Recognition: 2 theorem links
· Lean TheoremCan Vision Language Models Judge Action Quality? An Empirical Evaluation
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
Vision language models perform only marginally above random chance on action quality assessment and retain core limitations after bias fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
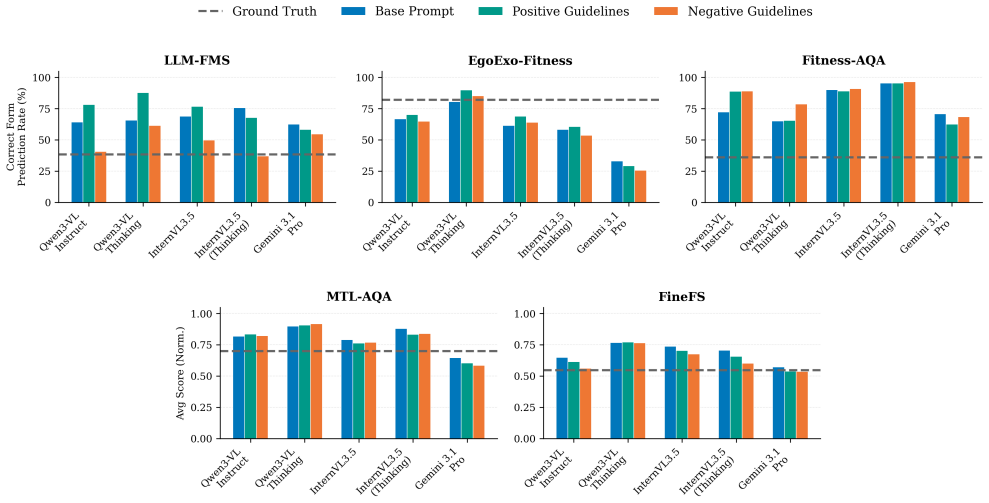
State-of-the-art VLMs achieve only marginal performance above random chance across activity domains, tasks, visual representations and prompting strategies. Isolated gains appear from skeleton incorporation, reasoning structures or in-context learning, yet no strategy works consistently. Prediction distributions expose a bias toward labeling executions as correct regardless of evidence and a sensitivity to superficial linguistic framing. Reformulating the tasks contrastively to counter these biases produces minimal improvement, which indicates that the models' shortcomings extend beyond surface biases to a fundamental difficulty with fine-grained movement quality assessment.
What carries the argument
Large-scale empirical evaluation of multiple VLMs on AQA datasets, combined with systematic testing of representations and prompts plus analysis of output distributions to identify biases.
If this is right
- VLMs cannot yet be deployed for reliable action quality scoring in physical therapy, sports coaching or judging.
- Bias mitigation through contrastive reformulation or added modalities is insufficient on its own.
- Future VLM-based AQA systems must target deeper architectural or training changes to handle fine-grained kinematic differences.
- The reported baseline enables direct measurement of progress in subsequent research.
- Identified failure modes such as over-prediction of correctness should be explicitly tested in new model releases.
Where Pith is reading between the lines
- The same models may face comparable limits on other tasks that require precise discrimination of temporal or kinematic variations, such as medical movement analysis.
- Training data may lack enough examples of subtle quality differences, suggesting data curation as one possible direction.
- Integration of explicit biomechanical constraints could help overcome the observed ceiling on performance.
- Real-time or multi-view AQA scenarios would likely expose the limitation even more clearly.
Load-bearing premise
The chosen datasets, activity domains and prompting strategies are representative enough to support a general claim of fundamental limitation rather than a limitation of the tested setups.
What would settle it
Demonstration of a VLM that achieves high accuracy on the same or similar AQA tasks by reliably distinguishing subtle execution differences without defaulting to positive predictions would falsify the claim of fundamental difficulty.
