Recognition: unknown
HiRO-Nav: Hybrid ReasOning Enables Efficient Embodied Navigation
Pith reviewed 2026-05-10 16:55 UTC · model grok-4.3
The pith
HiRO-Nav triggers reasoning only on high-entropy actions to raise navigation success while cutting token use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
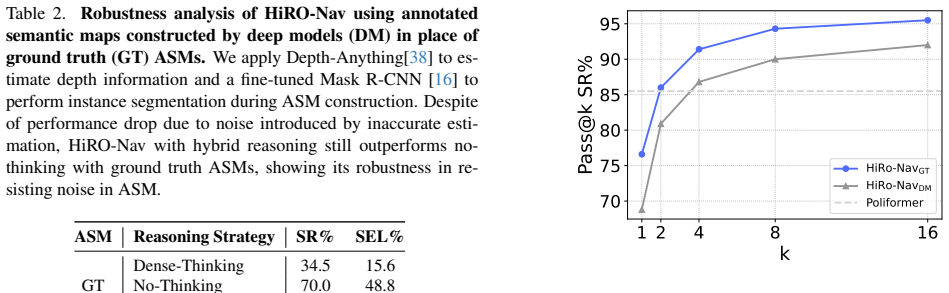
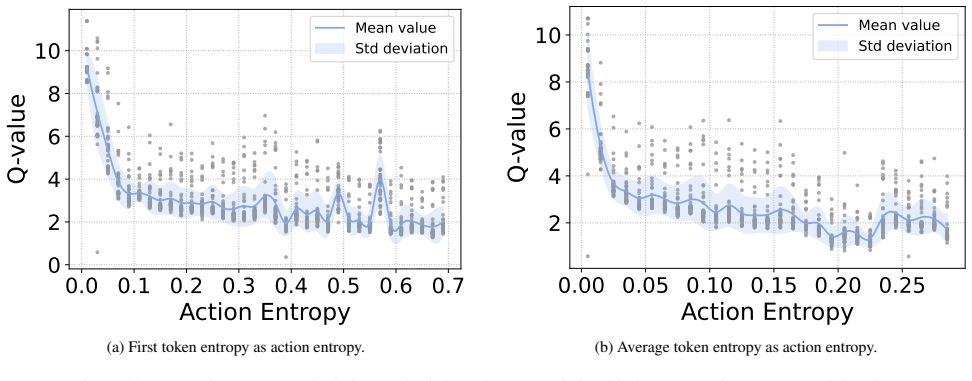
HiRO-Nav adaptively determines whether to perform thinking at every step based on its own action entropy. Examining entropy evolution reveals that only a small fraction of actions exhibit high entropy and these often steer the agent toward novel scenes or critical objects. The relationship between action entropy and Q-value further shows that improving high-entropy actions contributes more positively to task success. A tailored training pipeline of hybrid supervised fine-tuning followed by online reinforcement learning with the hybrid reasoning strategy explicitly activates reasoning only for high-entropy actions, significantly reducing computational overhead while improving decision quality
What carries the argument
Action entropy computed from the policy, used as a dynamic gate that activates deliberate reasoning only at high-uncertainty steps.
If this is right
- Success improves because reasoning effort is concentrated on the minority of steps that most affect long-horizon Q-values.
- Token consumption drops because the majority of low-entropy actions are executed reflexively without full reasoning traces.
- The two-stage training pipeline stabilizes the entropy-based gate without introducing instability in simple scenes.
- The same selective mechanism can be applied to other long-horizon embodied tasks that exhibit similar entropy distributions.
Where Pith is reading between the lines
- Entropy gating may reduce reasoning cost in other LRM applications such as planning or dialogue where uncertainty also clusters at decision forks.
- In physical robots the entropy signal would need to be computed from fast policy rollouts or approximations to avoid latency.
- Shared entropy across agents could coordinate when a team should reason collectively versus act independently.
Load-bearing premise
Action entropy reliably marks the exact steps where extra reasoning improves completion rates more than reflexive action and the hybrid training does not create new failure modes in low-entropy regimes.
What would settle it
An ablation that forces reasoning on low-entropy steps or suppresses it on high-entropy steps and measures whether overall success rate or efficiency degrades on the same CHORES-S episodes.
