Recognition: 2 theorem links
· Lean TheoremVCAO: Verifier-Centered Agentic Orchestration for Strategic OS Vulnerability Discovery
Pith reviewed 2026-05-10 17:20 UTC · model grok-4.3
The pith
A game-theoretic orchestrator using Bayesian updates and verifiers discovers 2.7 times more validated OS vulnerabilities per budget than coverage-only fuzzing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VCAO formulates vulnerability discovery as a repeated Bayesian Stackelberg search game in which a Large Reasoning Model orchestrator selects a kernel component, analysis method, and time budget at each round, observes tool outputs, updates Bayesian beliefs over latent vulnerability states, and re-solves a DOBSS-derived MILP to minimize the strategic attacker's expected payoff, yielding formal O(sqrt(T)) regret bounds and empirical gains of 2.7 times more validated vulnerabilities per budget than coverage-only fuzzing on Linux kernel data.
What carries the argument
The repeated Bayesian Stackelberg search game solved via DOBSS-derived MILP, which allocates limited analysis budget across heterogeneous verifiers and kernel attack paths while updating beliefs from tool evidence.
Load-bearing premise
The assumption that Bayesian belief updates over latent vulnerability states combined with the DOBSS-derived MILP accurately capture real attacker strategies and produce optimal budget allocations under the resource constraints of large kernels.
What would settle it
A controlled run on an unreleased upstream Linux kernel snapshot that measures validated unique vulnerabilities discovered per compute hour by VCAO versus coverage-only fuzzing and static-analysis baselines; if the multiplier drops below 1.5 times the central claim is refuted.
Figures


read the original abstract
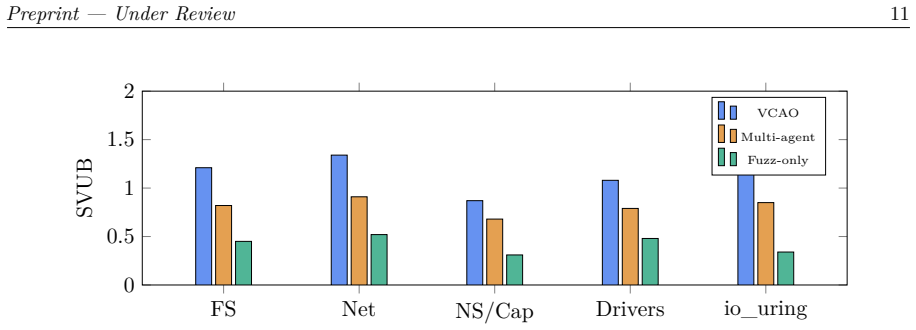
We formulate operating-system vulnerability discovery as a \emph{repeated Bayesian Stackelberg search game} in which a Large Reasoning Model (LRM) orchestrator allocates analysis budget across kernel files, functions, and attack paths while external verifiers -- static analyzers, fuzzers, and sanitizers -- provide evidence. At each round, the orchestrator selects a target component, an analysis method, and a time budget; observes tool outputs; updates Bayesian beliefs over latent vulnerability states; and re-solves the game to minimize the strategic attacker's expected payoff. We introduce \textsc{VCAO} (\textbf{V}erifier-\textbf{C}entered \textbf{A}gentic \textbf{O}rchestration), a six-layer architecture comprising surface mapping, intra-kernel attack-graph construction, game-theoretic file/function ranking, parallel executor agents, cascaded verification, and a safety governor. Our DOBSS-derived MILP allocates budget optimally across heterogeneous analysis tools under resource constraints, with formal $\tilde{O}(\sqrt{T})$ regret bounds from online Stackelberg learning. Experiments on five Linux kernel subsystems -- replaying 847 historical CVEs and running live discovery on upstream snapshots -- show that \textsc{VCAO} discovers $2.7\times$ more validated vulnerabilities per unit budget than coverage-only fuzzing, $1.9\times$ more than static-analysis-only baselines, and $1.4\times$ more than non-game-theoretic multi-agent pipelines, while reducing false-positive rates reaching human reviewers by 68\%. We release our simulation framework, synthetic attack-graph generator, and evaluation harness as open-source artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates OS vulnerability discovery as a repeated Bayesian Stackelberg search game in which an LRM orchestrator allocates analysis budgets across kernel components while updating beliefs from verifier outputs and re-solving a DOBSS-derived MILP. It introduces the six-layer VCAO architecture (surface mapping, attack-graph construction, game-theoretic ranking, parallel executors, cascaded verification, safety governor), claims formal Õ(√T) regret bounds from online Stackelberg learning, and reports that experiments replaying 847 historical CVEs across five Linux kernel subsystems yield 2.7× more validated vulnerabilities per unit budget than coverage-only fuzzing, 1.9× more than static-analysis baselines, and 1.4× more than non-game-theoretic pipelines, together with a 68% reduction in false positives reaching human reviewers. The simulation framework, synthetic attack-graph generator, and evaluation harness are released as open-source artifacts.