Figures

read the original abstract
Action Quality Assessment (AQA) has broad applications in physical therapy, sports coaching, and competitive judging. Although Vision Language Models (VLMs) hold considerable promise for AQA, their actual performance in this domain remains largely uncharacterised. We present a comprehensive evaluation of state-of-the-art VLMs across activity domains (e.g. fitness, figure skating, diving), tasks, representations, and prompting strategies. Baseline results reveal that Gemini 3.1 Pro, Qwen3-VL and InternVL3.5 models perform only marginally above random chance, and although strategies such as incorporation of skeleton information, grounding instructions, reasoning structures and in-context learning lead to isolated gains, none is consistently effective. Analysis of prediction distributions uncovers two systematic biases: a tendency to predict correct execution regardless of visual evidence, and a sensitivity to superficial linguistic framing. Reformulating tasks contrastively to mitigate these biases yields minimal improvement, suggesting that the models' limitations go beyond these biases, pointing to a fundamental difficulty with fine-grained movement quality assessment. Our findings establish a rigorous baseline for future VLM-based AQA research and provide an actionable outline for failure modes requiring mitigation prior to reliable real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a comprehensive empirical evaluation of state-of-the-art VLMs (Gemini 3.1 Pro, Qwen3-VL, InternVL3.5) on Action Quality Assessment (AQA) across domains including fitness, figure skating, and diving. Baseline performance is reported as only marginally above random chance; strategies such as skeleton input, grounding instructions, reasoning structures, in-context learning, and contrastive reformulation produce only isolated or minimal gains. The authors identify two systematic biases (over-prediction of correct execution and sensitivity to linguistic framing) and conclude that the results indicate a fundamental difficulty with fine-grained movement quality assessment, establishing a baseline for future VLM-based AQA work.
Significance. If the empirical findings hold under broader testing, the work is significant for documenting current VLM limitations on fine-grained visual judgment tasks with direct relevance to physical therapy, sports coaching, and judging applications. It supplies a reproducible baseline, identifies concrete failure modes (bias patterns and resistance to standard mitigations), and offers an actionable outline that can guide targeted improvements in visual reasoning for quality assessment.
major comments (2)
- [Abstract and §5] Abstract and §5 (Discussion/Conclusion): The claim that results point to a 'fundamental difficulty' with fine-grained movement quality assessment is load-bearing for the paper's central contribution. This inference rests on the tested domains, task framings, and prompting repertoire being representative; the manuscript provides no experiments with additional domains, multi-turn visual reasoning protocols, or lightweight adaptation/fine-tuning regimes that could produce substantially higher accuracy, so the generalization from 'minimal improvement in tested configurations' to 'fundamental limitation' is not yet supported by the evidence.
- [Results section] Results section (tables/figures reporting performance): The manuscript reports near-chance performance and minimal gains from mitigations but does not include exact sample sizes per domain, statistical significance tests (e.g., p-values or confidence intervals on accuracy differences), or full per-model/per-strategy result tables. Without these, it is difficult to evaluate the robustness of the 'only marginally above random chance' and 'minimal improvement' claims that underpin the fundamental-difficulty conclusion.
minor comments (3)
- [Abstract and §3] Clarify model version nomenclature (e.g., 'Gemini 3.1 Pro' appears to be a non-standard designation; confirm whether this refers to Gemini 1.5 Pro, Gemini 2.0, or another variant).
- [§3 (Experimental Setup)] Add explicit dataset statistics (number of videos/clips per activity domain, train/test splits, and annotation protocols) to the experimental setup section for reproducibility.
- [Figures and Tables] Ensure all figures include error bars or variance measures and that table captions fully describe the metrics and conditions shown.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help strengthen the rigor and clarity of our empirical evaluation. We respond to each major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Discussion/Conclusion): The claim that results point to a 'fundamental difficulty' with fine-grained movement quality assessment is load-bearing for the paper's central contribution. This inference rests on the tested domains, task framings, and prompting repertoire being representative; the manuscript provides no experiments with additional domains, multi-turn visual reasoning protocols, or lightweight adaptation/fine-tuning regimes that could produce substantially higher accuracy, so the generalization from 'minimal improvement in tested configurations' to 'fundamental limitation' is not yet supported by the evidence.
Authors: We agree that the phrasing 'fundamental difficulty' represents a strong generalization. Our evaluation covers representative AQA domains (fitness, figure skating, diving) and a broad range of standard prompting and input strategies, yet we acknowledge that the absence of multi-turn protocols or adaptation experiments limits the strength of the claim. In revision, we will moderate the language in the abstract and Section 5 to state that the results 'highlight substantial challenges and limitations in current VLM performance on fine-grained AQA' rather than asserting a fundamental difficulty. We will also add explicit discussion of the evaluation's scope and the value of future adaptation-based work. revision: partial
-
Referee: [Results section] Results section (tables/figures reporting performance): The manuscript reports near-chance performance and minimal gains from mitigations but does not include exact sample sizes per domain, statistical significance tests (e.g., p-values or confidence intervals on accuracy differences), or full per-model/per-strategy result tables. Without these, it is difficult to evaluate the robustness of the 'only marginally above random chance' and 'minimal improvement' claims that underpin the fundamental-difficulty conclusion.