Figures









read the original abstract
Embodied navigation agents built upon large reasoning models (LRMs) can handle complex, multimodal environmental input and perform grounded reasoning per step to improve sequential decision-making for long-horizon tasks. However, a critical question remains: \textit{how can the reasoning capabilities of LRMs be harnessed intelligently and efficiently for long-horizon navigation tasks?} In simple scenes, agents are expected to act reflexively, while in complex ones they should engage in deliberate reasoning before acting.To achieve this, we introduce \textbf{H}ybr\textbf{i}d \textbf{R}eas\textbf{O}ning \textbf{Nav}igation (\textbf{HiRO-Nav}) agent, the first kind of agent capable of adaptively determining whether to perform thinking at every step based on its own action entropy. Specifically, by examining how the agent's action entropy evolves over the navigation trajectories, we observed that only a small fraction of actions exhibit high entropy, and these actions often steer the agent toward novel scenes or critical objects. Furthermore, studying the relationship between action entropy and task completion (i.e., Q-value) reveals that improving high-entropy actions contributes more positively to task success.Hence, we propose a tailored training pipeline comprising hybrid supervised fine-tuning as a cold start, followed by online reinforcement learning with the proposed hybrid reasoning strategy to explicitly activate reasoning only for high-entropy actions, significantly reducing computational overhead while improving decision quality. Extensive experiments on the \textsc{CHORES}-$\mathbb{S}$ ObjectNav benchmark showcases that HiRO-Nav achieves a better trade-off between success rates and token efficiency than both dense-thinking and no-thinking baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HiRO-Nav, an embodied navigation agent for long-horizon tasks that adaptively activates reasoning only at high action-entropy steps. It reports an observational finding that high-entropy actions are rare, steer toward novel/critical states, and that improving them yields higher marginal gains in task completion (measured by Q-value). A hybrid pipeline of supervised fine-tuning followed by online RL is proposed to implement this selective reasoning, with the central empirical claim being a superior success-rate versus token-efficiency trade-off on the CHORES-S ObjectNav benchmark relative to dense-thinking and no-thinking baselines.
Significance. If the empirical claims and mechanism are substantiated, the work could be significant for efficient deployment of large reasoning models in embodied settings by showing that selective, entropy-triggered reasoning can reduce computational overhead while preserving or improving decision quality in navigation. The hybrid SFT+RL training recipe and the entropy-based activation rule address a practical scaling concern, though the absence of supporting quantitative evidence and controls currently limits assessment of its broader impact.
major comments (3)
- [Abstract] Abstract: The central claim that HiRO-Nav achieves a better success-rate/token-efficiency trade-off is unsupported by any reported numbers, error bars, ablation tables, or statistical tests, rendering the headline result impossible to evaluate for magnitude or reliability.
- [Abstract] Abstract: The relationship between action entropy and Q-value is described only as an observational finding ('studying the relationship... reveals that improving high-entropy actions contributes more positively') without causal experiments, interventions, or controls demonstrating that the entropy selector itself drives the reported gains rather than other elements of the training pipeline.
- [Experiments section] Experiments section: No ablation is presented that replaces the entropy-based selector with an alternative sparse activation rule of comparable density (e.g., random or fixed-interval selection) while keeping the rest of the hybrid SFT+RL pipeline fixed; without this, it is impossible to establish that the adaptive entropy rule is load-bearing for the claimed trade-off improvement.
minor comments (2)
- The benchmark is referred to as CHORES-S or CHORES-𝕊 without an explicit definition or citation in the abstract; this notation should be clarified on first use in the main text.
- [Abstract] The phrase 'the first kind of agent capable of adaptively determining whether to perform thinking' should be tempered with a brief literature comparison to avoid overstatement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and proposed revisions to strengthen the presentation of results and controls.
read point-by-point responses
-
Referee: [Abstract] The central claim that HiRO-Nav achieves a better success-rate/token-efficiency trade-off is unsupported by any reported numbers, error bars, ablation tables, or statistical tests, rendering the headline result impossible to evaluate for magnitude or reliability.
