Recognition: unknown
Scaling-Aware Data Selection for End-to-End Autonomous Driving Systems
Pith reviewed 2026-05-10 17:18 UTC · model grok-4.3
The pith
Scaling laws fitted per data domain let MOSAIC select mixtures that improve end-to-end driving scores with far less data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MOSAIC partitions a dataset into domains, fits neural scaling laws that map data volume from each domain to chosen evaluation metrics, and iteratively augments the training mixture by the domain that yields the largest predicted improvement in those metrics. In the autonomous-driving case this procedure produces higher EPDMS scores for an end-to-end planner than competing selection policies while requiring substantially smaller total data volumes.
What carries the argument
MOSAIC, the iterative mixture optimizer that uses per-domain neural scaling laws to forecast metric gains before each data addition.
If this is right
- Data collection budgets for multi-criterion physical-AI tasks can be allocated by predicted metric return rather than uniform or random sampling.
- The same scaling-law machinery can be reused across different planner architectures provided the evaluation metrics remain fixed.
- Iterative re-fitting of the laws after each addition keeps the selection policy responsive to the current training state.
Where Pith is reading between the lines
- The approach implicitly assumes that domain contributions are additive; interactions between domains may require an extended model.
- Because the method only needs the scaling curves, it can be applied to any task whose metrics admit power-law or similar fits.
- A practical extension would be to incorporate acquisition cost per domain so that the optimizer balances performance gain against collection expense.
Load-bearing premise
The fitted scaling laws from each domain accurately forecast the metric change that will occur when more data from that domain is added to the training mixture.
What would settle it
Train an end-to-end planner on the MOSAIC-selected mixture and on a baseline mixture of equal size; if the EPDMS score does not improve or if the observed score deviates markedly from the value predicted by the scaling laws, the central claim is falsified.
Figures










read the original abstract
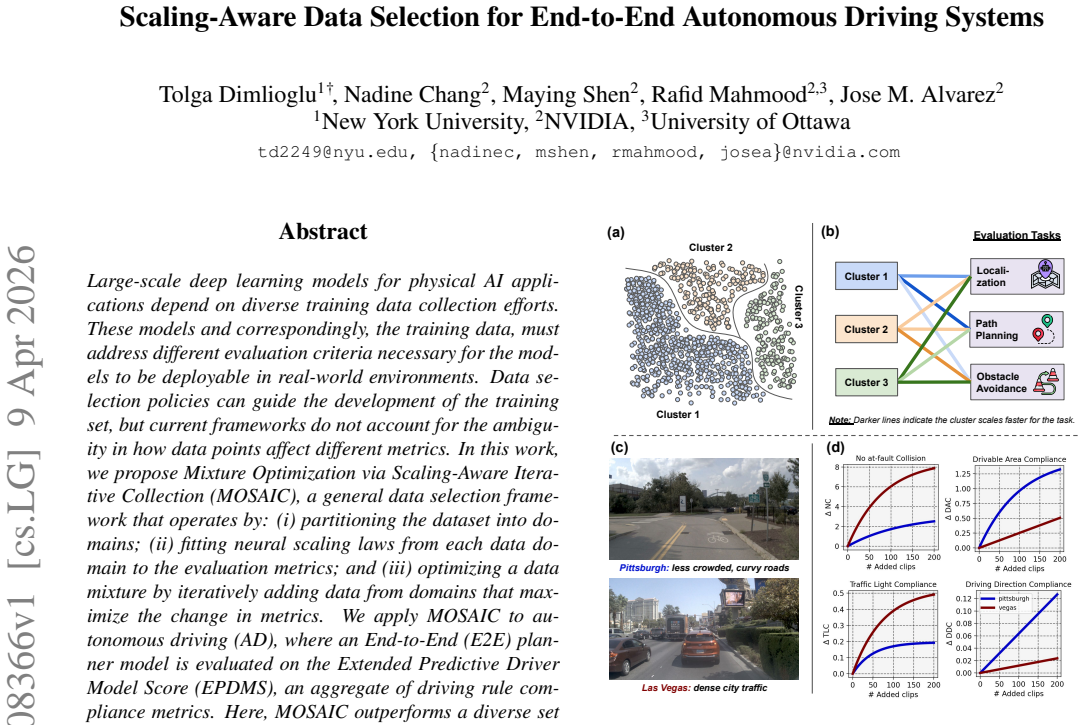
Large-scale deep learning models for physical AI applications depend on diverse training data collection efforts. These models and correspondingly, the training data, must address different evaluation criteria necessary for the models to be deployable in real-world environments. Data selection policies can guide the development of the training set, but current frameworks do not account for the ambiguity in how data points affect different metrics. In this work, we propose Mixture Optimization via Scaling-Aware Iterative Collection (MOSAIC), a general data selection framework that operates by: (i) partitioning the dataset into domains; (ii) fitting neural scaling laws from each data domain to the evaluation metrics; and (iii) optimizing a data mixture by iteratively adding data from domains that maximize the change in metrics. We apply MOSAIC to autonomous driving (AD), where an End-to-End (E2E) planner model is evaluated on the Extended Predictive Driver Model Score (EPDMS), an aggregate of driving rule compliance metrics. Here, MOSAIC outperforms a diverse set of baselines on EPDMS with up to 80\% less data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MOSAIC, a data selection framework that partitions training data into domains, fits separate neural scaling laws from each domain to target evaluation metrics, and iteratively optimizes the data mixture by selecting the domain that maximizes the predicted metric improvement at each step. Applied to end-to-end autonomous driving planners evaluated on the aggregate EPDMS score (rule-compliance metrics), the method is claimed to outperform a range of baselines while using up to 80% less data.
