Recognition: no theorem link
A unifying view of contrastive learning, importance sampling, and bridge sampling for energy-based models
Pith reviewed 2026-05-10 17:50 UTC · model grok-4.3
The pith
A unifying framework shows that noise contrastive estimation, reverse logistic regression, multiple importance sampling, and bridge sampling for energy-based models are equivalent under specific conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We provide a unified framework that connects noise contrastive estimation (NCE), reverse logistic regression (RLR), multiple importance sampling (MIS), and bridge sampling within the context of EBMs. We further show that these methods are equivalent under specific conditions. This unified perspective clarifies relationships among existing methods and enables the development of new estimators, with the potential to improve statistical and computational efficiency. Furthermore, this study helps elucidate the success of NCE in terms of its flexibility and robustness, while also identifying scenarios in which its performance can be further improved.
What carries the argument
The unified framework that re-expresses the objectives and estimators of NCE, RLR, MIS, and bridge sampling in common terms to establish their connections and conditional equivalences for energy-based models.
If this is right
- New hybrid estimators can be derived by mixing elements from the connected methods to improve efficiency.
- The practical success of noise contrastive estimation is explained by its flexibility and robustness inside the shared framework.
- Scenarios where current methods underperform can be identified and addressed through the equivalences.
- Relationships among contrastive and sampling techniques are clarified to guide selection and combination of estimators.
Where Pith is reading between the lines
- The unification could be tested on other contrastive objectives outside energy-based models to check broader applicability.
- Numerical comparisons on high-dimensional models would show whether the new estimators deliver measurable gains in accuracy or speed.
- Robustness properties identified for one method might transfer to the others by using the common framework as a design tool.
Load-bearing premise
The equivalences and new estimators hold only under specific conditions on the sampling distributions and model forms.
What would settle it
Applying NCE, RLR, MIS, and bridge sampling to the same energy-based model using matching sampling distributions and checking whether the resulting parameter estimates and performance metrics coincide would falsify the claimed equivalence if systematic differences appear.
Figures




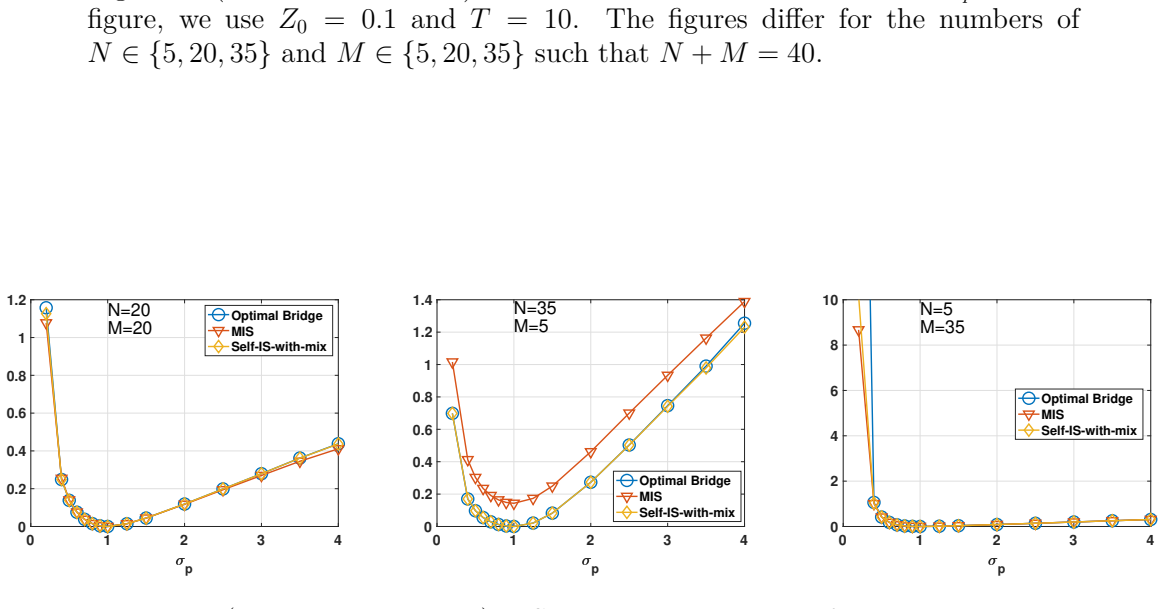

read the original abstract
In the last decades, energy-based models (EBMs) have become an important class of probabilistic models in which a component of the likelihood is intractable and therefore cannot be evaluated explicitly. Consequently, parameter estimation in EBMs is challenging for conventional inference methods. In this work, we provide a unified framework that connects noise contrastive estimation (NCE), reverse logistic regression (RLR), multiple importance sampling (MIS), and bridge sampling within the context of EBMs. We further show that these methods are equivalent under specific conditions. This unified perspective clarifies relationships among existing methods and enables the development of new estimators, with the potential to improve statistical and computational efficiency. Furthermore, this study helps elucidate the success of NCE in terms of its flexibility and robustness, while also identifying scenarios in which its performance can be further improved. Hence, rather than being a purely descriptive review, this work offers a unifying perspective and additional methodological contributions. The MATLAB code used in the numerical experiments is also made freely available to support the reproducibility of the results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a unifying framework connecting noise contrastive estimation (NCE), reverse logistic regression (RLR), multiple importance sampling (MIS), and bridge sampling for parameter estimation in energy-based models (EBMs) with intractable likelihoods. It claims these methods are equivalent under specific conditions on proposal/noise distributions and model forms, develops new estimators from this perspective, and supports the claims with numerical experiments whose MATLAB code is made freely available.