Authors: The abstract provides a high-level summary of the empirical findings. Detailed quantitative results—including success rates, token consumption, error bars across multiple seeds, ablation tables, and statistical comparisons—are reported in the Experiments section on the CHORES-S benchmark. To improve accessibility, we will revise the abstract to incorporate key numerical values (e.g., success rate and token efficiency deltas versus baselines) while retaining the summary style. revision: yes
-
Referee: [Abstract] The relationship between action entropy and Q-value is described only as an observational finding ('studying the relationship... reveals that improving high-entropy actions contributes more positively') without causal experiments, interventions, or controls demonstrating that the entropy selector itself drives the reported gains rather than other elements of the training pipeline.
Authors: The entropy-Q-value relationship is presented as an observational analysis of trajectories to motivate the method. The primary evidence for the selector's utility is the end-to-end performance of the full HiRO-Nav pipeline (hybrid SFT followed by online RL with entropy-triggered reasoning) against dense-thinking and no-thinking baselines that share the same training recipe. We agree the language could be clarified to emphasize the observational basis and will add a dedicated paragraph discussing potential confounding factors from the training pipeline along with any available supporting statistics. revision: partial
-
Referee: [Experiments section] No ablation is presented that replaces the entropy-based selector with an alternative sparse activation rule of comparable density (e.g., random or fixed-interval selection) while keeping the rest of the hybrid SFT+RL pipeline fixed; without this, it is impossible to establish that the adaptive entropy rule is load-bearing for the claimed trade-off improvement.
Authors: The current experiments compare the entropy-triggered approach against the boundary cases of always-reason and never-reason under the identical hybrid training pipeline. We acknowledge that an ablation using non-adaptive sparse rules (random or fixed-interval) at matched activation density would more directly isolate the benefit of entropy-based selection. We will add this control experiment in the revised manuscript. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper's core chain proceeds from empirical observations of action entropy on trajectories (high-entropy steps are rare and correlate with higher marginal Q-value impact) to a design choice for an entropy-gated hybrid reasoning policy, implemented via hybrid SFT+RL training, and finally evaluated on downstream success/token metrics against baselines. These steps rely on external benchmark results rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or uniqueness theorems are invoked that reduce the claimed trade-off to the input statistics by construction. The entropy selector is a motivated heuristic whose effectiveness is tested independently via RL optimization and CHORES-S evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Olek- sandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects. arXiv preprint arXiv:2006.13171, 2020. 3
-
[3]
Yuxin Cai, Xiangkun He, Maonan Wang, Hongliang Guo, Wei-Yun Yau, and Chen Lv. Cl-cotnav: Closed-loop hi- erarchical chain-of-thought for zero-shot object-goal nav- igation with vision-language models.arXiv preprint arXiv:2504.09000, 2025. 1, 2, 3
-
[4]
Cognav: Cognitive process modeling for object goal navigation with llms,
Yihan Cao, Jiazhao Zhang, Zhinan Yu, Shuzhen Liu, Zheng Qin, Qin Zou, Bo Du, and Kai Xu. Cognav: Cognitive pro- cess modeling for object goal navigation with llms.arXiv preprint arXiv:2412.10439, 2024. 1, 3
-
[5]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Hen- rique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021. 8
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187, 2024. 3, 1
work page internal anchor Pith review arXiv 2024
-
[7]
Navila: Legged robot vision-language- action model for navigation,
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453, 2024. 6, 1
-
[8]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforce- ment learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025. 2, 3
work page internal anchor Pith review arXiv 2025
-
[9]
Gemini pro.https : / / deepmind
DeepMind. Gemini pro.https : / / deepmind . google/models/gemini/pro/, 2024. 1, 6
2024
-
[10]
arXiv preprint arXiv:2507.19849 , year=
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, et al. Agentic reinforced policy optimization.arXiv preprint arXiv:2507.19849, 2025. 3
-
[11]
Spoc: Imitating shortest paths in simulation enables effective navigation and manipu- lation in the real world
Kiana Ehsani, Tanmay Gupta, Rose Hendrix, Jordi Salvador, Luca Weihs, Kuo-Hao Zeng, Kunal Pratap Singh, Yejin Kim, Winson Han, Alvaro Herrasti, et al. Spoc: Imitating shortest paths in simulation enables effective navigation and manipu- lation in the real world. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 162...