Significance. If the central empirical claims hold after addressing the mixture-interaction concern, MOSAIC would offer a principled, scaling-law-driven approach to data-efficient training for physical AI systems. This could meaningfully reduce the cost and scale of data collection for deployable models in autonomous driving and related domains, while providing a general template for metric-aware mixture optimization.
major comments (3)
- [§3 and §4] §3 (Method) and §4 (Experiments): The iterative selection procedure fits independent per-domain scaling laws to EPDMS (or its components) and assumes these can be used to predict marginal gains under domain mixtures. No ablation or hold-out validation is described that tests whether the predicted metric deltas match observed deltas when domains are actually combined during training; if non-additive interactions exist (e.g., rare-edge data only becoming useful after complementary coverage), the optimization will systematically select suboptimal mixtures. This assumption is load-bearing for the headline 80% data-reduction claim.
- [§4.2] §4.2 (Baselines and EPDMS): The abstract states outperformance on EPDMS but the provided description gives no information on the precise baselines, the number of runs, statistical significance testing, or how the aggregate EPDMS is decomposed when fitting the scaling laws. Without these details the data support for the central claim cannot be verified.
- [§3.3] §3.3 (Optimization loop): The procedure is described as iteratively adding data from the domain that maximizes predicted metric change, yet no analysis is given of convergence properties, sensitivity to the initial mixture, or whether the fitted scaling laws remain stable as the mixture evolves.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly named the baselines and stated whether EPDMS components or the aggregate score are used for the scaling-law fits.
- [§3] Notation for the scaling-law functional form and the precise definition of “change in metrics” should be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment by adding the requested validations, experimental details, and analyses to the revised manuscript. Our responses are provided point-by-point below.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): The iterative selection procedure fits independent per-domain scaling laws to EPDMS (or its components) and assumes these can be used to predict marginal gains under domain mixtures. No ablation or hold-out validation is described that tests whether the predicted metric deltas match observed deltas when domains are actually combined during training; if non-additive interactions exist (e.g., rare-edge data only becoming useful after complementary coverage), the optimization will systematically select suboptimal mixtures. This assumption is load-bearing for the headline 80% data-reduction claim.
Authors: We agree that validating the additivity assumption is essential. In the revised manuscript we have added a new ablation in §4.3 that trains models on held-out domain mixtures and directly compares the scaling-law-predicted EPDMS deltas against the observed deltas from actual training runs. The predictions match observed values with a mean absolute error of 0.02 on the EPDMS scale and no systematic bias, supporting the reported data-efficiency gains for the domain partition used. We also added a brief discussion of the assumption's limitations for strongly interactive domains. revision: yes
-
Referee: [§4.2] §4.2 (Baselines and EPDMS): The abstract states outperformance on EPDMS but the provided description gives no information on the precise baselines, the number of runs, statistical significance testing, or how the aggregate EPDMS is decomposed when fitting the scaling laws. Without these details the data support for the central claim cannot be verified.
