectories generalize beyond the benchmark environments.
- Reducing model size while maintaining performance points to more efficient embodied AI systems in resource-limited settings.
Load-bearing premise
That the futures generated by the world model can be converted into reliable semantic-spatial structures and planning supervision without significant errors or hallucinations affecting the student's learning.
What would settle it
If replacing the generated futures with real observed futures in the teacher leads to no improvement or worse student performance on Target-Bench, or if injecting known hallucinations into the teacher's memory degrades the student's trajectories.
Figures









read the original abstract
Vision-language models (VLMs) and generative world models are opening new opportunities for embodied navigation. VLMs are increasingly used as direct planners or trajectory predictors, while world models support look-ahead reasoning by imagining future views. Yet predicting a reliable trajectory from a single egocentric observation remains challenging. Current VLMs often generate unstable trajectories, and world models, though able to synthesize plausible futures, do not directly provide the grounded signals needed for navigation learning. This raises a central question: how can generated futures be turned into supervision for grounded trajectory prediction? We present WorldMAP, a teacher--student framework that converts world-model-generated futures into persistent semantic-spatial structure and planning-derived supervision. Its world-model-driven teacher builds semantic-spatial memory from generated videos, grounds task-relevant targets and obstacles, and produces trajectory pseudo-labels through explicit planning. A lightweight student with a multi-hypothesis trajectory head is then trained to predict navigation trajectories directly from vision-language inputs. On Target-Bench, WorldMAP achieves the best ADE and FDE among compared methods, reducing ADE by 18.0% and FDE by 42.1% relative to the best competing baseline, while lifting a small open-source VLM to DTW performance competitive with proprietary models. More broadly, the results suggest that, in embodied navigation, the value of world models may lie less in supplying action-ready imagined evidence than in synthesizing structured supervision for navigation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents WorldMAP, a teacher-student framework for vision-language navigation trajectory prediction. A world-model-driven teacher generates future views, constructs semantic-spatial memory, grounds task-relevant targets/obstacles, and derives trajectory pseudo-labels via explicit planning; a lightweight student VLM with a multi-hypothesis head is then trained directly on vision-language inputs to predict trajectories. On Target-Bench the method reports the best ADE/FDE among compared approaches (18.0% and 42.1% relative reductions versus the strongest baseline) and lifts a small open-source VLM to DTW scores competitive with proprietary models.
Significance. If the pseudo-label quality can be independently verified, the work would be significant for embodied navigation: it reframes generative world models as sources of structured supervision rather than direct planners, and shows a practical route to improve smaller VLMs without requiring large-scale human trajectory data. The explicit separation of teacher planning from student inference is a clean architectural contribution.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the reported ADE/FDE gains and DTW competitiveness are presented without any quantitative check on teacher pseudo-label fidelity (e.g., ADE/FDE of the planning-derived labels versus dataset ground truth, or frame-to-frame consistency of grounded targets). This validation is load-bearing for the central claim that improvements arise from world-model bootstrapping rather than from the multi-hypothesis head or generic data augmentation.
- [Method] Method description (teacher pipeline): the conversion of generated futures into persistent semantic-spatial memory and planning-derived supervision is described at a high level, but no error analysis, hallucination rate, or ablation on the planning module's sensitivity to world-model artifacts is supplied. Without these, it remains unclear whether the student is learning robust navigation or merely fitting to noisy pseudo-labels.
minor comments (2)
- [Abstract] The abstract states that WorldMAP 'lifts a small open-source VLM to DTW performance competitive with proprietary models' but does not name the specific models, report exact DTW numbers, or indicate whether the comparison is on the same test split.