Significance. If the equivalences hold under the stated conditions, the work would clarify interrelationships among established EBM estimators, explain NCE's observed robustness, and enable new hybrid estimators with potential gains in statistical and computational efficiency. The use of standard statistical identities rather than ad-hoc constructions, combined with explicit reproducibility via open code, adds value for practitioners working with intractable partition functions.
minor comments (2)
- The title references 'contrastive learning' while the abstract and claims center on NCE; a short clarifying sentence relating NCE to the broader contrastive-learning literature would improve consistency.
- The abstract states that equivalences hold 'under specific conditions'; a compact theorem or proposition that enumerates these conditions (e.g., requirements on the noise distribution relative to the proposal) would make the scope of the unification immediately visible to readers.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its significance, and recommendation for minor revision. The assessment that the unifying framework clarifies relationships among NCE, RLR, MIS, and bridge sampling for EBMs is appreciated. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected in unification of estimators
full rationale
The paper derives a unified framework by mapping NCE, RLR, MIS, and bridge sampling onto common sampling identities and objectives for EBM parameter estimation, showing equivalences only under explicitly stated conditions on proposal distributions and model forms. These steps rely on standard statistical identities (e.g., importance sampling ratios and logistic regression objectives) rather than any self-definitional reduction, fitted parameter renamed as prediction, or load-bearing self-citation chain. The central claim remains independent of its inputs, with derivations that are externally verifiable and do not collapse by construction; any self-citations serve only as background and are not required to establish the equivalences.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Implicit generation and modeling with energy based models,
Y. Du and I. Mordatch, “Implicit generation and modeling with energy based models,” Advances in Neural Information Processing Systems , vol. 32, 2019
2019
-
[2]
Introduction to latent variable energy-based models: a path toward autonomous machine intelligence,
A. Dawid and Y. LeCun, “Introduction to latent variable energy-based models: a path toward autonomous machine intelligence,” Journal of 29 Statistical Mechanics: Theory and Experiment , vol. 2024, no. 10, p. 104011, 2024
2024
-
[3]
A tutorial on energy-based learning,
Y. LeCun, S. Chopra, R. Hadsell, M. Ranzato, and F. J. Huang, “A tutorial on energy-based learning,” Predicting Structured Data , pp. 1–59, 2006
2006
-
[4]
M. J. Wainwright and M. I. Jordan, Graphical Models, Exponential Families, and Variational Inference . Now Publishers, 2008
2008
-
[5]
A survey of Monte Carlo methods for noisy and costly densities with application to reinforcement learning and ABC,
F. Llorente, L. Martino, J. Read, and D. Delgado, “A survey of Monte Carlo methods for noisy and costly densities with application to reinforcement learning and ABC,” International Statistical Review, vol. 93, no. 1, pp. 18–61, 2025
2025
-
[6]
Efficient computational strategies for doubly intractable problems with applications to bayesian social networks,
A. Caimo and A. Mira, “Efficient computational strategies for doubly intractable problems with applications to bayesian social networks,” Statistics and Computing , vol. 25, pp. 113–125, 2015
2015
-
[7]
A double metropolis-hastings sampler for spatial models with intractable normalizing constants,
F. Liang, “A double metropolis-hastings sampler for spatial models with intractable normalizing constants,” Journal of Statistical Computation and Simulation, vol. 80, no. 9, pp. 1007–1022, 2010
