Recognition: no theorem link
Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
Pith reviewed 2026-05-15 17:32 UTC · model grok-4.3
The pith
Kiwi-Edit achieves state-of-the-art results in controllable video editing by combining instructions with reference images through a new data pipeline and architecture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
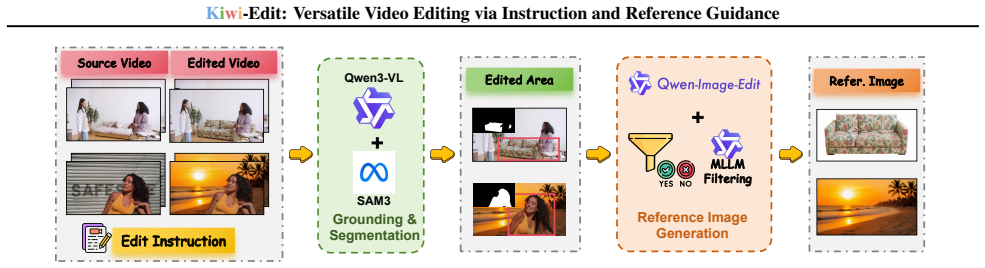
A scalable data generation pipeline converts existing video editing pairs into quadruplets with synthesized reference scaffolds created by image generative models; this yields the RefVIE dataset and benchmark, while the Kiwi-Edit architecture integrates learnable queries and latent visual features for reference semantic guidance and is trained through a progressive multi-stage curriculum to improve both instruction following and reference fidelity.
What carries the argument
The Kiwi-Edit unified editing architecture that combines learnable queries with latent visual features to supply reference semantic guidance, backed by the data pipeline that produces RefVIE quadruplets.
If this is right
- Higher accuracy when following complex natural-language instructions during video edits.
- Stronger visual consistency with the provided reference images in the output video.
- New state-of-the-art scores on the RefVIE-Bench evaluation suite.
- A reusable large-scale dataset and benchmark that can support further work on combined instruction and reference editing.
Where Pith is reading between the lines
- The same data-pipeline idea could be applied to other media such as image or audio editing where paired reference data is scarce.
- Professional video workflows might become faster if editors can supply quick reference images instead of writing exhaustive text descriptions.
- Further tests on highly varied real-world references could highlight where additional fine-tuning is needed for robust deployment.
Load-bearing premise
The image generative models used to synthesize reference scaffolds produce outputs that are high-fidelity and unbiased enough for models trained on them to generalize cleanly to real user references.
What would settle it
A large performance drop on editing tasks when the model receives authentic user-provided reference images instead of the synthesized scaffolds from the data pipeline.
Figures










read the original abstract
Instruction-based video editing has witnessed rapid progress, yet current methods often struggle with precise visual control, as natural language is inherently limited in describing complex visual nuances. Although reference-guided editing offers a robust solution, its potential is currently bottlenecked by the scarcity of high-quality paired training data. To bridge this gap, we introduce a scalable data generation pipeline that transforms existing video editing pairs into high-fidelity training quadruplets, leveraging image generative models to create synthesized reference scaffolds. Using this pipeline, we construct RefVIE, a large-scale dataset tailored for instruction-reference-following tasks, and establish RefVIE-Bench for comprehensive evaluation. Furthermore, we propose a unified editing architecture, Kiwi-Edit, that synergizes learnable queries and latent visual features for reference semantic guidance. Our model achieves significant gains in instruction following and reference fidelity via a progressive multi-stage training curriculum. Extensive experiments demonstrate that our data and architecture establish a new state-of-the-art in controllable video editing. All datasets, models, and code is released at https://github.com/showlab/Kiwi-Edit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a scalable data generation pipeline that uses image generative models to synthesize reference scaffolds from existing video editing pairs, creating the RefVIE dataset and RefVIE-Bench. It proposes Kiwi-Edit, a unified architecture combining learnable queries and latent visual features for reference semantic guidance, trained via a progressive multi-stage curriculum. The central claim is that this data and architecture yield significant gains in instruction following and reference fidelity, establishing a new state-of-the-art in controllable video editing.
Significance. If the empirical claims hold after addressing validation gaps, the work would be significant for the field: it directly tackles data scarcity in reference-guided video editing with a released large-scale dataset and code, introduces a practical architecture for combining textual instructions with visual references, and provides a benchmark for evaluation. The progressive training and dual guidance mechanism could influence future controllable generation models if the generalization from synthetic to real references is demonstrated.
major comments (2)
- [Section 3] Data generation pipeline (Section 3): The central claim that RefVIE enables generalization to real user-provided references rests on the assumption that image generative models produce unbiased, artifact-free reference scaffolds. No quantitative metrics (e.g., FID, perceptual similarity, or distribution divergence scores) are reported comparing synthetic scaffolds to real references, leaving the risk of embedded stylistic or lighting biases unaddressed and directly threatening the SOTA generalization results.