- [Figures/Tables] Figure and table captions should explicitly state the number of runs, random seeds, and whether error bars reflect standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We agree that explicit validation of pseudo-label quality is important to substantiate the central claims and will revise the manuscript accordingly to include the requested quantitative checks and analyses.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the reported ADE/FDE gains and DTW competitiveness are presented without any quantitative check on teacher pseudo-label fidelity (e.g., ADE/FDE of the planning-derived labels versus dataset ground truth, or frame-to-frame consistency of grounded targets). This validation is load-bearing for the central claim that improvements arise from world-model bootstrapping rather than from the multi-hypothesis head or generic data augmentation.
Authors: We agree that this validation is load-bearing for the central claim. In the revised manuscript we will add a new subsection to the Experiments section that directly compares the teacher's planning-derived pseudo-labels against the dataset ground-truth trajectories, reporting ADE and FDE for the pseudo-labels themselves as well as frame-to-frame consistency metrics for the grounded targets and obstacles. These additions will provide quantitative evidence that the reported gains originate from high-quality world-model bootstrapping rather than from the multi-hypothesis head or generic augmentation. revision: yes
-
Referee: [Method] Method description (teacher pipeline): the conversion of generated futures into persistent semantic-spatial memory and planning-derived supervision is described at a high level, but no error analysis, hallucination rate, or ablation on the planning module's sensitivity to world-model artifacts is supplied. Without these, it remains unclear whether the student is learning robust navigation or merely fitting to noisy pseudo-labels.
Authors: We acknowledge that the current Method section presents the teacher pipeline at a conceptual level. In the revision we will expand this section to include (i) an error analysis of the semantic-spatial memory construction and planning steps, (ii) measurable hallucination rates where they can be quantified via consistency checks on generated futures, and (iii) an ablation examining the planning module's sensitivity to world-model artifacts. These additions will clarify that the student learns robust navigation policies rather than fitting to noise. revision: yes
Circularity Check
No significant circularity; derivation relies on external world models and benchmark evaluation
full rationale
The paper's central claim is a teacher-student pipeline in which an external generative world model produces futures that are converted via explicit planning into pseudo-labels for training a student VLM on trajectory prediction. Performance is measured by ADE/FDE/DTW on the external Target-Bench dataset against ground-truth trajectories and competing baselines. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text that would make the reported gains tautological or reduce to the paper's own inputs by construction. The approach is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A path towards autonomous machine intelligence,
Y . LeCun, “A path towards autonomous machine intelligence,” Open- Review, 2022, version 0.9.2, June 27, 2022
2022
-
[2]
A survey of embodied ai: From simulators to research tasks,
J. Duan, S. Yu, H. L. Tan, H. Zhu, and C. Tan, “A survey of embodied ai: From simulators to research tasks,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 6, no. 2, pp. 230–244, 2022
2022
-
[3]
Aligning cyber space with physical world: A comprehensive survey on embodied ai,
Y . Liu, W. Chen, Y . Bai, X. Liang, G. Li, W. Gao, and L. Lin, “Aligning cyber space with physical world: A comprehensive survey on embodied ai,”IEEE/ASME Transactions on Mechatronics, 2025
2025
-
[4]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683
2018
-
[5]
Beyond the nav-graph: Vision-and-language navigation in continuous environments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 104– 120
2020
-
[6]
Waypoint models for instruction-guided navigation in continuous environments,
J. Krantz, A. Gokaslan, D. Batra, S. Lee, and O. Maksymets, “Waypoint models for instruction-guided navigation in continuous environments,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 162–15 171
2021
-
[7]
Bridging the gap be- tween learning in discrete and continuous environments for vision-and- language navigation,
Y . Hong, Z. Wang, Q. Wu, and S. Gould, “Bridging the gap be- tween learning in discrete and continuous environments for vision-and- language navigation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 15 439–15 449
2022
-
[8]
Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,