Authors: We thank the referee for identifying this presentational gap. In the revised manuscript we will report exact sample sizes per domain and task. We will add statistical tests, including binomial tests against chance level and confidence intervals on accuracy differences, along with pairwise comparisons between prompting strategies. Complete per-model and per-strategy result tables will be placed in an appendix to support transparent evaluation of all claims. revision: yes
Circularity Check
No circularity: pure empirical benchmarking with no derivations or self-referential reductions
full rationale
The paper is an empirical evaluation study that benchmarks VLMs on AQA tasks using existing datasets, reports observed accuracies and biases, and tests prompting variants. No equations, fitted parameters, or first-principles derivations appear; claims rest on direct experimental outcomes rather than any reduction to inputs by construction. Self-citations, if present, are not load-bearing for the central empirical findings. The generalization to 'fundamental difficulty' is an interpretive step whose strength depends on domain coverage, but this is a question of external validity, not circularity in any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Action quality can be meaningfully quantified and compared using video inputs and language-based scoring prompts on the selected activity domains.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Baseline results reveal that Gemini 3.1 Pro, Qwen3-VL and InternVL3.5 models perform only marginally above random chance... Reformulating tasks contrastively... yields minimal improvement, suggesting... fundamental difficulty with fine-grained movement quality assessment.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Analysis of prediction distributions uncovers two systematic biases... sensitivity to superficial linguistic framing.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
System card: Claude sonnet 4.6
Anthropic. System card: Claude sonnet 4.6. Technical re- port, Anthropic, 2026. 6
2026
-
[2]
Action quality assessment with temporal parsing transformer
Yang Bai, Desen Zhou, Songyang Zhang, Jian Wang, Errui Ding, Yu Guan, Yang Long, and Jingdong Wang. Action quality assessment with temporal parsing transformer. In European Conference on Computer Vision, pages 422–438,
-
[3]
PhD thesis, University of Luxembourg,
Renato Manuel Lemos Baptista.Human Motion Analysis Using 3D Skeleton Representation in the Context of Real- World Applications: From Home-Based Rehabilitation to Sensing in the Wild. PhD thesis, University of Luxembourg,
-
[4]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand- hini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz...
1901
-
[5]
Marianna Capecci, Maria Gabriella Ceravolo, Francesco Ferracuti, Sabrina Iarlori, Andrea Monteriu, Luca Romeo, and Federica Verdini. The kimore dataset: Kinematic assess- ment of movement and clinical scores for remote monitor- ing of physical rehabilitation.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 27(7):1436–1448,
-
[6]
Quo vadis, action recognition? A new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? A new model and the kinetics dataset. InIEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017. 1, 7
2017
-
[7]
SportsCap: Monocular 3D human motion capture and fine-grained understanding in challenging sports videos
Xin Chen, Anqi Pang, Wei Yang, Yuexin Ma, Lan Xu, and Jingyi Yu. SportsCap: Monocular 3D human motion capture and fine-grained understanding in challenging sports videos. International Journal of Computer Vision, 129:2846–2864,
-
[8]
Learning and fusing multiple hidden substages for action quality assessment.Knowledge- Based Systems, 229:107388, 2021
Li-Jia Dong, Hong-Bo Zhang, Qinghongya Shi, Qing Lei, Ji- Xiang Du, and Shangce Gao. Learning and fusing multiple hidden substages for action quality assessment.Knowledge- Based Systems, 229:107388, 2021. 1
2021
-
[9]
End-to-end action quality assessment with action parsing transformer
Hang Fang, Wengang Zhou, and Houqiang Li. End-to-end action quality assessment with action parsing transformer. In IEEE International Conference on Visual Communications and Image Processing, pages 1–5, 2023. 7
2023
-
[10]
Fine-grained spatio-temporal parsing net- work for action quality assessment.IEEE Transactions on Image Processing, 32:6386–6400, 2023