Authors: We apologize for the omitted details. The baselines are random sampling, uncertainty sampling (model entropy), diversity sampling (k-means on features), and full-data training. All experiments were run five times with independent random seeds; we report mean EPDMS together with standard deviations. Statistical significance versus baselines was assessed with paired t-tests (p < 0.01 for the 80 % data-reduction result). Scaling laws were fit to the aggregate EPDMS; per-component results are now provided in the appendix. These clarifications have been inserted into §4.2. revision: yes
-
Referee: [§3.3] §3.3 (Optimization loop): The procedure is described as iteratively adding data from the domain that maximizes predicted metric change, yet no analysis is given of convergence properties, sensitivity to the initial mixture, or whether the fitted scaling laws remain stable as the mixture evolves.
Authors: We have added the requested analysis to the revised §3.3 and a new Appendix C. The procedure converges in 8–12 iterations on our datasets, with mixture proportions stabilizing thereafter. Sensitivity tests starting from 5 %, 10 %, and 20 % random initial data yield final mixtures differing by <10 % in domain proportions and EPDMS scores within 1 % of one another. Scaling-law parameters stabilize after the first three iterations once sufficient per-domain data is present. These results are now reported in the manuscript. revision: yes
Circularity Check
No circularity: empirical scaling fits used as heuristic for selection, validated downstream
full rationale
The paper's chain is: partition data into domains, fit neural scaling laws per domain to EPDMS (or components), then iteratively select domains maximizing predicted metric change from the fits. The headline result (outperformance on EPDMS with 80% less data) is obtained by actually training the E2E planner on the resulting mixture and measuring the real metric, not by the predictions alone. No equation reduces a claimed prediction to its own fitted parameters by construction, no self-citation is load-bearing for a uniqueness claim, and no ansatz or renaming is smuggled in. The procedure is a standard empirical optimization heuristic whose correctness can be (and is) checked externally; it does not collapse to self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Scaling Laws of Mo- tion Forecasting and Planning – Technical Report, 2025
Mustafa Baniodeh, Kratarth Goel, Scott Ettinger, Carlos Fuertes, Ari Seff, Tim Shen, Cole Gulino, Chenjie Yang, Ghassen Jerfel, Dokook Choe, et al. Scaling laws of motion forecasting and planning–a technical report.arXiv preprint arXiv:2506.08228, 2025. 1
-
[4]
End to End Learning for Self-Driving Cars
M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, X. Zhang, J. Zhao, and K. Zeiba. End to end learning for self-driving cars, 2016. Available athttps: //arxiv.org/abs/1604.07316. 3
work page internal anchor Pith review arXiv 2016
-
[5]
On the resemblance and containment of documents
Andrei Z Broder. On the resemblance and containment of documents. InProceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171), pages 21–29. IEEE, 1997. 1
1997
-
[6]
Pseudo- simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, and Kashyap Chitta. Pseudo- simulation for autonomous driving. InConference on Robot Learning (CoRL), 2025. 3, 5
2025
-
[7]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
” what data benefits my classifier?” enhancing model performance and interpretability through influence- based data selection
Anshuman Chhabra, Peizhao Li, Prasant Mohapatra, and Hongfu Liu. ” what data benefits my classifier?” enhancing model performance and interpretability through influence- based data selection. InThe Twelfth International Confer- ence on Learning Representations, 2024. 3
2024
-
[9]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):12878–12895, 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):12878–12895, 2022. 3
2022
-
[10]
End-to-end driving via conditional imitation learning
Felipe Codevilla, Matthias M ¨uller, Antonio L ´opez, Vladlen Koltun, and Alexey Dosovitskiy. End-to-end driving via conditional imitation learning. In2018 IEEE international conference on robotics and automation (ICRA), pages 4693–
-
[11]
Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driv- ing
OpenScene Contributors. Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driv- ing. InProceedings of the Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, pages 18–22,
-
[12]
Michael J. Coren. Tesla has 780 million miles of driving data, and adds another million every 10 hours, 2025. Ac- cessed: YYYY-MM-DD. 1
2025
-
[13]
Parting with misconceptions about learning- based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with misconceptions about learning- based vehicle motion planning. InConf. on Robot Learning,
-
[14]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024. 2, 3, 5, 1
2024
-
[15]
Climb: Clustering-based iterative data mixture bootstrapping for language model pre-training,
Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, et al. Climb: Clustering-based iterative data mixture bootstrapping for language model pre-training. arXiv preprint arXiv:2504.13161, 2025. 3
-
[16]
Large scale in- teractive motion forecasting for autonomous driving: The waymo open motion dataset
Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles Qi, Yin Zhou, Zoey Yang, Aur ´elien Chouard, Pei Sun, Jiquan Ngiam, Vijay Vasudevan, Alexander McCauley, Jonathon Shlens, and Dragomir Anguelov. Large scale in- teractive motion forecasting for autonomous driving: The waymo open motion data...
