Recognition: 2 theorem links
· Lean TheoremImVideoEdit: Image-learning Video Editing via 2D Spatial Difference Attention Blocks
Pith reviewed 2026-05-10 17:46 UTC · model grok-4.3
The pith
Video editing can be learned from image pairs by freezing temporal modules and focusing spatial edits with difference attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
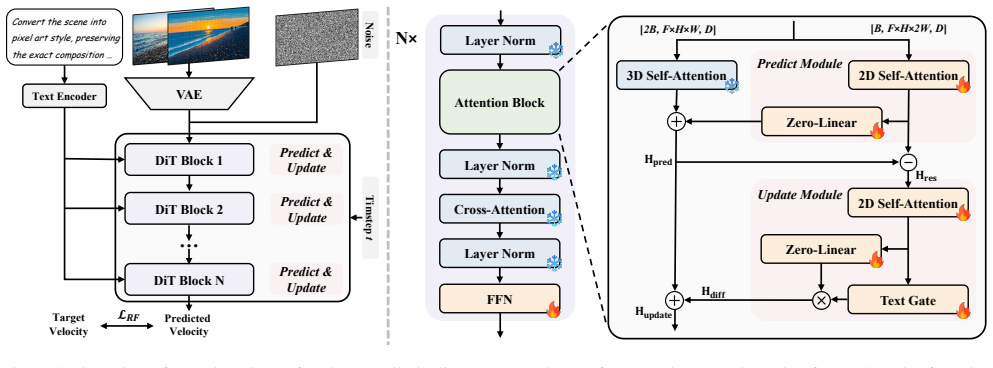
The central claim is that video editing can be formulated as a decoupled spatiotemporal process: temporal dynamics are preserved by freezing pretrained 3D attention modules while spatial content is selectively modified through 2D spatial difference attention blocks trained exclusively on image pairs, together with text-guided dynamic semantic gating for adaptive control, yielding results that match larger video-trained models despite minimal data and compute.
What carries the argument
The Predict-Update Spatial Difference Attention module, which progressively extracts spatial differences between input and target frames and injects them into the frozen temporal backbone, augmented by text-guided dynamic semantic gating that enables implicit, mask-free modifications.
If this is right
- Video editing becomes feasible with existing image datasets instead of costly paired video collections.
- Training time and compute drop sharply while preserving editing quality and frame coherence.
- Text instructions can drive edits adaptively without manual masks or external segmentation.
- Pretrained video generators can be extended to new editing tasks by adding only the spatial difference blocks.
- The same frozen-temporal approach may generalize to other tasks that require precise spatial control over time.
Where Pith is reading between the lines
- The method could reduce barriers for custom video tools in domains like film post-production or social media content creation.
- Extending the single-frame training assumption to multi-frame image sequences might improve handling of subtle motions without full video data.
- Integration with newer image-editing backbones could further lower data requirements for specialized video effects.
- Limits may appear in videos where spatial and temporal changes are tightly coupled, such as fluid dynamics or complex interactions.
Load-bearing premise
Freezing the pretrained 3D attention modules while training only on single-frame image pairs will keep the original temporal dynamics intact and prevent new inconsistencies during spatial edits.
What would settle it
Apply the trained model to videos containing rapid non-rigid motion or long sequences and measure drop in temporal consistency scores relative to a video-trained baseline; a large drop would falsify the decoupling premise.