2024
-
[12]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training. arXiv preprint arXiv:2505.10978, 2025. 6
work page internal anchor Pith review arXiv 2025
-
[13]
Octonav: Towards generalist embodied navigation.arXiv preprint arXiv:2506.09839, 2025
Chen Gao, Liankai Jin, Xingyu Peng, Jiazhao Zhang, Yue Deng, Annan Li, He Wang, and Si Liu. Octonav: To- wards generalist embodied navigation.arXiv preprint arXiv:2506.09839, 2025. 3, 6, 1
-
[14]
End-to-end navigation with vlms: Transforming spatial reasoning into question-answering
Dylan Goetting, Himanshu Gaurav Singh, and Antonio Lo- quercio. End-to-end navigation with vlms: Transforming spatial reasoning into question-answering. InWorkshop on Language and Robot Learning: Language as an Interface,
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017. 5, 8, 2
2017
-
[17]
Adactrl: Towards adaptive and controllable reasoning via difficulty-aware budgeting
Shijue Huang, Hongru Wang, Wanjun Zhong, Zhaochen Su, Jiazhan Feng, Bowen Cao, and Yi R Fung. Adactrl: Towards adaptive and controllable reasoning via difficulty-aware bud- geting.arXiv preprint arXiv:2505.18822, 2025. 3, 1
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Think only when you need with large hybrid-reasoning models.arXiv preprint arXiv:2505.14631,
Lingjie Jiang, Xun Wu, Shaohan Huang, Qingxiu Dong, Zewen Chi, Li Dong, Xingxing Zhang, Tengchao Lv, Lei Cui, and Furu Wei. Think only when you need with large hybrid-reasoning models.arXiv preprint arXiv:2505.14631,
-
[20]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474,
work page internal anchor Pith review arXiv
-
[21]
arXiv preprint arXiv:2503.16188 , volume=
Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, Haoquan Zhang, Wang Bill Zhu, and Kaipeng Zhang. Think or not think: A study of explicit thinking in rule-based visual re- inforcement fine-tuning.arXiv preprint arXiv:2503.16188,
-
[22]
Introducing o3 and o4 mini.https://openai
OpenAI. Introducing o3 and o4 mini.https://openai. com / zh - Hans - CN / index / introducing - o3 - and-o4-mini/, 2024. 1, 6
2024
-
[23]
Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Ad- vances in neural information processing systems, 35:27730– 27744, 2022. 4
2022
-
[24]
Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
Zhangyang Qi, Zhixiong Zhang, Yizhou Yu, Jiaqi Wang, and Hengshuang Zhao. Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221,
-
[25]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shi- jue Huang, et al. Ui-tars: Pioneering automated gui inter- action with native agents.arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review arXiv
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 4, 1
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre C ˆot´e, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for in- teractive learning.arXiv preprint arXiv:2010.03768, 2020. 8
work page internal anchor Pith review arXiv 2010
-
[29]
Zayne Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. To cot or not to cot? chain-of-thought helps mainly on math and sym- bolic reasoning.arXiv preprint arXiv:2409.12183, 2024. 2, 3, 1
-
[30]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 4, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Songjun Tu, Jiahao Lin, Qichao Zhang, Xiangyu Tian, Lin- jing Li, Xiangyuan Lan, and Dongbin Zhao. Learning when to think: Shaping adaptive reasoning in r1-style models via multi-stage rl.arXiv preprint arXiv:2505.10832, 2025. 2, 3, 1
-
[32]
Aux-think: Exploring reason- ing strategies for data-efficient vision-language navigation
Shuo Wang, Yongcai Wang, Wanting Li, Xudong Cai, Yucheng Wang, Maiyue Chen, Kaihui Wang, Zhizhong Su, Deying Li, and Zhaoxin Fan. Aux-think: Exploring reason- ing strategies for data-efficient vision-language navigation. arXiv preprint arXiv:2505.11886, 2025. 3, 1
-
[33]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shix- uan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025. 2, 3