Kumie Gedamu, Yanli Ji, Yang Yang, Jie Shao, and Heng Tao Shen. Fine-grained spatio-temporal parsing net- work for action quality assessment.IEEE Transactions on Image Processing, 32:6386–6400, 2023. 1
2023
-
[11]
Vertex AI.https://cloud.google
Google Cloud. Vertex AI.https://cloud.google. com/vertex-ai, 2023. 3
2023
-
[12]
Gemini 3.1 pro model card.https: / / deepmind
Google DeepMind. Gemini 3.1 pro model card.https: / / deepmind . google / models / model - cards / gemini-3-1-pro/, 2026. Google DeepMind. 1, 2
2026
-
[13]
Action quality assessment using transformers.arXiv preprint arXiv:2207.12318, 2022
Abhay Iyer, Mohammad Alali, Hemanth Bodala, and Sunit Vaidya. Action quality assessment using transformers.arXiv preprint arXiv:2207.12318, 2022. 1
-
[14]
Localization-assisted uncertainty score disentanglement network for action quality assessment
Yanli Ji, Lingfeng Ye, Huili Huang, Lijing Mao, Yang Zhou, and Lingling Gao. Localization-assisted uncertainty score disentanglement network for action quality assessment. In Proceedings of the 31st ACM International Conference on Multimedia, pages 1–10. ACM, 2023. 2
2023
-
[15]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InPro- ceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. 3
2023
-
[16]
EgoExo-Fitness: Towards egocentric and exocentric full-body action under- standing
Yuan-Ming Li, Wei-Jin Huang, An-Lan Wang, Ling-An Zeng, Jing-Ke Meng, and Wei-Shi Zheng. EgoExo-Fitness: Towards egocentric and exocentric full-body action under- standing. InEuropean Conference on Computer Vision (ECCV), pages 363–382. Springer, 2024. 2
2024
-
[17]
Tech- Coach: Towards technical-point-aware descriptive action coaching, 2025
Yuan-Ming Li, An-Lan Wang, Kun-Yu Lin, Yu-Ming Tang, Ling-An Zeng, Jian-Fang Hu, and Wei-Shi Zheng. Tech- Coach: Towards technical-point-aware descriptive action coaching, 2025. 1, 7
2025
-
[18]
Action quality as- sessment with ignoring scene context
Takasuke Nagai, Shoichiro Takeda, Masaaki Matsumura, Shinya Shimizu, and Susumu Yamamoto. Action quality as- sessment with ignoring scene context. InIEEE International Conference on Image Processing, pages 1189–1193, 2021. 1
2021
-
[19]
Eagle-Eye: Extreme-pose action grader using detail bird’s- eye view
Mahdiar Nekoui, Fidel Omar Tito Cruz, and Li Cheng. Eagle-Eye: Extreme-pose action grader using detail bird’s- eye view. InIEEE/CVF Winter Conference on Applications of Computer Vision, pages 394–402, 2021. 1
2021
-
[20]
Assess- ing the quality of soccer shots from single-camera video with vision-language models and motion features
Filip Noworolnik and Joanna Jaworek-Korjakowska. Assess- ing the quality of soccer shots from single-camera video with vision-language models and motion features. InIEEE/CVF International Conference on Computer Vision Workshops, pages 2733–2740, 2025. 7
2025
-
[21]
Action assess- ment by joint relation graphs
Jia-Hui Pan, Jibin Gao, and Wei-Shi Zheng. Action assess- ment by joint relation graphs. InIEEE/CVF International Conference on Computer Vision, pages 6331–6340, 2019. 1
2019
-
[22]
Learning to score olympic events
Paritosh Parmar and Brendan Tran Morris. Learning to score olympic events. InIEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 20–28, 2017. 1, 7
2017
-
[23]
What and how well you performed? A multitask learning approach to action quality assessment
Paritosh Parmar and Brendan Tran Morris. What and how well you performed? A multitask learning approach to action quality assessment. InIEEE Conference on Computer Vision and Pattern Recognition, pages 304–313, 2019. 1, 2, 7
2019
-
[24]
Do- main knowledge-informed self-supervised representations for workout form assessment
Paritosh Parmar, Amol Gharat, and Helge Rhodin. Do- main knowledge-informed self-supervised representations for workout form assessment. InEuropean Conference on Computer Vision (ECCV). Springer, 2022. 1, 2 9
2022
-
[25]
Pose-guided matching based on deep learning for assessing quality of action on rehabili- tation training.Biomedical Signal Processing and Control, 72:103323, 2022
Yuhang Qiu, Jiping Wang, Zhe Jin, Honghui Chen, Min- gliang Zhang, and Liquan Guo. Pose-guided matching based on deep learning for assessing quality of action on rehabili- tation training.Biomedical Signal Processing and Control, 72:103323, 2022. 1
2022
-
[26]
Qwen3-VL technical report, 2025