Figures








read the original abstract
Current video editing models often rely on expensive paired video data, which limits their practical scalability. In essence, most video editing tasks can be formulated as a decoupled spatiotemporal process, where the temporal dynamics of the pretrained model are preserved while spatial content is selectively and precisely modified. Based on this insight, we propose ImVideoEdit, an efficient framework that learns video editing capabilities entirely from image pairs. By freezing the pre-trained 3D attention modules and treating images as single-frame videos, we decouple the 2D spatial learning process to help preserve the original temporal dynamics. The core of our approach is a Predict-Update Spatial Difference Attention module that progressively extracts and injects spatial differences. Rather than relying on rigid external masks, we incorporate a Text-Guided Dynamic Semantic Gating mechanism for adaptive and implicit text-driven modifications. Despite training on only 13K image pairs for 5 epochs with exceptionally low computational overhead, ImVideoEdit achieves editing fidelity and temporal consistency comparable to larger models trained on extensive video datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
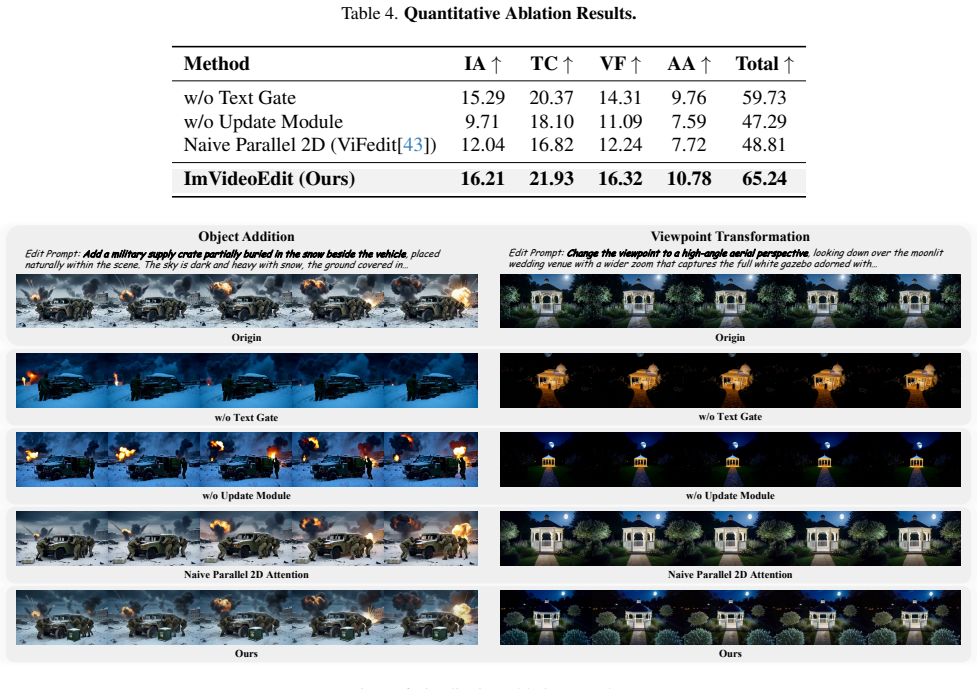
Summary. The manuscript proposes ImVideoEdit, an efficient video editing framework that learns editing capabilities exclusively from static image pairs. By freezing pretrained 3D attention modules and treating images as single-frame videos, the approach decouples spatial editing from temporal dynamics. The core contributions are a Predict-Update Spatial Difference Attention module for progressive spatial difference injection and a Text-Guided Dynamic Semantic Gating mechanism for adaptive text-driven edits. The central claim is that training on only 13K image pairs for 5 epochs yields editing fidelity and temporal consistency comparable to larger models trained on extensive video datasets, at exceptionally low computational cost.
Significance. If the empirical claims hold, the work would be significant for demonstrating that video editing can be effectively learned from image data alone, substantially reducing the need for costly paired video datasets and lowering computational barriers. The decoupling strategy via frozen 3D modules and the low-overhead training regime represent a practical efficiency advance in computer vision, with potential to influence data-efficient approaches in generative video tasks.
major comments (2)
- [Method section (Predict-Update Spatial Difference Attention and training procedure)] The central claim of preserved temporal consistency rests on the assumption that frozen pretrained 3D attention modules will continue to enforce original dynamics after spatial edits are injected by the new 2D modules. However, the training procedure uses only T=1 image pairs with no motion examples, no temporal conditioning on the 2D blocks, and no consistency regularizer, providing no gradient signal for how edits behave under inter-frame motion or changing semantics. This directly undermines the temporal consistency claim and requires explicit validation on multi-frame video inputs with motion.
- [Abstract and Experiments section] The abstract asserts 'comparable' editing fidelity and temporal consistency to larger video-trained models, yet the provided text contains no quantitative metrics, baselines, ablation studies, or error analysis (e.g., no PSNR/SSIM, CLIP scores, or user studies on standard benchmarks). Without these in the experiments, the performance claim cannot be evaluated and is load-bearing for the efficiency narrative.
minor comments (2)
- [Title and §3] The title refers to '2D Spatial Difference Attention Blocks' while the text introduces 'Predict-Update Spatial Difference Attention module'; clarify the exact relationship and whether the blocks are the same component.