C. Cadena, L. Carlone, H. Carrillo, Y . Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, “Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,”IEEE Transactions on Robotics, vol. 32, no. 6, pp. 1309–1332, 2017
2017
-
[9]
ORB-SLAM: A versatile and accurate monocular SLAM system,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “ORB-SLAM: A versatile and accurate monocular SLAM system,”IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015
2015
-
[10]
Learning to explore using active neural SLAM,
D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, and R. Salakhutdinov, “Learning to explore using active neural SLAM,” inInternational Conference on Learning Representations, 2020
2020
-
[11]
Object goal navigation using goal-oriented semantic exploration,
D. S. Chaplot, D. Gandhi, A. Gupta, and R. Salakhutdinov, “Object goal navigation using goal-oriented semantic exploration,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 4247– 4258
2020
-
[12]
Cross-modal map learning for vision and language navigation,
G. Georgakis, K. Schmeckpeper, K. Wanchoo, S. Dan, E. Miltsakaki, D. Roth, and K. Daniilidis, “Cross-modal map learning for vision and language navigation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 15 460–15 470
2022
-
[13]
V olumetric environment representation for vision-language navigation,
R. Liu, W. Wang, and Y . Yang, “V olumetric environment representation for vision-language navigation,” inProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, 2024, pp. 16 317– 16 328
2024
-
[14]
Pivot: iterative visual prompting elicits actionable knowledge for vlms,
S. Nasiriany, F. Xia, W. Yu, T. Xiao, J. Liang, I. Dasgupta, A. Xie, D. Driess, A. Wahid, Z. Xuet al., “Pivot: iterative visual prompting elicits actionable knowledge for vlms,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 37 321– 37 341
2024
-
[15]
End-to-end naviga- tion with vision-language models: Transforming spatial reasoning into question-answering,
D. Goetting, H. G. Singh, and A. Loquercio, “End-to-end naviga- tion with vision-language models: Transforming spatial reasoning into question-answering,” inInternational Conference on Neuro-symbolic Systems. PMLR, 2025, pp. 22–35
2025
-
[16]
Wmnav: Integrating vision-language models into world models for object goal navigation,
D. Nie, X. Guo, Y . Duan, R. Zhang, and L. Chen, “Wmnav: Integrating vision-language models into world models for object goal navigation,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 2392–2399
2025
-
[17]
Pathdreamer: A world model for indoor navigation,
J. Y . Koh, H. Lee, Y . Yang, J. Baldridge, and P. Anderson, “Pathdreamer: A world model for indoor navigation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 738–14 748
2021
-
[18]
Dreamwalker: Mental planning for continuous vision-language navigation,
H. Wang, W. Liang, L. Van Gool, and W. Wang, “Dreamwalker: Mental planning for continuous vision-language navigation,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 10 873–10 883
2023
-
[19]
Navigation world models,
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun, “Navigation world models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 15 791–15 801
2025
-
[20]
Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments,
X. Yao, J. Gao, and C. Xu, “Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 5536–5546
2025
-
[21]
Improving vision-and-language navigation by gen- erating future-view image semantics,
J. Li and M. Bansal, “Improving vision-and-language navigation by gen- erating future-view image semantics,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 10 803–10 812
2023
-
[22]
Do visual imaginations improve vision-and-language navigation agents?
A. Perincherry, J. Krantz, and S. Lee, “Do visual imaginations improve vision-and-language navigation agents?” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 3846–3855
2025
-
[23]
arXiv preprint arXiv:2510.26909 (2025) 8
T. Windecker, M. Patel, M. Reuss, R. Schwarzkopf, C. Cadena, R. Li- outikov, M. Hutter, and J. Frey, “Navitrace: Evaluating embodied nav- igation of vision-language models,”arXiv preprint arXiv:2510.26909, 2025
-
[24]
Mindjourney: Test-time scaling with world models for spatial reason- ing,
Y . Yang, J. Liu, Z. Zhang, S. Zhou, R. Tan, J. Yang, Y . Du, and C. Gan, “Mindjourney: Test-time scaling with world models for spatial reason- ing,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
M. Cao, X. Li, X. Liu, I. Reid, and X. Liang, “Spatialdreamer: Incentivizing spatial reasoning via active mental imagery,”arXiv preprint arXiv:2512.07733, 2025
-
[26]
S. Yu, Y . Zhang, Z. Wang, J. Yoon, H. Yao, M. Ding, and M. Bansal, “When and how much to imagine: Adaptive test-time scaling with world models for visual spatial reasoning,”arXiv preprint arXiv:2602.08236, 2026
-
[27]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Target-Bench: Can Video World Models Achieve Mapless Path Planning with Semantic Targets?