- [Section 5] Experiments and ablations (Section 5): The reported SOTA gains in instruction following and reference fidelity are load-bearing for the paper's contribution, yet the manuscript lacks ablations isolating the contribution of the progressive multi-stage curriculum versus the reference guidance components (learnable queries and latent features). Without these, it is unclear whether the architecture or the synthetic data pipeline drives the improvements.
minor comments (2)
- The abstract states that 'all datasets, models, and code is released' but the manuscript does not specify the exact license, access procedure, or version of the released assets, which should be clarified for reproducibility.
- Figure captions for qualitative results could more explicitly label which examples use real user references versus synthetic ones to help readers assess generalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the claims without misrepresenting the original results.
read point-by-point responses
-
Referee: [Section 3] Data generation pipeline (Section 3): The central claim that RefVIE enables generalization to real user-provided references rests on the assumption that image generative models produce unbiased, artifact-free reference scaffolds. No quantitative metrics (e.g., FID, perceptual similarity, or distribution divergence scores) are reported comparing synthetic scaffolds to real references, leaving the risk of embedded stylistic or lighting biases unaddressed and directly threatening the SOTA generalization results.
Authors: We agree that quantitative validation of the synthetic scaffolds against real references would further support the generalization claims. In the revised manuscript we will add a dedicated analysis subsection reporting FID, LPIPS perceptual similarity, and KL divergence between the generated reference scaffolds and a held-out set of real reference images. These metrics will be computed using the same conditioning signals as the pipeline to quantify any residual stylistic or lighting bias. revision: yes
-
Referee: [Section 5] Experiments and ablations (Section 5): The reported SOTA gains in instruction following and reference fidelity are load-bearing for the paper's contribution, yet the manuscript lacks ablations isolating the contribution of the progressive multi-stage curriculum versus the reference guidance components (learnable queries and latent features). Without these, it is unclear whether the architecture or the synthetic data pipeline drives the improvements.
Authors: We acknowledge the value of more explicit isolation. The current manuscript already contains component-wise ablations for learnable queries and latent features (Section 5.3) as well as a comparison of progressive versus single-stage training. In the revision we will add a consolidated ablation table that systematically varies the curriculum, the reference guidance modules, and the synthetic data source independently, reporting instruction-following and reference-fidelity metrics for each configuration to clarify the relative contributions. revision: yes
Circularity Check
No circularity: empirical pipeline and training results are independent of inputs
full rationale
The paper introduces a data generation pipeline that synthesizes reference scaffolds from existing video editing pairs using external image generative models, constructs the RefVIE dataset, and trains Kiwi-Edit via a progressive multi-stage curriculum. All central claims rest on new empirical results on RefVIE-Bench rather than any derivation, equation, or self-citation that reduces outputs to inputs by construction. No self-definitional steps, fitted predictions, or load-bearing self-citations appear in the provided text. The architecture (learnable queries + latent features) and evaluation are presented as novel and externally validated through experiments.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
Sparkle: Realizing Lively Instruction-Guided Video Background Replacement via Decoupled Guidance
Sparkle supplies a large-scale dataset and benchmark for instruction-driven video background replacement, enabling models that generate more natural and temporally consistent new scenes than earlier approaches.
-
InsEdit: Towards Instruction-based Visual Editing via Data-Efficient Video Diffusion Models Adaptation
InsEdit adapts a video diffusion backbone for text-instruction video editing via Mutual Context Attention, achieving SOTA open-source results with O(100K) data while also supporting image editing.
-
ImVideoEdit: Image-learning Video Editing via 2D Spatial Difference Attention Blocks
ImVideoEdit learns video editing from 13K image pairs by decoupling spatial modifications from frozen temporal dynamics in pretrained models, matching larger video-trained systems in fidelity and consistency.
-
Mamoda2.5: Enhancing Unified Multimodal Model with DiT-MoE
Mamoda2.5 is a 25B-parameter DiT-MoE unified AR-Diffusion model that reaches top video generation and editing benchmarks with 4-step inference up to 95.9x faster than baselines.