2010
-
[8]
Mcmc for doubly-intractable distributions
I. Murray, Z. Ghahramani, and D. MacKay, “Mcmc for doubly-intractable distributions,” arXiv preprint arXiv:1206.6848 , 2012
-
[9]
Bayesian inference in the presence of intractable normalizing functions,
J. Park and M. Haran, “Bayesian inference in the presence of intractable normalizing functions,” Journal of the American Statistical Association , vol. 113, no. 523, pp. 1372–1390, 2018
2018
-
[10]
Markov chain Monte Carlo maximum likelihood,
C. J. Geyer, “Markov chain Monte Carlo maximum likelihood,” Computing Science and Statistics , vol. 23, pp. 156–163, 1991
1991
-
[11]
On the convergence of Monte Carlo maximum likelihood calculations,
——, “On the convergence of Monte Carlo maximum likelihood calculations,” Journal of the Royal Statistical Society, Series B , vol. 56, no. 2, pp. 261–274, 1994
1994
-
[12]
Estimation of non-normalized statistical models by score matching,
A. Hyvärinen, “Estimation of non-normalized statistical models by score matching,” Journal of Machine Learning Research , vol. 6, pp. 695–709, 2005. 30
2005
-
[13]
Spatial interaction and the statistical analysis of lattice systems,
J. Besag, “Spatial interaction and the statistical analysis of lattice systems,” Journal of the Royal Statistical Society, Series B , vol. 36, no. 2, pp. 192–236, 1974
1974
-
[14]
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,
M. U. Gutmann and A. Hyvärinen, “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,” Journal of Machine Learning Research, vol. 13, pp. 307–361, 2012
2012
-
[15]
Statistical applications of contrastive learning,
M. U. Gutmann, S. Kleinegesse, and B. Rhodes, “Statistical applications of contrastive learning,” Behaviormetrika, vol. 49, pp. 277–301, 2022
2022
-
[16]
A note on gradient- based parameter estimation for energy-based models,
L. Martino, S. Ingrassia, S. Mangano, and L. Scaffidi, “A note on gradient- based parameter estimation for energy-based models,” proceedings of 15th conference of Scientific Meeting of the Classification and Data Analysis Group (CLADAG) — https://vixra.org/abs/2503.0117, pp. 1–10, 2025
-
[17]
Noise contrastive estimation: Asymptotics and comparison with MC-MLE,
L. Riou-Durand and N. Chopin, “Noise contrastive estimation: Asymptotics and comparison with MC-MLE,” arXiv:1801.10381, 2019
-
[18]
Contrastive representation learning: A framework and review,
P. H. Le-Khac, G. Healy, and A. F. Smeaton, “Contrastive representation learning: A framework and review,” IEEE Access, vol. 8, p. 193907–193934,
-
[19]
A vailable: http://dx.doi.org/10.1109/ACCESS.2020.3031549
[Online]. A vailable: http://dx.doi.org/10.1109/ACCESS.2020.3031549
-
[20]
Contrastive clustering,
Y. Li, P. Hu, Z. Liu, D. Peng, J. T. Zhou, and X. Peng, “Contrastive clustering,” in Proceedings of the AAAI conference on artificial intelligence , vol. 35, 2021, pp. 8547–8555
2021
-
[21]
L. Martino, L. Scaffidi-Domianello, and S. Mangano, “Importance sampling and contrastive learning schemes for parameter estimation in non-normalized models,” viXra:2601.0065, pp. 1–30, 2026
-
[22]
Safe and effective importance sampling,
A. B. Owen and Y. Zhou, “Safe and effective importance sampling,” Journal of the American Statistical Association , vol. 95, no. 449, pp. 135–143, 2000
2000
-
[23]
Generalized multiple importance sampling,
V. Elvira, L. Martino, D. Luengo, and M. F. Bugallo, “Generalized multiple importance sampling,” Statistical Science, vol. 34, no. 1, pp. 129–155, 2019
2019
-
[24]
Simulating ratios of normalizing constants via a simple identity: a theoretical exploration,
X. L. Meng and W. H. Wong, “Simulating ratios of normalizing constants via a simple identity: a theoretical exploration,” Statistica Sinica, pp. 831–860, 1996. 31
1996
-
[25]
Marginal likelihood computation for model selection and hypothesis testing: An extensive review,