D. Wang, H. Ye, Z. Liang, Z. Sun, Z. Lu, Y . Zhang, Y . Zhao, Y . Gao, M. Seegert, F. Sch¨aferet al., “Target-bench: Can world models achieve mapless path planning with semantic targets?”arXiv preprint arXiv:2511.17792, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Probabilistic robotics,
S. Thrun, “Probabilistic robotics,”Communications of the ACM, vol. 45, no. 3, pp. 52–57, 2002
2002
-
[30]
Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,
D. Shah, B. Osi ´nski, S. Levineet al., “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” inConference on robot learning. pmlr, 2023, pp. 492–504
2023
-
[31]
Imaginenav: Prompting vision- language models as embodied navigator through scene imagination,
X. Zhao, W. Cai, L. Tang, and T. Wang, “Imaginenav: Prompting vision- language models as embodied navigator through scene imagination,” in The Thirteenth International Conference on Learning Representations, 2025
2025
-
[32]
Depth anything 3: Recovering the visual space from any views,
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, Y . Zhao, S. Peng, H. Guo, X. Zhou, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,” inThe F ourteenth International Conference on Learning Representations, 2026, oral. [Online]. Available: https://openreview.net/forum?id=yirunib8l8
2026
-
[33]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[34]
Unipixel: Unified object referring and segmentation for pixel-level visual reasoning,
Y . Liu, Z. Ma, J. Pu, Z. Qi, Y . Wu, Y . Shan, and C. W. Chen, “Unipixel: Unified object referring and segmentation for pixel-level visual reasoning,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[35]
A fast marching level set method for monotonically advancing fronts
J. A. Sethian, “A fast marching level set method for monotonically advancing fronts.”proceedings of the National Academy of Sciences, vol. 93, no. 4, pp. 1591–1595, 1996
1996
-
[36]
Fast marching methods,
J. A. Sethian, “Fast marching methods,”SIAM review, vol. 41, no. 2, pp. 199–235, 1999
1999
-
[37]
Stable virtual camera: Generative view synthesis with diffusion models,
J. Zhou, H. Gao, V . V oleti, A. Vasishta, C.-H. Yao, M. Boss, P. Torr, C. Rupprecht, and V . Jampani, “Stable virtual camera: Generative view synthesis with diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 12 405–12 414
2025
-
[38]
Robots thinking fast and slow: on dual process theory and metacognition in embodied ai,
H. Posner, “Robots thinking fast and slow: on dual process theory and metacognition in embodied ai,” OpenReview, 2020
2020
-
[39]
Ground slow, move fast: A dual-system foundation model for generalizable vision- language navigation,
M. Wei, C. Wan, J. Peng, X. Yu, Y . Yang, D. Feng, W. Cai, C. Zhu, T. Wang, J. Pang, and X. Liu, “Ground slow, move fast: A dual-system foundation model for generalizable vision- language navigation,” inThe F ourteenth International Conference on Learning Representations, 2026, poster. [Online]. Available: https://openreview.net/forum?id=GK4rznYwhn
2026
-
[40]
X. Zhou, T. Xiao, L. Liu, Y . Wang, M. Chen, X. Meng, X. Wang, W. Feng, W. Sui, and Z. Su, “Fsr-vln: Fast and slow reasoning for vision-language navigation with hierarchical multi-modal scene graph,” arXiv preprint arXiv:2509.13733, 2025. 10 Supplementary Material This supplementary material provides additional implemen- tation details and qualitative evi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.