work page internal anchor Pith review arXiv 2025
-
[34]
Adaptive deep reasoning: Triggering deep thinking when needed.arXiv preprint arXiv:2505.20101, 2025
Yunhao Wang, Yuhao Zhang, Tinghao Yu, Can Xu, Feng Zhang, and Fengzong Lian. Adaptive deep reasoning: Triggering deep thinking when needed.arXiv preprint arXiv:2505.20101, 2025. 3, 1
-
[35]
Zhaowei Wang, Hongming Zhang, Tianqing Fang, Ye Tian, Yue Yang, Kaixin Ma, Xiaoman Pan, Yangqiu Song, and Dong Yu. Divscene: Benchmarking lvlms for object nav- igation with diverse scenes and objects.arXiv preprint arXiv:2410.02730, 2024. 1
-
[36]
Q-learning.Ma- chine learning, 8(3):279–292, 1992
Christopher JCH Watkins and Peter Dayan. Q-learning.Ma- chine learning, 8(3):279–292, 1992. 2, 4
1992
-
[37]
Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 1, 3
2022
-
[38]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 5, 8
2024
-
[39]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024
Hang Yin, Xiuwei Xu, Zhenyu Wu, Jie Zhou, and Jiwen Lu. Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation.Advances in neural information processing systems, 37:5285–5307, 2024. 1, 2, 3
2024
-
[40]
Vlfm: Vision-language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In2024 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 42–48. IEEE, 2024. 1
2024
-
[42]
Linan Yue, Yichao Du, Yizhi Wang, Weibo Gao, Fangzhou Yao, Li Wang, Ye Liu, Ziyu Xu, Qi Liu, Shimin Di, et al. Don’t overthink it: A survey of efficient r1-style large rea- soning models.arXiv preprint arXiv:2508.02120, 2025. 3, 1
-
[43]
Poliformer: Scaling on-policy rl with transformers results in masterful navigators
Kuo-Hao Zeng, Zichen Zhang, Kiana Ehsani, Rose Hendrix, Jordi Salvador, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, and Luca Weihs. Poliformer: Scaling on-policy rl with transformers results in masterful navigators. InCon- ference on Robot Learning, pages 408–432. PMLR, 2025. 4, 5, 6, 8, 1
2025
-
[44]
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024. 1
-
[45]
Navid: Video-based vlm plans the next step for vision-and-language navigation,
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation.arXiv preprint arXiv:2402.15852, 2024. 1
-
[46]
Adaptthink: Reasoning models can learn when to think
Jiajie Zhang, Nianyi Lin, Lei Hou, Ling Feng, and Juanzi Li. Adaptthink: Reasoning models can learn when to think. arXiv preprint arXiv:2505.13417, 2025. 3, 1
-
[47]
MapNav: A novel memory representation via annotated semantic maps for VLM-based vision-and-language navigation
Lingfeng Zhang, Xiaoshuai Hao, Qinwen Xu, Qiang Zhang, Xinyao Zhang, Pengwei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, and Renjing Xu. MapNav: A novel memory representation via annotated semantic maps for VLM-based vision-and-language navigation. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1...
2025
-
[48]
Lingfeng Zhang, Yuecheng Liu, Zhanguang Zhang, Matin Aghaei, Yaochen Hu, Hongjian Gu, Mohammad Ali Alomrani, David Gamaliel Arcos Bravo, Raika Karimi, Atia Hamidizadeh, et al. Mem2ego: Empower- ing vision-language models with global-to-ego memory for long-horizon embodied navigation.arXiv preprint arXiv:2502.14254, 2025. 1, 2, 3
-
[49]
Mingjie Zhang, Yuheng Du, Chengkai Wu, Jinni Zhou, Zhenchao Qi, Jun Ma, and Boyu Zhou. Apexnav: An adaptive exploration strategy for zero-shot object naviga- tion with target-centric semantic fusion.arXiv preprint arXiv:2504.14478, 2025. 1, 2, 3
-
[50]
Linqing Zhong, Chen Gao, Zihan Ding, Yue Liao, Huimin Ma, Shifeng Zhang, Xu Zhou, and Si Liu. Topv- nav: Unlocking the top-view spatial reasoning potential of mllm for zero-shot object navigation.arXiv preprint arXiv:2411.16425, 2024. 1 A. Related Work A.1. Foundation Models as Navigation Agents LRMs have been introduced to handle navigation tasks [7, 13,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.