- [Method section] Notation for the gating mechanism and difference attention could be formalized with equations to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help us improve the clarity and rigor of our manuscript. We address each major comment point by point below, providing our honest assessment and indicating planned revisions.
read point-by-point responses
-
Referee: [Method section (Predict-Update Spatial Difference Attention and training procedure)] The central claim of preserved temporal consistency rests on the assumption that frozen pretrained 3D attention modules will continue to enforce original dynamics after spatial edits are injected by the new 2D modules. However, the training procedure uses only T=1 image pairs with no motion examples, no temporal conditioning on the 2D blocks, and no consistency regularizer, providing no gradient signal for how edits behave under inter-frame motion or changing semantics. This directly undermines the temporal consistency claim and requires explicit validation on multi-frame video inputs with motion.
Authors: We thank the referee for this insightful observation on our validation approach. The design of ImVideoEdit explicitly decouples spatial editing from temporal modeling by freezing the pretrained 3D attention modules (which were trained on large-scale video data to capture dynamics) and applying the new 2D Predict-Update Spatial Difference Attention blocks only to spatial differences extracted from image pairs treated as single-frame videos. This ensures that no temporal parameters are updated, so the original dynamics remain enforced during inference on multi-frame inputs. The Text-Guided Dynamic Semantic Gating further operates adaptively on semantics without temporal conditioning. While this architectural choice provides the theoretical basis for consistency without motion-specific training signals, we agree that direct empirical validation on videos with motion would strengthen the claim. We will add such experiments, including qualitative results on multi-frame sequences with motion, to the revised manuscript. revision: partial
-
Referee: [Abstract and Experiments section] The abstract asserts 'comparable' editing fidelity and temporal consistency to larger video-trained models, yet the provided text contains no quantitative metrics, baselines, ablation studies, or error analysis (e.g., no PSNR/SSIM, CLIP scores, or user studies on standard benchmarks). Without these in the experiments, the performance claim cannot be evaluated and is load-bearing for the efficiency narrative.
Authors: We agree that quantitative metrics are essential to substantiate the efficiency and performance claims. The manuscript does include comparative evaluations and ablations demonstrating the benefits of the proposed modules, but to ensure the abstract's assertions are fully supported and easily verifiable, we will expand the Experiments section in the revision. This will incorporate explicit quantitative results (e.g., PSNR, SSIM, CLIP similarity), direct baselines against video-trained models, ablation studies isolating each component, error analysis, and user study outcomes on standard benchmarks. These additions will be presented clearly to allow rigorous evaluation of the fidelity and consistency claims. revision: yes
Circularity Check
No significant circularity; derivation is architectural and empirical.
full rationale
The paper's core claim rests on an architectural insight (decoupling spatiotemporal processes by freezing pretrained 3D attention modules and training 2D spatial edits on static image pairs) followed by empirical validation. No equations, derivations, or predictions are shown that reduce to self-referential definitions, fitted inputs renamed as outputs, or load-bearing self-citations. The Predict-Update Spatial Difference Attention and Text-Guided Dynamic Semantic Gating modules are presented as novel components trained directly on the 13K image pairs, with no mathematical reduction to prior results by construction. The approach is self-contained against external benchmarks via reported comparisons, yielding a normal non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Freezing pretrained 3D attention modules preserves temporal dynamics when images are treated as single-frame videos
invented entities (2)
-
Predict-Update Spatial Difference Attention module
no independent evidence
-
Text-Guided Dynamic Semantic Gating mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBy freezing the pre-trained 3D attention modules and treating images as single-frame videos, we decouple the 2D spatial learning process to help preserve the original temporal dynamics. The core of our approach is a Predict-Update Spatial Difference Attention module...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat embedding and J-cost positivity unclearwe introduce an innovative Predict-Update Spatial Difference Attention Module... Hpred = H3D + ZeroLin1(H(1)2D); Hres = Hpred - H(1)2D; Hupdate = Hpred + G ⊙ ZeroLin2(Hdiff)