2021
-
[17]
Doge: Domain reweighting with generalization estimation.arXiv preprint arXiv:2310.15393, 2023
Simin Fan, Matteo Pagliardini, and Martin Jaggi. Doge: Domain reweighting with generalization estimation.arXiv preprint arXiv:2310.15393, 2023. 2
-
[18]
Training ai for self-driving vehicles: the challenge of scale, 2017
Adam Grzywaczewski. Training ai for self-driving vehicles: the challenge of scale, 2017. Accessed: YYYY-MM-DD. 1
2017
-
[19]
Tan et al
K. Tan et al. H. Caesar, J. Kabzan. Nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles. In CVPR ADP3 workshop, 2021. 1
2021
-
[20]
arXiv preprint arXiv:2405.18392 , year=
Alexander H ¨agele, Elie Bakouch, Atli Kosson, Loubna Ben Allal, Leandro V on Werra, and Martin Jaggi. Scaling laws and compute-optimal training beyond fixed training dura- tions.arXiv preprint arXiv:2405.18392, 2024. 2
-
[21]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom B Brown, Prafulla Dhariwal, Scott Gray, et al. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010.14701, 2020. 1
work page internal anchor Pith review arXiv 2010
-
[22]
Vad: Vectorized scene representa- tion for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representa- tion for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8340–8350, 2023. 3
2023
-
[23]
Adaptive data optimization: Dynamic sample selection with scaling laws
Yiding Jiang, Allan Zhou, Zhili Feng, Sadhika Malladi, and J Zico Kolter. Adaptive data optimization: Dynamic sample selection with scaling laws. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2
2025
-
[24]
Multi-class active learning for image classification
Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. Multi-class active learning for image classification. In2009 9 ieee conference on computer vision and pattern recognition, pages 2372–2379. IEEE, 2009. 3, 5, 1
2009
-
[25]
Feiyang Kang, Nadine Chang, Maying Shen, Marc T Law, Rafid Mahmood, Ruoxi Jia, and Jose M Alvarez. Adadedup: Adaptive hybrid data pruning for efficient large-scale object detection training.arXiv preprint arXiv:2507.00049, 2025. 2
-
[26]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[27]
Towards learning-based planning: The nuplan benchmark for real-world autonomous driving
Napat Karnchanachari, Dimitris Geromichalos, Kok Seang Tan, Nanxiang Li, Christopher Eriksen, Shakiba Yaghoubi, Noushin Mehdipour, Gianmarco Bernasconi, Whye Kit Fong, Yiluan Guo, et al. Towards learning-based planning: The nuplan benchmark for real-world autonomous driving. In2024 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 6...