Qwen Team. Qwen3-VL technical report, 2025. 1, 2
2025
-
[27]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstan- tine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulhoff, et al. The prompt report: A systematic survey of prompting techniques.arXiv preprint arXiv:2406.06608, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[28]
Can VLMs actually see and read? a survey on modal- ity collapse in vision-language models
Mong Yuan Sim, Wei Emma Zhang, Xiang Dai, and Biaoyan Fang. Can VLMs actually see and read? a survey on modal- ity collapse in vision-language models. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 24452–24470, Vienna, Austria, 2025. Association for Com- putational Linguistics. 8
2025
-
[29]
A data set of human body movements for physical rehabilitation exercises.Data, 3(1):2, 2018
Aleksandar Vakanski, Hyung-pil Jun, David Paul, and Rus- sell Baker. A data set of human body movements for physical rehabilitation exercises.Data, 3(1):2, 2018. 1
2018
-
[30]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 2017. 1
2017
-
[31]
TSA-Net: Tube self-attention network for ac- tion quality assessment
Shunli Wang, Dingkang Yang, Peng Zhai, Chixiao Chen, and Lihua Zhang. TSA-Net: Tube self-attention network for ac- tion quality assessment. InACM International Conference on Multimedia, pages 4902–4910, 2021. 1, 7
2021
-
[32]
InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025
Weiyun Wang, Zhangwei Gao, Lixin Gu, et al. InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025. 1, 2
2025
-
[33]
Chain-of- thought prompting elicits reasoning in large language mod- els
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain-of- thought prompting elicits reasoning in large language mod- els. InAdvances in Neural Information Processing Systems,
-
[34]
HieroAction: Hierarchically guided VLM for fine-grained action analysis, 2025
Junhao Wu et al. HieroAction: Hierarchically guided VLM for fine-grained action analysis, 2025. 1, 4, 7
2025
-
[35]
Hager, and Trac D
Xiang Xiang, Ye Tian, Austin Reiter, Gregory D. Hager, and Trac D. Tran. S3D: Stacking segmental P3D for action qual- ity assessment. InIEEE International Conference on Image Processing, pages 928–932, 2018. 1, 7
2018
-
[36]
LLM-FMS: A fine-grained dataset for functional movement screen action quality assessment.PLOS ONE, 20 (3):e0313707, 2025
Qingjun Xing, Xing Xing, Peng Guo, Zhen Tang, and Yue Shen. LLM-FMS: A fine-grained dataset for functional movement screen action quality assessment.PLOS ONE, 20 (3):e0313707, 2025. 2
2025
-
[37]
Likert scor- ing with grade decoupling for long-term action assessment
Angchi Xu, Ling-An Zeng, and Wei-Shi Zheng. Likert scor- ing with grade decoupling for long-term action assessment. InIEEE Conference on Computer Vision and Pattern Recog- nition, pages 3232–3241, 2022. 1, 7
2022
-
[38]
Sam 3d body: Robust full-body human mesh recovery.arXiv preprint arXiv:2602.15989,
Xitong Yang, Devansh Kukreja, Don Pinkus, Anushka Sagar, Taosha Fan, Jinhyung Park, Soyong Shin, Jinkun Cao, Jiawei Liu, Nicolas Ugrinovic, Matt Feiszli, Jitendra Malik, Piotr Doll´ar, and Kris Kitani. SAM 3D Body: Robust full-body human mesh recovery.arXiv preprint arXiv:2602.15989,
-
[39]
A decade of action quality assessment: Largest systematic survey of trends, challenges, and future directions.International Journal of Computer Vi- sion, 134:73, 2026
Hao Yin, Paritosh Parmar, Daoliang Xu, Yang Zhang, Tianyou Zheng, and Weiwei Fu. A decade of action quality assessment: Largest systematic survey of trends, challenges, and future directions.International Journal of Computer Vi- sion, 134:73, 2026. 3
2026
-
[40]
Hybrid dynamic-static context-aware attention network for action assessment in long videos
Ling-An Zeng, Fa-Ting Hong, Wei-Shi Zheng, Qi-Zhi Yu, Wei Zeng, Yao-Wei Wang, and Jian-Huang Lai. Hybrid dynamic-static context-aware attention network for action assessment in long videos. InACM International Confer- ence on Multimedia, pages 2526–2534, 2020. 1
2020
-
[41]
a{video / image}of someone
Shiyi Zhang, Sule Bai, Guangyi Chen, Lei Chen, Jiwen Lu, Junle Wang, and Yansong Tang. Narrative action evaluation with prompt-guided multimodal interaction. InIEEE Con- ference on Computer Vision and Pattern Recognition, pages 18430–18439, 2024. 1, 7 10 Can Vision Language Models Judge Action Quality? An Empirical Evaluation Appendix A. Dataset Preproces...