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[3]
Qingyan Bai, Qiuyu Wang, Hao Ouyang, Yue Yu, Hanlin Wang, Wen Wang, Ka Leong Cheng, Shuailei Ma, Yanhong Zeng, Zichen Liu, et al. Scaling instruction-based video editing with a high-quality synthetic dataset.arXiv preprint arXiv:2510.15742, 2025. 3
-
[4]
Gemini 3.0 pro, 2025
Google DeepMind. Gemini 3.0 pro, 2025. 4
2025
-
[5]
Veo 3 technical report
Google DeepMind. Veo 3 technical report. Technical report, Google DeepMind, 2025. 1
2025
-
[6]
Stochastic video generation with a learned prior
Emily Denton and Rob Fergus. Stochastic video generation with a learned prior. InInternational conference on machine learning, pages 1174–1183. PMLR, 2018. 3
2018
-
[7]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xi- aojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113,
work page internal anchor Pith review arXiv
-
[8]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text- to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[9]
Haoyang He, Jie Wang, Jiangning Zhang, Zhucun Xue, Xingyuan Bu, Qiangpeng Yang, Shilei Wen, and Lei Xie. Openve-3m: A large-scale high-quality dataset for instruction-guided video editing.arXiv preprint arXiv:2512.07826, 2025. 3
-
[10]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[11]
Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.Advances in neural information processing systems, 35:8633–8646, 2022. 3
2022
-
[12]
VBench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
2024
-
[13]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17191–17202, 2025. 3, 6
2025
-
[14]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22511–22521, 2023. 3
2023
-
[16]
Xinyao Liao, Xianfang Zeng, Ziye Song, Zhoujie Fu, Gang Yu, and Guosheng Lin. In-context learning with unpaired clips for instruction-based video editing.arXiv preprint arXiv:2510.14648, 2025. 6
-
[17]
Kiwi-edit: Versatile video edit- ing via instruction and reference guidance, 2026
Yiqi Lin, Guoqiang Liang, Ziyun Zeng, Zechen Bai, Yanzhe Chen, and Mike Zheng Shou. Kiwi-edit: Versatile video edit- ing via instruction and reference guidance, 2026. 6
2026
-
[18]
Yiqi Lin, Guoqiang Liang, Ziyun Zeng, Zechen Bai, Yanzhe Chen, and Mike Zheng Shou. Kiwi-edit: Versatile video edit- ing via instruction and reference guidance.arXiv preprint arXiv:2603.02175, 2026. 3
work page internal anchor Pith review arXiv 2026
-
[19]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 5 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, pages 4296–4304, 2024. 3
2024
-
[22]
Universal few-shot spatial con- trol for diffusion models.arXiv preprint arXiv:2509.07530,
Kiet T Nguyen, Chanhyuk Lee, Donggyun Kim, Dong Hoon Lee, and Seunghoon Hong. Universal few-shot spatial con- trol for diffusion models.arXiv preprint arXiv:2509.07530,
-
[23]
Gpt 5.3, 2025
OpenAI. Gpt 5.3, 2025. 4
2025
-
[24]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[25]
Fatezero: Fus- ing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fus- ing attentions for zero-shot text-based video editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15932–15942, 2023. 3
2023
-
[26]
SpotEdit: Selective region editing in diffusion transformers.arXiv preprint arXiv:2512.22323, 2025
Zhibin Qin, Zhenxiong Tan, Zeqing Wang, Songhua Liu, and Xinchao Wang. Spotedit: Selective region editing in diffu- sion transformers.arXiv preprint arXiv:2512.22323, 2025. 3
-
[27]
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yan- fei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio- visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025. 1, 6
-
[28]
Sg-adapter: En- hancing text-to-image generation with scene graph guidance
Guibao Shen, Luozhou Wang, Jiantao Lin, Wenhang Ge, Chaozhe Zhang, Xin Tao, Yuan Zhang, Pengfei Wan, Zhongyuan Wang, Guangyong Chen, et al. Sg-adapter: En- hancing text-to-image generation with scene graph guidance. arXiv preprint arXiv:2405.15321, 2024. 3
-
[29]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review arXiv
-
[30]
Ominicontrol: Minimal and univer- sal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and univer- sal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14940–14950, 2025. 3
2025
-
[31]
arXiv preprint arXiv:2507.06119 , year=
Zhiyu Tan, Hao Yang, Luozheng Qin, Jia Gong, Meng- ping Yang, and Hao Li. Omni-video: Democratizing uni- fied video understanding and generation.arXiv preprint arXiv:2507.06119, 2025. 3, 6
-
[32]
Any-to-any generation via composable diffu- sion.Advances in Neural Information Processing Systems, 36:16083–16099, 2023
Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, and Mohit Bansal. Any-to-any generation via composable diffu- sion.Advances in Neural Information Processing Systems, 36:16083–16099, 2023. 3