Reference graph
Works this paper leans on
-
[1]
- Object identity, attributes (color, shape, material, style), and edit type must be consistent
Instruction-Follow Consistency - The reference image must accurately represent the result of the input edit instruction as shown in the edited image. - Object identity, attributes (color, shape, material, style), and edit type must be consistent. - No contradictions with the edited result
-
[2]
- Coherent structure, plausible lighting and texture
Image Quality & Focus - Clear, realistic, and artifact-free. - Coherent structure, plausible lighting and texture. - The main subject must be clear and not overwhelmed by distracting elements. Scoring Output one overall score (1-10). Final Output (JSON Only) {”score”: 1-10 integer} C. Benchmark Details The following prompt is used for RefVIE-Bench evaluat...
work page 2025
-
[3]
Object not swapped/added, or a completely unrelated object appears
-
[4]
Object is changed, but looks nothing like the reference image (wrong color, shape, or class)
-
[5]
Object class is correct, but identity details (texture, specific markings, logos) differ significantly from the reference image
-
[6]
High resemblance to the reference image; correct geometry and texture, with only minor variations in fine details
-
[7]
Temporal Consistency & Texture Fidelity
Perfect identity transfer: The object in the video is indistinguishable from the reference image in terms of texture, structure, and style, while maintaining the correct pose for the scene. Temporal Consistency & Texture Fidelity
-
[8]
The new object deforms, melts, or changes shape uncontrollably across frames
-
[9]
Texture ”swims” or flickers; resolution drops significantly compared to the rest of the video; object vanishes in some frames
-
[10]
Object is stable in form, but texture details blur or shift slightly during motion; style looks somewhat pasted-on
-
[11]
Object is structurally solid and texture is consistent; minor edge shimmer or noise visible only on close inspection
-
[12]
Physical Integration & Tracking
Completely temporally coherent; the object maintains rigid structure (or appropriate flexibility) and consistent texture details in every single frame, exactly like a real object. Physical Integration & Tracking
-
[13]
Object slides around (bad motion tracking); does not follow camera or scene movement; looks like a sticker on the screen
-
[14]
Missing interactions: No shadows, reflections, or occlusion handling (e.g., object appears on top of things that should be in front of it)
-
[15]
Motion tracking is decent with slight drift; lighting is flat or generic; occlusion is roughly correct but imprecise
-
[16]
Accurate tracking; lighting and shadows match the scene’s direction and intensity; correct occlusion handling
-
[17]
Physically flawless: Motion tracking, perspective changes, motion blur, shadows, reflections, and lighting interactions are indistinguishable from reality; the object feels physically present in the scene. The second and third score should no higher than first score!!! Example Response Format: Brief reasoning: A short explanation of the score based on the...
-
[18]
Background not changed, or the foreground subject is severely damaged/removed
-
[19]
Background changed but bears no resemblance to the reference image; foreground edges are significantly cut off or distorted
-
[20]
Background resembles the reference but lacks key details; foreground is mostly preserved but has noticeable missing parts or artifacts
-
[21]
12 Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
Background clearly matches the reference image structure and style; foreground subject is fully preserved with only minor edge errors. 12 Kiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
-
[22]
Matting Quality & Temporal Stability
Perfect execution: The background is an exact semantic and stylistic match to the reference image, and the foreground subject is preserved pixel-perfectly throughout the entire duration. Matting Quality & Temporal Stability
-
[23]
Severe flickering; the background or foreground jitters erratically; distinct ”boiling” artifacts on edges
-
[24]
Obvious seams, halos, or ”green screen” outlines around the subject; background moves unnaturally or freezes while the camera moves
-
[25]
Edges are generally stable but soft/fuzzy; minor flickering in complex areas (e.g., hair, transparent objects); background stability is acceptable
-
[26]
Clean edges with minimal temporal noise; background motion aligns well with camera movement; casual viewers notice no matting errors
-
[27]
Completely seamless composition; hair/transparency details are perfectly matted; background and foreground interact with perfect temporal stability in every frame. Visual Harmony & Perspective
-
[28]
Background looks like a flat 2D image pasted behind a 3D subject; severe perspective or lighting mismatch (e.g., shadows point wrong way)
-
[29]
Lighting clashes (e.g., sunny background, dark foreground); no depth integration; subject looks ”floating.”
-
[30]
Perspective and scale are roughly correct; lighting is neutral but doesn’t explicitly match the new environment’s ambience
-
[31]
Good environmental integration; foreground lighting tones reflect the new background; cast shadows are present and mostly accurate
-
[32]
Photorealistic integration: Depth of field, motion blur, lighting, and color grading of the foreground perfectly match the reference background; the composite looks like a single, raw video capture. The second and third score should no higher than first score!!! Example Response Format: Brief reasoning: A short explanation of the score based on the criter...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.