F. Llorente, L. Martino, D. Delgado, and J. López-Santiago, “Marginal likelihood computation for model selection and hypothesis testing: An extensive review,” SIAM Review, vol. 65, no. 1, pp. 3–58, 2023
2023
-
[26]
On the flexibility of Metropolis-Hastings acceptance probabilities in auxiliary variable proposal generation,
G. Storvik, “On the flexibility of Metropolis-Hastings acceptance probabilities in auxiliary variable proposal generation,” Scandinavian Journal of Statistics , vol. 38, no. 2, pp. 342–358, 2011
2011
-
[27]
On the flexibility of the design of multiple try Metropolis schemes,
L. Martino and J. Read, “On the flexibility of the design of multiple try Metropolis schemes,” Computational Statistics, vol. 28, no. 6, pp. 2797–2823, 2013
2013
-
[28]
The optimal noise in noise- contrastive learning is not what you think,
O. Chehab, A. Gramfort, and A. Hyvärinen, “The optimal noise in noise- contrastive learning is not what you think,” in Proceedings of the Thirty- Eighth Conference on Uncertainty in Artificial Intelligence , ser. Proceedings of Machine Learning Research, vol. 180, 2022, pp. 307–316
2022
-
[29]
——, “Optimizing the noise in self-supervised learning: From importance sampling to noise-contrastive estimation,” arXiv:2301.09696, 2023
-
[30]
Estimating normalizing constants and reweighting mixtures,
C. J. Geyer, “Estimating normalizing constants and reweighting mixtures,” Technical Report, number 568 - School of Statistics, University of Minnesota , 1994
1994
-
[31]
On Monte Carlo methods for estimating ratios of normalizing constants,
M. H. Chen, Q.-M. Shao et al. , “On Monte Carlo methods for estimating ratios of normalizing constants,” The Annals of Statistics , vol. 25, no. 4, pp. 1563–1594, 1997
1997
-
[32]
Recursive pathways to marginal likelihood estimation with prior-sensitivity analysis,
E. Cameron and A. Pettitt, “Recursive pathways to marginal likelihood estimation with prior-sensitivity analysis,” Statistical Science, vol. 29, no. 3, pp. 397–419, 2014
2014
-
[33]
The harmonic mean of the likelihood: worst Monte Carlo method ever,
R. Neal, “The harmonic mean of the likelihood: worst Monte Carlo method ever,” https://radfordneal.wordpress.com/, 2008
2008
-
[34]
Nonphysical sampling distributions in Monte Carlo free-energy estimation: Umbrella sampling,
G. M. Torrie and J. P. Valleau, “Nonphysical sampling distributions in Monte Carlo free-energy estimation: Umbrella sampling,” Journal of Computational Physics, vol. 23, no. 2, pp. 187–199, 1977. 32
1977
-
[35]
Strictly proper scoring rules, prediction, and estimation,
T. Gneiting and A. E. Raftery, “Strictly proper scoring rules, prediction, and estimation,” Journal of the American Statistical Association , vol. 102, no. 477, pp. 359–378, 2007
2007
-
[36]
Population Monte Carlo,
O. Cappé, A. Guillin, J. M. Marin, and C. P. Robert, “Population Monte Carlo,” Journal of Computational and Graphical Statistics , vol. 13, no. 4, pp. 907–929, 2004
2004
-
[37]
Adaptive importance sampling: the past, the present, and the future,
M. F. Bugallo, V. Elvira, L. Martino, D. Luengo, J. Miguez, and P. M. Djuric, “Adaptive importance sampling: the past, the present, and the future,” IEEE Signal Processing Magazine , vol. 34, no. 4, pp. 60–79, 2017
2017
-
[38]
Likelihood inference for spatial point processes,
C. J. Geyer and E. A. Thompson, “Likelihood inference for spatial point processes,” Journal of the Royal Statistical Society, Series B , vol. 61, no. 3, pp. 657–689, 1999
1999
-
[39]
Optimality in importance sampling: A gentle survey,
F. Llorente and L. Martino, “Optimality in importance sampling: A gentle survey,” arXiv:2502.07396, 2025. 33 Table 1: Summary of the estimators of Z using q(y) and/or ¯ϕ(y). The last column shows if a recursive procedure is required. The first four rows correspond to estimators using samples from ¯ϕ(y) and q(y). The last four rows correspond to estimators...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.