2023
-
[33]
Lucy edit: Open-weight text-guided video editing, 2025
DecartAI Team. Lucy edit: Open-weight text-guided video editing, 2025. 6
2025
-
[34]
Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025. 3
-
[35]
Generating videos with scene dynamics.Advances in neu- ral information processing systems, 29, 2016
Carl V ondrick, Hamed Pirsiavash, and Antonio Torralba. Generating videos with scene dynamics.Advances in neu- ral information processing systems, 29, 2016. 3
2016
-
[36]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Cong Wei, Quande Liu, Zixuan Ye, Qiulin Wang, Xintao Wang, Pengfei Wan, Kun Gai, and Wenhu Chen. Univideo: Unified understanding, generation, and editing for videos. arXiv preprint arXiv:2510.08377, 2025. 3
-
[38]
Qwen-image technical report,
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, De- qing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
-
[39]
Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025
Guangxuan Xiao, Tianwei Yin, William T Freeman, Fr ´edo Durand, and Song Han. Fastcomposer: Tuning-free multi- subject image generation with localized attention.Interna- tional Journal of Computer Vision, 133(3):1175–1194, 2025. 3
2025
-
[40]
Hao Yang, Zhiyu Tan, Jia Gong, Luozheng Qin, Hesen Chen, Xiaomeng Yang, Yuqing Sun, Yuetan Lin, Mengping Yang, and Hao Li. Omni-video 2: Scaling mllm-conditioned diffu- sion for unified video generation and editing.arXiv preprint arXiv:2602.08820, 2026. 6
-
[41]
Confctrl: Enabling precise camera control in video dif- fusion via confidence-aware interpolation, 2026
Liudi Yang, George Eskandar, Fengyi Shen, Mohammad Al- tillawi, Yang Bai, Chi Zhang, Ziyuan Liu, and Abhinav Val- ada. Confctrl: Enabling precise camera control in video dif- fusion via confidence-aware interpolation, 2026. 2
2026
-
[42]
Con- sistedit: Highly consistent and precise training-free visual editing
Zixin Yin, Ling-Hao Chen, Lionel Ni, and Xili Dai. Con- sistedit: Highly consistent and precise training-free visual editing. InProceedings of the SIGGRAPH Asia 2025 Con- ference Papers, pages 1–11, 2025. 3
2025
-
[43]
Vifeedit: A video-free tuner of your video diffusion transformer, 2026
Ruonan Yu, Zhenxiong Tan, Zigeng Chen, Songhua Liu, and Xinchao Wang. Vifeedit: A video-free tuner of your video diffusion transformer, 2026. 1, 9
2026
-
[44]
Veg- gie: Instructional editing and reasoning video concepts with grounded generation
Shoubin Yu, Difan Liu, Ziqiao Ma, Yicong Hong, Yang Zhou, Hao Tan, Joyce Chai, and Mohit Bansal. Veg- gie: Instructional editing and reasoning video concepts with grounded generation. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 15147– 15158, 2025. 3
2025
-
[45]
Group relative attention guidance for image editing
Xuanpu Zhang, Xuesong Niu, Ruidong Chen, Dan Song, Jianhao Zeng, Penghui Du, Haoxiang Cao, Kai Wu, and An- an Liu. Group relative attention guidance for image editing. arXiv preprint arXiv:2510.24657, 2025. 3
-
[46]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu 11 Qiao, and Ziwei Liu. VBench-2.0: Advancing video genera- tion benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025. 7 12 A. Robustness of VLM-Assisted Dataset Con- struction The cross-validation results of the evalu...
work page internal anchor Pith review arXiv 2025
-
[47]
Instruction Adherence (Max: 30 points): •Did the editing strictly follow the given instruction? •Are the requested changes accurately reflected without altering unintended elements?
-
[48]
You must zoom in on high-frequency details
Temporal Consistency & Micro-Stability (Max: 30 points) -STRICT DEDUCTION RULES: •VLM Warning: Do not just look at the overall subject. You must zoom in on high-frequency details. •Scoring Anchor: - 28-30 pts: Perfect stability, identical to the physics of a real camera. - 20-27 pts: Overall stable, but minor ”AI boiling” (micro-flickering of pixels) on e...
-
[49]
Evaluate the AI rendering quality
Texture Sharpness & Anti-Smoothing (Max: 25 points) -CALIBRATED FOR AI: •Do not compare this to an 8K cinema camera. Evaluate the AI rendering quality. We are looking for SHARPNESS vs. PLASTICITY . •Focus on the materials: the velvet texture of the blue dress, the individual threads of the embroidery, and the natural pores/lighting on the skin. •Scoring A...
-
[50]
# Output Format Provide your response strictly in the following JSON format
Artifact Absence (Max: 15 points): •Are there any visible AI generation artifacts (e.g., floating pixels, anatomical distortions, weird edge blending)? •The edited areas should blend seamlessly with the original unedited parts. # Output Format Provide your response strictly in the following JSON format. Do not include a total score, only the sub-scores fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.