2024
-
[42]
First, carefully examine the provided image in detail
-
[43]
Identify the person’s body position, joint angles, and alignment
-
[44]
For each question below, look at the specific body parts mentioned in the image
-
[45]
Base your answer ONLY on what is actually visible in this specific image
-
[46]
No explanations, no additional text
Compare what you see against each available option to select the best match RESPONSE FORMAT: You must respond ONLY with a valid JSON object. No explanations, no additional text. The JSON object must be in this exact format:{”{Rule ID}”: ”your answer”,} — ANALYSIS QUESTIONS: For each question, examine the relevant body parts in the image and select the opt...
-
[48]
Focus on the specific body parts and movements mentioned in the statement below
-
[49]
Observe how the person executes the movement throughout the video
-
[50]
Visual Grounding Prompt — Fitness-AQA You are analyzing a video of someone performing the exercise:{Action Name} CRITICAL INSTRUCTIONS:
Base your answer ONLY on what is actually visible in this specific video — STATEMENT TO VERIFY: ”{Keypoint Statement}” Observe the video and determine: Is this instruction being correctly followed? (Answer with the exact word that matches your observation) — RESPONSE FORMAT: Respond with ONLY ”True” or ”False” (nothing else). Visual Grounding Prompt — Fit...
-
[52]
Identify the person’s body position, movement patterns, and form throughout
-
[53]
For each error type below, observe the specific body parts mentioned across frames
-
[55]
No explanations, no additional text
Determine if each specific form error is present at any point during the movement RESPONSE FORMAT: You must respond ONLY with a valid JSON object. No explanations, no additional text. The JSON object must be in this exact format:{”{Error Name}”: ”True or False”,} — ERROR DETECTION: For each error type, examine the relevant body parts in the video and dete...
-
[57]
Identify the execution quality, movement patterns, and form throughout
-
[58]
Observe technique, flow, control, and any errors or excellent features
-
[60]
No explanations, no additional text
Determine the Grade of Execution (GOE) score for this execution RESPONSE FORMAT: You must respond with ONLY a single numeric value. No explanations, no additional text. Output only the numeric value from -5 to 5. — GOE SCALE: - Ranges from -5 (very poor) to 5 (exceptional) - 0 indicates meeting basic requirements - Positive GOE for good execution features...
-
[61]
First, carefully examine ALL frames in the provided video
-
[62]
Identify the execution quality, body positions, and form throughout
-
[63]
Observe technique, water entry, rotation control, and any errors or excellent features
-
[64]
Base your answer ONLY on what is actually visible in this specific video
-
[65]
No explanations, no additional text
Determine the execution score for this dive RESPONSE FORMAT: You must respond with ONLY a single numeric value. No explanations, no additional text. Output only the numeric value from 0 to 10. — SCORE RANGE: - Ranges from 0 (very poor) to 10 (perfect) - Higher scores indicate better execution quality - Consider execution quality, body position, form, tech...
-
[67]
— STEP 2 - ANSWER QUESTIONS: Based on your detailed observation above, answer the following questions
Then, answer specific questions based on your observations — STEP 1 - DETAILED OBSERV ATION: Before answering any questions, carefully examine the image and describe: - Overall body position and posture - Head and neck alignment - Shoulder position and alignment - Spine curvature and torso position - Hip position and alignment - Knee position and alignmen...