2024
-
[28]
Not all sam- ples are created equal: Deep learning with importance sam- pling
Angelos Katharopoulos and Franc ¸ois Fleuret. Not all sam- ples are created equal: Deep learning with importance sam- pling. InInternational conference on machine learning, pages 2525–2534. PMLR, 2018. 4
2018
-
[29]
D. P. Kingma and J. L. Ba. Adam: A method for stochas- tic optimization. InInt. Conf. on Learning Representations,
-
[30]
Are all training examples equally valu- able?arXiv preprint arXiv:1311.6510, 2013
Agata Lapedriza, Hamed Pirsiavash, Zoya Bylinskii, and Antonio Torralba. Are all training examples equally valu- able?arXiv preprint arXiv:1311.6510, 2013. 4
-
[31]
Centermask: Real- time anchor-free instance segmentation
Youngwan Lee and Jongyoul Park. Centermask: Real- time anchor-free instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13906–13915, 2020. 5, 1
2020
-
[32]
Heterogeneous uncertainty sampling for supervised learning
David D Lewis and Jason Catlett. Heterogeneous uncertainty sampling for supervised learning. InMachine learning pro- ceedings 1994, pages 148–156. Elsevier, 1994. 3
1994
-
[33]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi- target hydra-distillation.arXiv preprint arXiv:2406.06978,
work page internal anchor Pith review arXiv
-
[34]
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open- loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024. 3
2024
-
[35]
A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook.IEEE Transactions on Intelligent Vehicles, 2024
Mingyu Liu, Ekim Yurtsever, Jonathan Fossaert, Xingcheng Zhou, Walter Zimmer, Yuning Cui, Bare Luka Zagar, and Alois C Knoll. A survey on autonomous driving datasets: Statistics, annotation quality, and a future outlook.IEEE Transactions on Intelligent Vehicles, 2024. 1
2024
-
[36]
Regmix: Data mixture as regression for language model pre-training
Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin. Regmix: Data mixture as regression for language model pre-training. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2
2025
-
[37]
Influence selection for active learning
Zhuoming Liu, Hao Ding, Huaping Zhong, Weijia Li, Jifeng Dai, and Conghui He. Influence selection for active learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 9274–9283, 2021. 3
2021
-
[38]
Low-budget active learning via wasserstein distance: An integer program- ming approach
Rafid Mahmood, Sanja Fidler, and Marc T Law. Low-budget active learning via wasserstein distance: An integer program- ming approach. InInternational Conference on Learning Representations, 2022. 1
2022
-
[39]
Optimizing data collection for machine learning.Journal of Machine Learning Research, 26(38): 1–52, 2025
Rafid Mahmood, James Lucas, Jose M Alvarez, Sanja Fidler, and Marc T Law. Optimizing data collection for machine learning.Journal of Machine Learning Research, 26(38): 1–52, 2025. 2
2025
-
[40]
Is pseudo-lidar needed for monocular 3d object detection? InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 3142–3152,
Dennis Park, Rares Ambrus, Vitor Guizilini, Jie Li, and Adrien Gaidon. Is pseudo-lidar needed for monocular 3d object detection? InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 3142–3152,
-
[41]
Priyaranjan Pattnayak, Hitesh Laxmichand Patel, Bhargava Kumar, Amit Agarwal, Ishan Banerjee, Srikant Panda, and Tejaswini Kumar. Survey of large multimodal model datasets, application categories and taxonomy.arXiv preprint arXiv:2412.17759, 2024. 1
-
[42]
ALVINN: an autonomous land vehicle in a neural network
Dean Pomerleau. ALVINN: an autonomous land vehicle in a neural network. InAdvances in Neural Information Process- ing Systems 1, [NIPS Conference, Denver, Colorado, USA, 1988], pages 305–313. Morgan Kaufmann, 1988. 3
1988
-
[43]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
2021
-
[44]
A survey of deep active learning.ACM computing surveys (CSUR), 54(9):1–40, 2021
Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B Gupta, Xiaojiang Chen, and Xin Wang. A survey of deep active learning.ACM computing surveys (CSUR), 54(9):1–40, 2021. 2
2021
-
[45]
Margin-based active learning for structured output spaces
Dan Roth and Kevin Small. Margin-based active learning for structured output spaces. InEuropean conference on ma- chine learning, pages 413–424. Springer, 2006. 3
2006
-
[46]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolu- tional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017. 1, 3, 5, 2
work page Pith review arXiv 2017
-
[47]
Sse: Multimodal semantic data selection and enrich- ment for industrial-scale data assimilation
Maying Shen, Nadine Chang, Sifei Liu, and Jose M Al- varez. Sse: Multimodal semantic data selection and enrich- ment for industrial-scale data assimilation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2525–2535, 2025. 2, 3
2025
-
[48]
Fairdedup: Detecting and mitigating vision-language fair- ness disparities in semantic dataset deduplication
Eric Slyman, Stefan Lee, Scott Cohen, and Kushal Kafle. Fairdedup: Detecting and mitigating vision-language fair- ness disparities in semantic dataset deduplication. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13905–13916, 2024. 2
2024
-
[49]