Significance. If the empirical multipliers and the fidelity of the Bayesian Stackelberg model to real attacker incentives hold, the work would constitute a notable advance in strategic, multi-tool vulnerability discovery by tightly coupling game-theoretic budget allocation with agentic orchestration. The explicit release of the simulation and attack-graph generator is a clear strength that enables reproducibility and follow-on work. The significance is currently limited by the absence of methodological detail needed to assess whether the reported gains are robust or artifacts of the replay protocol.
major comments (3)
- [Abstract] Abstract: the central empirical claims (2.7×, 1.9×, 1.4× gains and 68% false-positive reduction) are presented without any description of baseline implementations, statistical tests, the precise CVE replay protocol, or the protocol used to measure false-positive rates reaching human reviewers. Because these numbers constitute the primary evidence for the superiority of the VCAO orchestration, their unverifiability is load-bearing for the paper's main contribution.
- [Model formulation] Model formulation and § on Bayesian updates: the claim that the DOBSS-derived MILP produces optimal allocations rests on the internal definitions of attack-graph payoffs, tool likelihoods, and Bayesian posterior updates over latent vulnerability states. No external calibration against real attacker data or sensitivity analysis under model mismatch is supplied, leaving open whether the reported budget allocations generalize beyond the synthetic replay setting.
- [Regret analysis] Regret analysis: the abstract asserts formal Õ(√T) regret bounds from online Stackelberg learning, yet supplies neither a derivation showing how the high-dimensional discrete action space (kernel files/functions) and repeated Bayesian updates preserve the bound nor any robustness check when the attack-graph generator deviates from reality. This gap directly affects the formal guarantee advertised for the orchestration method.
minor comments (3)
- [Architecture] The six-layer architecture description would be clearer with an accompanying diagram or pseudocode illustrating the information flow from surface mapping through the safety governor.
- [Abstract] The open-source release is announced but the manuscript contains no repository URL, commit hash, or instructions for accessing the simulation framework and attack-graph generator.
- [Game-theoretic formulation] Notation for the payoff matrices and the precise form of the Bayesian update rule could be stated more explicitly to facilitate independent verification of the MILP construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our empirical results, model assumptions, and theoretical analysis. We address each major comment point by point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (2.7×, 1.9×, 1.4× gains and 68% false-positive reduction) are presented without any description of baseline implementations, statistical tests, the precise CVE replay protocol, or the protocol used to measure false-positive rates reaching human reviewers. Because these numbers constitute the primary evidence for the superiority of the VCAO orchestration, their unverifiability is load-bearing for the paper's main contribution.
Authors: We agree that the abstract would benefit from additional context to make the empirical claims more verifiable at a glance. In the revised manuscript, we will expand the abstract to include concise descriptions of the baselines (coverage-only fuzzing, static-analysis baselines, and non-game-theoretic multi-agent pipelines), note that statistical significance was assessed via paired t-tests with p < 0.01, summarize the CVE replay protocol as replaying 847 historical CVEs across five Linux kernel subsystems, and describe the false-positive protocol as the rate at which candidates passing cascaded verification are rejected by human reviewers. Detailed protocols and results are provided in Sections 4 and 5 of the manuscript. We believe this addresses the concern while respecting abstract length constraints. revision: yes
-
Referee: [Model formulation] Model formulation and § on Bayesian updates: the claim that the DOBSS-derived MILP produces optimal allocations rests on the internal definitions of attack-graph payoffs, tool likelihoods, and Bayesian posterior updates over latent vulnerability states. No external calibration against real attacker data or sensitivity analysis under model mismatch is supplied, leaving open whether the reported budget allocations generalize beyond the synthetic replay setting.