-
[68]
First, describe what you observe regarding the specific aspect mentioned
-
[69]
Focus on the relevant body parts and movements mentioned
Then, determine if the statement is True or False — STATEMENT TO VERIFY: ”{Keypoint Statement}” STEP 1 - OBSERV ATION: Describe what you observe in the video regarding this specific instruction. Focus on the relevant body parts and movements mentioned. STEP 2 - DETERMINATION: Based on your observation, is the instruction being correctly followed? — RESPON...
-
[71]
— STEP 2 - ERROR DETECTION: Based on your detailed observation above, determine if each form error is present
Then, determine if each form error is present based on your observations — STEP 1 - DETAILED OBSERV ATION: Before answering any questions, carefully examine the video and describe: - Overall movement pattern and exercise technique - Body position and posture throughout the movement - Arm and hand positioning - Leg and foot positioning - Torso and spine al...
-
[73]
— STEP 2 - GOE PREDICTION: Based on your detailed observation above, determine the GOE score
Then, determine the Grade of Execution (GOE) based on your observations — STEP 1 - DETAILED OBSERV ATION: Before assigning a score, carefully examine the video and describe: - Overall movement pattern and execution quality - Body position and posture throughout - Technical aspects (form, positions, alignment) - Speed, flow, and control - Height/amplitude ...
-
[74]
First, provide a detailed description of what you observe
-
[75]
— STEP 2 - SCORE PREDICTION: Based on your detailed observation above, determine the execution score
Then, determine the execution score based on your observations — STEP 1 - DETAILED OBSERV ATION: Before assigning a score, carefully examine the video and describe: - Overall movement pattern and execution quality - Body position and posture throughout the dive - Technical aspects (form, positions, alignment) - Rotation control and speed - Water entry qua...
-
[77]
The ¡output¿ tag must contain ONLY valid JSON with answers from the provided options
-
[79]
Base your analysis ONLY on what is visible in the image Begin your structured analysis now. Structured Reasoning Prompt — EgoExo-Fitness You are analyzing a video of someone performing the exercise:{Action Name} — STATEMENT TO VERIFY: ”{Keypoint Statement}” — INSTRUCTIONS: You must analyze this video using a structured reasoning process. Follow the EXACT ...
-
[81]
The ¡output¿ tag must contain ONLY the word ”True” or ”False”
-
[83]
Base your analysis ONLY on what is visible in the video Begin your structured analysis now. Structured Reasoning Prompt — Fitness-AQA You are analyzing a video of someone performing:{Action Name} POSSIBLE ERRORS TO DETECT: -{Error Name}: ”{Error Description}” — INSTRUCTIONS: You must analyze this video using a structured reasoning process. Follow the EXAC...
-
[85]
The ¡output¿ tag must contain ONLY valid JSON with ”True” or ”False” for each error
-
[87]
Structured Reasoning Prompt — FineFS You are analyzing a video of someone executing a{Action Name}({Action Name})
Base your analysis ONLY on what is visible in the video Begin your structured analysis now. Structured Reasoning Prompt — FineFS You are analyzing a video of someone executing a{Action Name}({Action Name}). GOE SCALE: - Ranges from -5 (very poor) to 5 (exceptional) - 0 indicates meeting basic requirements - Positive GOE for good execution features (height...
-
[89]
The ¡output¿ tag must contain ONLY a single numeric value from -5 to 5
-
[91]
Structured Reasoning Prompt — MTL-AQA You are analyzing a video of someone executing a dive
Base your analysis ONLY on what is visible in the video Begin your structured analysis now. Structured Reasoning Prompt — MTL-AQA You are analyzing a video of someone executing a dive. SCORE RANGE: - Ranges from 0 (very poor) to 10 (perfect) - Higher scores indicate better execution quality - Consider execution quality, body position, form, technique, and...
-
[92]
You MUST use all five tags in order:<look>,<decompose>,<analyse>,<assess>, ¡output¿
-
[93]
The ¡output¿ tag must contain ONLY a single numeric value from 0 to 10
-
[94]
Do not skip any tags or change their order
-
[95]
Base your analysis ONLY on what is visible in the video Begin your structured analysis now. B.5. Guideline Prompts The Positive and Negative Guidelines Prompts share the same structure, represented here with the placeholder{Guidelines}, which is substituted with best-form or worst-form guidelines depending on the variant. Guidelines Prompt — LLM-FMS You a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.