Beyond neural scaling laws: beat- ing power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beat- ing power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022. 1, 2, 4
2022
-
[50]
10 Gordon
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J. 10 Gordon. An empirical study of example forgetting during deep neural network learning. InInternational Conference on Learning Representations, 2019. 3
2019
-
[51]
Williams
Ziting Wen, Oscar Pizarro, and Stefan B. Williams. Feature alignment: Rethinking efficient active learning via proxy in the context of pre-trained models.Transactions on Machine Learning Research, 2024. 5
2024
-
[52]
Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong base- line.Advances in Neural Information Processing Systems, 35:6119–6132, 2022
Penghao Wu, Xiaosong Jia, Li Chen, Junchi Yan, Hongyang Li, and Yu Qiao. Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong base- line.Advances in Neural Information Processing Systems, 35:6119–6132, 2022. 3
2022
-
[53]
Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36:69798–69818, 2023
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36:69798–69818, 2023. 2
2023
-
[54]
Chameleon: A flexible data-mixing framework for language model pretraining and finetuning
Wanyun Xie, Francesco Tonin, and V olkan Cevher. Chameleon: A flexible data-mixing framework for language model pretraining and finetuning. InForty-second Interna- tional Conference on Machine Learning, 2025. 2, 5
2025
-
[55]
Chengyin Xu, Kaiyuan Chen, Xiao Li, Ke Shen, and Chenggang Li. Unveiling downstream performance scal- ing of llms: A clustering-based perspective.arXiv preprint arXiv:2502.17262, 2025. 4
-
[56]
Data mixing laws: Optimizing data mixtures by predicting language modeling performance
Jiasheng Ye, Peiju Liu, Tianxiang Sun, Jun Zhan, Yunhua Zhou, and Xipeng Qiu. Data mixing laws: Optimizing data mixtures by predicting language modeling performance. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 1, 2
2025
-
[57]
Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta- world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020. 2
2020
-
[58]
Scaling vision transformers
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lu- cas Beyer. Scaling vision transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12104–12113, 2022. 1
2022
-
[59]
A compar- ative survey of deep active learning.arXiv preprint arXiv:2203.13450, 2022
Xueying Zhan, Qingzhong Wang, Kuan-hao Huang, Haoyi Xiong, Dejing Dou, and Antoni B Chan. A compar- ative survey of deep active learning.arXiv preprint arXiv:2203.13450, 2022. 2 11 Scaling-Aware Data Selection for End-to-End Autonomous Driving Systems Supplementary Material
-
[60]
Experiment Protocols 7.1. Dataset and Virtual Clip Creation We conduct experiments using theNavtrain[14] and trainvalsplits ofOpenScene[11] as the combined training and pool datasets.OpenSceneis a redistribution of the NuPlan dataset [19], subsampled to 2 Hz, and con- tains approximately 120 hours of driving data with dense annotations. TheNavtrainsplit i...
2024
-
[61]
Experiments onOpenscene.The full validation EPDMS and BRMR results for the Openscene experiments can be found in Table 6
More Results on the Experiments and Abla- tions Due to the space constraints in the main body of the paper, we present more results here. Experiments onOpenscene.The full validation EPDMS and BRMR results for the Openscene experiments can be found in Table 6. The breakdown of the validation EPDMS subscores are shared in Table 9. The scaling curves obtaine...
-
[62]
Please provide a concise description in one paragraph with less than 150 words
Describe it if objects are partially occluded by others, or are in areas with different brightness such as under shades. Please provide a concise description in one paragraph with less than 150 words. Do not mention anything that you are certain does not exist! No statements about uncertain ob- jects or events (no ’maybe’ or ’might’ or ’possibly’). All re...
-
[63]
MOSAIC requires an upfront compute investment to esti- mate cluster-specific scaling curves via pilot runs
Details on the Scaling Fits and Compute Budget. MOSAIC requires an upfront compute investment to esti- mate cluster-specific scaling curves via pilot runs. To keep this cost tractable, we avoid full training from-scratch dur- ing the pilot experiments. Instead, we adopt a continual- training approach: we resume training from the base model’s final epoch c...
2000
-
[64]
Ranking with Alternative Cheap Signals Since ranking is one of the key components of our framework, we also investigate cheaper alternatives to the EPDMS-based ranking signal to reduce the reliance on dense annotations such as bounding boxes. Specifically, we experiment with ranking clips according to (i) the trajectory imitation loss, (ii) the norm of th...
-
[65]
Approximation for Linear Separability and Error Analysis: Here, we formally express the performance improvement obtained from a data mixture∆U(n 1,· · ·, n M)as follows: MX i=1 ∆Ui(ni) + X i̸=j ∆Uij(ni, nj) +H.O.T. Here, the pairwise cross-cluster interaction term ∆Uij(ni, nj)is defined as∆U ij =U ij −U i −U j +U 0, where we use a lightweight notation for...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.