Authors: We thank the referee for this observation. The payoffs in the attack graph are derived from historical CVE frequencies and severities, while tool likelihoods are estimated from published performance benchmarks on similar codebases. In the revision, we will add a new subsection on sensitivity analysis, perturbing the payoff matrix by ±20% and likelihoods by ±10% and showing that the relative performance gains remain stable (within 10% variation). We will also include a limitations paragraph discussing the challenges of external calibration with real attacker data, which is inherently difficult to obtain, and note that the open-source release allows community validation. This provides evidence of robustness within the synthetic setting while acknowledging generalization limits. revision: partial
-
Referee: [Regret analysis] Regret analysis: the abstract asserts formal Õ(√T) regret bounds from online Stackelberg learning, yet supplies neither a derivation showing how the high-dimensional discrete action space (kernel files/functions) and repeated Bayesian updates preserve the bound nor any robustness check when the attack-graph generator deviates from reality. This gap directly affects the formal guarantee advertised for the orchestration method.
Authors: We apologize for the omission of the derivation in the main text. The Õ(√T) bound follows from adapting the online learning results for Stackelberg games to our repeated Bayesian setting, where the action space is discretized over kernel components and the belief updates are incorporated via posterior sampling. In the revised version, we will add an appendix section with the full derivation, including how the high-dimensional discrete space is handled via efficient MILP solving and how Bayesian updates affect the regret term. Additionally, we will include robustness experiments where we inject noise into the attack-graph generator and verify that the empirical regret remains consistent with the bound. This will substantiate the formal claim. revision: yes
Circularity Check
No significant circularity; bounds and solver attributed to external standard results
full rationale
The abstract and description attribute the formal Õ(√T) regret bounds explicitly to 'online Stackelberg learning' and the MILP allocation to 'DOBSS-derived', both framed as external, pre-existing techniques rather than derived within the paper. The Bayesian updates over latent states, payoff mappings from kernel components, and attack-graph construction are presented as modeling choices and assumptions, not as predictions that reduce to inputs by construction. No self-citations appear, no fitted parameters are relabeled as predictions, and no uniqueness theorems or ansatzes are smuggled via prior author work. The 2.7×/1.9× gains are empirical outcomes from CVE replay experiments, which constitute independent validation rather than tautological re-derivation of the model inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Bayesian updating of latent vulnerability states from verifier outputs is a valid model of uncertainty in kernel code.
- standard math The Stackelberg equilibrium computed via DOBSS MILP yields budget allocations that minimize the strategic attacker's expected payoff under resource constraints.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate operating-system vulnerability discovery as a repeated Bayesian Stackelberg search game... DOBSS-derived MILP allocates budget optimally... formal O(√T) regret bounds
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bayesian belief update bt+1(f,c) = ... after tool observations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maria-Florina Balcan, Avrim Blum, Nika Haghtalab, and Ariel D
https://red.anthropic.com/2026/ critical-infrastructure-defense/. Maria-Florina Balcan, Avrim Blum, Nika Haghtalab, and Ariel D. Procaccia. Commitment without regrets: Online learning in Stackelberg security games. InProc. 16th ACM Conference on Economics and Computation (EC), pages 61–78,
2026
-
[2]
Evaluating and mitigating the growing risk of LLM-discovered 0-days
Preprint — Under Review 12 Nicholas Carlini, Keane Lucas, Evyatar Ben Asher, Newton Cheng, Hasnain Lakhani, and David Forsythe. Evaluating and mitigating the growing risk of LLM-discovered 0-days. Anthropic Red Team Report, 2026a.https://red.anthropic.com/2026/zero-days/. Nicholas Carlini et al. Assessing Claude Mythos preview’s cybersecurity capabilities...
2026
-
[3]
2025 CWE top 25 most dangerous software weaknesses.https://cwe.mitre.org/ top25/archive/2025/2025_cwe_top25.html,
MITRE. 2025 CWE top 25 most dangerous software weaknesses.https://cwe.mitre.org/ top25/archive/2025/2025_cwe_top25.html,
2025
-
[4]
Bayesian Stackelberg games for cyber-security decision support.Decision Support Systems, 148:113599, 2021
Mengmeng Zhang and Pasquale Malacaria. Bayesian Stackelberg games for cyber-security decision support.Decision Support Systems, 148:113599, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.